Consensus Partition Liang Zheng 6 25 Outline Motivation





 – A (partial) function from Wk to")


= k i<j ( c(i)c(j)S(k, i, j)+(1 - c(i)c(j))L(k, i, j)) =")


. •")






 • the resulting consensus partition are")
 • Compactness measures the average")
 • R=A/(A+C) • A: the")


 • also measured the running time")


 and 3 evaluation questions(given below)")


![2 -Effectiveness Study Process • [GA: T 1 GB: T 2] [GB: T 1](https://slidetodoc.com/presentation_image_h/37f28c22fd8363e476c809b1413e3f5f/image-31.jpg "2 -Effectiveness Study Process • [GA: T 1 GB: T 2] [GB: T 1")




- Slides: 36
Consensus Partition Liang Zheng 6. 25
Outline • Motivation • Problem formulation • Optimization Method • Experiment study • Conclusion
Motivation • When viewing a entity aggregation of plenty of sources in a single entity profile, different properties often express the same thing. • To consolidate(merge/align) the potentially large and chaotic list of properties into a simpler list that is more meaningful to the user in order to enhance the user experience. • a: Consider the last segment of the property URI; b: Check the definition of the property (obtainable by dereferencing its URI) for an rdfs: label. properties alignment • Aligned process based on mass participation, which to be a assistant method.
• The problem – How to preserve personal alignment for each user? – How to improve (optimize) the public alignment according to users’ alignments? • Global alignment (Representation) • User’s alignment (Representation)
• Global alignment: an equivalence relation on W – A function from W to {0} N (c: W {0} N) 注:W上的等价关系,即 W×W的子集
• User’s alignment (k=1. . m) – A (partial) function from Wk to {0, k} N (ck: Wk {0, k} N) • Personalized alignment – ck c|W-Wk : W {0, k} N
Optimizing the global alignment • Input: a family of users’ partitions {ck} • Output: an optimal partition P* on Wk What Means a optimal Partition P* ? symmetric difference distance • Consider two objects u and v in V. The following simple 0/1 distance function checks if two partitions P 1 and P 2 agree on the clustering of u and v.
Problem formulation • Formal Definition – Given a set of objects V and m partitions {P 1 , P 2 , . . . , Pm} on V. – find a consensus partition P* that minimizes d(P* , Pi ) 9
kd(c, ck)= k i<j ( c(i)c(j)S(k, i, j)+(1 - c(i)c(j))L(k, i, j)) = i<j ( c(i)c(j) k. S(k, i, j) +(1 - c(i)c(j)) k. L(k, i, j)) = i<j ( c(i)c(j) qi, j +(1 - c(i)c(j)) pi, j) • = i<j pi, j - i<j c(i)c(j) (pi, j-qi, j) • • • max i<j c(i)c(j) (pi, j-qi, j) • pi, j - qi, j = 2 pi, j - m’ 这里的 d(c, ck), 距离是用对称差度量, minimizing d(c, Ck). S(k, i, j): i and j are separated in Ck L(k, i, j): i and j are joined in Ck. qi, j : the number of partitions in which two elements i and j are separated pi, j: the number of partitions in which two elements i and j are joined =2 m’(pi, j/m’-1/2) (pi, j + qi, j = m’ 0 < m’ m) w(i, j) = pi, j/m’-1/2 max i<j c(i)c(j) w(i, j) = pi, j/m’-1/2 • 直观解释:即有序对(I, j), 在所有关注 I 和 j 用户中,有超过一半的人表达“i and j are joined ”
Optimal Solution • By enumeration • Let X be a set of n elements, given an optimal solution enumerating partitions P of X. • generates all partitions P over X -k-partition(n≥k); S(n, k): Stirling number of the second kind. -Bell number • Select a partition P* P that minimizes D= d(P* , Pi) • This optimization problem is NP- complete. (Barthelemy et al, 1995. )
