Climatic Research Unit CRU Datasets and some analyses
 Datasets – and some analyses! Phil Jones Climatic Research Unit")



 monthly")





 I. Harris et al. , 2013: Updated high-resolution")


 • Ever since we first produced the hemispheric averages, we’ve been")
 • Variance adjustment still omitted the effect on largescale averages of regions")
 Red – homogeneity issues Green –")
 • • Used in 2012 releases to ensure users took")
 Includes the error estimate")



")
 versus the infilled CRU dataset (CRU TS 3. 10, LHS)")

 and differences (20 CR minus conventional datasets)")
 - annual")
 - annual")



- Slides: 37
Climatic Research Unit (CRU) Datasets – and some analyses! Phil Jones Climatic Research Unit University of East Anglia Norwich, NR 4 7 TJ, UK
Summary • Datasets • Data needs to be on the web • Where possible data needs to contain uncertainties • Dataset needs to have a peer-review publication to back it up
First • Don’t say, I used CRU data! I’ve seen this in a few papers I’ve been sent for review and also in countless emails, where the sender asks for details on how and sometimes why they should be using the data? • CRU has dataset names for a purpose – for people to refer to them by! We will be moving to DOIs, but there are issues here with regular updates • Most of our datasets are backed up by peer-review papers. These give details about their construction. The web site gives some details, mainly on lay-out, units etc. We can’t put some papers up • CRU datasets are generally supplied in netcdf and ascii (for smaller ones). It is up to users to read them into software • CRU isn’t able to extract windows out of the globalscale gridded datasets
Datasets • Here I’ll be discussing these three datasets • CRUTEM 4 (Jones, P. D. , Lister, D. H. , Osborn, T. J. , Harpham, C. , Salmon, M. , Morice, C. P. 2012: Hemispheric and large-scale land surface air temperature variations: An extensive revision and an update to 2010. J. Geophys. Res. 117, D 05127, doi: 10. 1029/2011 JD 017139 ) • Had. CRUT 4 (Morice, C. P. , Kennedy, J. J. , Rayner, N. A. and Jones, P. D. , 2012: Quantifying uncertainties in global and regional temperature change using an ensemble of observational estimates: the Had. CRUT 4 dataset. Journal of Geophysical Research, 117, D 08101, doi: 10. 1029/2011 JD 017187 ) • CRU TS 3. 10 (Harris, I. , Jones, P. D. , Osborn, T. J. and Lister, D. H. , 2013: Updated high-resolution grids of monthly climatic observations– the CRU TS 3. 10 Dataset. Int. J. ) • These are by no means all the datasets at CRU Climatol. (in press)
