Contentbased Video Indexing Classification Retrieval Presented by HOI

Content-based Video Indexing, Classification & Retrieval Presented by HOI, Chu Hong Nov. 27, 2002

Outline n n n Motivation Introduction Two approaches for semantic analysis A probabilistic framework (Naphade, Huang ’ 01) ¨ Object-based abstraction and modeling [Lee, Kim, Hwang ’ 01] ¨ n n A multimodal framework for video content interpretation Conclusion

Motivation n n There is an amazing growth in the amount of digital video data in recent years. Lack of tools for classify and retrieve video content There exists a gap between low-level features and high-level semantic content. To let machine understand video is important and challenging.

Introduction n Content-based Video indexing ¨ the process of attaching content based labels to video shots ¨ essential for content-based classification and retrieval ¨ Using automatic analysis techniques - shot detection, video segmentation - key frame selection - object segmentation and recognition - visual/audio feature extraction - speech recognition, video text, VOCR

Introduction n Content-based Video Classification ¨ Segment & classify videos into meaning categories ¨ Classify videos based on predefined topic ¨ Useful for browsing and searching by topic ¨ Multimodal method n n Visual features Audio features Motion features Textual features ¨ Domain-specific knowledge

Introduction n Content-based Video Retrieval ¨ Simple visual feature query n ¨ Feature combination query n ¨ Retrieve video with a running car toward right Object relationship query n ¨ Retrieve video which is similar to example Localized feature query n ¨ Retrieve video with high motion upward(70%), Blue(30%) Query by example (QBE) n ¨ Retrieve video with key-frame: Color-R(80%), G(10%), B(10%) Retrieve video with a girl watching the sun set Concept query (query by keyword) n Retrieve explosion, White Christmas

Introduction n Feature Extraction ¨ Color features ¨ Texture features ¨ Shape features ¨ Sketch features ¨ Audio features ¨ Camera motion features ¨ Object motion features

Semantic Indexing & Querying n Limitation of QBE Measuring similarity using only low-level features ¨ Lack reflection of user’s perception ¨ Difficult annotation of high level features ¨ n Syntactic to Semantic Bridge the gap between low-level feature and semantic content ¨ Semantic indexing, Query By Keyword (QBK) ¨ n Semantic description scheme – MPEG-7 Semantic interaction between concepts ¨ no scheme to learn the model for individual concepts ¨
 ¨")
Semantic Modeling & Indexing n Two approaches ¨ Probabilistic framework, ‘Multiject’ (Naphade’ 01) ¨ Object-based abstraction and indexing [Lee, Kim, Hwang ’ 01]
 (Naphade, Huang ’ 01) a probabilistic multimedia object")
A probabilistic approach (‘Multiject’ & ‘Multinet’) (Naphade, Huang ’ 01) a probabilistic multimedia object n 3 categories semantic concepts n ¨ Objects n Face, car, animal, building ¨ Sites n Sky, mountain, outdoor, cityscape ¨ Events n Explosion, waterfall, gunshot, dancing
 = 0.")
Multiject for semantic concept P( Outdoor = Present | features, other multijects) = 0. 7 Outdoor Visual features Audio features Other multijects Text features

How to create a Multiject n n Shot-boundary detection Spatio-temporal segmentation of within-shot frames Feature extraction (color, texture, edge direction, etc ) Modeling ¨ Sites: mixture of Gaussians ¨ Events: hidden Markov models (HMMs) with observation densities as gaussian mixtures ¨ All audio events: modeled using HMMs ¨ Each segment is tested for each concept and the information is then composed at frame level

Multiject : Hierarchical HMM ss 1 - ssm : state sequence for supervisor HMM sa 1 - sam : state sequence for audio HMM xa 1 - xam : audio observations sv 1 - svm : state sequence for video HMM xv 1 - xvm : video observations

Multinet: Concept Building based on Multiject • A network of multijects modeling interaction between them • + / - : positive/negative interaction between multijects
 • Layer 0")
Bayesian Multinet • Nodes : binary random variables (presence/absence of multiject) • Layer 0 : frame-level multiject-based semantic features • Layer 1 : inference from layer 0 : • Layer 2 : higher level for performance improvement

