CIS 501 Computer Architecture Unit 13 DataLevel Parallelism


 • Single operation repeated on multiple data elements")
 • Extend ISA with vector storage … • Vector")
![Example Use of Vectors – 4 -wide ldf [X+r 1]->f 1 mulf f 0,](https://slidetodoc.com/presentation_image_h/061dcb475f470e8ef602d01f134e7e69/image-5.jpg "Example Use of Vectors – 4 -wide ldf [X+r 1]->f 1 mulf f 0,")











 • Slides from Hot. Chips 2017 • https:")





- Slides: 45
CIS 501: Computer Architecture Unit 13: Data-Level Parallelism & Accelerators Slides developed by Joe Devietti, Milo Martin & Amir Roth at UPenn with sources that included University of Wisconsin slides by Mark Hill, Guri Sohi, Jim Smith, and David Wood CIS 501: Comp. Arch. | Prof. Joe Devietti | Accelerators 1
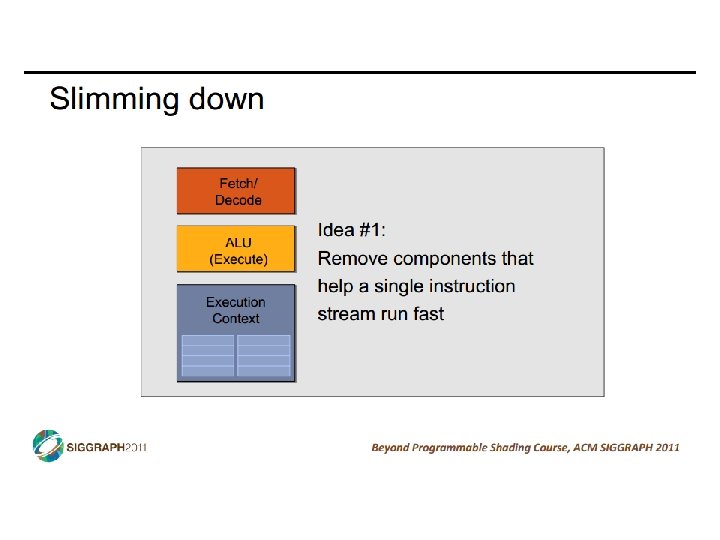
How to Compute This Fast? • Performing the same operations on many data items • Example: SAXPY for (I = 0; I < 1024; I++) { Z[I] = A*X[I] + Y[I]; } L 1: ldf [X+r 1]->f 