Concept Learning and Occams Razor CSCI 5822 Probabilistic

Concept Learning and Occam’s Razor CSCI 5822 Probabilistic Models of Human and Machine Intelligence Spring 2018 Professor Michael Mozer

Concept Learning Blorch Ringed Kingfisher Benign Ironic Compost Glick Belted Kingfisher Melanoma Not Ironic Paper

Supervised Approach To Concept Learning ü Machine learning methods typically require positive and negative examples - - ++ + - - - + ++ + - + + + ++ + +

Contrast With Human Learning Abiliites ü ü Learning from positive examples only Learning from a small number of examples § E. g. , word meanings § E. g. , learning appropriate social behavior § E. g. , learning edible foods § E. g. , skill instruction ü What would it mean to learn from a small number of positive examples? + + +

Learning Problem ü 2 3 + + 1 +
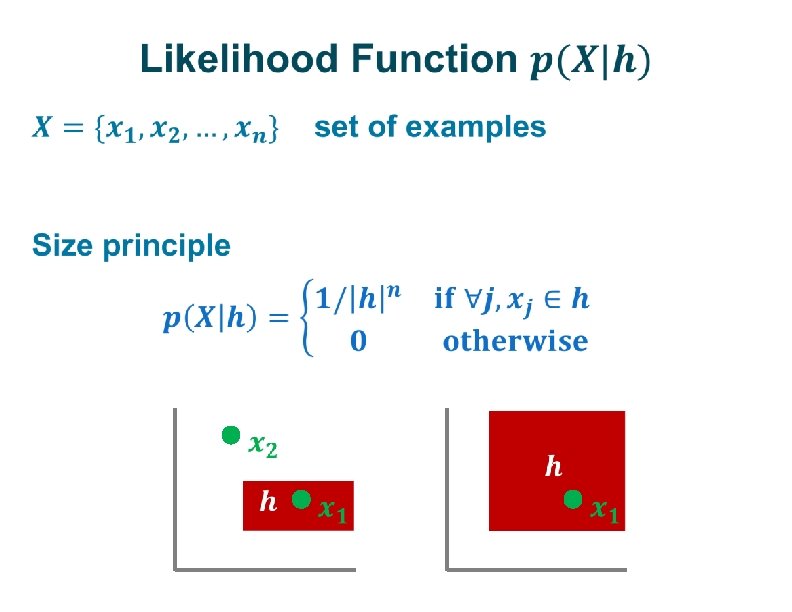
 ü ü ü Two dimensional continuous feature space Concepts defined by axis-parallel")
Tenenbaum (1999) ü ü ü Two dimensional continuous feature space Concepts defined by axis-parallel rectangles e. g. , feature dimensions § cholesterol level § insulin level ü e. g. , concept healthy
 Space ü ü H: all rectangles on the plane, parameterized by (l")
Hypothesis (Model) Space ü ü H: all rectangles on the plane, parameterized by (l 1, l 2, s 1, s 2) h: one particular hypothesis Note: |H| = ∞ ü Consider all hypotheses in parallel In contrast to non-Bayesian approach of maintaining only the best hypothesis at any point in time.

Prediction Via Model Averaging ü Marginalization or model averaging Chain rule Conditional independence

Prediction Via Model Averaging ü likelihood prior Bayes rule likelihood prior

ü Expected size prior

Digression on Priors ü

Prediction Via Model Averaging ü likelihood prior Bayes rule likelihood prior

Generalization Gradients MIN: smallest hypothesis consistent with data weak Bayes: instead of using size principle, assumes examples are produced by process independent of the true class Dark line = 50% prob.

Experimental Design Subjects shown n dots on screen that are “randomly chosen examples from some rectangle of healthy levels” ü § n drawn from {2, 3, 4, 6, 10, 50} ü Dots varied in horizontal and vertical range § r drawn from {. 25, . 5, 1, 2, 4, 8} units in a 24 unit window ü Task § draw the ‘true’ rectangle around the dots

Experimental Results

Number Game ü Experimenter picks integer arithmetic concept C § E. g. , prime number § E. g. , number between 10 and 20 § E. g. , multiple of 5 ü ü Experimenter presents positive examples drawn at random from C, say, in range [1, 100] Participant asked whether some new test case belongs in C

Empirical Predictive Distributions

Hypothesis Space § Even numbers § Odd numbers § Squares § Multiples of n § Ends in n § Powers of n § All numbers § Intervals [n, m] for n>0, m<101 § Powers of 2, plus 37 § Powers of 2, except for 32

