CLUSTERING Hierarchical Partitional Clustering Pendahuluan Tujuan utama teknik

 sehingga")


 Langkah-langkah: � Kelompokkan setiap obyek ke dalam kelompok/klasternya sendiri �")



![Cosinus - Contoh Untuk data contoh [10 5], dan [20 20], maka besarnya cosinus](https://slidetodoc.com/presentation_image_h2/722395522d371a13d597e1b24c1ae8af/image-9.jpg "Cosinus - Contoh Untuk data contoh [10 5], dan [20 20], maka besarnya cosinus")


 Complete linkage (furthest-neighbor approach) Average linkage")
 Jarak minimum antara elemen")

 Data awal: Single linkage clustering (nearest-neighbor approach): mencari jarak terkecil dgn")
: 1. 2. 3. 4. 5. 6. 7.")
 Data awal: Complete linkage clustering : cari jarak yang terjauh, tetapi")














/4,")

, dimana n adalah # objects, k adalah #")
- Slides: 36
CLUSTERING Hierarchical & Partitional Clustering
Pendahuluan Tujuan utama teknik clustering: � Pengelompokan sejumlah data/obyek ke dalam cluster (grup) sehingga dalam setiap klaster akan berisi data yang semirip mungkin. � Ukuran kemiripan biasanya dihitung dengan jarak. � Jarak dalam satu klaster dibuat sedekat mungkin dan jarak antar klaster diusahakan untuk sejauh mungkin � Jadi dalam satu cluster harus semirip mungkin dan dengan klaster yang lain harus berbeda.
Clustering merupakan salah satu teknik unsupervised learning � Tidak perlu dilakukan pelatihan metode tersebut � Tidak ada fase learning � Tidak membutuhkan label ataupun keluaran dari setiap data yang diinvestigasi. Terdapat 2 pendekatan dalam clustering: � Hirarki � Partisi
Untuk optimasi data yang diklaster, terkadang diperlukan untuk normalisasi dahulu:
Clustering Hirarki (Hierarchical Clustering) Langkah-langkah: � Kelompokkan setiap obyek ke dalam kelompok/klasternya sendiri � Temukan pasangan yang paling mirip untuk dimasukkan ke dalam klaster yang sama dengan melihat ke dalam matriks kemiripan (resemblance/similarity) � Gabungkan kedua obyek ke dalam satu klaster � Ulangi sampai tersisa hanya satu klaster
Kemiripan dan Ketidakmiripan Untuk penggabungan obyek ke dalam satu klaster diperlukan ukuran kemiripan dan ketidakmiripan Ukuran kemiripan dapat digunakan metoda: � Cosinus, kovarian dan korelasi Ukuran ketidakmiripan dapat digunakan ukuran jarak
Data contoh NO X 1 X 2 1 10 5 2 20 20 3 30 10 4 30 15 5 5 10
Cosinus antara 2 titik x dan y didefinisikan sebagai: • Di mana || x|| didefinisikan sebagai:
Cosinus - Contoh Untuk data contoh [10 5], dan [20 20], maka besarnya cosinus di antara keduanya dapat dihitung sebagai berikut:
Kovarian antara dua data didefinisikan sebagai: Di mana x adalah data pertama dan y data kedua. Dari data contoh bisa dihitung kovarian antara data ke satu dan ke dua. Rata-rata dari data satu dan ke dua adalah:
Korelasi Koevisien korelasi 2 buah data dituliskan dgn rumusan berikut:
Macam metoda hierarchical clustering Single linkage (nearest-neighbor approach) Complete linkage (furthest-neighbor approach) Average linkage See on Discovering Knowledge in Data by Daniel T. Larose