1 // I is in r 1 mulf f 0, f 1 ->f 2 // A is in f 0 ldf [Y+r 1]->f 3 addf f 2, f 3 ->f 4 stf f 4 ->[Z+r 1} addi r 1, 4 ->r 1 blti r 1, 4096, L 1 • Instruction-level parallelism (ILP) - fine grained • Loop unrolling with static scheduling –or– dynamic scheduling • Wide-issue superscalar (non-)scaling limits benefits • Thread-level parallelism (TLP) - coarse grained • Multicore • Can we do some “medium grained” parallelism? CIS 501: Comp. Arch. | Prof. Joe Devietti | Accelerators 2
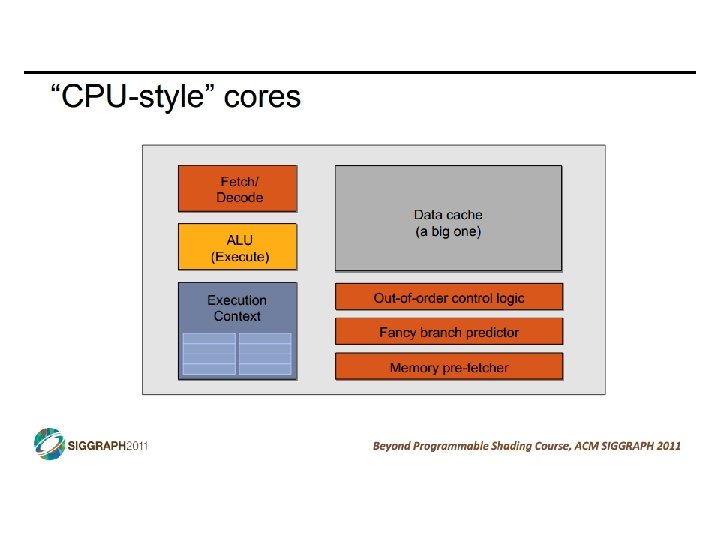
Data-Level Parallelism • Data-level parallelism (DLP) • Single operation repeated on multiple data elements • SIMD (Single-Instruction, Multiple-Data) • Less general than ILP: parallel insns are all same operation • Exploit with vectors • Old idea: Cray-1 supercomputer from late 1970 s • Eight 64 -entry x 64 -bit floating point “vector registers” • 4096 bits (0. 5 KB) in each register! 