Chapter 9 Virtual Memory Chapter 10 Virtual Memory




 n Virtual memory involves the separation of user logical memory from")
 n Virtual address space – logical view of how process is")












 n A page fault causes the following 3")


 프로세스 1이 page")

")
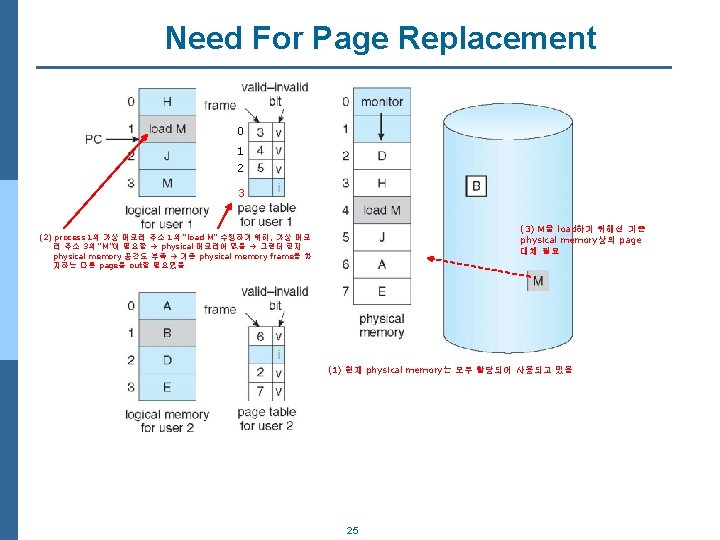




 Algorithm n 3개의 frame을 가지는 physical memory가 있다고 가정하고 page 참조는 다음과")


 Algorithm n Use past knowledge rather than future n Replace")
 n Counter implementation l Associate each page-table entry with a")

 Page-Replacement Algorithm • reference (참조) bit이 0 page 교체. 1이면 한번 더")

")





 n So far all memory accessed equally n Many")
 n Optimal performance comes from allocating memory “close to”")

 • 낮은 CPU 이용률 OS는 더 많은 process를 loading하여 CPU 이용률")








- Slides: 57
Chapter 9: Virtual Memory
Chapter 10: Virtual Memory n Background n Demand Paging n Copy-on-Write n Page Replacement n Allocation of Frames n Thrashing n Memory-Mapped Files n Allocating Kernel Memory n Other Considerations 2
Objectives n To describe the benefits of a virtual memory system n To explain the concepts of demand paging, page-replacement algorithms, and allocation of page frames n To discuss the principle of the working-set model n To examine the relationship between shared memory and memory-mapped files n To explore how kernel memory is managed 3
Background n Code needs to be in memory to execute, but entire program rarely used n Entire program code not needed at same time n The ability to execute a program that is only partially in memory have following benefits: l Program no longer constrained by limits of physical memory l Because each program takes less memory, more programs run at the same time 4 Increased CPU utilization and throughput with no increase in response time or turnaround time l Less I/O (b/w memory & hard disk) needed to load or swap user programs into memory 4 each user program runs faster 4
Background (Cont. ) n Virtual memory involves the separation of user logical memory from physical memory l Only part of the program needs to be in memory for execution l Logical address space can therefore be much larger than physical address space l Allows address spaces to be shared by several processes l Allows for more efficient process creation l More programs running concurrently l Less I/O needed to load or swap processes 5
Background (Cont. ) n Virtual address space – logical view of how process is stored in memory l Usually start at address 0, contiguous addresses until end of space l Meanwhile, physical memory organized in page frames l MMU must map logical to physical n Virtual memory can be implemented via: l Demand paging l Demand segmentation 6
Virtual Memory That is Larger Than Physical Memory n Virtual memory involves the separation of logical memory as perceived by users from physical memory. n This separation allows an extremely large virtual memory to be provided for programmers when only a smaller physical memory is available 7
Virtual-address Space n Usually design logical address space for stack to start at Max logical address and grow “down” while heap grows “up” l Maximizes address space use l Unused address space between the two is hole 4 No physical memory needed until heap or stack grows to a given new page n VA(Virtual Address) space enables sparse address spaces with holes left for growth, dynamically linked libraries, etc n System libraries shared via mapping into virtual address space 8
