Chapter 4 Mining Frequent Patterns Association and Correlations






















 Ck: Candidate itemset of size k Lk : frequent itemset")














 2021/10/17 Data Mining: Concepts and Techniques")


![挖掘多层关联规则 n 项通常具有层次 n 牛奶⇒ 面包[20%, 60%]. n 酸奶⇒ 黄面包[6%, 50%] 2021/10/17 Data Mining:](https://slidetodoc.com/presentation_image_h2/cbad08142af71389a25bcc3fe129b094/image-41.jpg "挖掘多层关联规则 n 项通常具有层次 n 牛奶⇒ 面包[20%, 60%]. n 酸奶⇒ 黄面包[6%, 50%] 2021/10/17 Data Mining:")











 buys(X, “bread”) n Multi-dimensional rules: 2")



")


 Basketball Not basketball Sum (row) Cereal")

![Interestingness Measure: Correlations (Lift) n play basketball eat cereal [40%, 66. 7%] is misleading](https://slidetodoc.com/presentation_image_h2/cbad08142af71389a25bcc3fe129b094/image-65.jpg "Interestingness Measure: Correlations (Lift) n play basketball eat cereal [40%, 66. 7%] is misleading")


 Mining n Finding all the patterns in a database autonomously? — unrealistic!")










- Slides: 78
Chapter 4: Mining Frequent Patterns, Association and Correlations n Basic concepts and a road map n Scalable frequent itemset mining methods n Mining various kinds of association rules n Constraint-based association mining n From association to correlation analysis n Mining colossal patterns n Summary 2021/10/17 Data Mining: Concepts and Techniques 1
What Is Frequent Pattern Analysis? Frequent pattern: a pattern (a set of items, subsequences, substructures, n etc. ) that occurs frequently in a data set n First proposed by Agrawal, Imielinski, and Swami [AIS 93] in the context of frequent itemsets and association rule mining Motivation: Finding inherent regularities in data n n n What products were often purchased together? — Beer and diapers? ! n What are the subsequent purchases after buying a PC? n What kinds of DNA are sensitive to this new drug? n Can we automatically classify web documents? Applications n Basket data analysis, cross-marketing, catalog design, sale campaign analysis, Web log (click stream) analysis, and DNA sequence analysis. 2021/10/17 Data Mining: Concepts and Techniques 2
Why Is Freq. Pattern Mining Important? n n Freq. pattern: An intrinsic and important property of datasets Foundation for many essential data mining tasks n Association, correlation, and causality analysis n Sequential, structural (e. g. , sub-graph) patterns n Pattern analysis in spatiotemporal, multimedia, timeseries, and stream data n Classification: discriminative, frequent pattern analysis n Cluster analysis: frequent pattern-based clustering n Data warehousing: iceberg cube and cube-gradient n Semantic data compression: fascicles n Broad applications 2021/10/17 Data Mining: Concepts and Techniques 5
confidence and support n n Itemset X={i 1, …, ik} Find all the rules X ⇒Y with min confidence and support Customer buys both Customer buys diaper support, s, probability that a transaction contains X Y support(X⇒Y)=同时包含项目集X和Y的交 易数/总交易数 用于描述有用性. confidence, c, conditional probability that a transaction having X also contains Y. confidence(X⇒Y)=同时购买商品X和Y的交 易数/购买商品X的交易数 用于描述确定性, 即”值得信赖的程度 ””可靠性” Customer buys beer 2021/10/17 Data Mining: Concepts and Techniques 8
Mining Association Rules—an Example Transaction-id Items bought 10 A, B, C 20 A, C 30 A, D 40 B, E, F Min. support 50% Min. confidence 50% Frequent pattern Support {A} 75% {B} 50% {C} 50% {A, C} 50% For rule A C: support = support({A} {C}) = 50% confidence = support({A} {C})/support({A}) = 66. 6% 2021/10/17 Data Mining: Concepts and Techniques 9
