Chapter One Introduction to Pipelined Processors Principle of

")













 and 4 floating")



 4 Control 3 2")

 4 Control")
 4 Control")




: set of resource objects whose data objects")

 • The necessary condition for this hazard is")
 • Example: I 1 : LOAD r 1, a I")
 • The necessary condition is")
 • Example I 1 : MUL r 1, r 2 I")
 • The necessary condition is")
 • • Example: I 1 : MUL r 1, r 2")

- Slides: 38
Chapter One Introduction to Pipelined Processors
Principle of Designing Pipeline Processors (Design Problems of Pipeline Processors)
Internal Data Forwarding and Register Tagging
Internal Forwarding and Register Tagging • Internal Forwarding: It is replacing unnecessary memory accesses by register-to-register transfers. • Register Tagging: It is the use of tagged registers for exploiting concurrent activities among multiple ALUs.
Internal Forwarding • Memory access is slower than register-toregister operations. • Performance can be enhanced by eliminating unnecessary memory accesses
Internal Forwarding • This concept can be explored in 3 directions: 1. Store – Load Forwarding 2. Load – Load Forwarding 3. Store – Store Forwarding
Store – Load Forwarding
Load – Load Forwarding
Store – Store Forwarding
EXAMPLE Example
EXAMPLE Example
Register Tagging
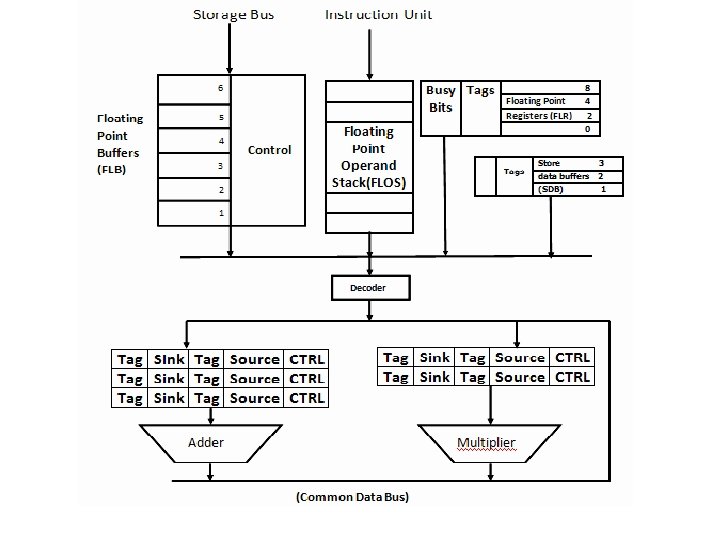
Example : IBM Model 91 : Floating Point Execution Unit
Example : IBM Model 91 -FPU • The floating point execution unit consists of : – Data registers – Transfer paths – Floating Point Adder Unit – Multiply-Divide Unit – Reservation stations – Common Data Bus
Example : IBM Model 91 -FPU • There are 3 reservation stations for adder named A 1, A 2 and A 3 and 2 for multipliers named M 1 and M 2. • Each station has the source & sink registers and their tag & control fields • The stations hold operands for next execution.
Example : IBM Model 91 -FPU • 3 store data buffers(SDBs) and 4 floating point registers (FLRs) are tagged • Busy bits in FLR indicates the dependence of instructions in subsequent execution • Common Data Bus(CDB) is to transfer operands
Example : IBM Model 91 -FPU • There are 11 units to supply information to CDB: 6 FLBs, 3 adders & 2 multiply/divide unit • Tags for these stations are : Unit Tag FLB 1 FLB 2 FLB 3 0001 0010 0011 ADD 2 ADD 3 1010 1011 1100 FLB 4 FLB 5 FLB 6 0100 0101 0110 M 1 M 2 1000 1001
Example : IBM Model 91 -FPU • Internal forwarding can be achieved with tagging scheme on CDB. • Example: • Let F refers to FLR and FLBi stands for ith FLB and their contents be (F) and (FLBi) • Consider instruction sequence ADD F, FLB 1 F (F) + (FLB 1) MPY F, FLB 2 F (F) x (FLB 2)
Example : IBM Model 91 -FPU • During addition : – Busy bit of F is set to 1 – Contents of F and FLB 1 is sent to adder A 1 – Tag of F is set to 1010 (tag of adder) F Busy Bit = 1 Tag=1010
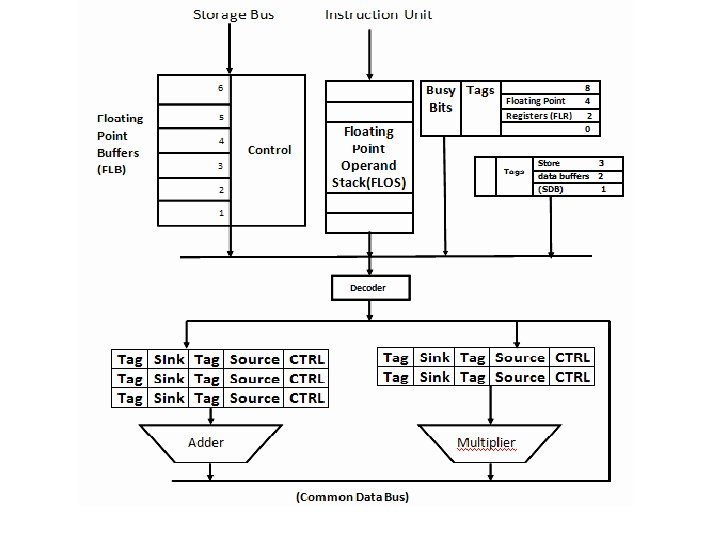
Storage Bus Instruction Unit 6 5 Floating Point Buffers (FLB) 4 Control 3 2 Floating Point Operand Stack(FLOS) Busy Bit = 1 Tag=1010 Tags 1 Decoder Tag Sink 1010 F Tag 0001 Source FLB 1 CTRL Tag Sink Adder Tag Source CTRL Multiplier (Common Data Bus) Store 3 data buffers 2 (SDB) 1