Shared Library Using Virtual Memory n System libraries can be shared by several processes through mapping of the shared object into a virtual address space. • Although each process considers the libraries to be part of its virtual address space, the actual pages where the libraries reside in physical memory are shared by all the processes n Pages can be shared during process creation with the fork() system call, thus speeding up process creation. 9
Demand Paging n Could bring entire process into memory at load time n Or bring a page into memory only when it is needed Demand paging ! Less I/O needed l Less memory needed l Faster response l More users n Similar to paging system with swapping (diagram on right) n Page is needed reference to it l invalid reference abort l not-in-memory bring to memory n Lazy swapper – swaps a page into memory when page will be needed l Swapper that deals with pages is a pager l 10
Basic Concepts n When a process is to be swapped in, the pager guesses which pages will be used before the process is swapped out again n Instead of swapping in a whole process, the pager brings only those pages into memory l 사용되지 않을 페이지는 메모리로 가져오지 않음으로서 시간 낭비와 메모 리 공간 낭비를 줄일 수 있음 n How to determine that set of pages? l Need new MMU functionality to implement demand paging n If pages needed are already memory resident l No difference from non demand-paging n If page needed and not memory resident l Need to detect and load the page into memory from storage 4 Without changing program behavior 4 Without programmer needing to change code 11
Valid-Invalid Bit n With each page table entry a valid–invalid bit is associated n valid the associated page is both legal & in-memory resident n invalid the page is either not valid(즉, 프로세스의 가상 주소 공간이 아 님) or valid but currently on the disk n Initially valid–invalid bit is set to i on all entries n Example of a page table snapshot: n During MMU address translation, if valid–invalid bit in page table entry is i page fault 12
Page Table When Some Pages Are Not in Main Memory Page table의 valid/invalid bit에서 v는 해당 페이지가 main memory에 있다는 의미 프로세스가 main memory에 없는 페이지를 접근하려고 하면 page fault trap이 발생함 13
Page Fault n If there is a reference to a page, first reference to that page will 1. 2. 3. 4. 5. trap to operating system: page fault Operating system looks at another table to decide: l Invalid reference abort l Just not in memory Find free frame Swap page into frame via scheduled disk operation Reset tables to indicate page now in memory Set validation bit = v Restart the instruction that caused the page fault 14
Steps in Handling a Page Fault § If there is a reference to a page, first reference to that page will trap to operating system: page fault. < the procedure for handling this page fault> Ø We check internal table for this process to determine whether the reference was a valid or an invalid memory access Ø If the reference was invalid, we terminate the process. If it was valid but we have not yet brought in that page, we now page it in. Ø We find a free frame Ø We schedule a disk operation to read the desired page into the newly allocated frame Ø When the disk read is complete, we modify the internal table kept with the 15
