Classification Supervised learning Supervised vs Unsupervised Methods Data




 � Maka berdasarkan klasifikasi dari data")
 Bayes � Decision Tree based Methods �")



 Algorithm � K-NN merupakan instance-based learning, dimana data training disimpan sehingga")

 pasien 2 (drug")
? � Bagaimana")

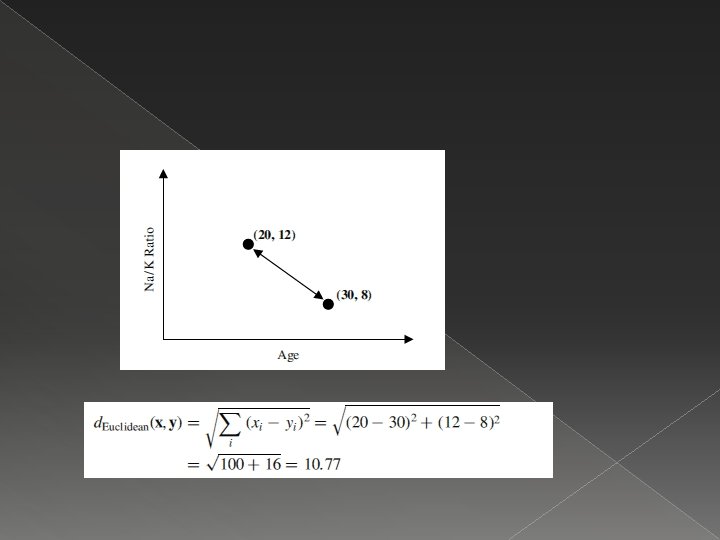

 Maka jarak antara pasien A &")
=0. 6, d(A, C)=1 sehingga dihasilkan pasien")