Basic Concepts: Frequent Patterns Tid Items bought 10 Beer, Nuts, Diaper 20 Beer, Coffee, Diaper 30 Beer, Diaper, Eggs 40 Nuts, Eggs, Milk 50 Nuts, Coffee, Diaper, Eggs, Milk Customer buys both n n n Customer buys diaper n n Customer buys beer 2021/10/17 itemset: A set of one or more items k-itemset X = {x 1, …, xk} (absolute) support, or, support count of X: Frequency or occurrence of an itemset X (relative) support, s, is the fraction of transactions that contains X (i. e. , the probability that a transaction contains X) An itemset X is frequent if X’s support is no less than a minsup threshold Data Mining: Concepts and Techniques 11
Basic Concepts: Association Rules Tid Items bought 10 Beer, Nuts, Diaper 20 Beer, Coffee, Diaper 30 Beer, Diaper, Eggs 40 50 Nuts, Eggs, Milk n Nuts, Coffee, Diaper, Eggs, Milk Customer buys both Customer buys beer 2021/10/17 Customer buys diaper Find all the rules X Y with minimum support and confidence n support, s, probability that a transaction contains X Y n confidence, c, conditional probability that a transaction having X also contains Y Let minsup = 50%, minconf = 50% Freq. Pat. : Beer: 3, Nuts: 3, Diaper: 4, Eggs: 3, {Beer, Diaper}: 3 n Association rules: (many more!) n Beer Diaper (60%, 100%) n Diaper Beer (60%, 75%) Data Mining: Concepts and Techniques 12
Closed Patterns and Max-Patterns n n n A long pattern contains a combinatorial number of subpatterns, e. g. , {a 1, …, a 100} contains (1001) + (1002) + … + (110000) = 2100 – 1 = 1. 27*1030 sub-patterns! Solution: Mine closed patterns and max-patterns instead An itemset X is closed if X is frequent and there exists no super-pattern Y כ X, with the same support as X (proposed by Pasquier, et al. @ ICDT’ 99) An itemset X is a max-pattern if X is frequent and there exists no frequent super-pattern Y כ X (proposed by Bayardo @ SIGMOD’ 98) Closed pattern is a lossless compression of freq. patterns n 2021/10/17 Reducing the # of patterns and rules Data Mining: Concepts and Techniques 13
Closed Patterns and Max-Patterns n Exercise. DB = {<a 1, …, a 100>, < a 1, …, a 50>} n n n What is the set of closed itemset? n <a 1, …, a 100>: 1 n < a 1, …, a 50>: 2 What is the set of max-pattern? n n Min_sup = 1. <a 1, …, a 100>: 1 What is the set of all patterns? n 2021/10/17 !! Data Mining: Concepts and Techniques 14
Computational Complexity of Frequent Itemset Mining n How many itemsets are potentially to be generated in the worst case? n n The number of frequent itemsets to be generated is senstive to the minsup threshold When minsup is low, there exist potentially an exponential number of frequent itemsets The worst case: MN where M: # distinct items, and N: max length of transactions The worst case complexty vs. the expected probability n Ex. Suppose Walmart has 104 kinds of products n The chance to pick up one product 10 -4 n The chance to pick up a particular set of 10 products: ~10 -40 n 2021/10/17 What is the chance this particular set of 10 products to be frequent 103 times in 109 transactions? Data Mining: Concepts and Techniques 15
Chapter 4: Mining Frequent Patterns, Association and Correlations n Basic concepts and a road map n Scalable frequent itemset mining methods n Mining various kinds of association rules n Constraint-based association mining n From association to correlation analysis n Mining colossal patterns n Summary 2021/10/17 Data Mining: Concepts and Techniques 16
