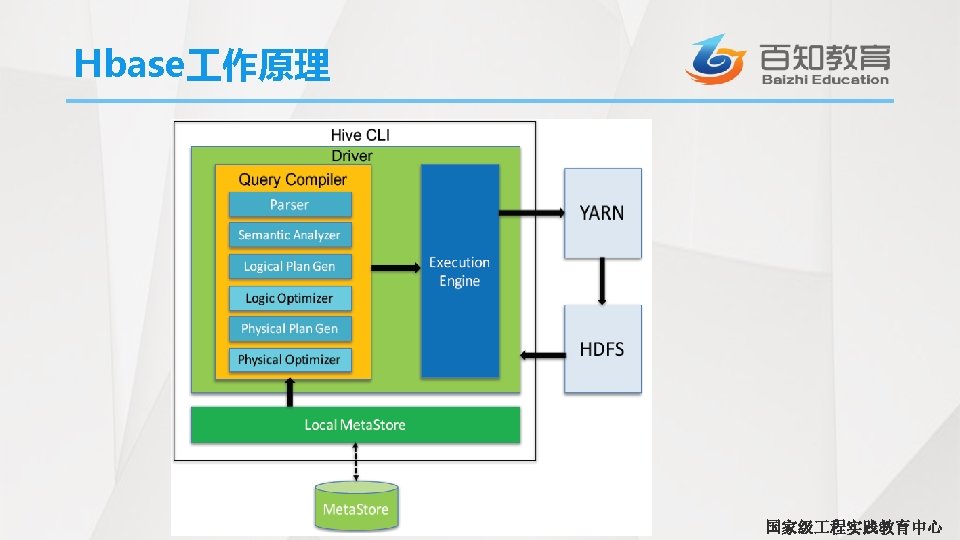
CONTENTS ITEMS 1 ITEMS 2 3 ITEMS 4




































 SELECT *")





这样的聚合函数)。假设有一个employees表: CREATE TABLE employees( name STRING, salary FLOAT,")


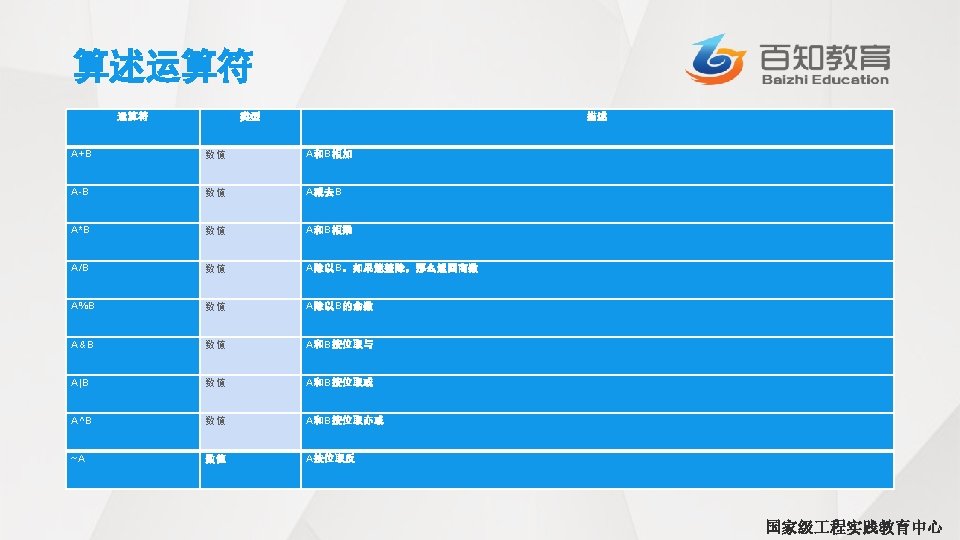

 返回DOUBLE型d的BIGINT类型的近似值 DOUBLE round(DOUBLE")


![LIMIT语句 • 典型的查询会返回多行数据。LIMIT子句用于限制返回的行数 hive> SELECT upper (name),salary, deductions["Federal Taxes"], >round (salary*(1 -deductions["Federal Taxes"])) FROM](https://slidetodoc.com/presentation_image_h2/fa78074db161d2c1091b295e30ad241c/image-63.jpg "LIMIT语句 • 典型的查询会返回多行数据。LIMIT子句用于限制返回的行数 hive> SELECT upper (name),salary, deductions[\"Federal Taxes\"], >round (salary*(1 -deductions[\"Federal Taxes\"])) FROM")
![列别名 • 为第 3个和第 4个字段起了别名,别名分别为fed_taxes和 salary_minuses_fed_taxes。 hive> SELECT upper(name) , salary, deductions["Federal Taxes"]as fed](https://slidetodoc.com/presentation_image_h2/fa78074db161d2c1091b295e30ad241c/image-64.jpg "列别名 • 为第 3个和第 4个字段起了别名,别名分别为fed_taxes和 salary_minuses_fed_taxes。 hive> SELECT upper(name) , salary, deductions[\"Federal Taxes\"]as fed")
![嵌套SELECT语句 • 对于嵌套查询语句来说,使用别名是非常有用的。下面,我们使用前面的示 例作为一个嵌套查询: hive> FROM > SELECT upper(name), salary, deductions["Federal Taxes"] as fed](https://slidetodoc.com/presentation_image_h2/fa78074db161d2c1091b295e30ad241c/image-65.jpg "嵌套SELECT语句 • 对于嵌套查询语句来说,使用别名是非常有用的。下面,我们使用前面的示 例作为一个嵌套查询: hive> FROM > SELECT upper(name), salary, deductions[\"Federal Taxes\"] as fed")



![关于浮点数比较的一个常见陷阱出现在不同类型间作比较的时候(也就是FLOAT和 DOUBLE比较)。思考下面这个对于员 表的查询语句,该语句将返回员 姓名、 资和联邦税,过滤条件是薪水的减免税款超过0. 2 (20%): hive> SELECT name, salary, deductions[‘Federal Taxes’] >](https://slidetodoc.com/presentation_image_h2/fa78074db161d2c1091b295e30ad241c/image-69.jpg "关于浮点数比较的一个常见陷阱出现在不同类型间作比较的时候(也就是FLOAT和 DOUBLE比较)。思考下面这个对于员 表的查询语句,该语句将返回员 姓名、 资和联邦税,过滤条件是薪水的减免税款超过0. 2 (20%): hive> SELECT name, salary, deductions[‘Federal Taxes’] >")





会返回右边表所有符合WHERE语句的记录。左 表中匹配不上的字段值用NULL代替。 • 这里我们调整下stocks表和divideneds表的位置来执行右外连接,并保留 SELECT语句不变: hive> SELECT s.")

























































