- Slides: 24
Classification Supervised learning
Supervised vs Unsupervised Methods � Data mining dapat dikategorikan sebagai supervised ataupun unsupervised. � Dalam unsupervised method, tidak ada variabel tujuan yg diidentifikasikan. � Kebanyakan metoda data mining adalah supervised method, yang berarti : › Ada variabel target yg dispesifikasi sebelumnya › Algoritma diberikan beberapa contoh di mana nilai dari variabel target disediakan sehingga algoritma dapat mempelajari yg mana nilai variabel target berhubungan dengan yg mana nilai variabel pemrediksi.
Methodology for Supervised Modelling � Algoritma disediakan data training untuk membuat model yg diaplikasika n pada data test
Classification Task � Beberapa contoh fungsi klasifikasi: › Banking: �Pemberian kredit good or bad credit risk �Transaksi kartu kredit fraudulent or not › Education: �Penempatan student baru ke suatu jalur tertentu › Medicine: �Mendiagnosa apakah keberadaan jenis penyakit › Law: �Menentukan akan penulisan terhadap yg meninggal atau pemalsuan › Homeland security: �Mengidentifikasikan apakah seseotang yg berperilaku mendikasikan kemungkan ancaman teroris.
� Contoh kutipan pengklasifikasian pendapatan. (sebagai data training) � Maka berdasarkan klasifikasi dari data training, akan dapat mengassign rekord baru, misal seorang profesor wanita berusia 63 th mgkn diklasifikasikan ke high-income
Classification Techniques � Nearest-neighbor � Naïve (KNN) Bayes � Decision Tree based Methods � Rule-based Methods � Support Vector Machines � Neural Networks � Boosting, Bagging, Random Forests
Nearest Neighbor Classifiers � Basic idea: › Jika dia berjalan seperti itik, maka dia itik Test Record Training Records Choose k of the “nearest” records
K-Nearest Neighbor � K-nearest neighbors dari suatu record x: titik 2 data yg memiliki k terkecil jarak ke x
Nearest Neighbor Classifiers l Requires three things – The set of stored records – Distance Metric to compute distance between records – The value of k, the number of nearest neighbors to retrieve l To classify an unknown record: – Compute distance to other training records – Identify k nearest neighbors – Use class labels of nearest neighbors to determine the class label of unknown record (e. g. , by taking majority vote)
K-Nearest Neighbor (KNN) Algorithm � K-NN merupakan instance-based learning, dimana data training disimpan sehingga klasifikasi untuk record baru yg belum diklasifikasi dpt ditemukan dengan membandingkan kemiripan yang paling banyak dalam data training.
Contoh: scatter plot untuk rasio sodium/ potasium thd umur � � � 200 pasien Y light gray X dark gray (A) B, C medium gray
� Jika ada pasien baru, maka dilihat yg paling dekat (k=1) pasien 2 (drug A)
Important issue in K-NN � Berapa banyak neighbor yg seharusnya dipertimbangkan (k)? � Bagaimana mengukur jarak? � Bagaimana mengkombinasikan informasi dari lebih dari satu observasi? � Haruskah seluruh titik sama bobotnya, atau beberapa titik memiliki informasi lebih dari yg lain
DISTANCE FUNCTION � Fungsi jarak yang paling umum digunakan Euclidean distance � Dimana, x=x 1, x 2, …xm, dan y 1, y 2, …ym merepresentasikan nilai atribut m dari dua rekord
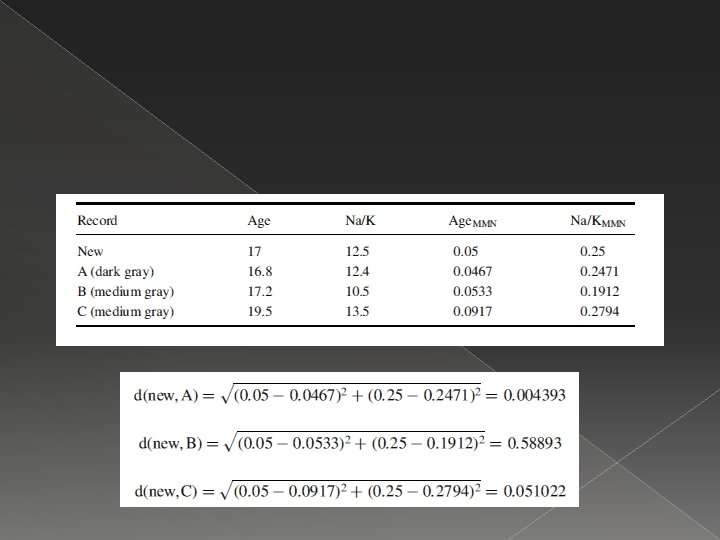
� Untuk data kontinyu bisa juga digunakan rumusan normalisasi/ standarisasi sebelum dilakukan klasifikasi: � Untuk variabel kategori:
Contoh: nilai variable untuk age & gender (k=1) Maka jarak antara pasien A & B d(A, B)=√[(50 -20)2 + 02]= 30; dan jarak antara A & C d(A, C)= √[(50 -50)2 + 12]=1 � Hal ini berarti pasien A lebih similar ke C daripada ke B �
Jika dilakukan normalisasi min-max, maka ditemukan: d(A, B)=0. 6, d(A, C)=1 sehingga dihasilkan pasien B lebih mirip ke pasien A � Dan juga bila dilakukan Z-score standarization, maka dihasilkan: d(A, B)=0. 6, d(A, C)=1, sehingga didapatkan pasien C yg lebih mirip ke pasien A � Sering terjadi penyimpangan yg dilakukan oleh normalisasi min-max �
Combination Function � Simple Unweighted Voting 1. Menentukan k, jml rekord yg memiliki suara dalam pengklasifikasian rekord baru 2. Membandingkan rekord baru ke k-nn, yakni k rekord yg berjarak minim dalam ukuran jarak 3. Sekali k rekord dipilih, maka yg diperhatikan jaraknya. Satu record satu vote � Maka bila terdapat k=3, dan terdapat 2 rekord yg lebih dekat ke suatu record (misal: medium gray), maka memiliki confidence 66. 67%
� Weighting Voting › Diharapkan memperkecil kesalahan › Merupakan kebalikan proporsi jarak dari rekord baru dengan klasifikasi. › Vote dibobotkan dengan inverse square dari nilai jarak
� Sehingga gray dipilih vote tertinggi yakni dark
Quantifying Attribute Relevance: Stretching the Axes � Adanya kemungkinan suatu atribut memiliki informasi yg penting thd yg lain, maka dilakukan pengalian terhadap nilai tertentu. Misal adanya informasi Na/K ratio tiga kali lebih penting dari age, maka untuk pencarian jarak sbb:
Choosing k Pemilihan k yg terlalu kecil menyebabkan sensitive terhadap noise � Namun k terlalu besar, neighborhood dapat mencangkup titik 2 dari kelas lain � Sehingga dilakukan pemilihan dengan meminimkan estimasi error pengklasifikasian �