The Apriori Algorithm—An Example Database TDB Tid Items 10 A, C, D 20 B, C, E 30 A, B, C, E 40 B, E Itemset {A, C} {B, E} {C, E} sup {A} 2 {B} 3 {C} 3 {D} 1 {E} 3 C 1 1 st scan C 2 L 2 Itemset sup 2 2 3 2 Itemset {A, B} {A, C} {A, E} {B, C} {B, E} {C, E} sup 1 2 3 2 L 1 Itemset sup {A} 2 {B} 3 {C} 3 {E} 3 C 2 2 nd scan Itemset {A, B} {A, C} {A, E} {B, C} {B, E} {C, E} C 3 2021/10/17 Itemset {B, C, E} 3 rd scan Itemset L 3 C, E} {B, sup 2 Data Mining: Concepts and Techniques 19
Apriori: A Candidate Generation & Test Approach n n Apriori pruning principle: If there is any itemset which is infrequent, its superset should not be generated/tested! (Agrawal & Srikant @VLDB’ 94, Mannila, et al. @ KDD’ 94) Method: n n 2021/10/17 Initially, scan DB once to get frequent 1 -itemset Generate length (k+1) candidate itemsets from length k frequent itemsets Test the candidates against DB Terminate when no frequent or candidate set can be generated Data Mining: Concepts and Techniques 21
The Apriori Algorithm—An Example Database TDB Tid Items 10 A, C, D 20 B, C, E 30 A, B, C, E 40 B, E Supmin = 2 Itemset {A, C} {B, E} {C, E} sup {A} 2 {B} 3 {C} 3 {D} 1 {E} 3 C 1 1 st scan C 2 L 2 Itemset sup 2 2 3 2 Itemset {A, B} {A, C} {A, E} {B, C} {B, E} {C, E} sup 1 2 3 2 L 1 Itemset sup {A} 2 {B} 3 {C} 3 {E} 3 C 2 2 nd scan Itemset {A, B} {A, C} {A, E} {B, C} {B, E} {C, E} C 3 2021/10/17 Itemset {B, C, E} 3 rd scan L 3 Itemset sup {B, C, E} 2 Data Mining: Concepts and Techniques 22
The Apriori Algorithm (Pseudo-Code) Ck: Candidate itemset of size k Lk : frequent itemset of size k L 1 = {frequent items}; for (k = 1; Lk != ; k++) do begin Ck+1 = candidates generated from Lk; for each transaction t in database do increment the count of all candidates in Ck+1 that are contained in t Lk+1 = candidates in Ck+1 with min_support end return k Lk; 2021/10/17 Data Mining: Concepts and Techniques 23
Implementation of Apriori n n How to generate candidates? n Step 1: self-joining Lk n Step 2: pruning Example of Candidate-generation n n L 3={abc, abd, ace, bcd} Self-joining: L 3*L 3 n n n Pruning: n n 2021/10/17 abcd from abc and abd acde from acd and ace acde is removed because ade is not in L 3 C 4 = {abcd} Data Mining: Concepts and Techniques 24
Candidate Generation: An SQL Implementation of candidate generation n Suppose the items in Lk-1 are listed in an order n Step 1: self-joining Lk-1 insert into Ck select p. item 1, p. item 2, …, p. itemk-1, q. itemk-1 from Lk-1 p, Lk-1 q where p. item 1=q. item 1, …, p. itemk-2=q. itemk-2, p. itemk-1 < q. itemk -1 Step 2: pruning forall itemsets c in Ck do forall (k-1)-subsets s of c do if (s is not in Lk-1) then delete c from Ck Use object-relational extensions like UDFs, BLOBs, and Table functions for efficient implementation [S. Sarawagi, S. Thomas, and R. Agrawal. Integrating association rule mining with relational database systems: Alternatives and implications. SIGMOD’ 98] n n 2021/10/17 Data Mining: Concepts and Techniques 25
提高Apriori方法的有效性 n n Challenges n Multiple scans of transaction database n Huge number of candidates n Tedious workload of support counting for candidates Improving Apriori: general ideas n Reduce passes of transaction database scans n Shrink number of candidates n Facilitate support counting of candidates n 改进方法,包括:散列、划分、抽样。。。。 2021/10/17 Data Mining: Concepts and Techniques 26