Observation = 16 • Likelihood function • § Size principle Prior • § Intuition

Observation = 16 8 2 64 • Likelihood function • § Size principle Prior • § Intuition

Posterior Distribution After Observing 16

Model Vs. Human Data MODEL HUMAN DATA
 ü Method §Pick prior distribution (includes hypothesis space) §Pick likelihood")
Summary of Tenenbaum (1999) ü Method §Pick prior distribution (includes hypothesis space) §Pick likelihood function (size principle) §Leads to predictions for generalization as a function of r (range) and n (number of examples) Claims people generalize optimally given assumptions about priors and likelihood Bayesian approach provides best description of how people generalize on rectangle task. Explains how people can learn from a small number of examples, and only positive examples.

Important Ideas in Bayesian Models ü Generative theory captures process that produces observations § Prior § Likelihood ü Consideration of multiple hypotheses in parallel § Potentially infinite hypothesis space ü Inference § Role of priors diminishes with amount of evidence § Prediction via model (hypothesis) averaging § Explaining away ü Learning § just another form of inference § trade off between model simplicity and fit to data Bayesian Occam’s Razor
 If two")
medieval philosopher and monk ü ü Ockham's Razor tool for cutting (metaphorical) If two hypotheses are equally consistent with the data, prefer the simpler one. Simplicity § can accommodate fewer observations § smoother § fewer parameters § restricts predictions more (“sharper” predictions)

Motivating Ockham's Razor ü PRIORS Aesthetic considerations § A theory with mathematical beauty is more likely to be right (or believed) than an ugly one, given that both fit the same data. ü Past empirical success of the principle § Develop inference techniques (e. g. , Bayesian reasoning) that automatically incorporate Ockham's razor ü Two theories H 1 and H 2 LIKELIHOODS
 probabililty text more complex hypotheses should have lower")
Ockham's Razor with Priors Jeffreys (1939) probabililty text more complex hypotheses should have lower priors Requires a numerical rule for assessing complexity e. g. , number of free parameters e. g. , Vapnik-Chervonenkis (VC) dimension

Subjective vs. Objective Priors subjective or informative prior specific, definite information about a random variable objective or uninformative prior vague, general information Philosophical arguments for certain priors as uninformative Maximum entropy / least committment e. g. , interval [a b]: uniform e. g. , interval [0, ∞) with mean 1/λ: exponential distribution e. g. , mean μ and std deviation σ: Gaussian Independence of measurement scale e. g. , Jeffrey’s prior 1/(θ(1 -θ)) for θ in [0, 1] expresses same belief whether we talk about θ or logθ

Ockham’s Razor Via Likelihoods ü Coin flipping example H 1: coin has two heads H 2: coin has a head and a tail ü Consider 5 flips producing HHHHH H 1 could produce only this sequence H 2 could produce HHHHH, but also HHHHT, HHHTH, . . . TTTTT P(HHHHH | H 1) = 1, P(HHHHH | H 2) = 1/32 H 2 pays the price of having a lower likelihood via the fact it can accommodate a greater range of observations ü ü H 1 is more readily rejected by observations

Simple and Complex Hypotheses H 2 H 1

Note: “model” and “hypothesis” are generally interchangeable ü ü Bayes Factor BIC is approximation to Bayes factor A. k. a. likelihood ratio

Hypothesis Classes Varying In Complexity ü
 Minimum Description Length Prefer models that can communicate the data in the")
Rissanen (1976) Minimum Description Length Prefer models that can communicate the data in the smallest number of bits. ü The preferred hypothesis H for explaining data D minimizes: ü (1) length of the description of the hypothesis (2) length of the description of the data with the help of the chosen theory L: length
 MDL: prefer hypothesis that")
MDL & Bayes ü L: some measure of length (complexity) MDL: prefer hypothesis that min. L(H) + L(D|H) ü ü Bayes rule implies MDL principle P(H|D) = P(D|H)P(H) / P(D) –log P(H|D) = –log P(D|H) – log P(H) + log P(D) = L(D|H) + L(H) + const


Relativity Example Explain deviation in Mercury's orbit at perihelion with respect to prevailing theory ü E: Einstein's theory deviation F: fudged Newtonian theory deviation α = true a = observed
 ü Subjective Ockham's razor result depends on one's belief about P(α|F)")
Relativity Example (Continued) ü Subjective Ockham's razor result depends on one's belief about P(α|F) ü Objective Ockham's razor for Mercury example, RHS is 15. 04 ü Applies to generic situation
- Slides: 38