Example : IBM Model 91 -FPU • Meantime, the decode of MPY reveals F is busy, then – F should set tag of M 1 as 1010 (Tag of adder) – F should change its tag to 1000 (Tag of Multiplier) – Send content of FLB 2 to M 1 F Busy Bit = 1 Tag=1000
Storage Bus Instruction Unit Before addition 6 5 Floating Point Buffers (FLB) 4 Control 3 2 Floating Point Operand Stack(FLOS) Busy Bit = 1 Tag=1000 Tags 1 Decoder Tag Sink Tag Source CTRL 1010 F 0010 Tag Sink Tag Adder FLB 2 CTRL Source CTRL Multiplier (Common Data Bus) Store 3 data buffers 2 (SDB) 1
Storage Bus Instruction Unit After addition 6 5 Floating Point Buffers (FLB) 4 Control 3 2 Floating Point Operand Stack(FLOS) Busy Bit = 1 Tag=1000 Tags 1 Decoder Tag Sink Tag Source CTRL 1000 F 0010 Tag Sink Tag Adder FLB 2 CTRL Source CTRL Multiplier (Common Data Bus) Store 3 data buffers 2 (SDB) 1
Example : IBM Model 91 -FPU • When addition is done, CDB finds that the result should be sent to M 1 • Multiplication is done when both operands are available
Hazard Detection and Resolution
Hazard Detection and Resolution • Hazards are caused by resource usage conflicts among various instructions • They are triggered by inter-instruction dependencies Terminologies: • Resource Objects: set of working registers, memory locations and special flags
Hazard Detection and Resolution • Data Objects: Content of resource objects • Each Instruction can be considered as a mapping from a set of data objects to a set of data objects. • Domain D(I) : set of resource of objects whose data objects may affect the execution of instruction I. (e. g. Source Registers)
Hazard Detection and Resolution • Range R(I): set of resource objects whose data objects may be modified by the execution of instruction I. (e. g. Destination Register) • Instruction reads from its domain and writes in its range
Hazard Detection and Resolution • Consider execution of instructions I and J, and J appears immediately after I. • There are 3 types of data dependent hazards: 1. RAW (Read After Write) 2. WAW(Write After Write) 3. WAR (Write After Read)
RAW (Read After Write) • The necessary condition for this hazard is
RAW (Read After Write) • Example: I 1 : LOAD r 1, a I 2 : ADD r 2, r 1 • I 2 cannot be correctly executed until r 1 is loaded • Thus I 2 is RAW dependent on I 1
WAW(Write After Write) • The necessary condition is
WAW(Write After Write) • Example I 1 : MUL r 1, r 2 I 2 : ADD r 1, r 4 • Here I 1 and I 2 writes to same destination and hence they are said to be WAW dependent.
WAR(Write After Read) • The necessary condition is
WAR(Write After Read) • • Example: I 1 : MUL r 1, r 2 I 2 : ADD r 2, r 3 Here I 2 has r 2 as destination while I 1 uses it as source and hence they are WAR dependent
Hazard Detection and Resolution • Hazards can be detected in fetch stage by comparing domain and range. • Once detected, there are two methods: 1. Generate a warning signal to prevent hazard 2. Allow incoming instruction through pipe and distribute detection to all pipeline stages.