CLS MHC Class II Risk Alleles and Amino







: MHC Class II Risk Alleles and Amino Acid Residues in Idiopathic Membranou")

 Deep. EM The convolutional neural network used in Deep. EM for particle picking")

 100 80")

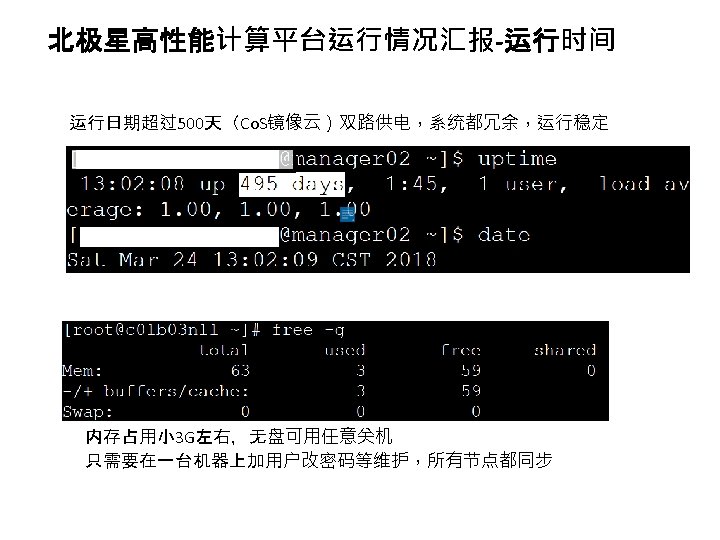
--NS方程+两方程模型方程(重复三次) Intel Xeon Gold 6132处理器(2. 6 GHz 14 C 19. 25 MB")

 GPU PERFORMANCE COMPARISON P 100 V 100")





 DGX-2,")

