Ukuran Jarak maksimum antara elemen dalam klaster (complete linkage clustering) Jarak minimum antara elemen dalam klaster (single linkage clustering)
Konsep Jarak Euclidan, jarak dua titik x dan y menurut Euclidan dirumuskan sebagai: Jarak Manhattan atau Cityblock, menurut konsep ini jarak dua titik x dan y dirumuskan:
Single linkage (contoh) Data awal: Single linkage clustering (nearest-neighbor approach): mencari jarak terkecil dgn nilai terkecil untuk penggabungan
Single linkage �Tahapan dari proses clustering (singlelingkage): 1. 2. 3. 4. 5. 6. 7. 8. 9. Cluster {33} & {33} digabung Cluster{15} & {16} digabung Cluster{15 , 16} dg {18} digabung Cluster{2}&{5} digabung Cluster {2, 5} dg {9} digabung Cluster {2, 5, 9} dg {15, 16, 18} digabung Cluster {2, 5, 9, 15, 16, 18} dg {25} digabung Cluster{2, 5, 9, 15, 16, 18, 25} dg {33, 33} digabung Cluster{2, 5, 9, 15, 16. 18, 25, 33} dg {45} digabung
Complete linkage (contoh) Data awal: Complete linkage clustering : cari jarak yang terjauh, tetapi diambil nilai terkec
Complete linkage �Tahapan 1. 2. 3. 4. 5. 6. 7. 8. 9. dari proses clustering: Cluster {33} dg {33} digabung Cluster{15} dg {16} digabung Cluster{2} dg {5} digabung (arbitrary} Cluster {15, 16} dg {18} digabung Cluster {2, 5} dg {9} digabung Cluster {25} dg {33, 33} digabung Cluster{2, 5, 9} dg {15, 16, 18} digabung Cluster{25, 33} dg {45} digabung Cluster{2, 5, 9, 16, 18} dg {25, 33, 45} digabung
Average linkage �Tahapan dari proses clustering: Step 1 sama Step 2 sama Average linkage dari cluster {2}dg{5} atau combinasi cluster {15, 16} dg {18} sehingga didapatkan average dari |18 -15| dan |18 -16| 2. 5, shg digabungkan dahulu {15, 16} dg {18} 4. Cluster {2} dg {5} digabung 5. Dst. 1. 2. 3.
CLUSTERING DENGAN METODE KMEANS Partitional clustering
Pendahuluan K-means merupakan teknik clustering yang paling umum dan sederhana. Tujuan clustering ini adalah mengelompokkan obyek ke dalam k cluster/kelompok. Nilai k harus ditentukan terlebih dahulu (berbeda dengan hierarchical clustering). Ukuran ketidakmiripan masih tetap digunakan untuk mengelompokkan obyek yang ada.
Algoritma K-Means Secara ringkas algoritma K-means adalah sebagai berikut: 1. 2. 3. 4. 5. Pilih jumlah cluster k Inisialisasi k pusat cluster Tempatkan setiap data/obyek ke cluster terdekat Perhitungan kembali pusat cluster Ulangi langkah 3 dengan memakai pusat cluster yang baru. Jika pusat cluster tidak berubah lagi maka proses peng-cluster-an dihentikan.
Penentuan Jumlah dan Pusat Cluster Inisialisasi atau penentuan nilai awal pusat cluster dapat dilakukan dengan berbagai macam cara, antara lain: � Pemberian nilai secara random � Pengambilan sampel awal dari data � Penentuan nilai awal hasil dari cluster hirarki dengan jumlah cluster yang sesuai dengan penentuan awal. Dalam hal ini biasanya user memiliki pertimbangan intuitif karena dia memiliki informasi awal tentang obyek yang sedang dipelajari, termasuk jumlah cluster yang paling tepat.
