Conceitos bsicos da teoria da informao e as
")
Conceitos básicos da teoria da informação e as medidas de desigualdade de Theil (1967) Cap. 4 – Distribuição de renda – Medidas de desigualdade e Pobreza – Rodolfo Hoffmann

Conteúdo informativo de uma mensagem • Seja x a probabilidade de ocorrência do evento A • Vamos olhar para a relação entre essa probabilidade e o conteúdo informativo da mensagem “O evento A ocorreu”. • Se a probabilidade de ocorrência do evento A fosse x = 1, então, a mensagem acima não traria nenhuma novidade. Ideia: quanto menor for o valor de x, maior será o conteúdo informativo da mensagem “O evento A ocorreu. ” • Quando x 0, o conteúdo informativo
 conteúdo informativo de uma mensagem")
Conteúdo informativo de uma mensagem • Por definição: h(x) conteúdo informativo de uma mensagem é dado por: • Função log foi escolhida devido a propriedade de aditividade no caso de dois eventos independentes h(x 1, x 2) = h(x 1) + h(x 2)

Conteúdo informativo de uma previsão • Suponha que a probabilidade de chuva seja igual a x = 0, 2 h(x) = ln(1/0, 2) = 1, 61 – valor informativo da informação de que “choveu” • Vamos supor também que no dia anterior, vc assistiu o noticiário que afirmou que no dia seguinte iria chover. • Admita que isso tenha alterado a probabilidade de chuva para y = 0, 6 h(y) = ln(1/0, 6) = 0, 51 – valor informativo da mensagem de que “choveu”
 – h(y) = ln(1/x) – ln(1/y) =")
O conteúdo informativo da previsão • h(x) – h(y) = ln(1/x) – ln(1/y) = ln(y/x) • Ideia = com o conteúdo informativo que recebemos da previsão, ficamos menos ‘surpresos’ com a chuva. • Quando uma mensagem está sujeita a erro, como no caso de uma previsão, o conteúdo informativo da previsão: • h = log(y/x) • x = é a probabilidade a priori, ou seja, antes de receber a mensagem • y = é a probabilidade a posteriori

A esperança do conteúdo informativo de uma mensagem e a entropia de uma distribuição • Considere n possíveis eventos Ai i= 1, . . . , n exaustivos e mutuamente exclusivos, aos quais associamos as probabilidades xi • A esperança matemática do conteúdo informativo da mensagem “ocorreu Ai”, isto é, a informação esperada é:

A esperança do conteúdo informativo de uma mensagem e a entropia de uma distribuição • Para xi = 0 • Para 0 < xi 1, temos 1/xi ≥ 1 e log(1/xi) ≥ 0 • Quando H(x) será igual a zero? Quando uma das probabilidades é 1 e as demais 0. • Se resolvermos o lagrangeano para equação acima, encontraremos o máximo de H(x) = log n • Portanto,

Lagrangeano

A esperança do conteúdo informativo de uma mensagem e a entropia de uma distribuição • Perguntas: • Quando H(x) será igual a zero? • Quando H(x) será igual ao máximo? • 0<= H(x) <= log n
 é")
Entropia da distribuição • A esperança do conteúdo informativo para uma distribuição H(x) é chamada entropia da distribuição. • A entropia da distribuição é máxima (ou seja, há um máximo de incerteza a respeito do que pode ocorrer) quando todos os possíveis eventos são igualmente prováveis.

Informação esperada de uma mensagem incerta • n possíveis eventos Ai com probabilidades xi • consideremos uma mensagem incerta (uma previsão ou mensagem duvidosa) que transforma as probabilidades a priori xi em probabilidades a posteriori yi (yi é a probabilidade de ocorrência do evento Ai depois de recebida a mensagem). • A esperança do conteúdo informativo da mensagem é:
 tende ao infinito")
Observação • É possível mostrar que: • Note que I(y: x) tende ao infinito quando uma das probabilidades a priori (xi) tende a zero e a correspondente probabilidade a posteriori (yi) é positiva.

As medidas de desigualdade de Theil • Considere uma população onde todos recebem uma fração não-negativa (yi >=0, com i= 1, 2, . . . , n) da renda total. • Os valores de yi têm as mesmas propriedades que as probabilidades associadas a um universo de eventos.

Entropia da distribuição de renda Ø No caso da perfeita igualdade da distribuição de renda, todos recebem a mesma fatia da renda yi = 1/n a entropia é máxima; Ø No caso da perfeita desigualdade da distribuição de renda, existe uma pessoa que fica com toda a renda, yi =1 para algum i H(y) = 0 Entropia é uma medida do grau de igualdade da distribuição.