- Slides: 188
CONTENTS ITEMS 1 ITEMS 2 3 ITEMS 4 HBase介绍 Hive. QL表操作 Hive结构 Hive. QL数据操作 国家级 程实践教育中心
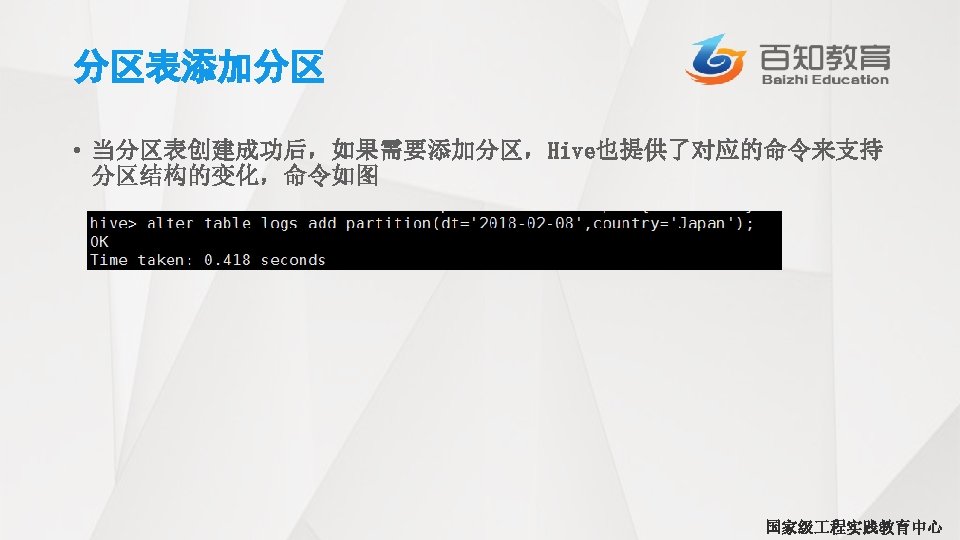
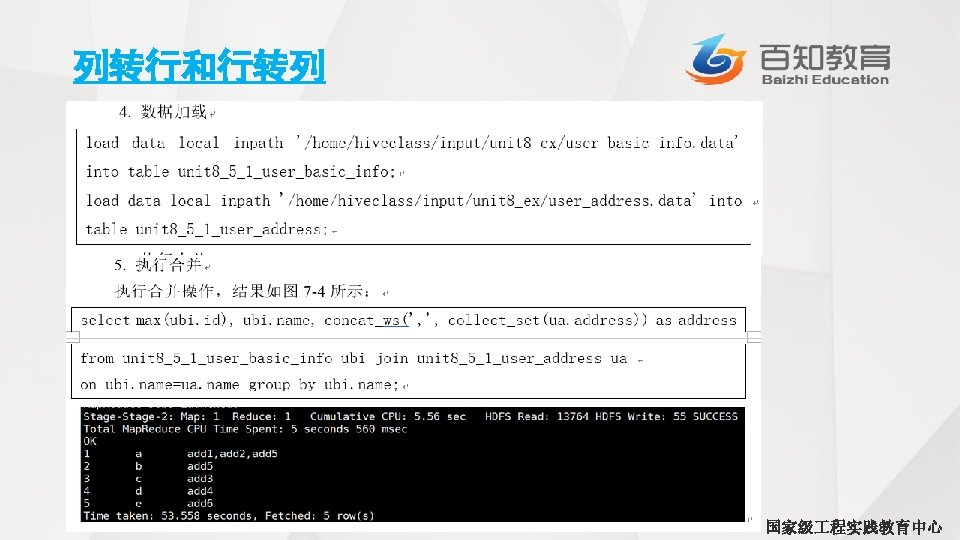
4. 2 通过查询语句向表中插入数据 • INSERT语句允许用户通过查询语句向目标表中插入数据。具体实例如下所示: INSERT OVERWRITE TABLE employees PARTITION (country=’US’, state=’OR’) SELECT * from employees_tmp et WHERE et. cnty = ‘US’ AND et. st = ‘OR’; 国家级 程实践教育中心
5. 1 SELECT…FROM语句 • SELECT是SQL中的射影算子,FROM子句标识了从哪个表、视图或嵌套查询中选择记 录。对于一个给定的记录,SELECT指定了要保存的列以及输出函数需要调用的一个 或多个列(例如,像count(*)这样的聚合函数)。假设有一个employees表: CREATE TABLE employees( name STRING, salary FLOAT, subordinates ARRAY<STRING>, deductions MAP<STRING, FLOAT>, address STRUCT<street: STRING, city: STRING, state: STRING, zip: INT> ) PARTITIONED BY (country STRING, state STRING); 国家级 程实践教育中心
