Chapter 4 Divide and Conquer 1 A problems

Chapter 4
 A problem’s instance is divides into several smaller instances")
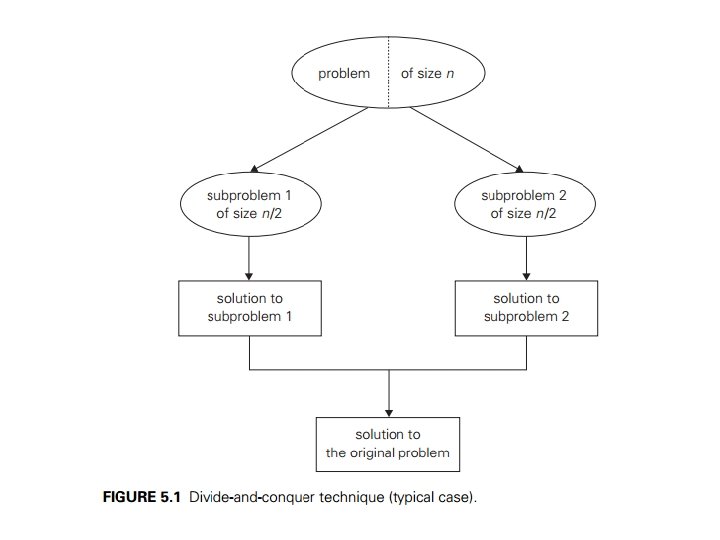
Divide and Conquer 1. ) A problem’s instance is divides into several smaller instances of the same problem, ideally of about the same size. 2. ) The smaller instance are solved(typically recursively , though sometimes a different algorithm is employed when instances become small enough) 3. ) If necessary, the solutions obtained for the smaller instances are combined to get a solution to the original instance.
![Merge sort • Split array A[0. . n-1] into about equal halves and make](http://slidetodoc.com/presentation_image_h/0251c6f1f0533e8ec8a8e7d326306a14/image-4.jpg "Merge sort • Split array A[0. . n-1] into about equal halves and make")
Merge sort • Split array A[0. . n-1] into about equal halves and make copies of each half in arrays B and C • Sort arrays B and C recursively • Merge sorted arrays B and C into array A as follows: – Repeat the following until no elements remain in one of the arrays: • compare the first elements in the remaining unprocessed portions of the arrays • copy the smaller of the two into A, while incrementing the index indicating the unprocessed portion of that array – Once all elements in one of the arrays are processed, copy the remaining unprocessed elements from the other array into A.


")
• All cases have same efficiency: Θ(n log n)
. (Here is first) • Rearrange the list")
Quicksort • Select a pivot (partitioning element). (Here is first) • Rearrange the list so that all the elements in the first s positions are smaller than or equal to the pivot and all the elements in the remaining n-s positions are larger than or equal to the pivot. p A[i] p • Exchange the pivot with the last element in the first (i. e. , ) subarray — the pivot is now in its final position • Sort the two subarrays recursively

Quick Sort


Quicksort Example 5 3 1 9 8 2 4 7 2 3 1 4 5 8 9 7 1 2 3 4 5 7 8 9
")
Analysis of Quicksort • Best case: split in the middle — Θ(n log n) • Worst case: sorted array! — Θ(n 2) • Average case: random arrays — Θ(n log n) • Improvements: – better pivot selection: median of three partitioning – switch to insertion sort on small subfiles – elimination of recursion These combine to 20 -25% improvement