Aspects of Demand Paging n Extreme case – start process with no pages in memory l OS sets instruction pointer to first instruction of process, non-memory-resident page fault l And for every other process pages on first access l Pure demand paging (즉, 어떤 페이지가 필요해지기 전에는 결코 그 페이지를 메모리로 적재하지 않음) n Actually, a given instruction could access multiple pages multiple page faults l 예로서, 어떤 프로그램의 읽기 명령어를 포함하는 page가 memory에 사전 loading 되어있지 않았고, 또한, 읽기 대상 data가 여러 page에 걸쳐 있는 경우 l 이때, 해당 읽기 명령 1개 수행시, 여러 page fault 생길 수 있음 성능 저하큼 4 다행스럽게도 많이 발생하지는 않음(locality of reference 때문) n Hardware support needed for demand paging l Page table with valid / invalid bit l Secondary memory (swap device with swap space) l Instruction restart 16
Performance of Demand Paging n Demand Paging can significantly affect the performance of a computer system l To see why, let’s compute the effective access time for a demand-paged memory. l For most computer systems, the memory-access time, denoted ma, ranges from 10 to 200 nanoseconds. 4 As long as we have no page faults, the effective access time is equal to the memory access time. 4 If, however, a page fault occurs, we must first read the relevant page from disk and then access the desired word. l Let p be the probability of a page fault (0 ≤ p ≤ 1). We would expect p to be close to zero—that is, we would expect to have only a few page faults. l The effective access time is then • • ma: memory access time (10 ns~200 ns로 범위) Page fault time: 복잡한 동작 필요하므로 많은 시간 소요(see next page) 17
Performance of Demand Paging n Stages in Demand Paging (when page fault occurs: worst case) 1. Trap to the operating system 2. Save the user registers and process state 3. Determine that the interrupt was from a page fault Page fault Interrupt 발생 확인 4. Check that the page reference was legal and determine the location of the page on the disk ( 페이지 참조가 유효한 것으로 확인 후, 디스크에 있는 페이지 위치 확인) 5. Issue a read from the disk to a free frame (memory): 1. Wait in a queue for this device until the read request is serviced 2. Wait for the device seek and/or latency time 3. Begin the transfer of the page to a free frame Disk 읽기 main memory로 page 이동 (Disk, I/O read시, wait 될 수 있음) 6. While waiting, allocate the CPU to some other user (Disk 읽는동안, CPU는 다른 process수행) 7. Receive an interrupt from the disk I/O subsystem (I/O completed) 8. Save the registers and process state for the other user Disk 모두 읽었다라는 Interrupt 처리 9. Determine that the interrupt was from the disk 10. Correct the page table and other tables to show page is now in memory 11. Wait for the CPU to be allocated to this process again 12. Restore the user registers, process state, and new page table, and then resume the interrupted instruction 프로세스 재시작 18
Performance of Demand Paging (Cont. ) n A page fault causes the following 3 major activities l Service the interrupt – careful coding means just several hundred instructions needed l Read the page – lots of time l Restart the process – again just a small amount of time n Page Fault Rate 0 p 1 l if p = 0, no page faults l if p = 1, every reference is a fault n Effective Access Time (EAT) EAT = (1 – p) x memory access + p (page fault overhead + swap page out + swap page in ) 19
Demand Paging Example n Memory access time = 200 nanoseconds n Average page-fault service time = 8 milliseconds n EAT = (1 – p) x 200 + p x (8 milliseconds) = (1 – p) x 200 + p x 8, 000 = 200 + p x 7, 999, 800 n If one access out of 1, 000 causes a page fault (i. e, p=1/1, 000), then EAT = 8. 2 microseconds. This is a slowdown by a factor of 40!! (200 ns Memory access time보다 약 40배 느려짐) n If you want to keep the performance degradation due to paging less than 10 percent, we should allow fewer than one page-fault (memory access) out of 400, 000 memory accesses l 220 > 200 + 7, 999, 800 x p 20 > 7, 999, 800 x p l p <. 0000025 l < one page fault in every 400, 000 memory accesses 20