What are the datasets? • CRUTEM 4 – gridded (5° by 5° lat/long) monthly temperature anomalies (from 1961 -90) based on land stations. Extends from 1850 and does no infilling, so if there are no station data, the grid-box value is missing • Had. CRUT 4 – combination of CRUTEM 4 with Had. SST 3 (a similar gridded dataset of SST anomalies) • Both Had. CRUT 4 and CRUTEM 4 updated monthly, but much more extensively every year (~April) with updated homogenized data provided offline or through websites from NMSs • CRU TS 3. 10 – gridded (0. 5° by 0. 5° lat/long) monthly anomalies (from 1961 -90) mean temperature, DTR, precipitation total, vapour pressure, sunshine and potential evapotranspiration (PET). Extends from 1901 and is as spatially complete as possible for all variables Interpolation/extrapolation only occurs over land areas. The Antarctic (south of 60°S is missing)
Citation Statistics • The current three versions are quite new, but there were earlier versions of all three datasets (CRUTEM 2/3, Had. CRUT 2/3, CRUS TS 1. 0/2. 1) • Which dataset gets the most citations? • Reason is that it puts the data as anomalies and absolute values, and derives national averages for ~200 countries and territories • Some data papers appear to get more citations than modelling/analysis papers, even though many don’t put the reference in
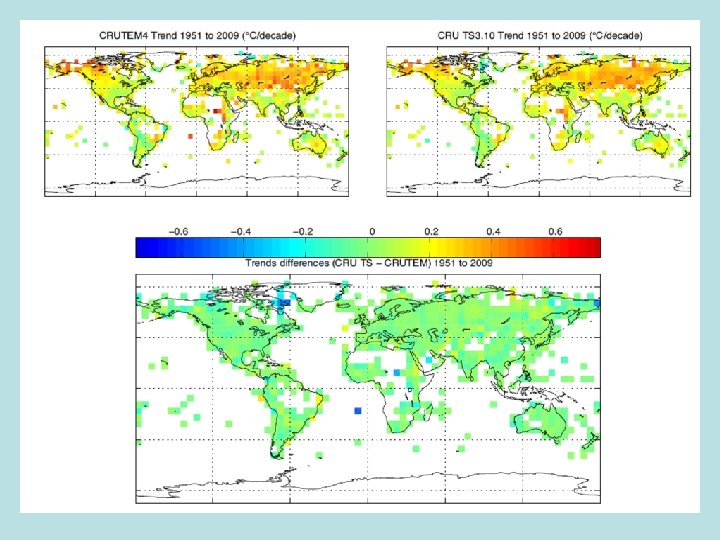
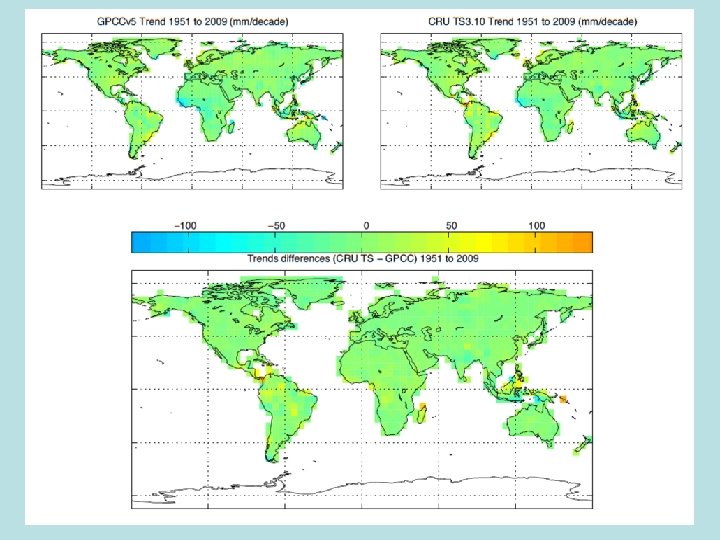
An initial comparison • CRU TS 3. 10 is complete over global land (except Antarctica) • Next plot degrades its resolution to CRUTEM 4 and then removes all missing areas that are in CRUTEM 4 • Comparison plots of trends 1951 -2009 • Subsequent slide shows whether the trends are significantly different. Only two boxes show a difference • Similar pair of plots comparing CRU TS 3. 10 for Precipitation against GPCCv 5 (from the Global Precipitation Climatology Centre at DWD) • Similar comparisons for additional periods (1901 -50 and 19012009)
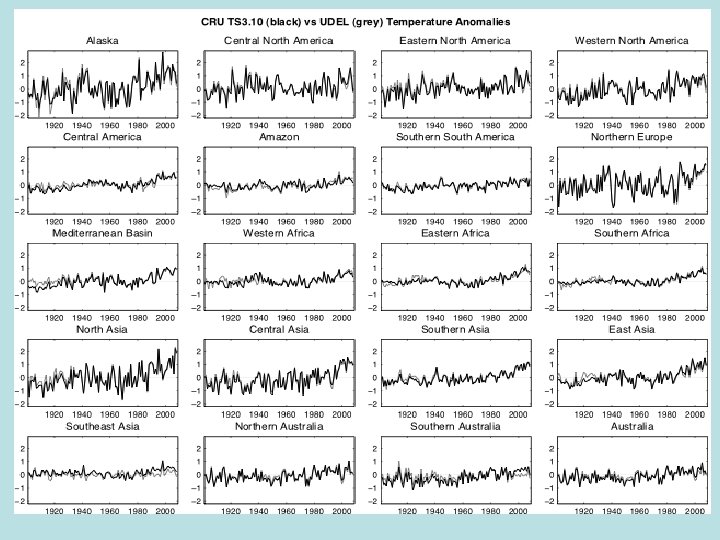
Series at smaller scales (region definition) I. Harris et al. , 2013: Updated high-resolution grids of monthly climatic observations – the CRU TS 3. 10 Dataset. Int. J. Climatol. (in press)