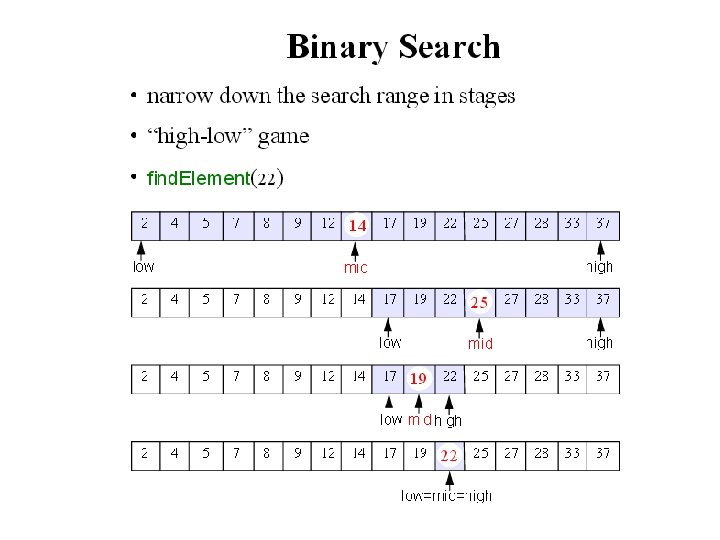
Binary Search • If we place our items in an array and sort them in either ascending or descending order on the key first, then we can obtain much better performance with an algorithm called binary search. • In binary search, we first compare the key with the item in the middle position of the array. If there's a match, we can return immediately. If the key is less than the middle key, then the item sought must lie in the lower half of the array; if it's greater then the item sought must lie in the upper half of the array. So we repeat the procedure on the lower (or upper) half of the array.


 n-digit integers represented")
Multiplication of Large Integers Consider the problem of multiplying two (large) n-digit integers represented by arrays of their digits such as: A = 12345678901357986429 B = 87654321284820912836 The grade-school algorithm: a 1 a 2 … an b 1 b 2 … bn (d 10) d 11 d 12 … d 1 n (d 20) d 21 d 22 … d 2 n ………………… (dn 0) dn 1 dn 2 … dnn Efficiency: Θ(n 2) single-digit multiplications

First Divide-and-Conquer Algorithm A small example: A B where A = 2135 and B = 4014 A = (21· 102 + 35), B = (40 · 102 + 14) So, A B = (21 · 102 + 35) (40 · 102 + 14) = 21 40 · 104 + (21 14 + 35 40) · 102 + 35 14 In general, if A = A 1 A 2 and B = B 1 B 2 (where A and B are n-digit, A 1, A 2, B 1, B 2 are n/2 -digit numbers), A B = A 1 B 1· 10 n + (A 1 B 2 + A 2 B 1) · 10 n/2 + A 2 B 2 Recurrence for the number of one-digit multiplications M(n): M(n) = 4 M(n/2), M(1) = 1 Solution: M(n) = n 2

Second Divide-and-Conquer Algorithm A B = A 1 B 1· 10 n + (A 1 B 2 + A 2 B 1) · 10 n/2 + A 2 B 2 The idea is to decrease the number of multiplications from 4 to 3: (A 1 + A 2 ) (B 1 + B 2 ) = A 1 B 1 + (A 1 B 2 + A 2 B 1) + A 2 B 2, I. e. , (A 1 B 2 + A 2 B 1) = (A 1 + A 2 ) (B 1 + B 2 ) - A 1 B 1 - A 2 B 2, which requires only 3 multiplications at the expense of (4 -1) extra add/sub.

• Recurrence for the number of multiplications: -

Conventional Matrix Multiplication • Brute-force algorithm c 00 c 01 a 00 a 01 = c 10 c 11 a 10 a 11 b 00 b 01 * b 10 b 11 a 00 * b 00 + a 01 * b 10 a 00 * b 01 + a 01 * b 11 a 10 * b 00 + a 11 * b 10 a 10 * b 01 + a 11 * b 11 = 8 multiplications 4 additions efficiency in n 3
: c")
Strassen’s Matrix Multiplication • Strassen’s algorithm for two 2 x 2 matrices (1969): c 00 c 01 a 00 a 01 b 00 b 01 = * c 10 c 11 a 10 a 11 b 10 b 11 = • • m 1 + m 4 - m 5 + m 7 m 1 = (a 00 + a 11) * (b 00 + b 11) m 2 = (a 10 + a 11) * b 00 m 3 = a 00 * (b 01 - b 11) m 4 = a 11 * (b 10 - b 00) m 5 = (a 00 + a 01) * b 11 m 6 = (a 10 - a 00) * (b 00 + b 01) m 7 = (a 01 - a 11) * (b 10 + b 11) m 2 + m 4 m 3 + m 5 m 1 + m 3 - m 2 + m 6 7 multiplications 18 additions/subtraction
![Strassen’s Matrix Multiplication Strassen observed [1969] that the product of two matrices can be](http://slidetodoc.com/presentation_image_h/0251c6f1f0533e8ec8a8e7d326306a14/image-23.jpg "Strassen’s Matrix Multiplication Strassen observed [1969] that the product of two matrices can be")
Strassen’s Matrix Multiplication Strassen observed [1969] that the product of two matrices can be computed in general as follows: C 00 C 01 A 00 A 01 = C 10 C 11 B 00 B 01 * A 10 A 11 M 1 + M 4 - M 5 + M 7 B 10 B 11 M 3 + M 5 = M 2 + M 4 M 1 + M 3 - M 2 + M 6 Where A and B be two n by n matrices where n is a power of two. We can divide A, B and their product C into four n/2 by n/2 submatrices.
 (B 00")
Formulas for Strassen’s Algorithm M 1 = (A 00 + A 11) (B 00 + B 11) M 2 = (A 10 + A 11) B 00 M 3 = A 00 (B 01 - B 11) M 4 = A 11 (B 10 - B 00) M 5 = (A 00 + A 01) B 11 M 6 = (A 10 - A 00) (B 00 + B 01) M 7 = (A 01 - A 11) (B 10 + B 11)