- Slides: 51
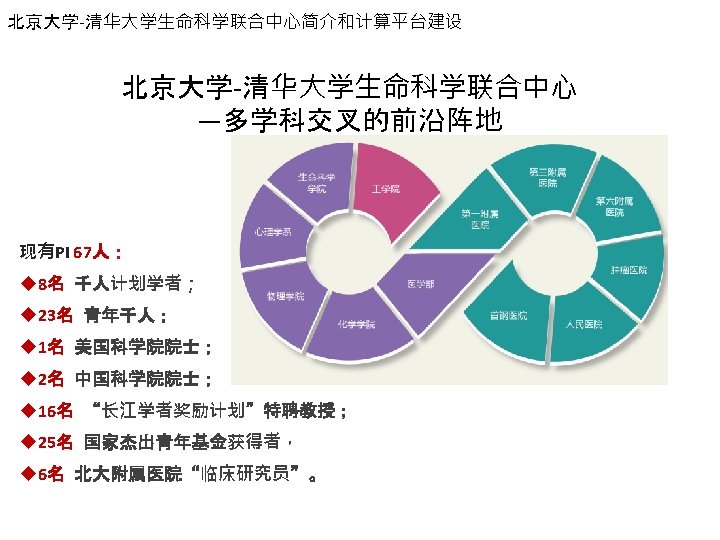
CLS老师赵明辉(计算部分陈芳进完成): MHC Class II Risk Alleles and Amino Acid Residues in Idiopathic Membranou s Nephropathy(Journal of the American Society of Nephrology 2016) Cui Z, Xie LJ, Chen FJ(并列一作,完成计算部分),
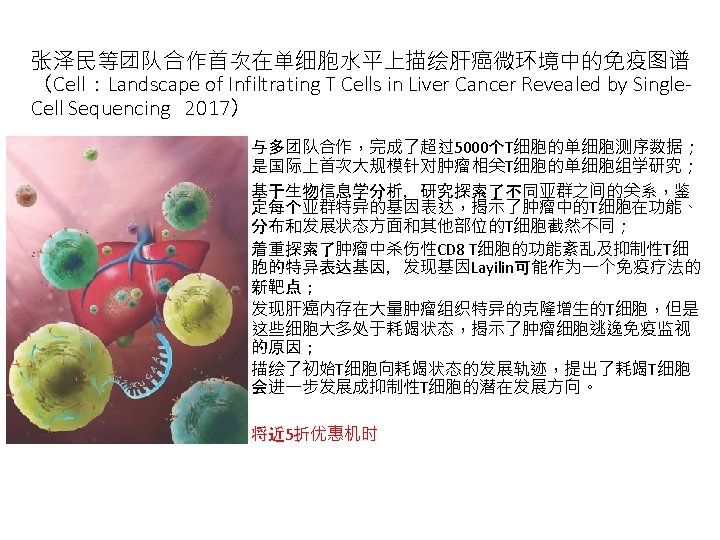
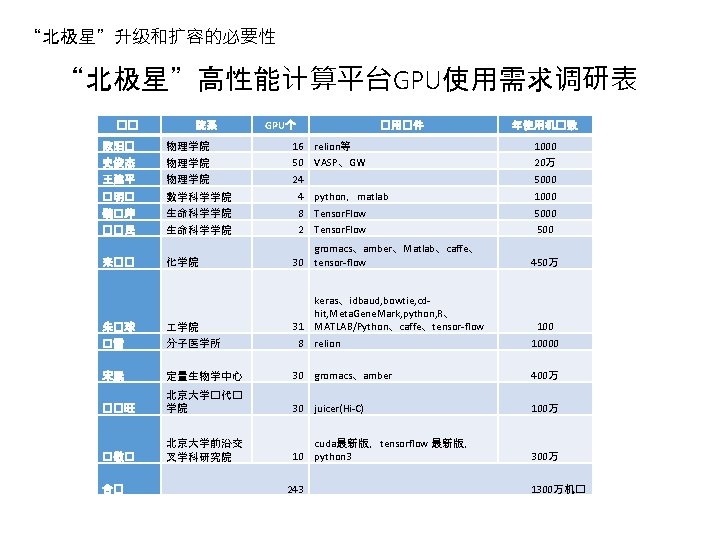
“北极星”升级和扩容的必要性-GPU(欧阳颀课题组文章) Deep. EM The convolutional neural network used in Deep. EM for particle picking in Cryo-EM Y, Zhu, et al. A deep convolutional neural network approach to single-particle recognition in cryo-electron Microscopy. BMC Bioinformatics (2017) 18: 348 Y, Zhu, et al. Structural mechanism for nucleotide-driven remodeling of the AAA-ATPase unfoldnase in the activated human 26 S proteasome. Nature Communications (2018), In Press.
“北极星”升级和扩容的必要性—GPU在冷冻电镜加速 RELION: Plasmodium ribosome on P 100 s PCIe 0. 0140 0. 0120 0. 0112 40. 0 X 37. 3 X 33. 7 X 0. 0101 0. 0100 1/Minutes 0. 0080 0. 0070 0. 0060 23. 3 X 15. 3 X 9. 0 X 0. 0046 0. 0040 Running RELION version 2. 0. 3 The blue node contains Dual Intel Xeon E 5 -2690 v 4@2. 6 GHz (Broadwell) CPUs The green nodes contain Dual Intel Xeon E 5 -2690 v 4@2. 6 GHz (Broadwell) CPUs + Tesla P 100 PCIe (16 GB) GPUs 0. 0027 0. 0020 0. 0003 0. 0000 1 Broadwell 1 node + 2 nodes + node 1 x P 100 2 x P 100 4 x P 100 8 x P 100 PCIe (16 GB)PCIe (16 GB) PCIe per node (16 GB) 3 nodes + 12 x P 100 PCIe (16 GB) 4 nodes + 16 x P 100 PCIe (16 GB) Data Citation: http: //en. community. dell. com/techcenter/hi gh-performancecomputing/b/general_hpc/archive/2017/03/1 4/application-performance-on-p 100 -pcie-gpus 10