Further Improvement of the Apriori Method n n Major computational challenges n Multiple scans of transaction database n Huge number of candidates n Tedious workload of support counting for candidates Improving Apriori: general ideas n Reduce passes of transaction database scans n Shrink number of candidates n Facilitate support counting of candidates 2021/10/17 Data Mining: Concepts and Techniques 27
Partition: Scan Database Only Twice n Any itemset that is potentially frequent in DB must be frequent in at least one of the partitions of DB n Scan 1: partition database and find local frequent patterns n n Scan 2: consolidate global frequent patterns A. Savasere, E. Omiecinski, and S. Navathe. An efficient algorithm for mining association in large databases. In VLDB’ 95 2021/10/17 Data Mining: Concepts and Techniques 28
DHP: Reduce the Number of Candidates n A k-itemset whose corresponding hashing bucket count is below the threshold cannot be frequent n Candidates: a, b, c, d, e n Hash entries: {ab, ad, ae} {bd, be, de} … n Frequent 1 -itemset: a, b, d, e n ab is not a candidate 2 -itemset if the sum of count of {ab, ad, ae} is below support threshold n J. Park, M. Chen, and P. Yu. An effective hash-based algorithm for mining association rules. In SIGMOD’ 95 2021/10/17 Data Mining: Concepts and Techniques 29
Sampling for Frequent Patterns n Select a sample of original database, mine frequent patterns within sample using Apriori n Scan database once to verify frequent itemsets found in sample, only borders of closure of frequent patterns are checked n Example: check abcd instead of ab, ac, …, etc. n Scan database again to find missed frequent patterns n H. Toivonen. Sampling large databases for association rules. In VLDB’ 96 2021/10/17 Data Mining: Concepts and Techniques 30
DIC: Reduce Number of Scans ABCD n ABC ABD ACD BCD AB AC BC AD BD n CD Once both A and D are determined frequent, the counting of AD begins Once all length-2 subsets of BCD are determined frequent, the counting of BCD begins Transactions B A C D Apriori {} Itemset lattice S. Brin R. Motwani, J. Ullman, and S. Tsur. Dynamic itemset DIC counting and implication rules for market basket data. In SIGMOD’ 97 2021/10/17 1 -itemsets 2 -itemsets … 1 -itemsets 2 -items Data Mining: Concepts and Techniques 3 -items 31
Pattern-Growth Approach: Mining Frequent Patterns Without Candidate Generation n Bottlenecks of the Apriori approach n Breadth-first (i. e. , level-wise) search n Candidate generation and test n n n Often generates a huge number of candidates The FPGrowth Approach (J. Han, J. Pei, and Y. Yin, SIGMOD’ 00) n Depth-first search n Avoid explicit candidate generation Major philosophy: Grow long patterns from short ones using local frequent items only n “abc” is a frequent pattern n Get all transactions having “abc”, i. e. , project DB on abc: DB|abc n “d” is a local frequent item in DB|abc abcd is a frequent pattern 2021/10/17 Data Mining: Concepts and Techniques 32
Construct FP-tree from a Transaction Database TID 100 200 300 400 500 Items bought (ordered) frequent items {f, a, c, d, g, i, m, p} {f, c, a, m, p} {a, b, c, f, l, m, o} {f, c, a, b, m} min_support = 3 {b, f, h, j, o, w} {f, b} {b, c, k, s, p} {c, b, p} {a, f, c, e, l, p, m, n} {f, c, a, m, p} {} Header Table 1. Scan DB once, find f: 4 c: 1 Item frequency head frequent 1 -itemset (single f 4 item pattern) c: 3 b: 1 c 4 2. Sort frequent items in a 3 b 3 frequency descending a: 3 p: 1 m 3 order, f-list p 3 m: 2 b: 1 3. Scan DB again, construct FP-tree p: 2 m: 1 F-list = f-c-a-b-m-p 2021/10/17 Data Mining: Concepts and Techniques 33
