Conditional Generation by RNN Attention Outline Generation Attention

Conditional Generation by RNN & Attention

Outline • Generation • Attention • Tips for Generation • Pointer Network

Generation Generating a structured object component-by-component

Generation http: //youtien. pixnet. net/blog/post/4604096%E 6%8 E%A 8%E 6%96%87%E 6%8 E%A 5%E 9%BE%8 D%E 4%B 9%8 B%E 5%B 0%8 D%E 8%81%AF%E 9%81 %8 A%E 6%88%B 2 • Sentences are composed of characters/words • Generating a character/word at each time by RNN 床 sample P(w 1) 前 P(w 2|w 1) 明 月 P(w 3|w 1, w 2) P(w 4|w 1, w 2, w 3) …… …… <BOS> 床 前 明 w 1 w 2 w 3 ……

Consider as a sentence blue red yellow gray …… Generation Train a language model based on the “sentences” • Images are composed of pixels • Generating a pixel at each time by RNN red blue P(w 1) P(w 2|w 1) pink blue P(w 3|w 1, w 2) P(w 4|w 1, w 2, w 3) …… …… red <BOS> w 1 blue w 2 pink w 3 ……

Generation • Images are composed of pixels 3 x 3 images

Generation • Image • Aaron van den Oord, Nal Kalchbrenner, Koray Kavukcuoglu, Pixel Recurrent Neural Networks, ar. Xiv preprint, 2016 • Aaron van den Oord, Nal Kalchbrenner, Oriol Vinyals, Lasse Espeholt, Alex Graves, Koray Kavukcuoglu, Conditional Image Generation with Pixel. CNN Decoders, ar. Xiv preprint, 2016 • Video • Aaron van den Oord, Nal Kalchbrenner, Koray Kavukcuoglu, Pixel Recurrent Neural Networks, ar. Xiv preprint, 2016 • Handwriting • Alex Graves, Generating Sequences With Recurrent Neural Networks, ar. Xiv preprint, 2013 • Speech • Aaron van den Oord, Sander Dieleman, Heiga Zen, Karen Simonyan, Oriol Vinyals, Alex Graves, Nal Kalchbrenner, Andrew Senior, Koray Kavukcuoglu, Wave. Net: A Generative Model for Raw Audio, 2016

Conditional Generation • We don’t want to simply generate some random sentences. • Generate sentences based on conditions: Caption Generation “A young girl is dancing. ” Given condition: Chat-bot Given condition: “Hello” “Hello. Nice to see you. ”

Conditional Generation • Represent the input condition as a vector, and consider the vector as the input of RNN generator. (period) CNN woman A vector A Image Caption Generation <BOS> …… Input image
")
Sequence-tosequence learning Conditional Generation 機 器 學 Encoder 習 Jointly train Decoder . (period) Information of the whole sentences learning machine • Represent the input condition as a vector, and consider the vector as the input of RNN generator • E. g. Machine translation / Chat-bot

Conditional Generation M: Hello U: Hi M: Hi Need to consider longer context during chatting https: //www. youtube. com/watch? v=e 2 Mp. Omy. QJw 4 M: Hello U: Hi Serban, Iulian V. , Alessandro Sordoni, Yoshua Bengio, Aaron Courville, and Joelle Pineau, 2015 "Building End-To-End Dialogue Systems Using Generative Hierarchical Neural Network Models.

Attention Dynamic Conditional Generation
 器 learning 機 machine Information")
Dynamic Conditional Generation Encoder Decoder 學 習 . (period) 器 learning 機 machine Information of the whole sentences

Machine Translation • Attention-based model Jointly learned with other part of the network match What is match ? Design by yourself Cosine similarity of z and h Small NN whose input is z and h, output a scalar 機 器 學 習

Machine Translation 0. 5 machine • Attention-based model 0. 0 softmax Decoder input 機 器 學 習

Machine Translation match 機 器 學 習 machine • Attention-based model

0. 0 0. 5 softmax 機 器 學 習 learning 0. 0 machine • Attention-based model Decoder gets 1. Attended input (c) 2. Current decoding state (z) Machine Translation

Machine Translation learning machine • Attention-based model …… …… match …… 機 器 學 習 The same process repeat until generating. (period)

What is z? RNN Memory value RNN Output Transformed RNN output Etc.