SELECT…FROM语句 • 下面是对这个表进行的查询语句以及其输出内容如下: hive> SELECT name, salary FROM employees; John Doe 100000. 0 Mary Smith Todd Jones Bill King 80000. 0 70000. 0 60000. 0 国家级 程实践教育中心
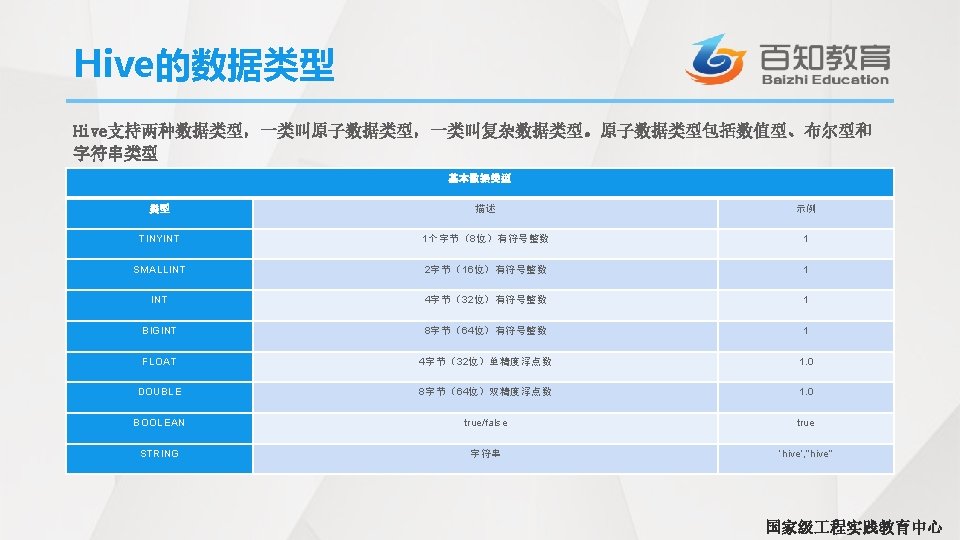
使用函数 • 数学函数 Hive内置数学函数, 详情请参照书本 返回值类型 样式 描述 BIGINT round(DOUBLE d) 返回DOUBLE型d的BIGINT类型的近似值 DOUBLE round(DOUBLE d, INT n) 返回DOUBLE型d的保留n位小数的DOUBLE型的近似值 BIGINT floor(Dd. UBLE d) d是DOUBLE类型的,返回<=d的最大BIGINT型值 BIGINT ceil(DOUBLE d) ceiling (DOUBLE d) d是DOUBLE类型的,返回>=d的最小BIGINT型值 国家级 程实践教育中心
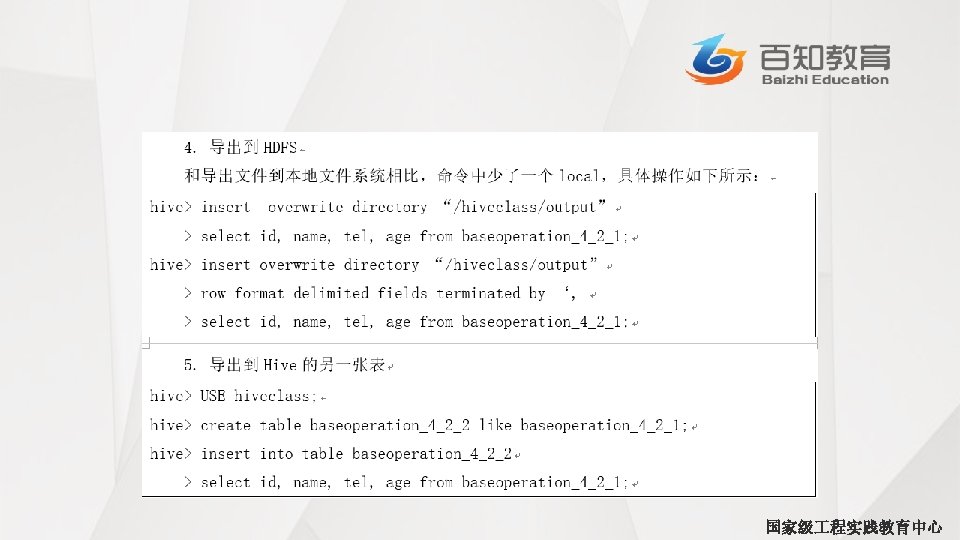
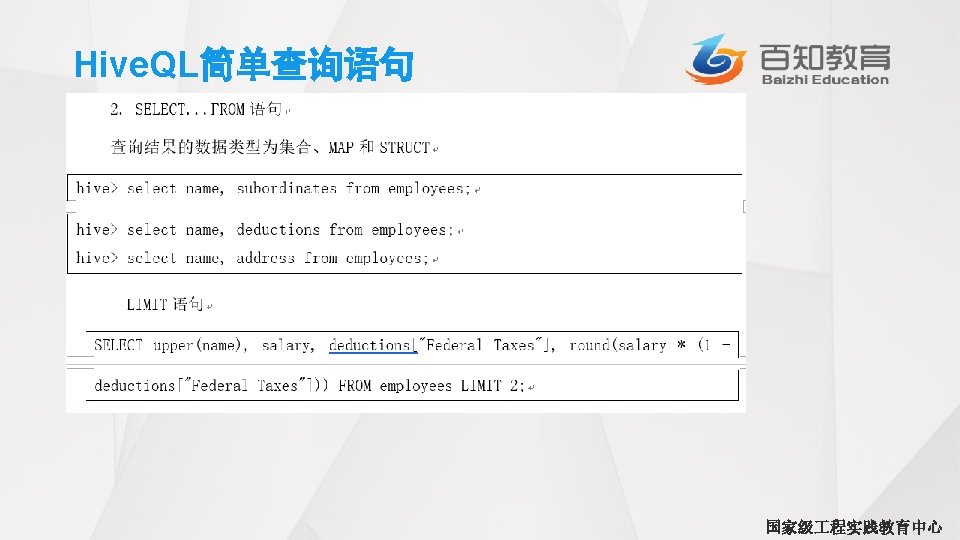
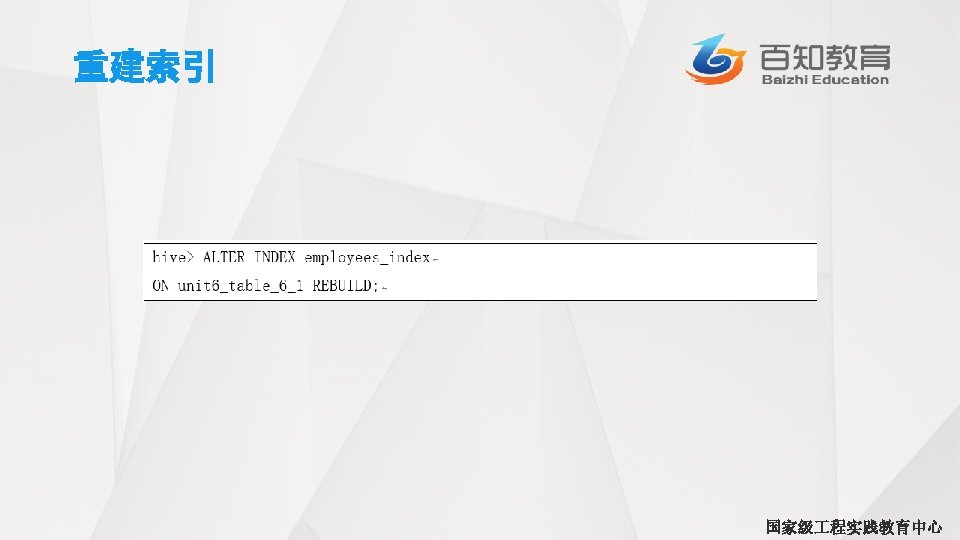
LIMIT语句 • 典型的查询会返回多行数据。LIMIT子句用于限制返回的行数 hive> SELECT upper (name),salary, deductions["Federal Taxes"], >round (salary*(1 -deductions["Federal Taxes"])) FROM employees >LIMIT 2; JOHN DOE MARY SMITH 100000. 0 0. 2 80000. 0 0. 2 69000 国家级 程实践教育中心
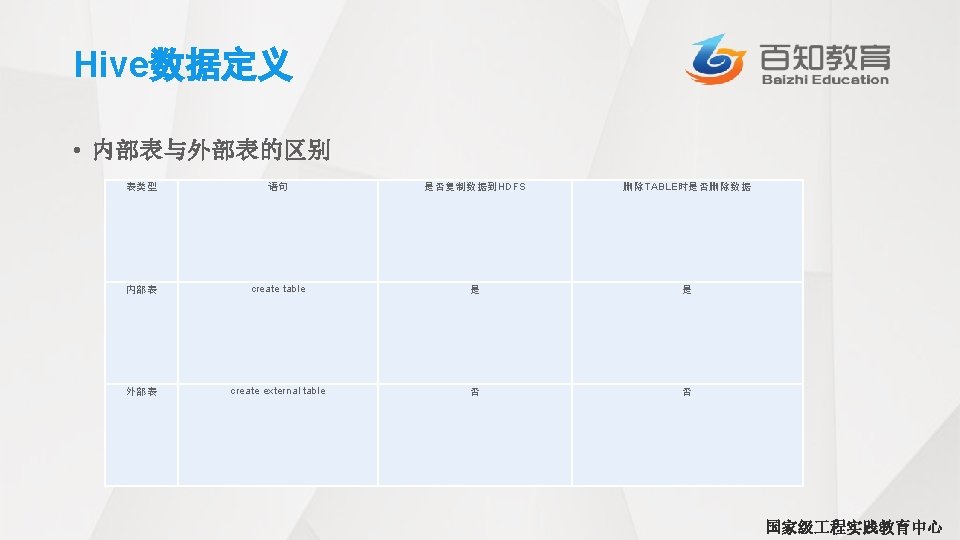
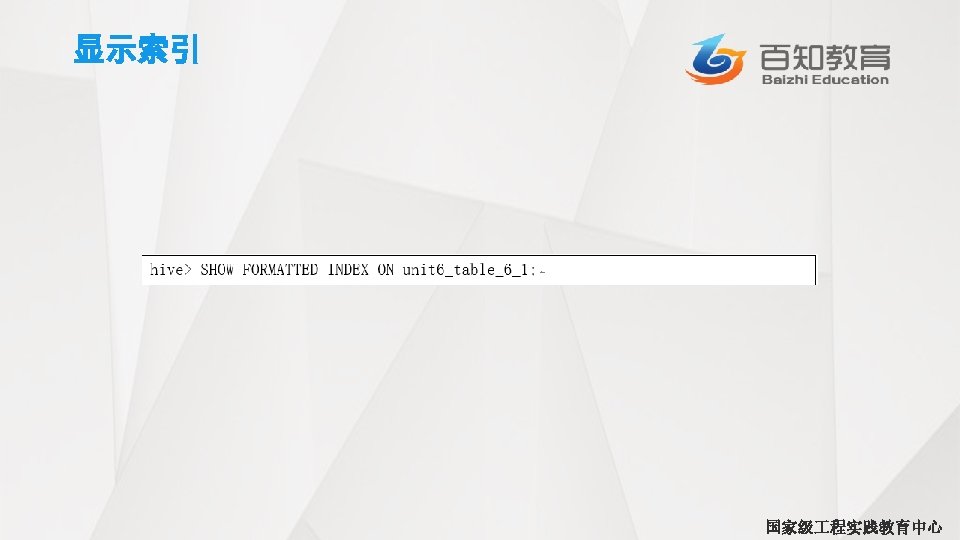