“北极星”升级和扩容的必要性—GPU在分子动力学上加速 AMBER 16 AMBER MD Performance for Cryptochrome on CLS HPC (ns/Day) 100 80 80 60 40 4 X 20 17 15 40 2 x K Cryptochrome 6 9305 atoms gp u/ e( 12 od 5 N s/ cn P 1 00 /1 x. P 0 C o. 10 0 . . 0 4 x~5 x Faster than CPU only system or two K 40 cards.
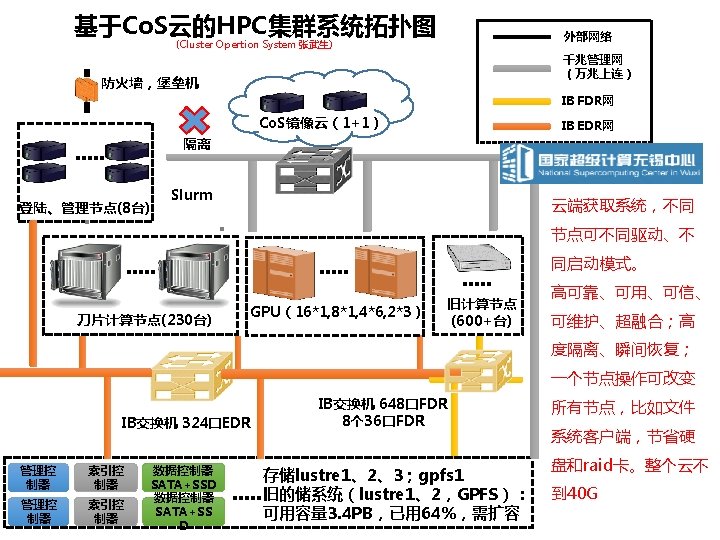
CPU选型 6132 解偏微分方程组(7个方程)--NS方程+两方程模型方程(重复三次) Intel Xeon Gold 6132处理器(2. 6 GHz 14 C 19. 25 MB L 3 140 W) $2111. 00 Intel Xeon Gold 6140处理器(2. 3 GHz 16 C 24. 75 MB L 3 140 W) $2445. 00 为多节点大规模并行任务,6132性价比比较高
GPU卡选型 TESLA V 100 M The Fastest and Most Productive GPU for AI and HPC Volta Architecture Tensor Core Most Productive GPU 125 Programmable TFLOPS Deep Learning Improved NVLink 2. 0 (300 GB/s)&HBM 2(900 GB/s) Volta MPS Improved SIMT Model Efficient Bandwidth Inference Utilization New Algorithms 18
P 100&V 100 P 100即将停产(为什么是V 100 m) GPU PERFORMANCE COMPARISON P 100 V 100 m? Training acceleration 10 TOPS 125 TOPS 12 x Inference acceleration 21 TFLOPS 125 TOPS 6 x FP 64/FP 32 5/10 TFLOPS 7. 8/15. 7 TFLOPS 1. 5 x HBM 2 Bandwidth 720 GB/s 900 GB/s 1. 2 x NVLink Bandwidth 160 GB/s 300 GB/s 1. 9 x L 2 Cache 4 MB 6 MB 1. 5 x L 1 Caches 1. 3 MB 10 MB 7. 7 x 56 SM 3584 CUDA Cores Ratio 80 SM 5120 CUDA Cores 640 Tensor Cores
VOLTA GV 100 M 21 B transistors 815 mm 2 80 SM 5120 CUDA Cores 640 Tensor Cores 32 GB HBM 2 900 GB/s HBM 2 300 GB/s NVLink *full GV 100 chip contains 84 SMs
VOLTA GV 100 M SM GV 100 FP 32 units 64 FP 64 units 32 INT 32 units 64 Tensor Cores 8 Register File 256 KB Unified L 1/Shared memory 128 KB Active Threads 2048
深度学习-NVIDIA DGX-2 THE WORLD’S MOST POWERFUL DEEP LEARNING SYSTEM FOR THE MOST COMPLEX DEEP LEARNING CHALLENGES • First 2 PFLOPS System • 16 V 100 32 GB GPUs Fully Interconnected • NVSwitch: 2. 4 TB/s bisection bandwidth • 24 X GPU-GPU Bandwidth • 0. 5 TB of Unified GPU Memory • 10 X Deep Learning Performance • 8 EDR Infiniband/100 Gig. E(OPA不支持) 3