Speech Recognition Decoder William Chan, Navdeep Jaitly, Quoc V. Le, Oriol Vinyals, “Listen, Attend and Spell”, ICASSP, 2016

Image Caption Generation A vector for each region CNN match 0. 7 filter filter filter

Image Caption Generation A vector for each region CNN filter filter Word 1 weighted sum 0. 1 0. 7 0. 1 0. 0 filter filter

Image Caption Generation A vector for each region CNN Word 1 Word 2 weighted sum filter filter 0. 8 0. 0 0. 2 0. 0 filter filter

Image Caption Generation Kelvin Xu, Jimmy Ba, Ryan Kiros, Kyunghyun Cho, Aaron Courville, Ruslan Salakhutdinov, Richard Zemel, Yoshua Bengio, “Show, Attend and Tell: Neural Image Caption Generation with Visual Attention”, ICML, 2015

Image Caption Generation Kelvin Xu, Jimmy Ba, Ryan Kiros, Kyunghyun Cho, Aaron Courville, Ruslan Salakhutdinov, Richard Zemel, Yoshua Bengio, “Show, Attend and Tell: Neural Image Caption Generation with Visual Attention”, ICML, 2015

Li Yao, Atousa Torabi, Kyunghyun Cho, Nicolas Ballas, Christopher Pal, Hugo Larochelle, Aaron Courville, “Describing Videos by Exploiting Temporal Structure”, ICCV,

Memory Network Sentence to vector can be jointly trained. Answer Extracted Information DNN gets 1. Query 2. Relevant database input …… Document vector Match q Query Sainbayar Sukhbaatar, Arthur Szlam, Jason Weston, Rob Fergus, “End-To-End Memory Networks”, NIPS, 2015

Memory Network Answer Extracted Information DNN content Jointly learned …… Hopping Key …… Document Match q Query

DNN Extract information …… …… Compute attention …… Memory Network Updated q Extract information …… …… Compute attention q a

Wei Fang, Juei-Yang Hsu, Hung-yi Lee, Lin-Shan Lee, "Hierarchical Attention Model for Improved Machine Comprehension of Spoken Content", SLT, 2016

Neural Turing Machine • von Neumann architecture Neural Turing Machine not only read from memory Also modify the memory through attention https: //www. quora. com/How-does-the-Von-Neumann-architectureprovide-flexibility-for-program-development

Neural Turing Machine y 1 h 0 f x 1 r 0 Retrieval process Long term memory

Neural Turing Machine y 1 h 0 f x 1 r 0 softmax

Neural Turing Machine • Real version
 0~1")
Neural Turing Machine (element-wise) 0~1

Neural Turing Machine y 2 y 1 h 0 h 1 f x 1 r 0 f x 2 r 1

Tips for Generation

Attention Kelvin Xu, Jimmy Ba, Ryan Kiros, Kyunghyun Cho, Aaron Courville, Ruslan Salakhutdinov, Richard Zemel, Yoshua Bengio, “Show, Attend and Tell: Neural Image Caption Generation with Visual Attention”, ICML, 2015 component time Bad Attention frame time w 1 w 2 (woman w 3 w 4 (woman) …… no cooking ) each input component has approximately the Good Attention: same attention weight E. g. Regularization term: For each component Over the generation

Mismatch between Train and Test • Training Reference: A Minimizing cross -entropy of each component : condition B A B A B <BOS> B A B Ground truth: <BOS>, A, B, B
")
Mismatch between Train and Test • Generation We do not know the reference (GT) Testing: Output of model is the input of the next step. A B A B Training: the inputs are reference (GT). <BOS> Exposure Bias A A B

A B A A One step wrong A B B A A May be totally A wrong B A A A B B A B A B B B 一步錯,步步錯 Never explore ……

Modifying Training Process? When we try to decrease the loss for both step 1 and 2 …. . Training is matched to testing. In practice, it is hard to train in this way. A Reference B B B A A A B A B A

cheduled Sampling Reference A B B A A B A B from model A B A From reference from model B From reference

Scheduled Sampling • Caption generation on MSCOCO BLEU-4 METEOR CIDER Always from reference 28. 8 24. 2 89. 5 Always from model 11. 2 15. 7 49. 7 Scheduled Sampling 30. 6 24. 3 92. 1 Samy Bengio, Oriol Vinyals, Navdeep Jaitly, Noam Shazeer, Scheduled Sampling for Sequence Prediction with Recurrent Neural Networks, ar. Xiv preprint, 2015

Beam Search The green path has higher score. Not possible to check all the paths A B 0. 4 A A 0. 4 B A 0. 6 B 0. 6 A A B 0. 4 B A B 0. 9