列别名 • 为第 3个和第 4个字段起了别名,别名分别为fed_taxes和 salary_minuses_fed_taxes。 hive> SELECT upper(name) , salary, deductions["Federal Taxes"]as fed taxes, > round (salary*(1 -deductions["Federal Taxes"])) as salary_minus_fed_taxes > FROM employees LIMIT 2; JOHN DOE 100000. 0 MARY SMITH 80000. 0 0. 2 80000. 0 64000 国家级 程实践教育中心
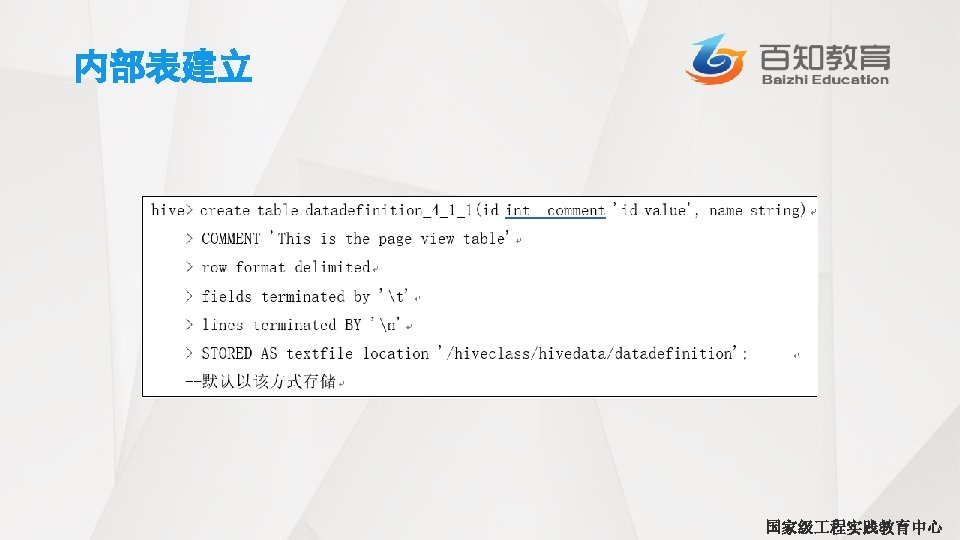
嵌套SELECT语句 • 对于嵌套查询语句来说,使用别名是非常有用的。下面,我们使用前面的示 例作为一个嵌套查询: hive> FROM > SELECT upper(name), salary, deductions["Federal Taxes"] as fed taxes, > round(salary*(1 -deductions["Federal Taxes"]))as salary_minus_fed_taxes > FROM employees > ) e > SELECT e. name, e. salary_minus_ fed_ taxes > 70000; JOHN DOE 100000. 0 0. 2 80000 国家级 程实践教育中心
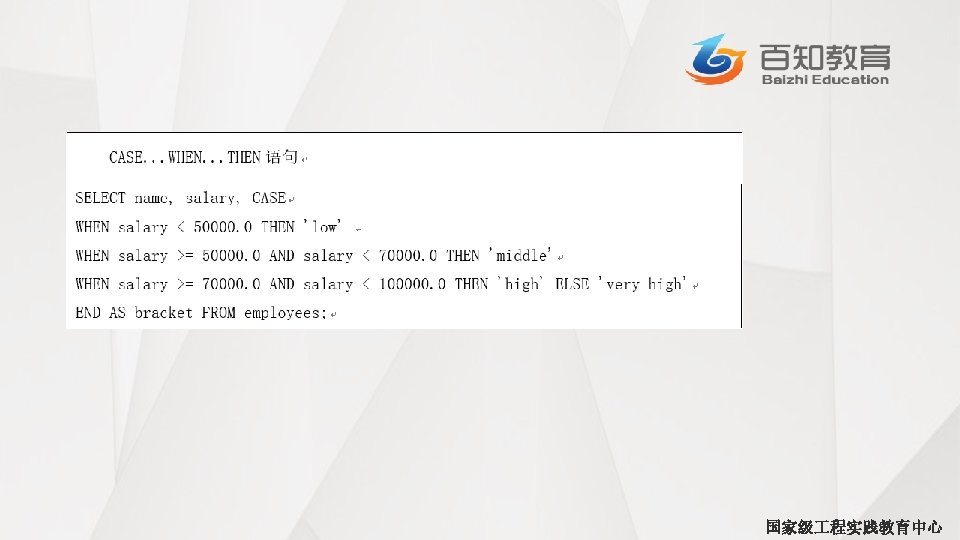
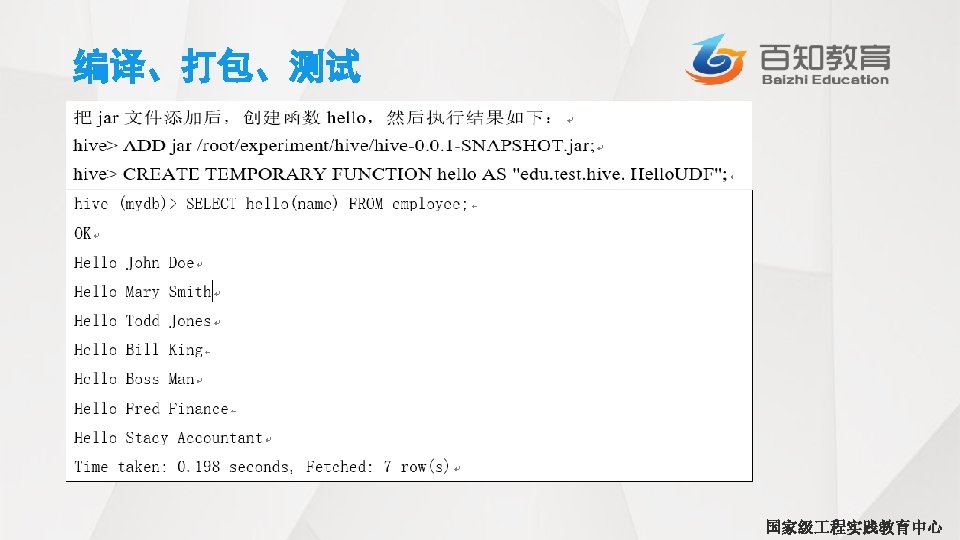
CASE…WHEN…THEN句式 • CASE. . . WHEN. . . THEN语句和if条件语句类似,用于处理单个列的查询结果。例如: hive> SELECT name, salary, > CASE > WHEN salary<50000. 0 THEN ’low’ > WHEN salary>=50000. 0 AND salary<70000. 