Penempatan Obyek ke dalam Cluster Penempatan obyek ke dalam cluster didasarkan pada kedekatannya dengan pusat cluster Dalam tahap ini perlu dihitung jarak tiap data ke tiap pusat cluster yang telah ditentukan. Jarak paling dekat antara suatu data dengan pusat cluster tertentu merupakan hal penentu data tersebut akan masuk cluster yang mana.
Perhitungan Kembali Pusat Cluster Pusat cluster ditentukan kembali dengan cara dihitung nilai rata-rata data/obyek dalam cluster tertentu. Jika dikehendaki dapat pula digunakan perhitungan median dari anggota cluster yang dimaksud Mean bukan satu-satunya ukuran yang bisa dipakai Pada kasus tertentu pemakaian median memberikan hasil yang lebih baik. Karena median tidak sensitif terhadap data outlier (data yang terletak jauh dari yang lain, meskipun dalam satu cluster - pencilan) Contoh: � � � Mean dari 1, 3, 5, 7, 9 adalah 5 Mean dari 1, 3, 5, 7, 1009 adalah 205 Median dari 1, 3, 5, 7, 1009 adalah 5
Konvergensi atau terminasi Untuk menghentikan proses iterasi dalam mencari pengcluster-an yang optimum, maka digunakan ratio perbandingan antara nilai kovarian antar cluster dan di dalam cluster: BCV = Between Cluster Variation; WCV = Within Cluster Variation Dengan rumusan SSE sbb: dimana, m nilai pusat dari setiap cluster, p merepresentasikan setiap titik data Semakin besar nilai ratio, semakin tepat cluster yg terbentuk
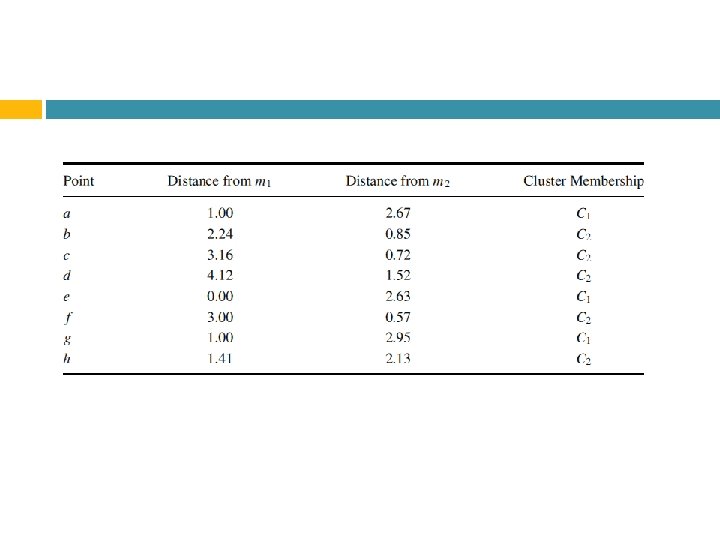
Contoh Data points untuk k-means Maka, dengan algoritma k-means: 1. 2. 3. Menanyakan user berapa jumlah cluster k (misal k=2) Menentukan secara random untuk inisialisasi lokasi pusat cluster; m 1=(1, 1) dan m 2=(2, 1) Untuk setiap record dicari nilai pusat cluster terdekat, dengan menghitung jarak tiap-tiap titik terhadap pusat cluster.
1 st iteration Sehingga dengan kedekatannya mengindikasikan ke cluster mana
Expectation: increasing for the ratio
2 nd iteration 4. Mengupdate nilai titik pusat cluster -1& 2 dengan mean dari setiap cluster yg terbentuk: m 1’=[(1+1+1)/3, (3+2+1)/3]= (1, 2) m 2’=[(3+4+5+4+2)/5, (3+3+3+2+1)/5]=(3. 6, 2. 4) 5. Kemudian dihitung jarak tiap-tiap titik dengan pusat yg baru
Sehingga diperoleh jumlah error kuadrat dari pusat cluster Dan ratio: Karena nilainya lebih besar dari sebelumnya, shg terjadi peningkatan
3 rd iteration Menemukan kembali lokasi pusat cluster dengan meng-update-nya dari mean: m 1’’=[(1+1+2)/4, (3+2+1+1)/4]=(1. 25, 1. 75) m 2’’=[(3+4+5+4)/4, (3+3+3+2)/4]=(4, 2. 75) Kemudian dicari jaraknya tiap-tiap titik terhadap titik pusat cluster yang baru
Karena nilainya lebih besar dari sebelumnya, maka dilakukan iterasi lagi
Kelebihan � Relatively efficient: O(tkn), dimana n adalah # objects, k adalah # clusters, dan t merupakan # iterations. Umumnya, k, t << n. � Biasanya berhenti pada nilai optimum lokal (local optimum). Nilai global optimum dapat ditentukan dengan menggunakan teknik seperti deterministic annealing dan genetic algorithms Kekurangan � Dapat diterapkan hanya saat nilai mean telah ditentukan, bagaimana untuk data-data bersifat kategori? � Perlu ditentukan k, jumlah cluster � Tidak dapat menangani noisy data dan outliers � Tidak tepat untuk membentuk cluster dengan data nonconvex shapes