Benefits of the FP-tree Structure n Completeness n n n Preserve complete information for frequent pattern mining Never break a long pattern of any transaction Compactness n n n Reduce irrelevant info—infrequent items are gone Items in frequency descending order: the more frequently occurring, the more likely to be shared Never be larger than the original database (not count node-links and the count field) 2021/10/17 Data Mining: Concepts and Techniques 34
The Frequent Pattern Growth Mining Method n n Idea: Frequent pattern growth n Recursively grow frequent patterns by pattern and database partition Method n For each frequent item, construct its conditional pattern -base, and then its conditional FP-tree n Repeat the process on each newly created conditional FP-tree n Until the resulting FP-tree is empty, or it contains only one path—single path will generate all the combinations of its sub-paths, each of which is a frequent pattern 2021/10/17 Data Mining: Concepts and Techniques 35
Visualization of Association Rules: Plane Graph 2021/10/17 Data Mining: Concepts and Techniques 36
Visualization of Association Rules: Rule Graph 2021/10/17 Data Mining: Concepts and Techniques 37
Visualization of Association Rules (SGI/Mine. Set 3. 0) 2021/10/17 Data Mining: Concepts and Techniques 38
Chapter 4: Mining Frequent Patterns, Association and Correlations n Basic concepts and a road map n Efficient and scalable frequent itemset mining methods n Mining various kinds of association rules n From association mining to correlation analysis n Constraint-based association mining n Mining colossal patterns n Summary 2021/10/17 Data Mining: Concepts and Techniques 39
Mining Various Kinds of Association Rules n Mining multilevel association n Miming multidimensional association n Mining quantitative association n Mining interesting correlation patterns 2021/10/17 Data Mining: Concepts and Techniques 40
挖掘多层关联规则 n 项通常具有层次 n 牛奶⇒ 面包[20%, 60%]. n 酸奶⇒ 黄面包[6%, 50%] 2021/10/17 Data Mining: Concepts and Techniques 41
支持度不变 2021/10/17 Data Mining: Concepts and Techniques 44
支持度递减 2021/10/17 Data Mining: Concepts and Techniques 45
Mining Multiple-Level Association Rules n n n Items often form hierarchies Flexible support settings n Items at the lower level are expected to have lower support Exploration of shared multi-level mining (Agrawal & Srikant@VLB’ 95, Han & Fu@VLDB’ 95) reduced support uniform support Level 1 min_sup = 5% Level 2 min_sup = 5% 2021/10/17 Milk [support = 10%] 2% Milk [support = 6%] Skim Milk [support = 4%] Data Mining: Concepts and Techniques Level 1 min_sup = 5% Level 2 min_sup = 3% 47
Multi-level Association: Redundancy Filtering n n Some rules may be redundant due to “ancestor” relationships between items Example n milk wheat bread [support = 8%, confidence = 70%] n 2% milk wheat bread [support = 2%, confidence = 72%] We say the first rule is an ancestor of the second rule A rule is redundant if its support is close to the “expected” value, based on the rule’s ancestor 2021/10/17 Data Mining: Concepts and Techniques 48
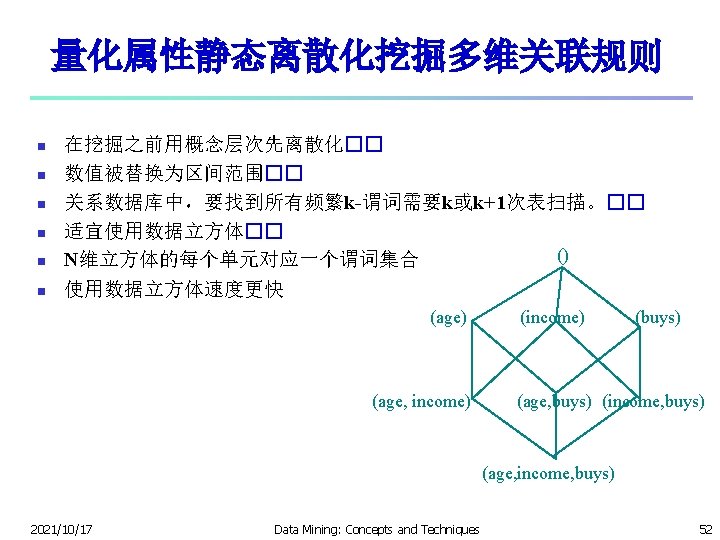