Underlying Station Data/Code • Partly because, we’ve included station series sent to us by National Met Services (NMSs) we have been not able to release the individual station series • In late 2009, we contacted all NMSs to see if we could release the station series we have for their countries. Only 40% replied and only one country said no. With the UK Met Office we decided to overrule Poland released all the station data. The station series are updated each year • We intend to release all the station data for the CRU TS 3. 10 dataset as well • The Met Office released a version of the code to calculate CRUTEM 3/4. This is not the original Fortran, but a version in Perl which works with a free compiler • GPCC (part of DWD) have lots of different version of their gridded precipitation products, but don’t release the underlying station data. Difficult, therefore, to know where some of their ‘oddish’ values come from • Issue is becoming one of gridded datasets being traceable back to the original ‘raw’ data
Updating Issues • Our principle of homogeneity adjustment is to make as much use as possible of these types of data produced by National Met Services (NMSs) • This means that each year we have to access NMS web sites to update series • Generally, we find that many NMSs have improved their homogeneity and added new long series, so updating is not straightforward • We must check each series against what we had and recalculate 1961 -90 normals • NCDC are updating their homogeneity exercise every month now, but only updating the stations once a year • As mentioned earlier, dataset doi’s and regular updates is not that clear
Uncertainties (grid boxes) • Ever since we first produced the hemispheric averages, we’ve been asked about the accuracy of the hemispheric averages and also the individual grid-box series • To address this, we developed variance adjusted versions for CRUTEM 2/3/4 so CRUTEM 2 v/3 v/4 v and also for Had. CRUT 2 v/3 v • Variance adjustment (Jones et al. , 1997) attempts to make each grid-box series internally consistent and not affected by changing station numbers (each series is adjusted to one based on an infinitely sampled grid box) • This study leads to the concept of the effective number of spatial degrees of freedom (Neff), which decreases with increasing timescale. The number is larger for some variables, such as precipitation, which are much more spatially variable • For temperature, the fact that (Neff) is smaller at larger timescales enables proxy reconstructions to be made • Jones, P. D. , Osborn, T. J. and Briffa, K. R. , 1997: Estimating sampling errors in large-scale temperature averages. J. Climate 10, 2548 -2568.