0 THEN 'middle’ > WHEN salary>=70000. 0 AND salary<100000. 0 THEN ’high’ > ELSE ’very high’ > END AS bracket FROM employeest; John Doe 100000. 0 very high Mary Smith 80000. 0 high Todd Jones 70000. 0 high Bill King 60000. 0 middle Boss Man 200000. 0 very high Fred Finance 150000. 0 very high Stacy Accountant 60000. 0 middle 国家级 程实践教育中心
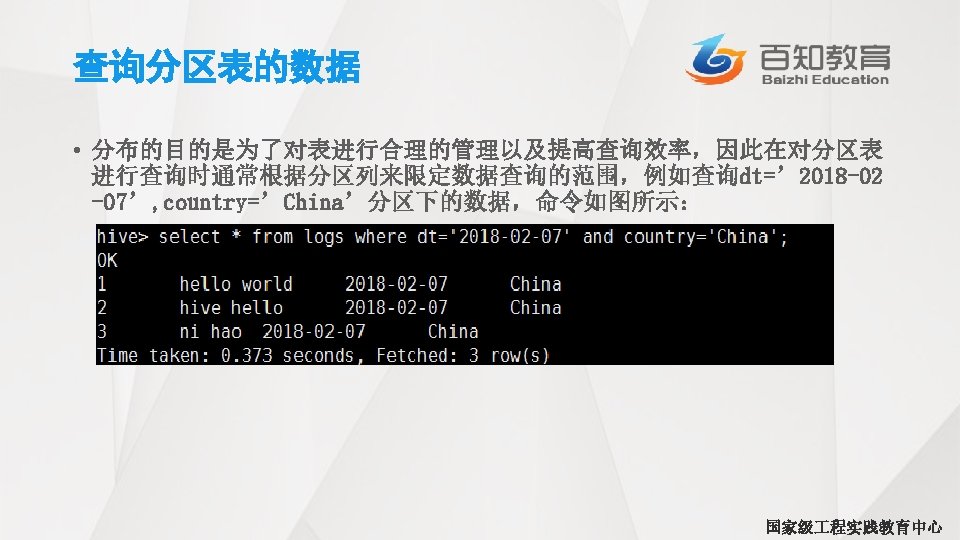
WHERE语句 SELECT * FROM employees WHERE country = 'US’ AND state=’CA’; • 谓词可以引用和SELECT语句中相同的各种对于列值的计算。这里我们修改下 之前的对于联邦税收的查询,过滤保留那些 资减去联邦税后总额大于 70, 000的查询结果: hive> SELECT name, salary, deductions["Federal Taxes"], > salary*(1 -deductions["Federal Taxes"]) > FROM employees > WHERE round(salary*(1 -deductions["Federal Taxes"]))>70000; John Doe 100000. 0 0. 2 80000. 0 国家级 程实践教育中心
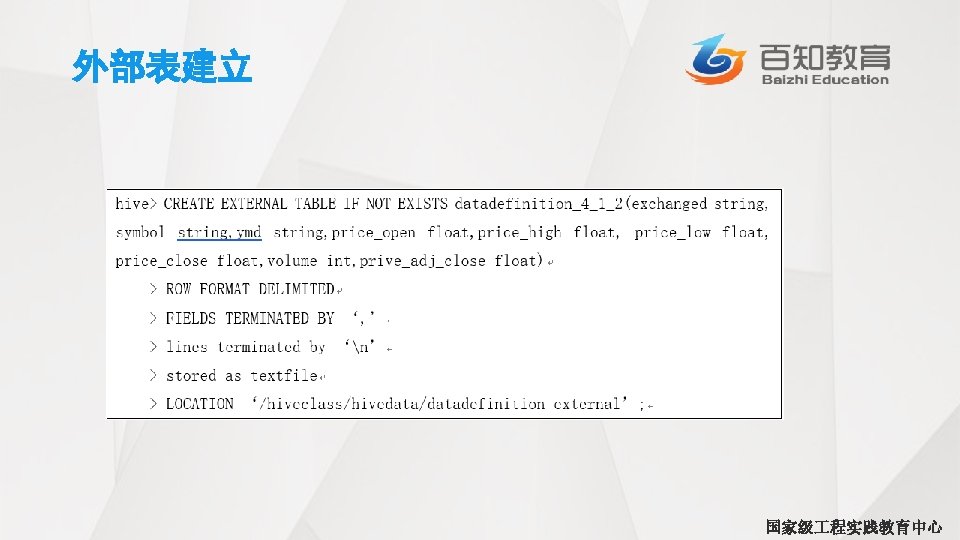