Mining Multi-Dimensional Association n Single-dimensional rules: buys(X, “milk”) buys(X, “bread”) n Multi-dimensional rules: 2 dimensions or predicates n Inter-dimension assoc. rules (no repeated predicates) age(X, ” 19 -25”) occupation(X, “student”) buys(X, “coke”) n hybrid-dimension assoc. rules (repeated predicates) age(X, ” 19 -25”) buys(X, “popcorn”) buys(X, “coke”) n n Categorical Attributes: finite number of possible values, no ordering among values—data cube approach Quantitative Attributes: Numeric, implicit ordering among values—discretization, clustering, and gradient approaches 2021/10/17 Data Mining: Concepts and Techniques 56
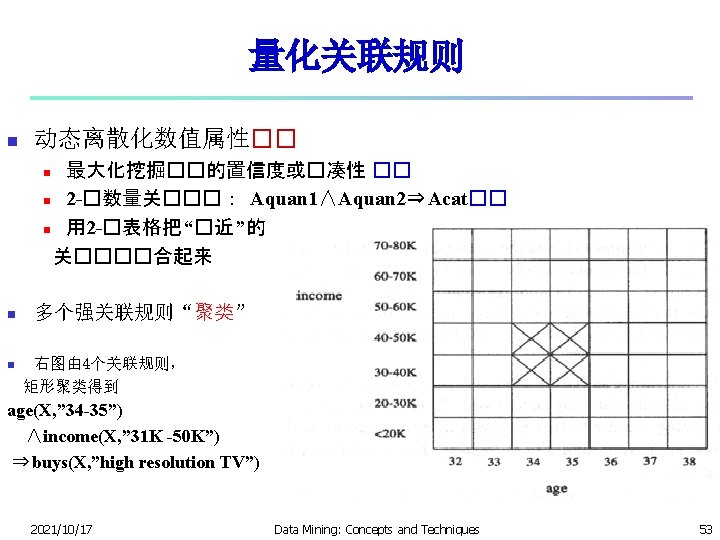
Mining Quantitative Associations n Techniques can be categorized by how numerical attributes, such as age or salary are treated 1. Static discretization based on predefined concept hierarchies (data cube methods) 2. Dynamic discretization based on data distribution (quantitative rules, e. g. , Agrawal & Srikant@SIGMOD 96) 3. Clustering: Distance-based association (e. g. , Yang & Miller@SIGMOD 97) n One dimensional clustering then association 4. Deviation: (such as Aumann and Lindell@KDD 99) Sex = female => Wage: mean=$7/hr (overall mean = $9) 2021/10/17 Data Mining: Concepts and Techniques 57
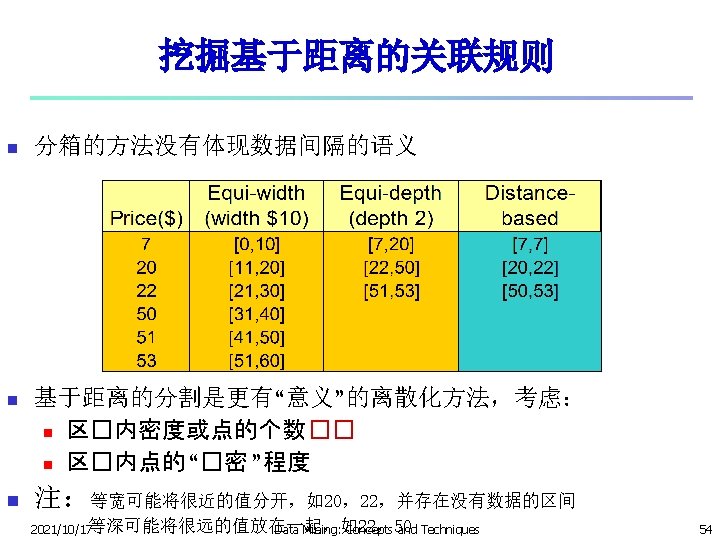
Static Discretization of Quantitative Attributes n Discretized prior to mining using concept hierarchy. n Numeric values are replaced by ranges n In relational database, finding all frequent k-predicate sets will require k or k+1 table scans n Data cube is well suited for mining n The cells of an n-dimensional () (age) (income) (buys) cuboid correspond to the predicate sets n Mining from data cubes can be much faster 2021/10/17 (age, income) (age, buys) (income, buys) (age, income, buys) Data Mining: Concepts and Techniques 58
Quantitative Association Rules n n Proposed by Lent, Swami and Widom ICDE’ 97 Numeric attributes are dynamically discretized n Such that the confidence or compactness of the rules mined is maximized 2 -D quantitative association rules: Aquan 1 Aquan 2 Acat n Cluster adjacent association rules to form general rules using a 2 -D grid n Example age(X, “ 34 -35”) income(X, “ 30 -50 K”) buys(X, “high resolution TV”) n 2021/10/17 Data Mining: Concepts and Techniques 59
Mining Other Interesting Patterns n Flexible support constraints (Wang, et al. @ VLDB’ 02) n n n Some items (e. g. , diamond) may occur rarely but are valuable Customized supmin specification and application Top-K closed frequent patterns (Han, et al. @ ICDM’ 02) n n 2021/10/17 Hard to specify supmin, but top-k with lengthmin is more desirable Dynamically raise supmin in FP-tree construction and mining, and select most promising path to mine Data Mining: Concepts and Techniques 60
Chapter 4: Mining Frequent Patterns, Association and Correlations n Basic concepts and a road map n Efficient and scalable frequent itemset mining methods n Mining various kinds of association rules n From association mining to correlation analysis n Constraint-based association mining n Mining colossal patterns n Summary 2021/10/17 Data Mining: Concepts and Techniques 61
支持度-置信度方法的不足 n Example 1: (Aggarwal& Yu, PODS 98) Basketball Not basketball Sum (row) Cereal 2000 1750 3750 Not cereal 1000 250 1250 Sum(col. ) 3000 喜�打�球 3750 喜�吃米� 2000 同�喜�打�球和吃米� 3000 2000 5000 个学生中 n n n n 关联规则:play basketball ⇒eat cereal [40%, 66. 7%] 该规则具有欺骗性,因为从整个学生情况来看,有75%的学生喜欢吃 米饭,大大高于66. 7%。 关联规则:play basketball ⇒not eat cereal [20%, 33. 3%] 该规则虽然拥有较低的支持度和置信度,但是比较精确。 2021/10/17 Data Mining: Concepts and Techniques 63