Uncertainties (Hemispheres/Globe) • Variance adjustment still omitted the effect on largescale averages of regions dropping out in the early years • This was addressed in 2003 and more completely in 2006 by Brohan et al (2006) • Few users used these uncertainty estimates as some components were temporally and spatially dependent • So addressed in Had. CRUT 4 in a different way • Brohan, P. , Kennedy, J. , Harris, I. , Tett, S. F. B. and Jones, P. D. , 2006: Uncertainty estimates in regional and global observed temperature changes: a new dataset from 1850. J. Geophys. Res. 111, D 12106, doi: 10. 1029/2005 JD 006548
Global time-series at annual resolution (Had. CRUT 3) Red – homogeneity issues Green – sampling Blue – buckets Combined error is the sum in quadrataure, as the various errors are uncorrelated
Latest Uncertainties (Ensemble approach) • • Used in 2012 releases to ensure users took the uncertainties properly into account Developed by deriving 100 realizations of the past, drawing from the distributions for the various error and bias components Users wanting just one realization take the best guess for each grid box, and also the best guess for each hemispheric average and the globe An FAQ needed to explain why the best guess for each grid box doesn’t produce the best guess hemispheric and global averages Requirement to understand the structure of the uncertainties and the error estimates of the various components Knowledge of the error structure is vital for addressing approaches to reduce the error. This shows that reductions will come from digitising more data in areas currently without data, and not from regions that already have extensive coverage – so need more series from Africa than more in parts of North America Also improvements will come from improved methods of adjusting for biases in both the marine and land components
Comparison of CRUTEM 4 with papers by Callendar (1938, 1961) Includes the error estimate ranges for CRUTEM 4 developed by Morice et al (2012) Further comparisons with earlier work in Ch 1 of WG 1 from AR 4
Had. CRUT 4 vs other groups Each series has its full coverage