Demand Paging Optimizations n Disk I/O to swap space is faster than that to the file system l Because swap space is allocated in much larger blocks, and file lookups and indirect allocation methods are not used (복잡한 파일 시스템 입출력보다 disk swap 은 블록단위의 전송이며 단순하기 때문) n Can get better paging throughput by copying entire process(file) image into the swap space at process startup(load) time and then performing demand paging from the swap space l Used in older BSD Unix n Mobile systems l Typically don’t support swapping l 대신, 이러한 시스템에서는 파일 시스템에서 page를 요구함. 또한, 만약 memory 제 약 상황이 발생시, code와 같은 read-only page 부분이 memory로부터 방출됨 4 Update된 page는 수정된 데이터를 가지므로 page 방출시 동기화 등 여러 절차가 필요하므로 read-only page 부분을 memory로부터 없애는 것이 편함 21
Copy-on-Write 프로세스 1이 page C를 수정 한 후 (page C가 복사됨) 프로세스 1이 page C를 수정하기 전 n Fork() 수행시, parent process공간을 child process 와 공유. Child process는 fork때 해당 page 를 복사해서 갖는 것이 아니라, child process가 해당 page에 새로운 값을 write할때, page를 복사하게 됨 n Copy-on-Write (COW) allows both parent and child processes to initially share the same pages in memory l If either process modifies a shared page, only then is the page copied n COW allows more efficient process creation as only modified pages are copied n In general, free pages are allocated from a pool of zero-fill-on-demand pages l Pool should always have free frames for fast demand page execution n vfork() variation on fork() system call has parent suspended and child using copy-on- write address space of parent l Designed to have child call exec() l Very efficient 22
Page Replacement n Prevent over-allocation of memory by modifying page-fault service routine to include page replacement n Use modify (dirty) bit to reduce overhead of page transfers – only modified (updated) pages are written to disk l 즉, 특정 memory frame을 차지하는 page가 새로운 값으로 update되 지 않았다면 굳이 disk에 저장할 필요없음 (disk로의 page out/write 필요없음) 23
What Happens if There is no Free Frame? n Every memory used up (occupied) by process pages l Also in demand from the kernel, I/O buffers, etc l 즉, 메모리는 program 페이지를 저장하는 용도뿐만 아니라, I/O 버퍼 용도로 도 사용하므로 어느정도의 메모리를 program용으로 할당할지, 얼마를 I/O용 으로 할당할지 결정 필요 n How much to allocate to each? l 과할당은 process 실행 중, page fault 발생시 과도한 overhead 유발 4 update된 기존 page out, 새로운 page를 paging in 두번의 Disk access 필요 n Page replacement – find some page in memory, but not really in use, page it out l Algorithm – terminate? swap out? replace the page? l Performance – want an algorithm which will result in minimum number of page faults n Same page may be brought into memory several times 24
Basic Page Replacement • 즉, empty memory frame이 없으면 현재 사용되고 있지 않는 frame을 찾아서 이를 비워야 함. 그 프레임(victim frame)의 내용을 disk swap 공간에 쓰고 그 페이지가 메모리에 존재하지 않는다고 page table을 update함(v invalid) 1. Find the location of the desired page on disk 2. Find a free frame: - If there is a free frame, use it - If there is no free frame, use a page replacement algorithm to select a victim frame - Write victim frame to disk if dirty 3. Bring the desired page into the (newly) free frame; update the page and frame tables 4. Continue the process by restarting the instruction that caused the trap Note now potentially 2 page transfers for page fault – increasing EAT 26
Page Replacement 2 page transfers for page fault 27