Interestingness Measure: Correlations (Lift) n play basketball eat cereal [40%, 66. 7%] is misleading n n The overall % of students eating cereal is 75% > 66. 7%. play basketball not eat cereal [20%, 33. 3%] is more accurate, although with lower support and confidence n Basketball Measure of dependent/correlated events: lift 2021/10/17 Not basketball Sum (row) Cereal 2000 1750 3750 Not cereal 1000 250 1250 Sum(col. ) 3000 2000 5000 Data Mining: Concepts and Techniques 65
Chapter 4: Mining Frequent Patterns, Association and Correlations n Basic concepts and a road map n Efficient and scalable frequent itemset mining methods n Mining various kinds of association rules n From association mining to correlation analysis n Constraint-based association mining n Mining colossal patterns n Summary 2021/10/17 Data Mining: Concepts and Techniques 66
Constraint-based (Query-Directed) Mining n Finding all the patterns in a database autonomously? — unrealistic! n n Data mining should be an interactive process n n The patterns could be too many but not focused! User directs what to be mined using a data mining query language (or a graphical user interface) Constraint-based mining n n n 2021/10/17 User flexibility: provides constraints on what to be mined System optimization: explores such constraints for efficient mining — constraint-based mining: constraint-pushing, similar to push selection first in DB query processing Note: still find all the answers satisfying constraints, not finding some answers in “heuristic search” Data Mining: Concepts and Techniques 68
Constraints in Data Mining n n n Knowledge type constraint: n classification, association, etc. Data constraint — using SQL-like queries n find product pairs sold together in stores in Chicago in Dec. ’ 02 Dimension/level constraint n in relevance to region, price, brand, customer category Rule (or pattern) constraint n small sales (price < $10) triggers big sales (sum > $200) Interestingness constraint n strong rules: min_support 3%, min_confidence 60% 2021/10/17 Data Mining: Concepts and Techniques 69
Constraint-Based Frequent Pattern Mining n Classification of constraints based on their constraintpushing capabilities n Anti-monotonic: If constraint c is violated, its further mining can be terminated n Monotonic: If c is satisfied, no need to check c again n Data anti-monotonic: If a transaction t does not satisfy c, t can be pruned from its further mining n Succinct: c must be satisfied, so one can start with the data sets satisfying c n Convertible: c is not monotonic nor anti-monotonic, but it can be converted into it if items in the transaction can be properly ordered 2021/10/17 Data Mining: Concepts and Techniques 70
Chapter 4: Mining Frequent Patterns, Association and Correlations n Basic concepts and a road map n Efficient and scalable frequent itemset mining methods n Mining various kinds of association rules n From association mining to correlation analysis n Constraint-based association mining n Mining colossal patterns n Summary 2021/10/17 Data Mining: Concepts and Techniques 71
Why Mining Colossal Frequent Patterns? n n n F. Zhu, X. Yan, J. Han, P. S. Yu, and H. Cheng, “Mining Colossal Frequent Patterns by Core Pattern Fusion”, ICDE'07. We have many algorithms, but can we mine large (i. e. , colossal) patterns? ― such as just size around 50 to 100? Unfortunately, not! Why not? ― the curse of “downward closure” of frequent patterns n The “downward closure” property n n Any sub-pattern of a frequent pattern is frequent. Example. If (a 1, a 2, …, a 100) is frequent, then a 1, a 2, …, a 100, (a 1, a 2), (a 1, a 3), …, (a 1, a 100), (a 1, a 2, a 3), … are all frequent! There about 2100 such frequent itemsets! No matter using breadth-first search (e. g. , Apriori) or depth-first search (FPgrowth), we have to examine so many patterns Thus the downward closure property leads to explosion! 2021/10/17 Data Mining: Concepts and Techniques 72