4 KB for vector register file • Special vector instructions to perform vector operations • Load vector, store vector (wide memory operation) • Vector+Vector or Vector+Scalar • addition, subtraction, multiply, etc. • In Cray-1, each instruction specifies 64 operations! • ALUs were expensive, so one operation per cycle (not parallel) CIS 501: Comp. Arch. | Prof. Joe Devietti | Accelerators 3
Example Vector ISA Extensions (SIMD) • Extend ISA with vector storage … • Vector register: fixed-size array of FP/int elements • Vector length: For example: 4, 8, 16, 64, … • … and example operations for vector length of 4 • Load vector: ldf. v [X+r 1]->v 1 ldf [X+r 1+0]->v 10 ldf [X+r 1+1]->v 11 ldf [X+r 1+2]->v 12 ldf [X+r 1+3]->v 13 • Add two vectors: addf. vv v 1, v 2 ->v 3 addf v 1 i, v 2 i->v 3 i (where i is 0, 1, 2, 3) • Add vector to scalar: addf. vs v 1, f 2, v 3 addf v 1 i, f 2 ->v 3 i (where i is 0, 1, 2, 3) • Today’s vectors: short (128 -512 bits), but fully parallel CIS 501: Comp. Arch. | Prof. Joe Devietti | Accelerators 4
