Code Optimization II Machine Dependent Optimization Topics n

 { int i; int")
 { int i; int")
 { int length = vec_length(v);")
,")




 Operations %edx. 0 load incl load cmpl+1 %ecx. i cc.")



 { int length = vec_length(v); int")




 { int length = vec_length(v);")
 * x 2) * x 4) *")



 { int length")
) * (x 2 *")







- Slides: 33
Code Optimization II: Machine Dependent Optimization Topics n Machine-Dependent Optimizations l Unrolling l Enabling instruction level parallelism
Previous Best Combining Code void combine 4(vec_ptr v, int *dest) { int i; int length = vec_length(v); int *data = get_vec_start(v); int sum = 0; for (i = 0; i < length; i++) sum += data[i]; *dest = sum; } Task n Compute sum of all elements in vector Vector represented by C-style abstract data type n Achieved CPE of 2. 00 n l Cycles per element – 2–
General Forms of Combining void abstract_combine 4(vec_ptr v, data_t *dest) { int i; int length = vec_length(v); data_t *data = get_vec_start(v); data_t t = IDENT; for (i = 0; i < length; i++) t = t OP data[i]; *dest = t; } – 3–
Pointer Code void combine 4 p(vec_ptr v, int *dest) { int length = vec_length(v); int *data = get_vec_start(v); int *dend = data+length; int sum = 0; while (data < dend) { sum += *data; data++; } *dest = sum; } Optimization n Use pointers rather than array references n CPE: 3. 00 (Compiled -O 2) l Oops! We’re not making progress here! Warning: Some compilers do better job optimizing array code – 4–
Pointer vs. Array Code Inner Loops Array Code. L 24: addl (%eax, %edx, 4), %ecx incl %edx cmpl %esi, %edx jl. L 24 # # # Loop: sum += data[i] i++ i: length if < goto Loop Pointer Code. L 30: addl (%eax), %ecx addl $4, %eax cmpl %edx, %eax jb. L 30 # Loop: # sum += *data # data ++ # data: dend # if < goto Loop Performance n n – 5– Array Code: 4 instructions in 2 clock cycles Pointer Code: Almost same 4 instructions in 3 clock cycles
Modern CPU Design Instruction Control Fetch Control Retirement Unit Register File Address Instrs. Instruction Decode Instruction Cache Operations Register Updates Prediction OK? Integer/ Branch General Integer FP Add Operation Results FP Mult/Div Load Addr. Store Addr. Data Cache Execution – 6– Functional Units Data
CPU Capabilities of Pentium III Multiple Instructions Can Execute in Parallel n 1 load 1 store n 2 integer (one may be branch) n 1 FP Addition n 1 FP Multiplication or Division n Some Instructions Take > 1 Cycle, but Can be Pipelined Instruction Latency n Load / Store 3 n Integer Multiply 4 n Double/Single FP Multiply 5 n Double/Single FP Add 3 n – 7– Cycles/Issue 1 1 2 1
CPU Capabilities of Pentium III Multiple Instructions Can Execute in Parallel n 1 load 1 store n 2 integer (one may be branch) n 1 FP Addition n 1 FP Multiplication or Division n Some Instructions Take > 1 Cycle, but Can be Pipelined Instruction Latency n Load / Store 3 n Integer Multiply 4 n Double/Single FP Multiply 5 n Double/Single FP Add 3 n Integer Divide 36 n Double/Single FP Divide 38 n – 8– Cycles/Issue 1 1 2 1 36 38
Visualizing Operations %edx. 0 incl load cmpl %edx. 1 Operations n cc. 1 %ecx. 0 l Cannot begin operation until jl t. 1 operands available n Time imull %ecx. 1 – 9– Vertical position denotes time at which executed Height denotes latency
Visualizing Operations (cont. ) Operations %edx. 0 load incl load cmpl+1 %ecx. i cc. 1 %ecx. 0 Time jl t. 1 addl %ecx. 1 – 10 – %edx. 1 n Same as before, except that add has latency of 1
3 Iterations of Combining Product Unlimited Resource Analysis n n Assume operation can start as soon as operands available Operations for multiple iterations overlap in time Performance n n – 11 – Limiting factor becomes latency of integer multiplier Gives CPE of 4. 0
4 Iterations of Combining Sum 4 integer ops Unlimited Resource Analysis Performance n n n – 12 – Can begin a new iteration on each clock cycle Should give CPE of 1. 0 Would require executing 4 integer operations in parallel
Combining Sum: Resource Constraints n n Only have two integer functional units Some operations delayed even though operands available Performance n – 13 – Sustain CPE of 2. 0