Colossal Patterns: A Motivating Example T 1 = 1 2 3 4 …. . 39 40 Let’s make 4040 transactions T 2 = 1 2 3 a 4 set …. . of 39 : . : . T 40=1 2 3 4 …. . 39 40 Then delete the items on the diagonal T 1 = 2 3 4 …. . 39 40 T 2 = 1 3 4 …. . 39 40 : . : . T 40=1 2 3 4 …… 39 2021/10/17 Closed/maximal patterns may partially alleviate the problem but not really solve it: We often need to mine scattered large patterns! Let the minimum support threshold σ= 20 There are size 20 frequent patterns of Each is closed and maximal # patterns = The size of the answer set is exponential to n Data Mining: Concepts and Techniques 73
Colossal Pattern Set: Small but Interesting n It is often the case that only a small number of patterns are colossal, i. e. , of large size Colossal patterns are usually attached with greater importance than those of small. Data Mining: Concepts and Techniques 2021/10/17 n 74
Mining Colossal Patterns: Motivation and Philosophy n n Motivation: Many real-world tasks need mining colossal patterns n Micro-array analysis in bioinformatics (when support is low) n Biological sequence patterns n Biological/sociological/information graph pattern mining No hope for completeness n n Jumping out of the swamp of the mid-sized results n n If the mining of mid-sized patterns is explosive in size, there is no hope to find colossal patterns efficiently by insisting “complete set” mining philosophy What we may develop is a philosophy that may jump out of the swamp of mid-sized results that are explosive in size and jump to reach colossal patterns Striving for mining almost complete colossal patterns n 2021/10/17 The key is to develop a mechanism that may quickly reach colossal patterns and discover most of them Data Mining: Concepts and Techniques 75
Alas, A Show of Colossal Pattern Mining! T 1 = 2 3 4 …. . 39 40 T 2 = 1 3 4 …. . 39 40 : . : . T 40=1 2 3 4 …… 39 T 41= 41 42 43 …. . 79 T 42= 41 42 43 …. . 79 : . T 60= 41 42 43 … 79 Let the min-support threshold σ= 20 Then there are closed/maximal frequent patterns of size 20 However, there is only one with size greater than 20, (i. e. , colossal): α= {41, 42, …, 79} of size 39 The existing fastest mining algorithms (e. g. , FPClose, LCM) fail to complete running Our algorithm outputs this colossal pattern in seconds 2021/10/17 Data Mining: Concepts and Techniques 76
Chapter 4: Mining Frequent Patterns, Association and Correlations n Basic concepts and a road map n Efficient and scalable frequent itemset mining methods n Mining various kinds of association rules n From association mining to correlation analysis n Constraint-based association mining n Mining colossal patterns n Summary 2021/10/17 Data Mining: Concepts and Techniques 77
Frequent-Pattern Mining: Summary n Frequent pattern mining—an important task in data mining n Scalable frequent pattern mining methods § Mining a variety of rules and interesting patterns § Constraint-based mining § Mining sequential and structured patterns § Extensions and applications 2021/10/17 Data Mining: Concepts and Techniques 78