Example Use of Vectors – 4 -wide ldf [X+r 1]->f 1 mulf f 0, f 1 ->f 2 ldf [Y+r 1]->f 3 addf f 2, f 3 ->f 4 stf f 4 ->[Z+r 1] addi r 1, 4 ->r 1 blti r 1, 4096, L 1 7 x 1024 instructions • Operations • • ldf. v [X+r 1]->v 1 mulf. vs v 1, f 0 ->v 2 ldf. v [Y+r 1]->v 3 addf. vv v 2, v 3 ->v 4 stf. v v 4, [Z+r 1] addi r 1, 16 ->r 1 blti r 1, 4096, L 1 7 x 256 instructions (4 x fewer instructions) Load vector: ldf. v [X+r 1]->v 1 Multiply vector to scalar: mulf. vs v 1, f 2 ->v 3 Add two vectors: addf. vv v 1, v 2 ->v 3 Store vector: stf. v v 1 ->[X+r 1] • Performance? • Best case: 4 x speedup • But, vector instructions don’t always have single-cycle throughput • Execution width (implementation) vs vector width (ISA) CIS 501: Comp. Arch. | Prof. Joe Devietti | Accelerators 5
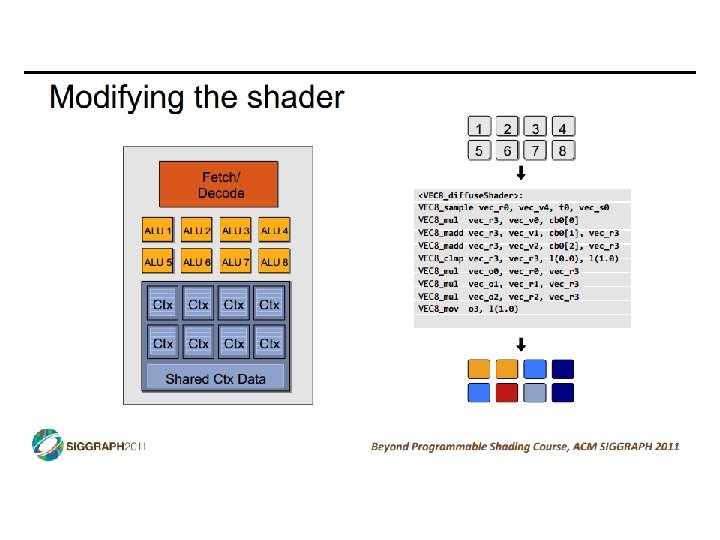
Vector Datapath & Implementatoin • Vector insn. are just like normal insn… only “wider” • • • Single instruction fetch (no extra N 2 checks) Wide