Page and Frame Replacement Algorithms n Frame-allocation algorithm determines l How many frames to give each process l Which frames to replace n Page-replacement algorithm l Want lowest page-fault rate on both first access and re-access n Evaluate algorithm by running it on a particular string of memory references (reference string) and computing the number of page faults on that string l String is just page numbers, not full addresses l Repeated access to the same page does not cause a page fault l Results depend on number of frames available n In all our examples, the reference string of referenced page numbers is 7, 0, 1, 2, 0, 3, 0, 4, 2, 3, 0, 3, 2, 1, 2, 0, 1, 7, 0, 1 예) 어떤 프로세스가 다음과 같은 주소를 참조하며, 각 page는 100 byte 용량을 가진다 면, reference string은 아래와 같음 - 가용 physical memory frame이 3개 이상이라면 위 상황에서의 demand paging은 3번의 page fault 발생 만약 1개의 physical memory frame만 있다면, 11번의 page fault 발생 28
Graph of Page Faults Versus The Number of Frames 가용 physical memory frame의 수가 많으면 page fault 횟수는 감소 29
First-In-First-Out (FIFO) Algorithm n 3개의 frame을 가지는 physical memory가 있다고 가정하고 page 참조는 다음과 같은 sequence로 이뤄진다고 가정 (FIFO 페이지 교체 알고리즘 적용시) n Reference string: 7, 0, 1, 2, 0, 3, 0, 4, 2, 3, 0, 3, 2, 1, 2, 0, 1, 7, 0, 1 n 3 frames (3 pages can be in memory at a time per process) 15 page faults n Can vary by reference string: consider 1, 2, 3, 4, 1, 2, 5, 1, 2, 3, 4, 5 1 1 1 4 4 4 5 2 2 2 1 1 1 3 3 3 2 2 30
FIFO Illustrating Belady’s Anomaly • Though adding more frames, more page faults occur! Belady’s Anomaly Belady의 모순 현상 발생 가능) 31
Optimal Algorithm n Replace page that will not be used for longest period of time n “미래(? )에 가장 오랫동안 사용되지 않을 페이지를 찾아서 교체함” l 9 is optimal for the example n How do you know this? l Can’t read the future n Used for measuring how well your algorithm performs 7이 교체된 이유는 미래에 7이 한번밖에 사용 되지 않을 것이므로. . 32
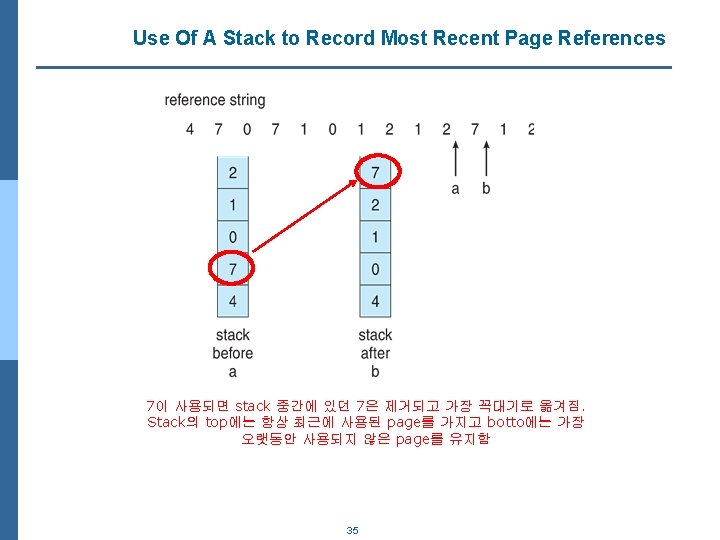
Least Recently Used (LRU) Algorithm n Use past knowledge rather than future n Replace page that has not been used in the most amount of time n Associate time of last use with each page 7이 교체된 이유는 최근에 사용된 page는 1과 0이었으므로 3에 대한 page fault 발생 최근에 사용 된 page는 0과 2이므로, 가장 오래전 사용 된 1을 replace함 n 12 faults – better than FIFO but worse than OPT n Generally good algorithm and frequently used n But how to implement? – 각 page frame을 최근 사용된 순서로 파악할 수 있어야 함 33
LRU Algorithm (Cont. ) n Counter implementation l Associate each page-table entry with a time-of-use field 4 Every page entry has a counter; every time page is referenced through this entry, copy the clock into the counter l When a page needs to be changed, look at the counters to find smallest value 4 Search through table needed n Stack implementation l Keep a stack of page numbers in a double link form: l Page referenced: 4 move it to the top 4 requires 6 pointers to be changed l But each update more expensive l No search for replacement n LRU and OPT are cases of stack algorithms that don’t have Belady’s Anomaly 34
LRU Approximation Algorithms n LRU needs special hardware and still slow l LRU 페이지 교체 기법을 충분히 지원하는 하드웨어는 많지 않음 LRU와 유사하지 만, 하드웨어 지원 필요성이 없는 알고리즘 필요 n Reference bit (참조비트) l With each page associate a bit, initially = 0 l When page is referenced bit set to 1 l Replace any with reference bit = 0 (if one exists) 4 We do not know the order, however n Second-chance algorithm (2차 기회 알고리즘) l Generally FIFO, plus hardware-provided reference bit l Clock replacement l If page to be replaced has 4 Reference 4 reference bit = 0 -> replace it bit = 1 then: – set reference bit 0, leave page in memory – replace next page, subject to same rules 36