关于浮点数比较的一个常见陷阱出现在不同类型间作比较的时候(也就是FLOAT和 DOUBLE比较)。思考下面这个对于员 表的查询语句,该语句将返回员 姓名、 资和联邦税,过滤条件是薪水的减免税款超过0. 2 (20%): hive> SELECT name, salary, deductions[‘Federal Taxes’] > FROM employees WHERE deductions [‘Federal Taxes’] > 0. 2; John Mary Boss Fred Doe 100000. 0 Smith 80000. 0 Man 200000. 0 Finance 150000. 0 0. 2 0. 3 国家级 程实践教育中心
LIKE和RLIKE • 下面 3个查询依次分别选择出了住址中街道是以字符串Ave结尾的雇员名称和住址、 城市是以O开头的雇员名称和住址和街道名称中包含有Chicago的雇员名称和住址: hive> SELECT name, address. street FROM employees WHERE address. street LIKE ‘%Ave. ’; John Doe 1 Michigan Ave. Todd Jones 200 Chicago Ave. hive> SELECT name, address. city FROM employees WHERE address. city LIKE ‘O%’; Todd Jones Oak Park Bill King Obscuria hive> SELECT name, address. street FROM employees WHERE address. street LIKE ‘%Chi%’; Todd Jones 200 Chicago Ave 国家级 程实践教育中心
LEFT OUTER JOIN • 左外连接通过关键字LEFT OUTER进行标识: hive> SELECT s. ymd, s. symbol, s. price_close, d. dividend > FROM stocks s LEFT OUTER JOIN dividends d ON s. ymd=d. ymd AND s. symbol=d. symbol > WHERE s. symbol=’AAPL’; 1987 -05 -01 AAPL 80. 0 NULL 1987 -05 -04 AAPL 79. 75 NULL 1987 -05 -05 AAPL 80. 25 NULL 国家级 程实践教育中心