register read & write (not multiple ports) Wide execute: replicate floating point unit (same as superscalar) Wide bypass (avoid N 2 bypass problem) Wide cache read & write (single cache tag check) • Execution width (implementation) vs vector width (ISA) • Example: Pentium 4 and “Core 1” executes vector ops at half width • “Core 2” executes them at full width • Because they are just instructions… • …superscalar execution of vector instructions • Multiple n-wide vector instructions per cycle CIS 501: Comp. Arch. | Prof. Joe Devietti | Accelerators 6
Vector Insn Sets for Different ISAs • x 86 • Intel and AMD: MMX, SSE 2, SSE 3, SSE 4, AVX 2 • currently: AVX 512 offers 512 b vectors • Power. PC • Alti. VEC/VMX: 128 b • ARM • NEON: 128 b • Scalable Vector Extensions (SVE): up to 2048 b • implementation is narrower than this! CIS 501: Comp. Arch. | Prof. Joe Devietti | Accelerators 7
By the numbers: CPUs vs GPUs Intel Xeon Platinum 8168 “Skylake” Nvidia Quadro GV 100 Intel Xeon Phi 7290 F frequency 2. 7 GHz 1. 1 GHz 1. 5 GHz cores / threads 24 / 48 80 (“ 5120”) / 10 Ks 72 / 288 RAM 768 GB 32 GB 384 GB DP TFLOPS 1. 0 5. 8 3. 5 Transistors >5 B ? 21. 1 B >5 B ? Price $5, 900 $9, 000 $3, 400 CIS 501: Comp. Arch. | Prof. Joe Devietti | Accelerators 12
• following slides c/o Kayvon Fatahalian’s “Beyond Programmable Shading” course • http: //www. cs. cmu. edu/~kayvonf/ CIS 501: Comp. Arch. | Prof. Joe Devietti | Accelerators 16
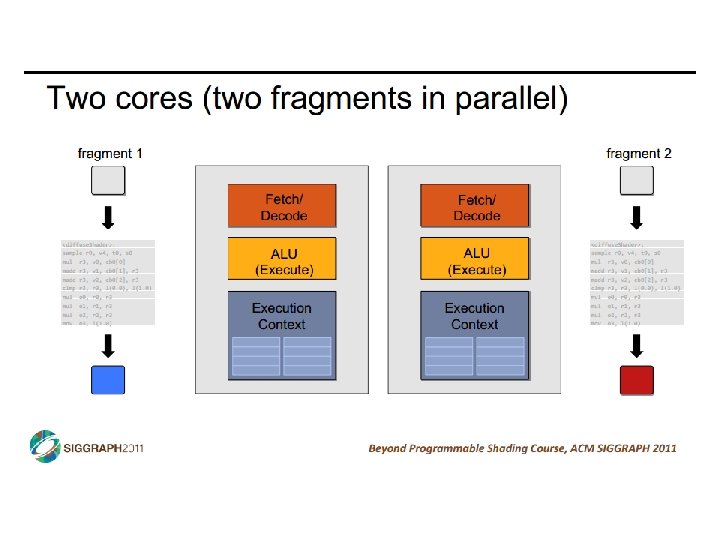
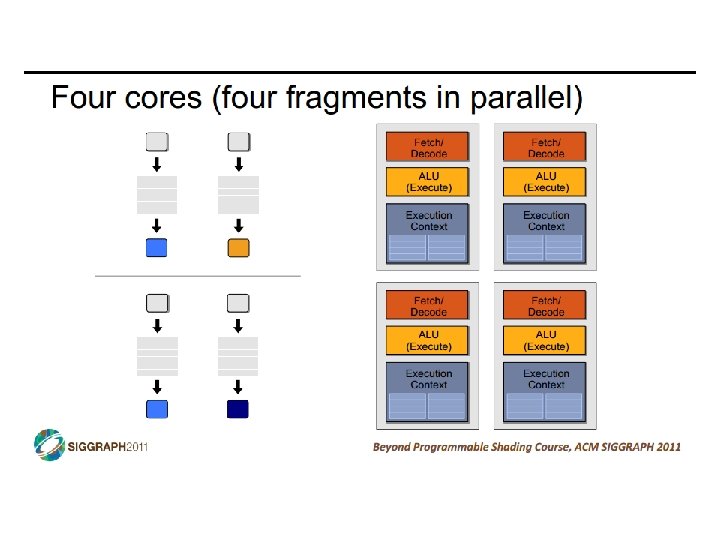
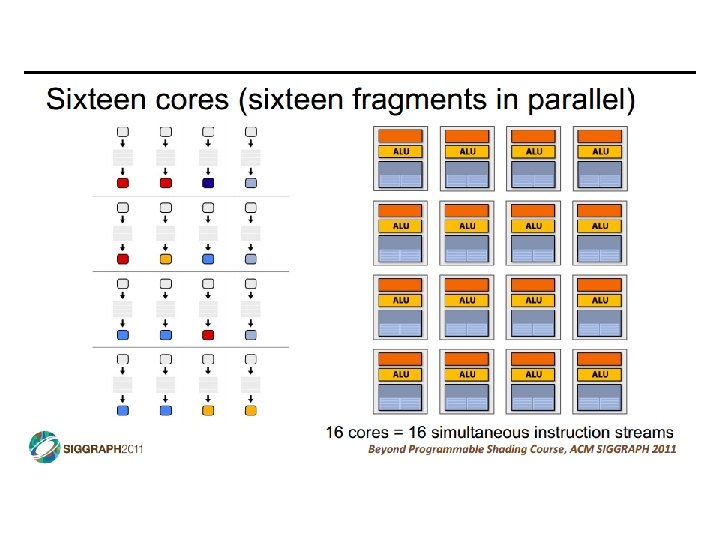
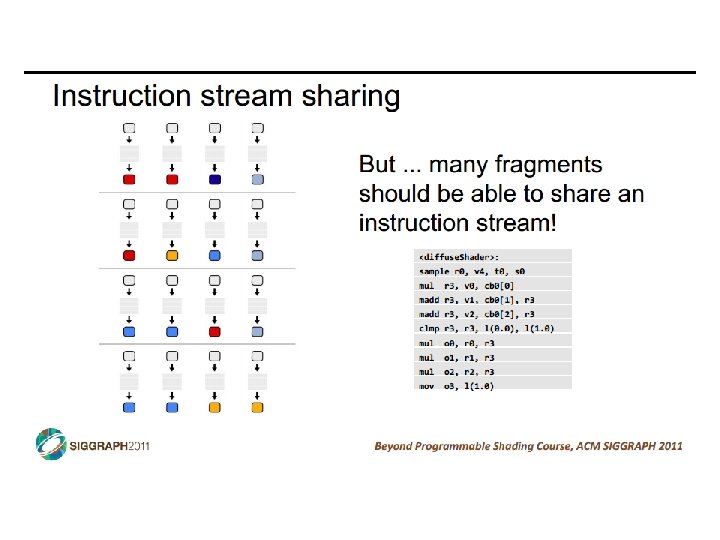
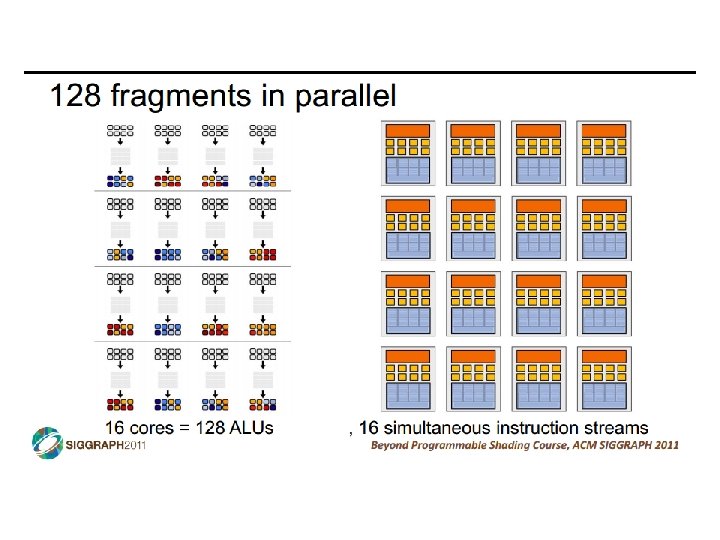
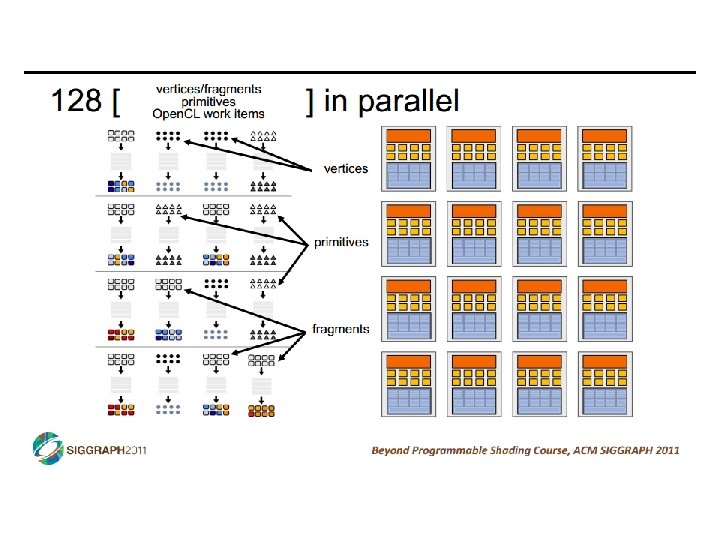
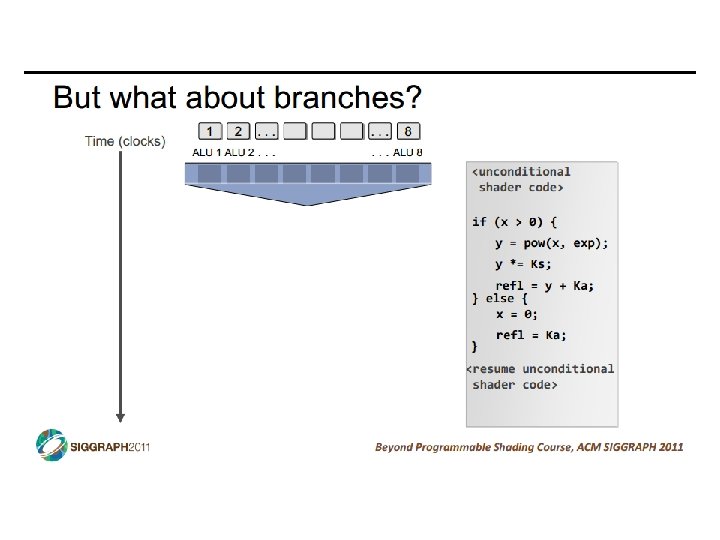
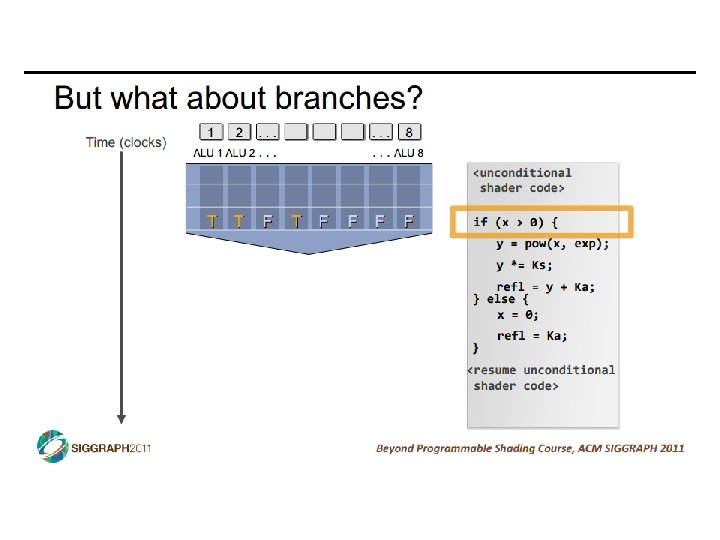
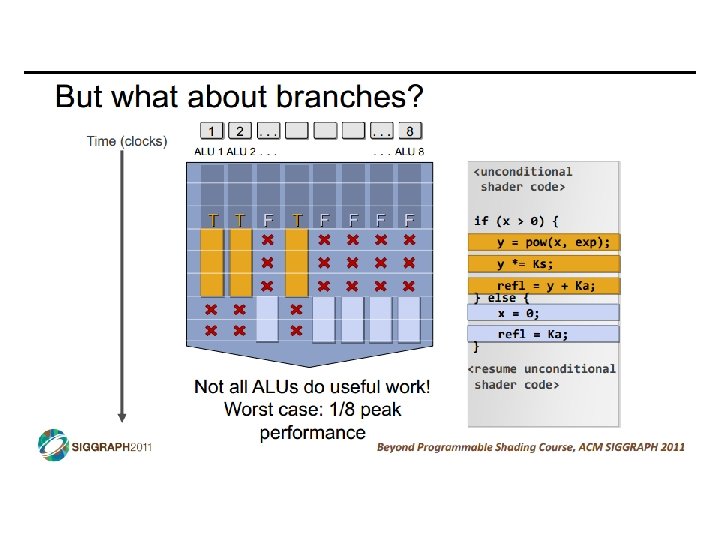
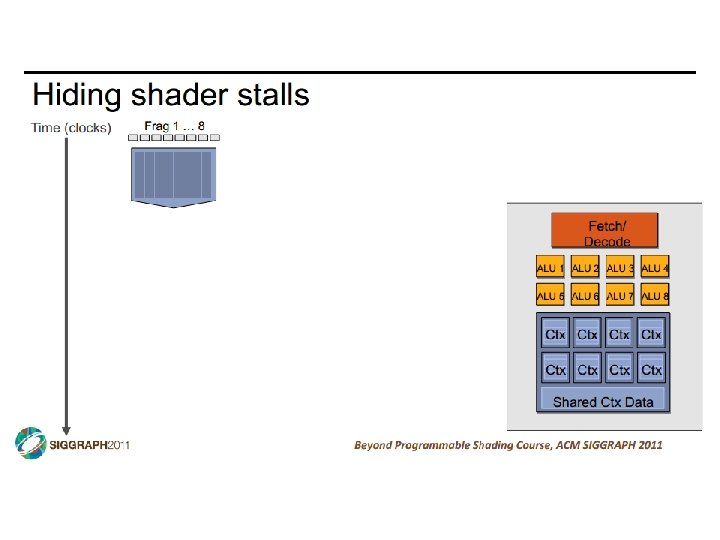
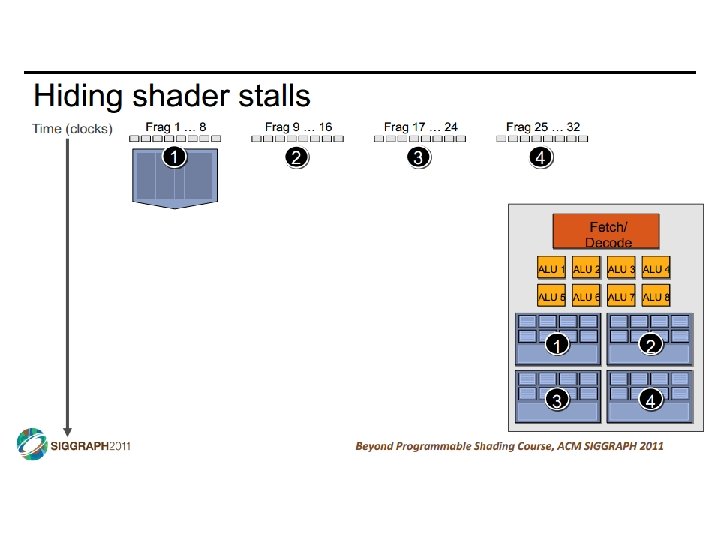
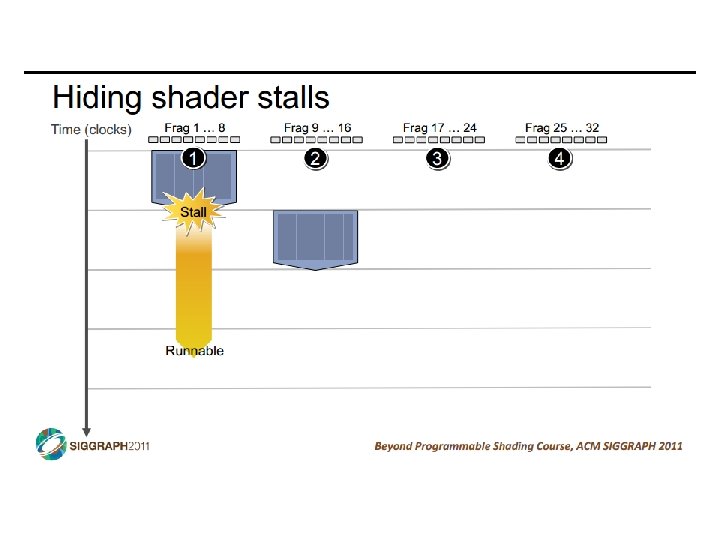
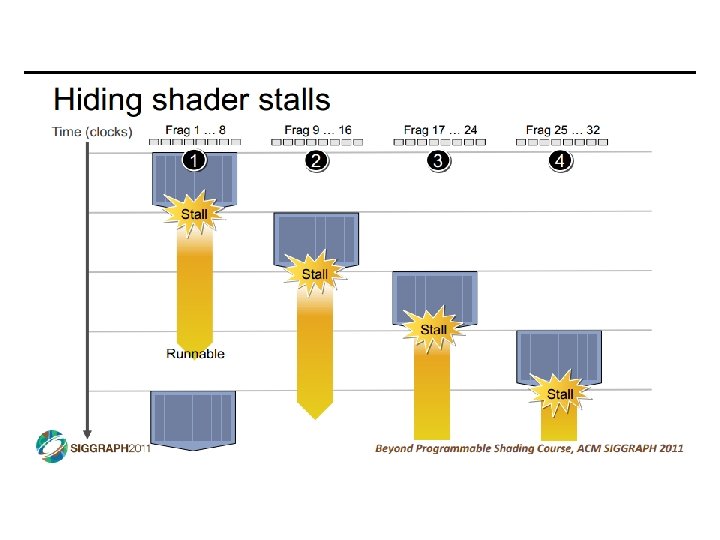