Second-Chance (clock) Page-Replacement Algorithm • reference (참조) bit이 0 page 교체. 1이면 한번 더 기회를 줌. 1을 0으로바꾼 후, 다음 FIFO 페이지로 넘어감 37
Counting Algorithms n Keep a counter of the number of references that have been made to each page l Not common n Lease Frequently Used (LFU) Algorithm: replaces page with smallest count n Most Frequently Used (MFU) Algorithm: based on the argument that the page with the smallest count was probably just brought in and has yet to be used 가장 작은 참조 횟수를 가진 페이지가 가 장 최근 참조이며, 앞으로 많이 사용될 것이라는 판단에 근거 38
Page-Buffering Algorithms n Keep a pool of free frames, always (가용 프레임 유지 기법) l Then frame available when needed, not found at fault time l Read page into free frame and select victim to evict and add to free pool l When convenient, evictim 4 즉, page fault 발생시, physical memory에서 victim frame을 찾고 이를 swapping 한 후, 해당 page를 memory로 loading하는 것이 아니라, 해당 page를 우선 “가용 free frame”에 loading을 먼저함. 39
Allocation of Frames n Each process needs minimum number of physical memory frames l 기본적으로 프로세스에는 최소한 어느정도 이상의 메모리 프레 임을 할당해야 함. 너무 적게 할당하면, 프로세스 실행시 page fault가 자주 발생하여 성능이 급격히 저하됨 n Maximum of course is total frames in the system n Two major allocation schemes l fixed allocation l priority allocation n Many variations 41
Fixed Allocation n Equal allocation – For example, if there are 100 frames (after allocating frames for the OS) and 5 processes, give each process 20 frames l Keep some as free frame buffer pool n Proportional allocation – Allocate according to the size of process l Dynamic as degree of multiprogramming, process sizes change 42
Priority Allocation n Use a proportional allocation scheme using priorities rather than size n If process Pi generates a page fault, l select for replacement one of its frames l select for replacement a frame from a process with lower priority number 43
Global vs. Local Allocation n Global replacement – process selects a replacement frame from the set of all frames; one process can take a frame from another (교체할 프레임을 찾을때, 다른 프로세스에 속하는 프레임도 교체 대상이 됨) l But then process execution time can vary greatly l But greater throughput so more common n Local replacement – each process selects from only its own set of allocated frames (각 프로세스는 자기에게 할당된 프레임들 중에서 교체 대상 찾음) l More consistent per-process performance l But possibly underutilized memory 44
Non-Uniform Memory Access(비균등 메모리 접근) n So far all memory accessed equally n Many systems are NUMA – speed of access to memory varies l Consider system boards containing CPUs and memory, interconnected over a system bus UMA NUMA 45
Non-Uniform Memory Access(비균등 메모리 접근) n Optimal performance comes from allocating memory “close to” the CPU on which the thread is scheduled l And modifying the scheduler to schedule thread on the same system board when possible l Solved by Solaris by creating lgroups ( locality groups ) 4 Structure to track CPU / Memory low latency groups 4 Used my schedule and pager 4 When possible schedule all threads of a process and allocate all memory for that process within the lgroup https: //blogs. oracle. com/solaris/locality-group-observability-on-solaris-v 2 46