Web Locations • http: //www. cru. uea. ac. uk/data • CRUTEM 4 and Had. CRUT 4 are also available at • http: //www. metoffice. gov. uk/hadobs/crute m 4/ • http: //www. metoffice. gov. uk/hadobs/hadcr ut 4/
20 CR LSAT trends compared to conventional large-scale averages • Paper by Compo et al. (2013) accepted by GRL
20 CR LSAT versus conventional series for land (90 N-60 S)
20 CR (RHS) versus the infilled CRU dataset (CRU TS 3. 10, LHS)
Trends over 1952 -2010
Separate plots for LSAT (90 N-60 S) and differences (20 CR minus conventional datasets) 20 CR seems far too warm in some WW 2 years
UK (50 -60°N, 0 -10°W) - annual
NZ (165 -180°E, 35 -50°S) - annual
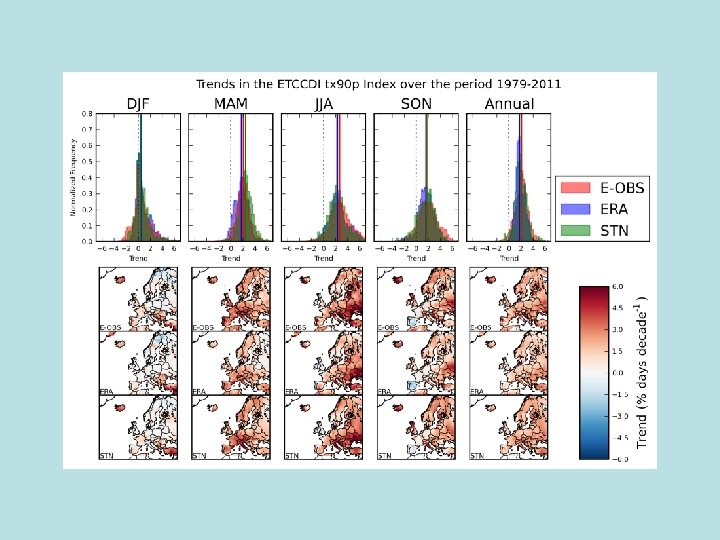
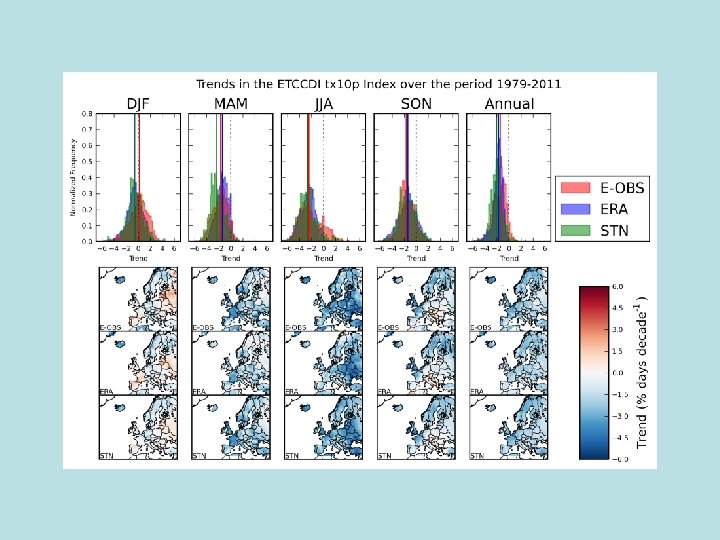
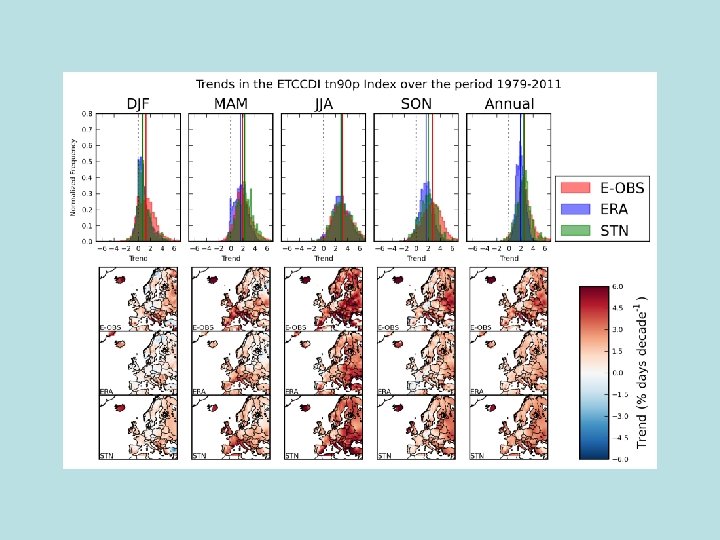
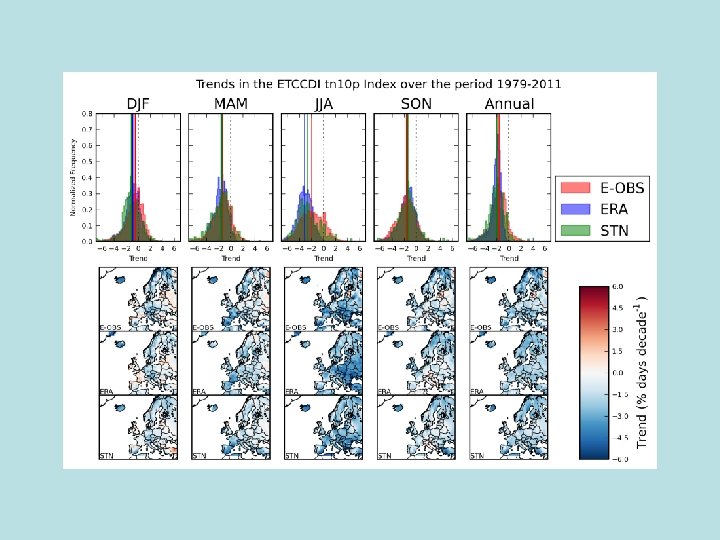
Using ERA-Interim to assess changes in extremes across Europe • Uses 1979 -2010 for ERA-Interim and compares the trends in extremes with station data from E-OBS, and also the E-OBS grids • Four indices of extremes (Tx 90 p, Tx 10 p, Tn 90 p and Tn 10 p) all calculated using the ETCCDI software • Work not yet completed
Peer-Review papers • Useful to have these to back up datasets. IPCC requires this! • Not necessary to update regularly, but useful if this can be done • Don’t worry that datasets don’t always get referenced • Dataset journals coming along, setting up doi’s for datasets in a similar way to papers
Conclusions • Many CRU datasets, as there are many datasets at NCDC and different versions of GCM/RCM simulations • This compared CRU’s high (CRU TS 3. 10) and low resolution (CRUTEM 4) datasets and also with the GPCCv 5 precipitation dataset • Using as much NMS-homogeneity adjusted land data means updating in near-real time creates additional burdens • Uncertainties addressed at the grid-box and the larger-scale levels • To use these effectively, the latest version of our combined dataset (Had. CRUT 4) provides multiple realizations of the past (in an ensemble nature similar to many GCM simulations) • Knowledge of the error structure is vital to developing effective ways of reducing the error