Optimization problem can be represented by the weighted graph of clique partitioning problem(CPP). • complete graph G = (V, E, W). • W: weights for the edges (xi , xj). w(i, j) = pi, j/m’-1/2 • Let P be a partition into p classes. P = (X 1, . . . , Xp) • seek a set of disjoint cliques in (Kn , W), having a maximum total weight. These disjoint cliques must cover X to make a partition that is median partition • 注: (− 1/2 w (i, j) 1 /2)
Our approach • input : Π ={P 1, P 2, . . . , Pm} ; output: a partition P • Construct weighted complete graph GR = (V, E, W). V=∪Pk, w(i, j) = pi, j/m’-1/2. ( pi, j: the number of partitions in which two elements i and j are joined; m’: the number of partitions in which two elements i and j are joined and separated; ) • create super-graph G’(S, E’, W’) ; S=V, E’=E, W’=W. • 核心思想(类似层次聚类) • Element做为图的顶点;边的权重为pi, j/m’-1/2 • 选择边集的权重最大并大于0的边,删除边并合并两个端 点做为新的顶点,重新调整相关边的权重 • 重复,直至边集中边的权重全部小于0
while E’≠ foreach e’i, j E’ find a edge e’i, j E’ and w’(i, j) is positive value and maxweight in W’ Common. Set=Common. Neighbor(G’, si , sj ) //公共邻接顶点集合 sij = si∪sj ; ; S=S- si- sj ; S=S∪sij E’=Delete. Edge(E’, si) ; E’=Delete. Edge(E’, sj) foreach sk Common. Set do E’= E’ ∪{e’k, ij } w’(k, ij)=avg{w’(k, i), w’(k, j)} //边权值调整,取边权值的平均值 endfor endwhile return P=S Complexity of Algorithm is O(mn 2)+O(n 2) O(mn 2):初始建图; O(n 2):算法
Example: V={1, 2, 3, 4, 5, 6}; P={P 1, P 2 , P 3 , P 4 } ; P 1={{1, 2}, {3, 4}, {5, 6}}; P 2={{1, 2, 4}, {3, 5, 6}} ; P 3={{1, 2, 5, 6}, {3, 4}} ; P 4={{1, 2, 5}, {3, 4, 6}} The input distance matrix [Wuv ] 1 1 2 3 4 5 6 0 1/2 -1/4 0 -1/2 -1/4 0 1/4 -1/4 0 0 -1/2 -1/4 0 1/4 2 3 4 5 6 1 : 2 : 0 Noise data 3 :
Experiment study • Simulated Study --- compare four algorithms on 7 data sets • Real-World Study --- evaluation of our approach
Simulated Study • compare four algorithms on 7 data sets, 4 of simulated and 3 of real data. • All four simulated data sets, R 0, …, R 3 consist of 10 random setpartitions. • The number of elements in the set-partition is n=10, 50, 100, 200 respectively. • A set-partition include 10 classes at most. (Medium number of partition. Guénoche 2011) • The three real datasets from UCI Machine Learning dataset, include labor-relation, Iris and Glass.
Simulated Study Evaluation Criteria 1. Consensus Criteria • Average distances 2. Clustering Criteria(the quality of Consensus Partition, CP ) • Compactness • Recall 3. Run-time
Simulated Study Evaluation Criteria 1: Average distances(Filkov, 2004) • the resulting consensus partition are summarized by average sum of distances to the given set-partitions • Avg. SOD=D/(C(n, 2) m)
Simulated Study Evaluation Criteria 2 -1: Compactness (Nguyen, 2007) • Compactness measures the average pairwise distances between points in the same cluster 注:d(xi , xj)=|{ i |1 i m and Pi(xi) = Pi(xj) }| / m :CP ; Ck : equivalence class ; nk : |Ck| 特殊情况: =1,全体用户划分只有一个等价类 =0:全体用户划分中单个元素作为一个等价类
Simulated Study Evaluation Criteria 2 -2: Recall (Euzenat, 2007) • R=A/(A+C) • A: the number of pair produced by the CP, which has a positive contribution when both elements are equivalent in more than half of the users preference partitions. • A+C: the number of pair which has a positive contribution when both elements are equivalent in more than half of the users preference partitions. Equivalence. Not Equivalence relation computed A B Non-computed C D 注:借鉴Ontology Alignment Evaluation Recall用来刻画CP得到的等价关系对,覆盖到应当得到的等价关系对(超过一半人 认可的等价关系对)的比例