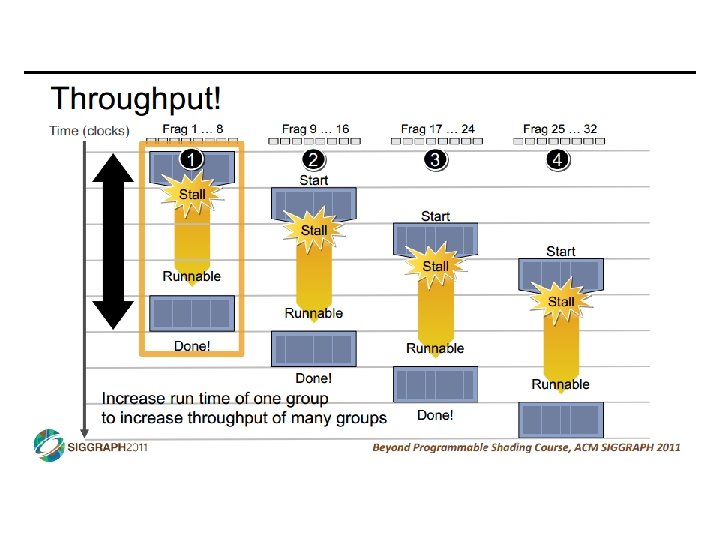
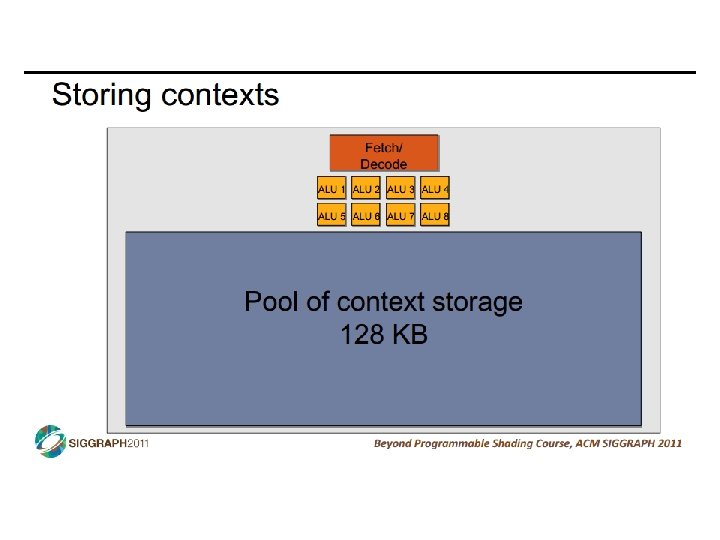
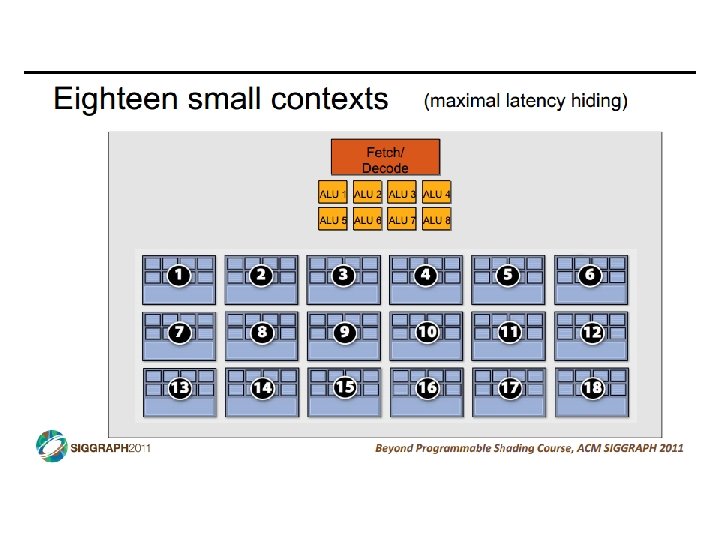
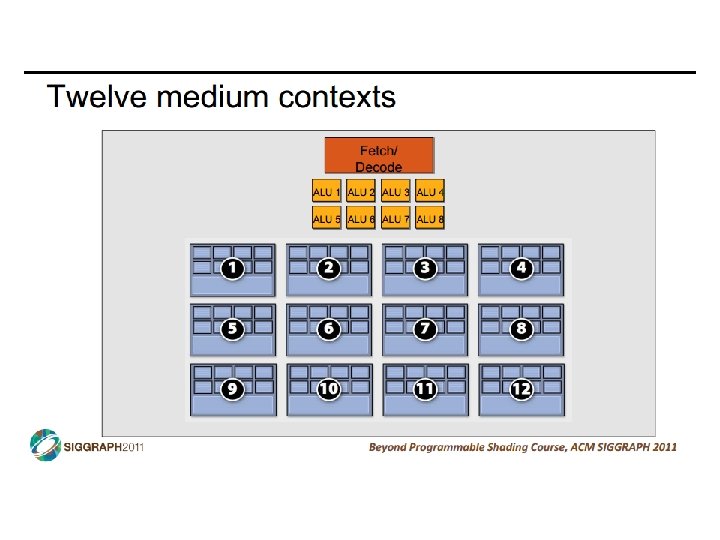
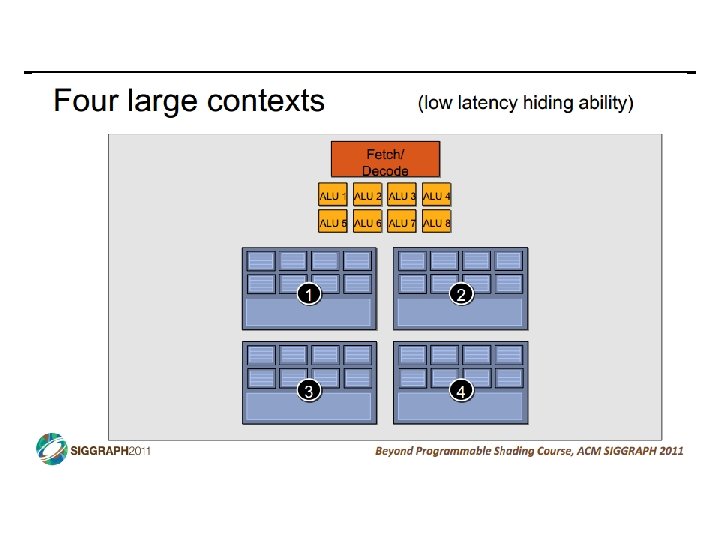
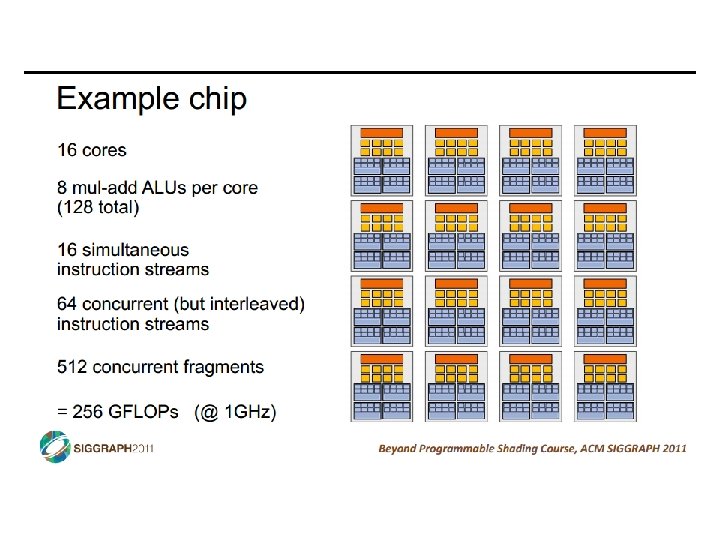
SIMD vs SIMT • SIMD: single insn multiple data • write 1 insn that operates on a vector of data • handle control flow via explicit masking operations • SIMT: single insn multiple thread • write 1 insn that operates on scalar data • each of many threads runs this insn • compiler+hw aggregate threads into groups that execute on SIMD hardware • compiler+hw handle masking for control flow CIS 501: Comp. Arch. | Prof. Joe Devietti | Accelerators 38
Google Tensor Processing Unit (v 2) • Slides from Hot. Chips 2017 • https: //www. hotchips. org/wpcontent/uploads/hc_archives/hc 29/HC 29. 22 -Tuesday. Pub/HC 29. 22. 69 -Key 2 -AI-MLPub/Hot. Chips%20 keynote%20 Jeff%20 Dean%20%20 August%202017. pdf CIS 501: Comp. Arch. | Prof. Joe Devietti | Accelerators 54
CIS 501: Comp. Arch. | Prof. Joe Devietti | Accelerators 55
CIS 501: Comp. Arch. | Prof. Joe Devietti | Accelerators 56
TPU v 1 ISA CIS 501: Comp. Arch. | Prof. Joe Devietti | Accelerators 57
Systolic Array Matrix Multiply • https: //storage. googleapis. com/gweb-cloudblogpublish/original_images/Systolic_Array_for_Neural_Networ k_2 g 8 b 7. GIF CIS 501: Comp. Arch. | Prof. Joe Devietti | Accelerators 58
Accelerators Summary • Data Level Parallelism • “medium-grained” parallelism between ILP and TLP • Still one flow of execution (unlike TLP) • Compiler/programmer must explicitly express it (unlike ILP) • GPUs • Embrace data parallelism via “SIMT” execution model • Becoming more programmable all the time • TPUs • Neural network accelerator • Fast matrix multiply machine • Slow growth in single-thread performance, Moore’s Law drives adoption of accelerators CIS 501: Comp. Arch. | Prof. Joe Devietti | Accelerators 59