Analysis of Strassen’s Algorithm If n is not a power of 2, matrices can be padded with zeros. Number of multiplications:

Recurrence • Recursive function call itself. • Recurrence is an equation or inequality that describes a function in terms of its value on smaller inputs. • Where T(n) is recurrence • an instance of size n can be divided into b instances of size n/b , with a of them needing to be solved. • a>= 1 and b> 1 • For obtaining Recurrence in Asymptotic notions: • Substitution Method • Recursion Tree Method • Master Method

Substitution Method For example: - for Recurrence We guess that values is O(n lg n) Then substituting yields: - • Where c >= 1

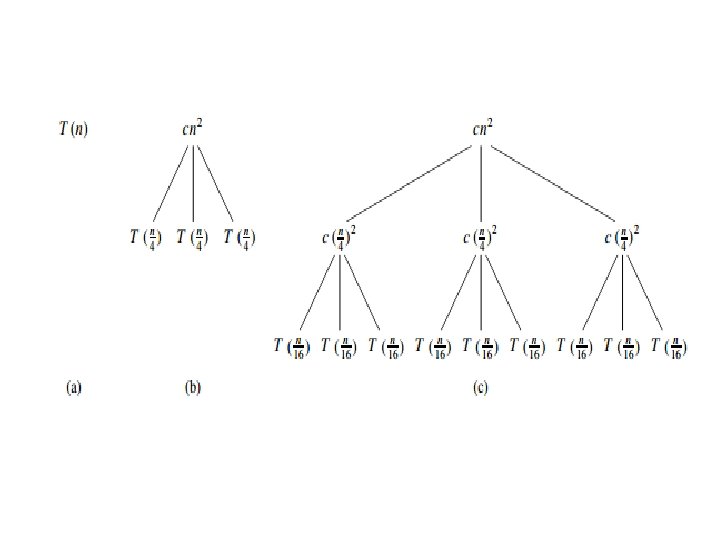
Recursion Tree Method • In recursion tree, each node represents the cost of a single sub-problem somewhere in the set of recursive function invocations. • We sum the costs within each level of the tree to obtain a set of per level costs, and then we sum all he per-level costs to determine he total cost of all levels of the recursion. • For example: T(n) = 3 T(n/4) + cn 2
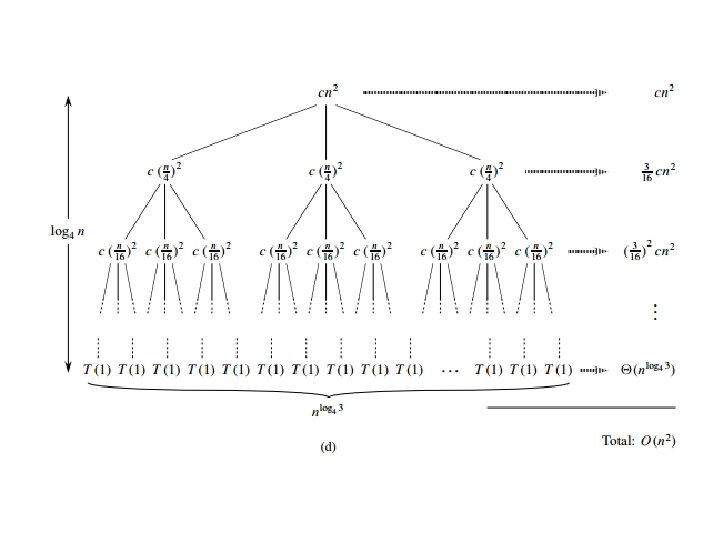
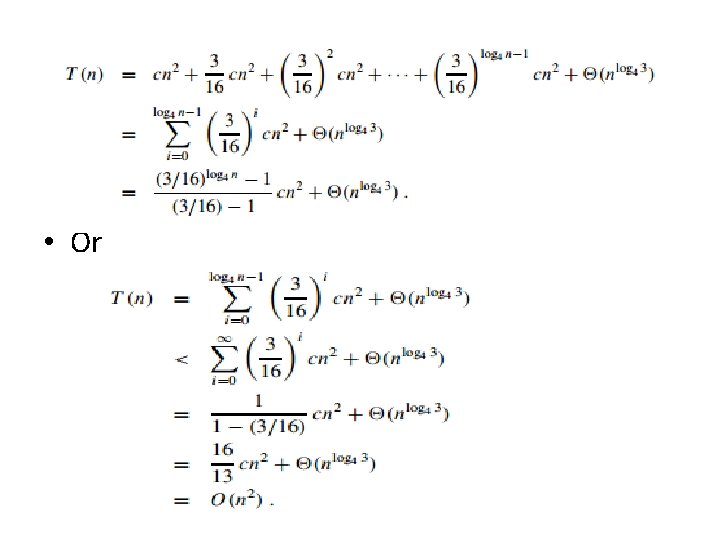