Thrashing n If a process does not have “enough” pages, the page-fault rate is very high l Page fault to get page l Replace existing frame l But quickly need replaced frame back l This leads to: 4 Low CPU utilization 4 Operating system thinking that it needs to increase the degree of multiprogramming 4 Another process added to the system n Thrashing a process is busy swapping pages in and out • • 어떤 프로세스에 할당된 memory frame이 어느정도 이하가 되면 page fault 발생이 급격히 많아짐 Swap out된 page를 또 다시 필요로 하며(swap in), 다시 page fault가 발생하여 swap out과 swap in이 반복적으로 발생하는 Thrashing 현상 발생 • 낮은 CPU 이용률로 OS가 더 많은 process를 loading하게되면, 각 process가 가지는 memory frame은 작아지고 이때문에 page fault가 많이 발생하며, 결국 trashing 상황까지 발생 가능 47
Thrashing (Cont. ) • 낮은 CPU 이용률 OS는 더 많은 process를 loading하여 CPU 이용률 높이고자 함 각 process의 memory frame은 적어, 많은 page fault가 발생 swap in/out에 의해 CPU 이용률은 높아지지 않음 OS는 더욱 더 많은 process load … page fault만 많아짐 (Thrashing 현상 발생) 48
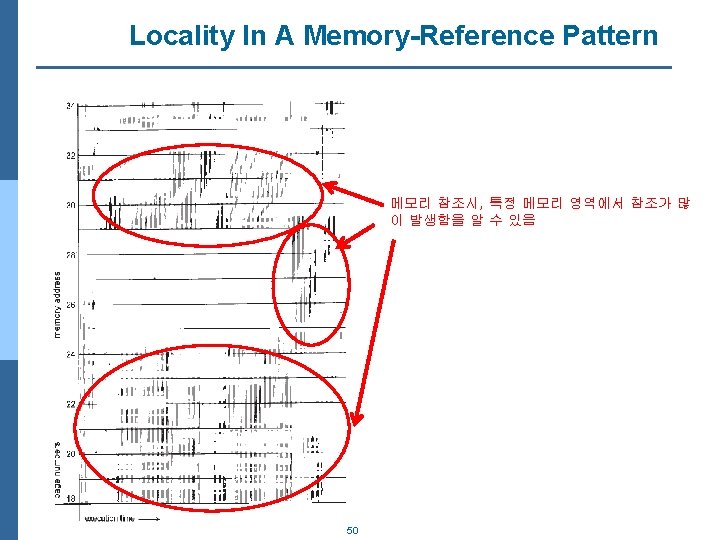
Demand Paging and Thrashing n Why does demand paging work? Locality model n Locality model(지역성 모델) l Process migrates from one locality to another l Localities may overlap l 즉, process는 실행시 항상 어떤 특정 지역에서만 메모리를 집 중적으로 참조하는 특성 가짐 l 이와 같은 Locality 특성을 사용하여, process에게 local replacement만 수행하여 Thrashing 현상 방지할 수 있음 n Why does thrashing occur? size of locality > total memory size l Limit effects by using local or priority page replacement 49
Memory-Mapped Files n Memory-mapped file I/O allows file I/O to be treated as routine memory access by mapping a disk block to a page in memory < read/write/lseek system call을 사용 한 File I/O > < Memory mapped I/O> https: //learning. oreilly. com/library/view/solaristm-internalscore/0130224960_ch 11 lev 1 sec 5. html# 51
Memory-Mapped Files n A file is initially read using demand paging l A page-sized portion of the file is read from the file system into a physical page l Subsequent reads/writes to/from the file are treated as ordinary memory accesses n Simplifies and speeds file access by driving file I/O through memory rather than read() and write() system calls n Also allows several processes to map the same file allowing the pages in memory to be shared n But when does written data make it to disk? l Periodically and / or at file close() time l For example, when the pager scans for dirty pages 52
Memory-Mapped File Technique for all I/O n Some OSes uses memory mapped files for standard I/O n Process can explicitly request memory mapping a file via mmap() system call l Now file mapped into process address space n For standard I/O (open(), read(), write(), close()), mmap anyway l But map file into kernel address space l Process still does read() and write() 4 Copies l data to and from kernel space and user space Uses efficient memory management subsystem 4 Avoids needing separate subsystem n COW can be used for read/write non-shared pages n Memory mapped files can be used for shared memory (although again via separate system calls) 53
Memory Mapped Files 54
Shared Memory via Memory-Mapped I/O 55
Shared Memory in Windows API n First create a file mapping for file to be mapped l Then establish a view of the mapped file in process’s virtual address space n Consider producer / consumer l Producer create shared-memory object using memory mapping features l Open file via Create. File(), returning a HANDLE l Create mapping via Create. File. Mapping() creating a named shared-memory object l Create view via Map. View. Of. File() n Sample code in Textbook 56
Allocating Kernel Memory n Treated differently from user memory n Often allocated from a free-memory pool l Kernel requests memory for structures of varying sizes l Some kernel memory needs to be contiguous 4 I. e. for device I/O 57