Beam Search Keep several best path at each step Beam size = 2 A A B A B A A B B B A B

Beam Search The size of beam is 3 in this example. https: //github. com/tensorflow/issues/654#issuecomment-169009989

Better Idea? U: how do you feel? M: happy to smile or sad to cry smile A high score happy B happy≈sad A B <BOS> B happy A B <BOS> B smile≈cry A A B Happy ≈sad

Object level v. s. Component level • Minimizing the error defined on component level is not equivalent to improving the generated objects Ref: The dog is running fast A cat a a a Cross-entropy of each step The dog is is fast The dog is running fast Optimize object-level criterion instead of component-level crossentropy. object-level criterion: Gradient Descent? : generated utterance, : ground truth

Reinforcement learning? Start with observation Obtain reward Action : “right” Observation Obtain reward Action : “fire” (kill an

Reinforcement learning? Action taken Marc'Aurelio Ranzato, Sumit Chopra, Michael Auli, Wojciech Zaremba, “Sequence Level Training with Recurrent Neural Networks”, ICLR, 2016 A A B <BOS> observation A B Actions set R(“BAA”, reference) A B The action we take influence the observation in the next step

Scheduled sampling reinforcement

DAD: Scheduled Sampling MIXER: reinforcement

Pointer Network Oriol Vinyals, Meire Fortunato, Navdeep Jaitly, Pointer Network, NIPS, 2015
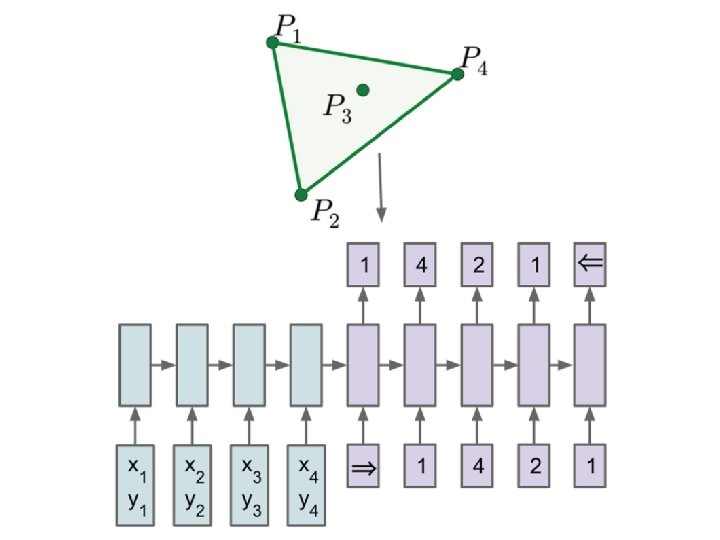


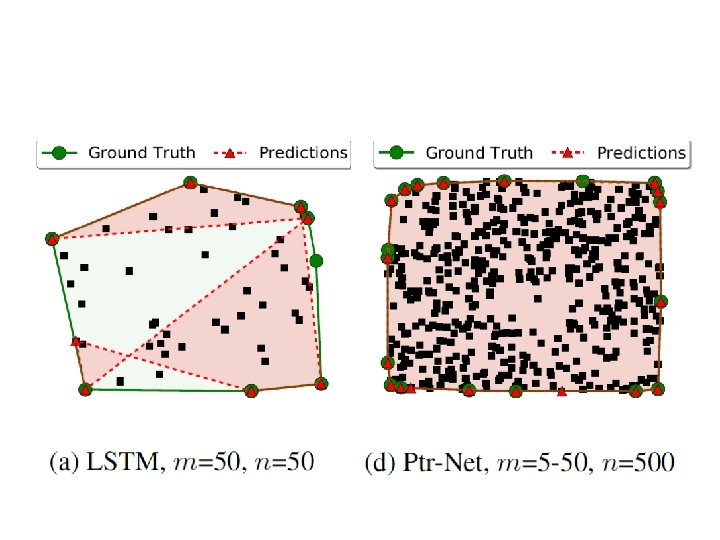

Applications Jiatao Gu, Zhengdong Lu, Hang Li, Victor O. K. Li, “Incorporating Copying Mechanism in Sequence-to. Sequence Learning”, ACL, 2016 Caglar Gulcehre, Sungjin Ahn, Ramesh Nallapati, Bowen Zhou, Yoshua Bengio, “Pointing the Unknown Words”, ACL, 2016 Machine Translation Chat-bot User: X寶你好,我是宏毅 Machine: 宏毅你好,很高興認識你
- Slides: 60