Master Method

• • Case 1 : Case 2 : Case 3: For Example: - > f(n) = f(n) < f(n)

• Example 2: - Example 3: -

Some Log
 and")
Closest-Pair Problem by Divide-and-Conquer Step 0 Sort the points by x (list one) and then by y (list two). Step 1 Divide the points given into two subsets S 1 and S 2 by a vertical line x = c so that half the points lie to the left or on the line and half the points lie to the right or on the line.
 Step 2 Find recursively the closest pairs for")
Closest Pair by Divide-and-Conquer (cont. ) Step 2 Find recursively the closest pairs for the left and right subsets. Step 3 Set d = min{d 1, d 2} We can limit our attention to the points in the symmetric vertical strip of width 2 d as possible closest pair. Let C 1 and C 2 be the subsets of points in the left subset S 1 and of the right subset S 2, respectively, that lie in this vertical strip. The points in C 1 and C 2 are stored in increasing order of their y coordinates, taken from the second list. Step 4 For every point P(x, y) in C 1, we inspect points in C 2 that may be closer to P than d. There can be no more than 6 such points (because d ≤ d 2)!

Closest Pair by Divide-and-Conquer: Worst Case The worst case scenario is depicted below:
 is: T(n)")
Efficiency of the Closest-Pair Algorithm Running time of the algorithm (without sorting) is: T(n) = 2 T(n/2) + Θ(n) By the Master Theorem (with a = 2, b = 2) T(n) Θ(n log n) So the total time is Θ(n log n).

Quick hull Algorithm for Finding Convex Hull Convex hull: smallest convex set that includes given points. An O(n^3) brute force time. • Assume points are sorted by x-coordinate values • Identify extreme points P 1 and P 2 (leftmost and rightmost) • Compute upper hull recursively: – find point Pmax that is farthest away from line P 1 P 2 – compute the upper hull of the points to the left of line P 1 Pmax – compute the upper hull of the points to the left of line Pmax. P 2 • Compute lower hull in a similar manner Pmax P 2 P 1

Efficiency of Quickhull Algorithm • Finding point farthest away from line P 1 P 2 can be done in linear time. -- worst case: Θ(n 2) -- average case: Θ(n) • If points are not initially sorted by x-coordinate value, this can be accomplished in O(n log n) time
- Slides: 41