Object-based Semantic Video Modeling Video Sequence VO Extraction Object-based Video Abstraction Object-based Low-Level Feature Extraction Semantic Features Modeling Indexing /Retrieving
![Object Extraction based on Object Tracking [Kim, Hwang ‘ 00] In In-1 von-1 Motion](http://slidetodoc.com/presentation_image/024aef812e034a4450c6d4b4f60901eb/image-17.jpg "Object Extraction based on Object Tracking [Kim, Hwang ‘ 00] In In-1 von-1 Motion")
Object Extraction based on Object Tracking [Kim, Hwang ‘ 00] In In-1 von-1 Motion Projection Model Update (Histogram Backprojection) Object Post-processing von delay

Semantic Feature Modeling Abstracted frame sequence - Preprocessing Object Features HMM Training Modeling based on temporal variation of object features Boundary shape and motion statistics of object area

HMM Modeling 1. Observation Sequence O 1 ……. OT . . object features 2. Left-Right 1 -D HMM modeling S 1 S 2 …. . ST

Video Modeling: Three Layer Structure Three layer structure of video modeling, compared to NLP Video Understanding Natural Language Processing Content Interpretation Semantic Video Modeling Frame-based Structural Modeling Audio-Visual Feature Extraction Interpretation Object-based Structural Modeling Sentence Structure & grammar Word Recognition

A Multimodal Framework for Video Content Interpretation n n Long-term goal Application on automatic TV Programs Scout Allow user to request topic-level programs Integrate multiple modalities: visual, audio and Text information Multi-level concepts ¨ ¨ ¨ n Low: low-level feature Mid: object detection, event modeling High: classification result of semantic content Probabilistic model, Using Bayesian network for classification (causal relationship, domain-knowledge)
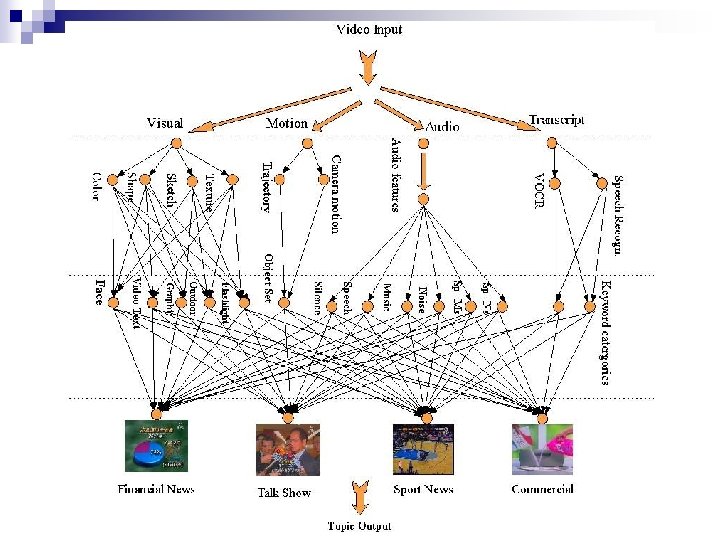

How to work with the framework? n Preprocessing ¨ ¨ ¨ n Story segmentation (shot detection) VOCR, Speech Recognition Key frame selection Feature Extraction ¨ Visual features based on key-frame n ¨ Audio features n ¨ n Knowledge tree, a lot of keyword categories: politics, entertainment, stock, art, war, etc. Word spotting, vote histogram Motion features n n average energy, bandwidth, pitch, mel-frequency cepstral coefficients, etc. Textual features (Transcript) n ¨ Color, texture, shape, sketch, etc. Camera operation: Panning, Tilting, Zooming, Tracking, Booming, Dollying Motion trajectories (moving objects) Object abstraction, recognition Building and training the Bayesian network

Challenging points n Preprocessing is significant in the framework. ¨ Accuracy of key-frame selection ¨ Accuracy of speech recognition & VOCR n n n Good feature extraction is important for the performance of classification. Modeling semantic video objects and events How to integrate multiple modalities still need to be well considered.

Conclusion Introduction of several basic concepts n Semantic video modeling and indexing n Propose a multimodal framework for topic classification of Video n Discussion of Challenging problems n

Q&A Thank you!
- Slides: 26