Data. Set n R 0 10 R 1 50 R 2 100 R 3 200 labor 57 Iris 150 Glass 214 Enumeration m k 10 10 50 50 50 4 5 10 10 5 8 10 Comp Avg. S Rec actne OD all ss 0. 42 0. 44 1 Best. Clustering Bottom. Up Avg. S Compa Reca Avg. S Compa Rec OD ctness ll OD ctness all 0. 6 0. 55 0. 33 0. 32 0. 35 0. 18 0. 22 0. 26 0. 28 0. 19 0. 743 0. 9 0. 664 0. 3 0. 5 0. 6 0. 5 0. 9 0. 42 0. 39 0. 2 0. 15 0. 09 0. 19 0. 24 0. 12 0. 018 0. 839 0. 873 0. 5 0. 1 1 0. 9 0. 6 Best. Clustering+ One. Move Comp Avg. Rec actnes SOD all s 0. 5 0. 43 1 0. 5 0. 29 0. 6 0. 3 0. 19 0. 7 0. 3 0. 93 0. 6 0. 1 0. 91 0. 8 0. 2 0. 74 0. 9 Bottom. Up+One. M ove Avg. S Compa Reca OD ctness ll 0. 42 0. 39 0. 2 0. 15 0. 09 0. 18 0. 24 0. 12 0. 018 0. 839 0. 843 0. 5 0. 1 1 0. 9 0. 7
Simulated Study Evaluation Criteria 3: Run-Time (GIONIS, 2005) • also measured the running time of the 4 algorithms for real datasets. • generate datasets of sizes 57, 150 , 214 and 500 points. Real dataset 140 120 100 Best. Clustering 80 sec Bottom. Up 60 Best. Clustering+One. Move Bottom. Up+One. Move 40 20 0 1 2 3 4
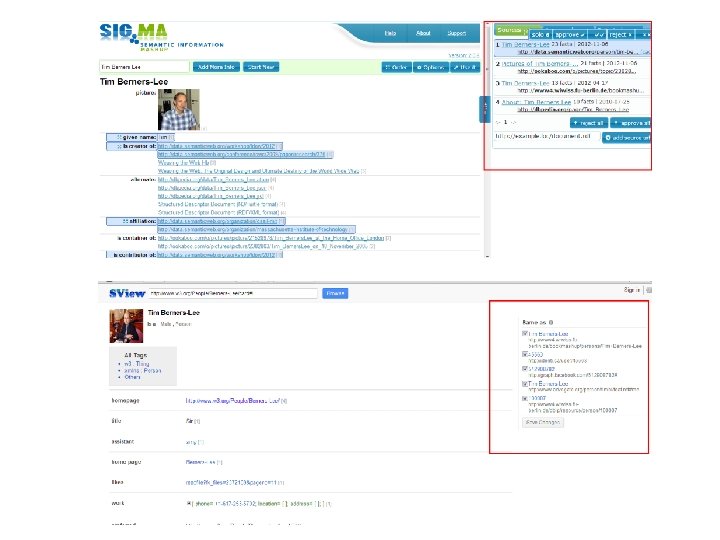
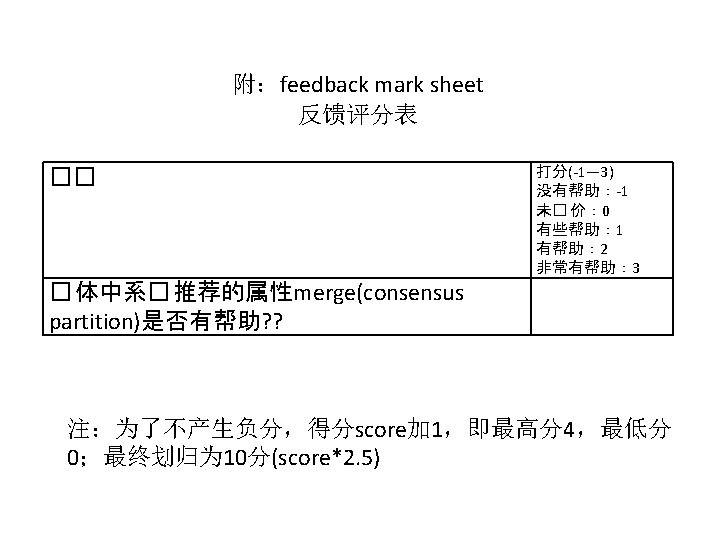
Experimental Design datasets DBpedia/Freebase/Linked. MDB: 5 common classes from different domain; For each class, select one entities which has 30 of properties at least. Participants • 20 people majoring in computer science. • None of them has previous experience with SView systems. • Divided into two groups with 10 persons in each group. • One group(GA) includes 10 freshmen. (casual users for SW) • the other group(GB) includes 7 graduate students and 3 teachers. (expert users for SW)
1 -Usability Study Task • Given 2 systems(SView/Sig. ma/) and 3 evaluation questions(given below) were chosen to range from simple to complex ones and to test systems' ability. • After testing each system, each user fill in a questionnaire(SUS form). 评测问题: • 用户通过关键字查询,得到自己感兴趣实体的一组 uri, 任选一个uri,浏览其内容 • 在当前实体浏览中,添加多个其他来源的同一实体 uri, 集中汇总式浏览 • 将认为语义相同的属性lable记录下,填写在问卷表 的反馈栏中
1 -Usability Study Results and Discussion SUS Scores Casual users Sview Sig. ma Expert users Total
2 -Effectiveness Study Task • T 1: Merge properties of one entities of each class according to user preference • T 2: Evaluate recommended consensus partition according to viewing one entity of each class, and fill out a feedback mark sheet.
2 -Effectiveness Study Process • [GA: T 1 GB: T 2] [GB: T 1 GA: T 2] 注:mutual evaluation[Jia 2009] • casual users做merge, expert users对CP评测; • expert users做merge, casual users对CP评测; • Process反映了expert users形成的共识对casual users是 否有帮助,或者相反。 • 目标:通过迭代循环的反馈,用户满意度提高
2 -Effectiveness Study Results and Discussion Feedback Scores Class 1 Class 2 Class 3 Class 4 Class 5 Total Casual users Expert users Total
Conclusion • Difficult Point: • How to prove effectiveness of our approach?
References • Guénoche A. Consensus of partitions: a constructive approach. Advances in Data Analysis and Classification, 2011, 5(3): 215 -229 • A. Gionis, H. Mannila and P. Tsaparas, Clustering aggregation, ACM Trans. Knowl. Discov. Data 1(1) (2007) 341 -352. • Filkov, V. and Skiena, S. 2003. Integrating microarray data by concensus clustering. In International Conference on Tools with Articial Inteligence. • N. Nguyen and R. Caruana, Consensus Clusterings, Proc. IEEE Int’l Conf. Data Mining, pp. 607 -612, 2007. • Ehrig, M. , Euzenat, J. : Relaxed precision and recall for ontology matching. In: Proceedings of the K-CAP 2005 Workshop on Integrating Ontologies (2005)
Thanks! Q&A