DESIGNED TO TRAIN THE PREVIOUSLY IMPOSSIBLE 2 Two GPU Boards 8 V 100 32 GB GPUs per board 6 NVSwitches per board 512 GB Total HBM 2 Memory interconnected by Plane Card NVIDIA Tesla V 100 32 GB 1 Twelve NVSwitches 3 2. 4 TB/sec bi-section bandwidth 9 4 Eight EDR Infiniband/100 Gig. E 1600 Gb/sec Total Bi-directional Bandwidth 5 PCIe Switch Complex 30 TB NVME SSDs 8 Internal Storage 6 Two Intel Xeon Platinum CPUs 7 1. 5 TB System Memory Dual 10/25 Gb/sec 9 Ethernet NVIDIA DGX-2等均不支持OPA
VOLTA NVLINK 4卡、8卡为NVLINK, 16卡位全对称NVSwitches 300 GB/sec 50% more links 28% faster signaling 21
10 X PERFORMANCE GAIN IN LESS THAN A YEAR Time to Train (days) DGX-2, Q 3‘ 18 DGX-1, SEP’ 17 DGX-1 with V 100 15 days DGX-2 10 Time 1. 5 days 0 5 s Faster 10 15 20 software improvements across the stack including NCCL, cu. DNN, etc. Workload: Fair. Seq, 55 epochs to solution. Py. Torch training performance. NVIDIA CONFIDENTIAL. DO NOT DISTRIBUTE.
NVME SSD STORAGE Rapidly ingest the largest datasets into cache • Faster than SATA SSD, optimized for transferring huge datasets • Dramatically larger user scratch space • The protocol of choice for next-gen storage technologies • 8 x 3. 84 TB NVMe in RAID 0 (Data) • 25. 5 GB/sec Sequential Read bandwidth (vs. 2 GB/sec for 7 TB of SAS SSDs on DGX-1) 10
LATEST GENERATION CPU AND 1. 5 TB SYSTEM MEMORY Faster, more resilient, boot and storage management • More system memory to handle larger DL and HPC applications • 2 Intel Skylake Xeon Platinum 8168 2. 7 GHz, 24 cores • 24 x 64 GB DIMM System Memory 11
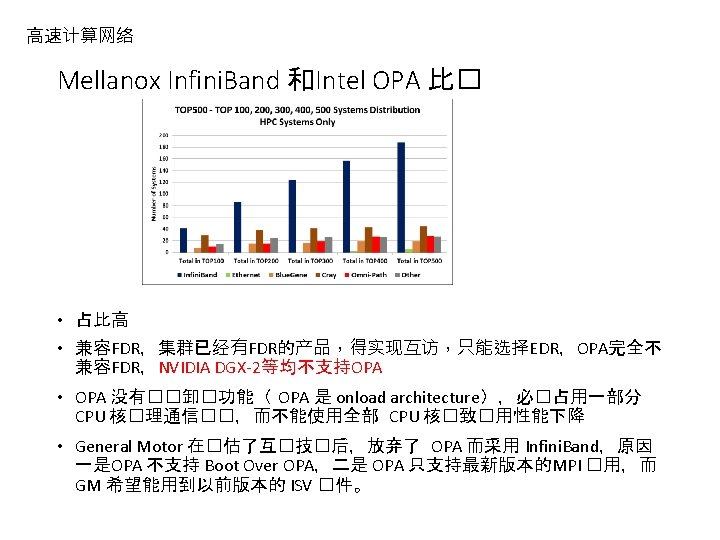
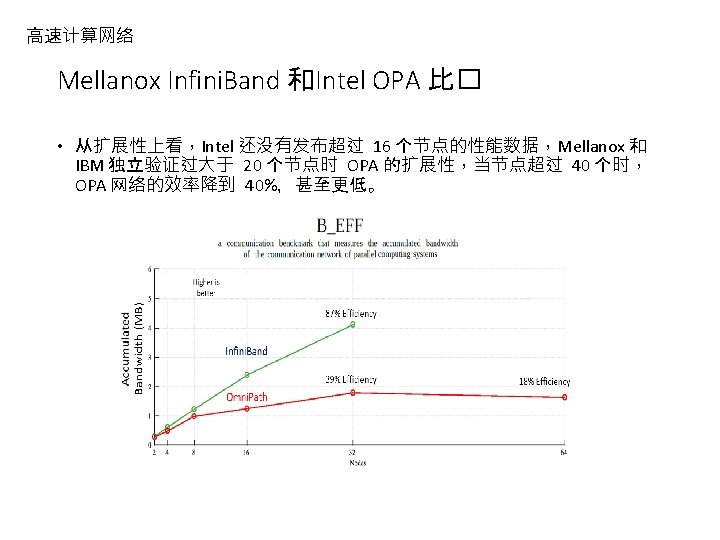
高速计算网络 Mellanox Infini. Band 和Intel OPA 比� • SPEC MPI 2007 Benchmark Suite