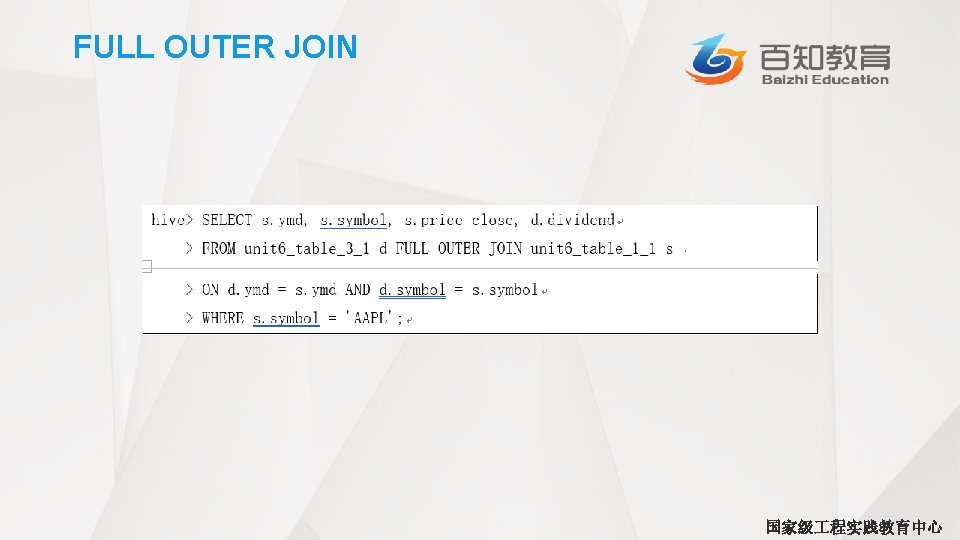
RIGHT OUTER JOIN • 右外连接(RIGHT OUTER JOIN)会返回右边表所有符合WHERE语句的记录。左 表中匹配不上的字段值用NULL代替。 • 这里我们调整下stocks表和divideneds表的位置来执行右外连接,并保留 SELECT语句不变: hive> SELECT s. ymd, s. symbol, s. price_close, d. dividend > FROM dividends d RIGHT OUTER JOIN stocks s ON d. ymd=s. ymd AND d. symbol=s. symbol > WHERE s. symbol=’AAPL’ 1987 -05 -07 AAPL 80. 25 NULL 1987 -05 -08 AAPL 79. 0 NULL 1987 -05 -11 AAPL 77. 0 0. 015 国家级 程实践教育中心
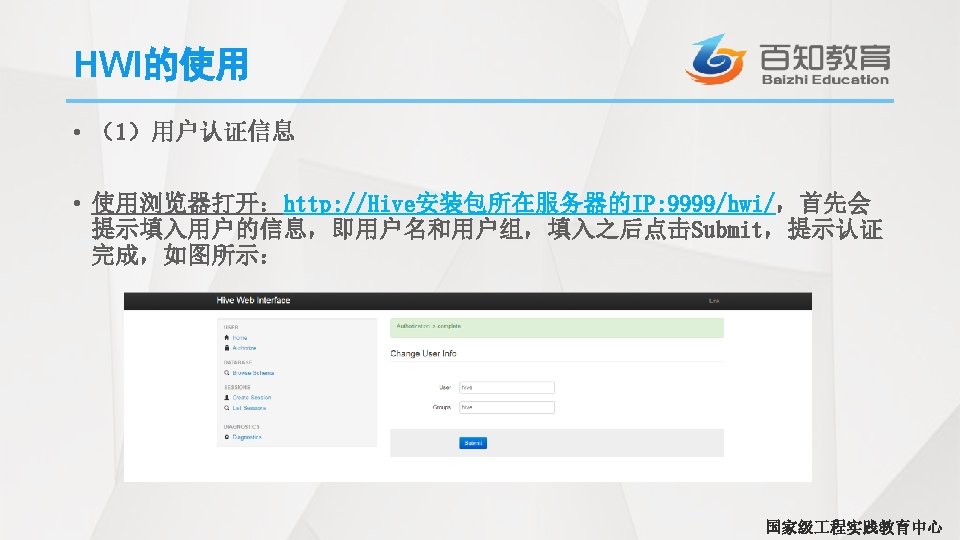
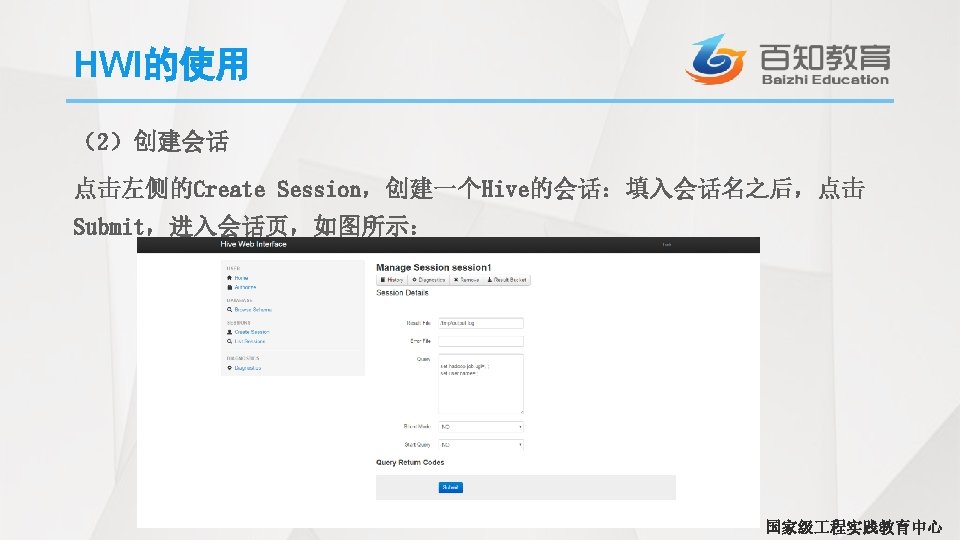
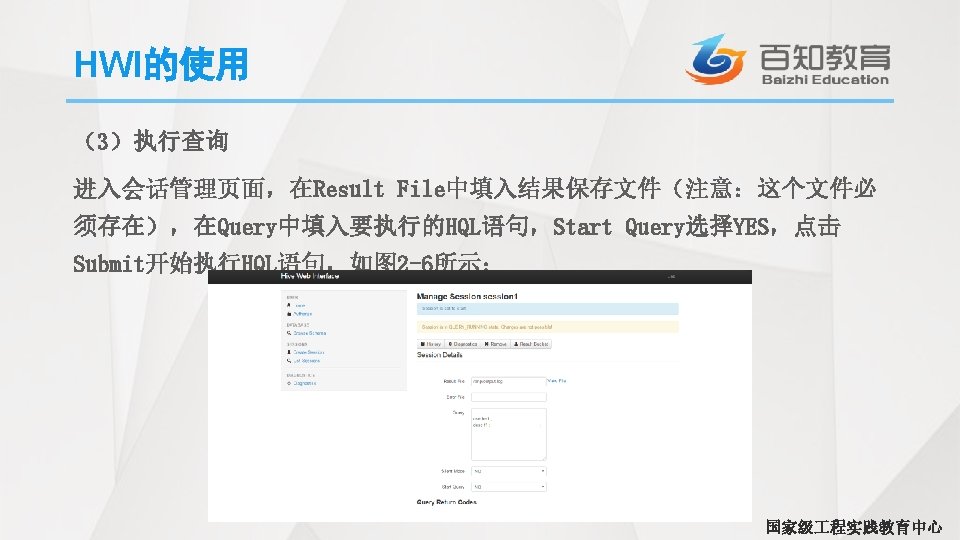
Hive启动WEB界面 • 首先需要下载一个hwi. war包,这里我们去Hive的源码包中打包一个自己的 hwi. war包,具体操作如下所示: # tar -zxvf apache-hive-1. 2. 1 -src. tar. gz # cd apache-hive-1. 2. 1 -src/hwi # jar cvf. M 0 hive-hwi-my. war -C web/. # mv hive-hwi-my. war /root/apache-hive-1. 2. 1 -bin/hive-hwi-my. war • 修改配置文件hive-site. xml # cd $HIVE_HOME/conf # vim hive-site. xml 国家级 程实践教育中心
6. 3 Hive基本操作 • • Hive CLI命令行操作 hive> CREATE DATABASE financial; hive> CREATE DATABASE financial IF NOT EXISTS financial; hive> SHOW DATABASES LIKE 'f. *'; hive> CREATE DATABASE financial LOCATION '/user/hive/mywarehouse'; hive> CREATE DATABASE financial COMMENT 'Holds all financial tables'; • hive> DESCRIBE DATABASE financial; • hive> CREATE DATABASE financial • > WITH DBPROPERTIES ('creator' = 'hive', 'date' = '2018 -2 -23'); 国家级 程实践教育中心
Hive CLI命令行操作 • • hive> DESCRIBE DATABASE EXTENDED financial; hive> USE default; hive> set hive. cli. print. current. db=true; hive> DROP DATABASE IF EXISTS financial CASCADE; hive> ALTER DATABASE financial set DBPROPERTIES ('created by' = 'bjqg'); • hive> DESCRIBE DATABASE FORMATTED financial; 国家级 程实践教育中心
Hive数据导入 • load data local inpath '/home/hiveclass/input/baseoperation_4_1. data' into table baseoperation_4_1_1; 国家级 程实践教育中心