Combining labeled and unlabeled data for text categorization

Combining labeled and unlabeled data for text categorization with a large number of categories Rayid Ghani KDD Lab Project

Supervised Learning with Labeled Data Labeled data is required in large quantities and can be very expensive to collect.

Why use Unlabeled data? w Very Cheap in the case of text n n n Web Pages Newsgroups Email Messages w May not be equally useful as labeled data but is available in enormous quantities

Goal w Make learning more efficient by reducing the amount of labeled data required for text classification with a large number of categories

• ECOC very accurate and efficient for text categorization with a large number of classes • Co-Training useful for combining labeled and unlabeled data with a small number of classes

Related research with unlabeled data w Using EM in a generative model (Nigam et al. 1999) w Transductive SVMs (Joachims 1999) w Co-Training type algorithms (Blum & Mitchell 1998, Collins & Singer 1999, Nigam & Ghani 2000)

• ECOC very accurate and efficient for text categorization with a large number of classes • Co-Training useful for combining labeled and unlabeled data with a small number of classes

What is ECOC? w Solve multiclass problems by decomposing them into multiple binary problems (Dietterich & Bakiri 1995) w Use a learner to learn the binary problems

Testing Training. ECOC f 1 f 2 f 3 f 4 f 5 A B C D 0 1 0 0 1 1 1 0 1 0 0 1 X 1 1 0

The Feature Split Setting Tom Mitchell …My advisor… …My favorite band… Fredkin Professor of AI… Guns ‘n Roses November Rain … Avrim Blum ? ? …Professor Blum… Classifier A My research interests are… Classifier B
![The Co-training algorithm [Blum & Mitchell 1998] w Loop (while unlabeled documents remain): n](http://slidetodoc.com/presentation_image_h/008c3c9f4dc396885d95f162e22ec78a/image-11.jpg "The Co-training algorithm [Blum & Mitchell 1998] w Loop (while unlabeled documents remain): n")
The Co-training algorithm [Blum & Mitchell 1998] w Loop (while unlabeled documents remain): n Build classifiers A and B l n Classify unlabeled documents with A & B l n Use Naïve Bayes Add most confident A predictions and most confident B predictions as labeled training examples
![The Co-training Algorithm [Blum & Mitchell, 1998] Naïve Bayes on A Estimate labels Select](http://slidetodoc.com/presentation_image_h/008c3c9f4dc396885d95f162e22ec78a/image-12.jpg "The Co-training Algorithm [Blum & Mitchell, 1998] Naïve Bayes on A Estimate labels Select")
The Co-training Algorithm [Blum & Mitchell, 1998] Naïve Bayes on A Estimate labels Select most confident Learn from labeled data Naïve Bayes on B Estimate labels Add to labeled data Select most confident

ECOC + Co-Training w ECOC decomposes multiclass problems into binary problems w Co-Training works great with binary problems w ECOC + Co-Train = Learn each binary problem in ECOC with Co-Training

SPORTS HEALTH ARTS SCIENCE POLITICS LAW
 n n n Job Postings (Two feature sets")
Datasets w Jobs-65 (from Whiz. Bang) n n n Job Postings (Two feature sets – Title, Description) 65 categories Baseline 11% w Hoovers-255 n n n Collection of 4285 corporate websites Each company is classified into one of 255 categories Baseline 2%
 10%")
Results Dataset Naïve Bayes ECOC EM Co. Trainin g (No Un. Labeled Data) 10% Labeled 100% Labeled 10% Labeled Jobs-65 50. 1 68. 2 Hoovers 255 15. 2 32. 0 ECOC + Co. Trainin g 100% Labeled 10% Labeled 10% Labele d 59. 3 71. 2 58. 2 54. 1 64. 5 24. 8 36. 5 9. 1 10. 2 27. 6
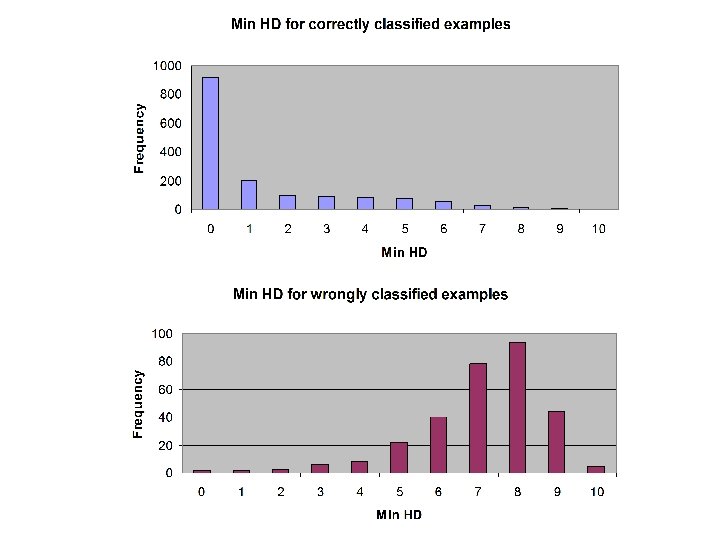

Results

Next Steps w Use Active Learning techniques to pick initial labeled examples w Develop techniques to partition a standard feature set into two redundantly sufficient feature sets w Create codes specifically for unlabeled data

Summary w Combination of ECOC and Co-Training performs extremely well for learning with labeled and unlabeled data w Results in High-Precision classifications w Randomly partitioning the vocabulary works well for Co-Training
- Slides: 20