Entropia da distribuição de renda • Depois de definir a entropia da distribuição, Theil (1967) argumenta que é mais interessante trabalhar com a medida de desigualdade que se obtém fazendo = ‘valor máximo da entropia’ – ‘valor observado da entropia’ • T = log n – H(y) =
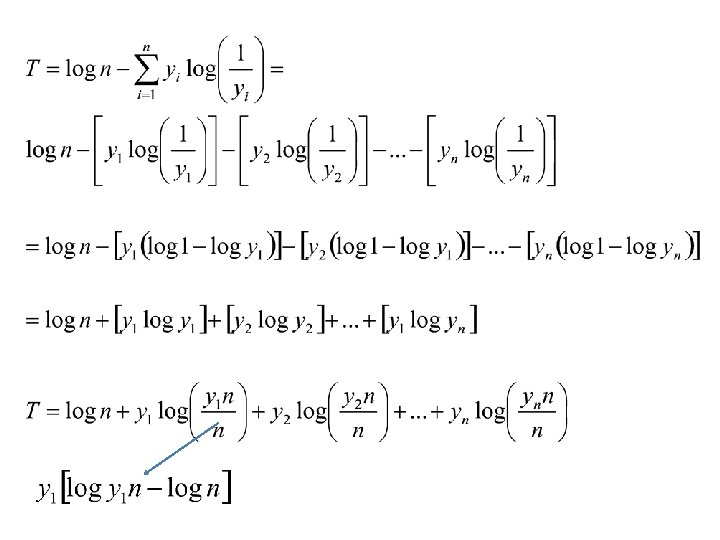

Para uma sociedade perfeitamente igualitária, T=0 Yi=1/n Para uma sociedade totalmente desigual, T = log n
 = Fração da renda apropriada")
Note que: • T = log n – H(y) = Fração da renda apropriada por cada indivíduo Probabilidades a priori== fraçao da população correspondente a cada pessoa Indice T-Theil esperança do valor informativo de uma mensagem incerta que transforma frações da população em frações da renda Se yi = 1/n T = 0 não há desigualdade

Índice L-Theil esperança do valor informativo de uma mensagem incerta que transforma frações da renda em frações da população Para uma sociedade perfeitamente igualitária, L=0 Yi=1/n Por outro lado, se Yi tende a zero para qq i, L tende a

Medidas em função das rendas individuais • xi = renda da i-ésima pessoa • = renda média • yi = fração da renda assegurada pela i-ésima pessoa =

Medidas em função das rendas individuais – T-Theil

Medidas em função das rendas individuais – L-Theil

Propriedades desejadas para índices de desigualdade de renda

Medidas de desigualdade • Existem várias formas de mensurar a desigualdade e cada uma delas tem uma intuição e uma abordagem matemática diferente. • Algumas medidas, contudo, podem gerar resultados perversos. • Exemplo: variância • Uma das formas mais simples de mensurar a desigualdade, contudo, dependente da escala. • Duplicar a renda, multiplica por 4 a estimativa da desigualdade de renda. • Propriedade não desejável.

Medidas de desigualdade • As melhores medidas de desigualdade devem seguir um conjunto de axiomas. • Existem 5 propriedades que normalmente são requeridas para gerar boas medidas de desigualdade.
 Simetria (ou Anonimato, Anonimidade) • Não diferencia as pessoas por outras características que")
1) Simetria (ou Anonimato, Anonimidade) • Não diferencia as pessoas por outras características que não a medida de bem estar individual (renda ou consumo).
 Princípio das transferências (Pigou, 1912; Dalton, 1920) • A desigualdade aumenta (ou pelo")
2) Princípio das transferências (Pigou, 1912; Dalton, 1920) • A desigualdade aumenta (ou pelo menos não cai) em resposta a uma transferência de um mais pobre para um mais rico. • Medidas de classe de entropia generalizada, atkinson e gini satisfazem. Não satisfazem: log var e var log
 Independência de escala • Respeita a propriedade de homogeidade de grau zero da")
3) Independência de escala • Respeita a propriedade de homogeidade de grau zero da renda: se dobramos todas as rendas não acontece nada com o indicador. • Variância não respeita.
 Independência da Replicação da População (Dalton, 1920) • A desigualdade é invariante à")
4) Independência da Replicação da População (Dalton, 1920) • A desigualdade é invariante à replicações da população. • Medida de Herfindahl não satisfaz (H cai quando n aumenta)
 Decomponibilidade • A desigualdade total pode se relacionar de forma consistente com as")
5) Decomponibilidade • A desigualdade total pode se relacionar de forma consistente com as partes constituintes da distribuição. • Por exemplo, se a desigualdade aumenta em cada sub-grupo da população, a gente espera que a desigualdade total também cresça.
 que atendem a todos")
Medidas da classe GE • As medidas de desigualdade I(y) que atendem a todos esses axiomas fazem parte da classe GE (Generalized Entropy) de medidas de desigualdade.

Medidas da classe GE a = 0 Theil L – desvio do log da média (Mean Log Deviation) a = 1 Theil T a = 2 a raiz quadrada dele é igual ao coeficiente de variação Coeficiente de variação

Gini • O coeficiente de Gini satisfaz os axiomas de 1 a 4 descritos anteriormente, mas não satisfaz o axioma da ‘decomponibilidade’ se os subvetores da renda se cruzam (overlap).
- Slides: 33