Loop Unrolling void combine 5(vec_ptr v, int *dest) { int length = vec_length(v); int limit = length-2; int *data = get_vec_start(v); int sum = 0; int i; Optimization n Combine multiple iterations into single loop body Amortizes loop overhead across multiple iterations n Finish extras at end n Measured CPE = 1. 33 n } – 14 –
Visualizing Unrolled Loop n n Loads can pipeline, since don’t have dependencies Only one set of loop control operations %edx. 0 addl load %ecx. 0 c cmpl+1 %ecx. i jl load cc. 1 t. 1 a addl %ecx. 1 a load Time t. 1 b addl %ecx. 1 b – 15 – %edx. 1 t. 1 c addl %ecx. 1 c
Executing with Loop Unrolling n Predicted Performance l Can complete iteration in 3 cycles l Should give CPE of 1. 0 n Measured Performance l CPE of 1. 33 l One iteration every 4 cycles – 16 –
Effect of Unrolling Degree 1 2 3 4 8 16 2. 00 1. 50 1. 33 1. 50 1. 25 1. 06 Integer Sum Integer Product 4. 00 FP Sum 3. 00 FP Product 5. 00 n Only helps integer sum for our examples l Other cases constrained by functional unit latencies n Effect is nonlinear with degree of unrolling l Many subtle effects determine exact scheduling of operations – 17 –
1 x 0 * Serial Computation x 1 * Computation x 2 * ((((((1 * x 0) * x 1) * x 2) * x 3) * x 4 ) * x 5 ) * x 6 ) * x 7 ) * x 8 ) * x 9 ) * x 10) * x 11) x 3 * x 4 * x 5 * Performance n x 6 * n N elements, D cycles/operation N*D cycles x 7 * x 8 * x 9 * x 10 * – 18 – x 11 *
Parallel Loop Unrolling void combine 6(vec_ptr v, int *dest) { int length = vec_length(v); int limit = length-1; int *data = get_vec_start(v); int x 0 = 1; int x 1 = 1; int i; Code Version n Integer product Optimization n Accumulate in two different products l Can be performed simultaneously n Combine at end Performance CPE = 2. 0 n 2 X performance n } *dest = x 0 * x 1; } – 19 –
Dual Product Computation ((((((1 * x 0) * x 2) * x 4) * x 6) * x 8) * x 10) * ((((((1 * x 1) * x 3) * x 5) * x 7) * x 9) * x 11) Performance n n n – 20 – N elements, D cycles/operation (N/2+1)*D cycles ~2 X performance improvement
Requirements for Parallel Computation Mathematical n Combining operation must be associative & commutative l OK for integer multiplication l Not strictly true for floating point » OK for most applications Hardware n n – 21 – Pipelined functional units Ability to dynamically extract parallelism from code
Visualizing Parallel Loop n n Two multiplies within loop no longer have data dependency Allows them to pipeline %edx. 0 addl load %ecx. 0 cmpl load cc. 1 jl t. 1 a %ebx. 0 t. 1 b Time imull %ecx. 1 %ebx. 1 – 22 – %edx. 1
Executing with Parallel Loop n Predicted Performance l Can keep 4 -cycle multiplier – 23 – busy performing two simultaneous multiplications l Gives CPE of 2. 0
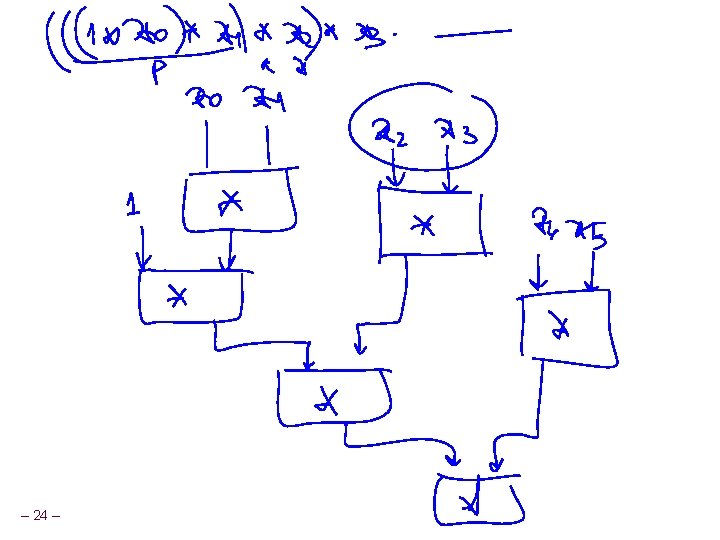
Parallel Unrolling: Method #2 void combine 6 aa(vec_ptr v, int *dest) { int length = vec_length(v); int limit = length-1; int *data = get_vec_start(v); int x = 1; int i; Code Version n Integer product Optimization Multiply pairs of elements together n And then update product n Performance n } – 25 – CPE = 2. 5
Method #2 Computation ((((((1 * (x 0 * x 1)) * (x 2 * x 3)) * (x 4 * x 5)) * (x 6 * x 7)) * (x 8 * x 9)) * (x 10 * x 11)) Performance n n N elements, D cycles/operation Should be (N/2+1)*D cycles l CPE = 2. 0 n Measured CPE worse Unrolling 2 – 26 – CPE (measured) (theoretical) 2. 50 2. 00 3 1. 67 1. 33 4 1. 50 1. 00 6 1. 78 1. 00
Understanding Parallelism /* Combine 2 elements at a time */ for (i = 0; i < limit; i+=2) { x = (x * data[i]) * data[i+1]; } n n CPE = 4. 00 All multiplies performed in sequence /* Combine 2 elements at a time */ for (i = 0; i < limit; i+=2) { x = x * (data[i] * data[i+1]); } n n – 27 – CPE = 2. 50 Multiplies overlap
Limitations of Parallel Execution Need Lots of Registers n To hold sums/products n Only 6 usable integer registers l Also needed for pointers, loop conditions n n 8 FP registers When not enough registers, must spill temporaries onto stack l Wipes out any performance gains – 28 –
Machine-Dependent Opt. Summary Pointer Code n Look carefully at generated code to see whether helpful Loop Unrolling n n Some compilers do this automatically Generally not as clever as what can achieve by hand Exposing Instruction-Level Parallelism n Very machine dependent (GCC on IA 32/Linux not very good) Warning: n n – 29 – Benefits depend heavily on particular machine Do only for performance-critical parts of code