Chapter 10 Functional Dependencies and Normalization for Relational






: • Design a relation schema so that it is easy to explain its")
 • Department (DNum, DName, Dmang#) •")













: design relation schemas so that they can be joined with equality conditions on")

 • ﺗﻌﺮﻳﻒ ﺍﻻﻋﺘﻤﺎﺩ ﺍﻟﺪﺍﻟﻲ • A functional dependency denoted by x y")



 • Given a set of FDs F, we can")
 • Some additional inference rules that are useful: –")



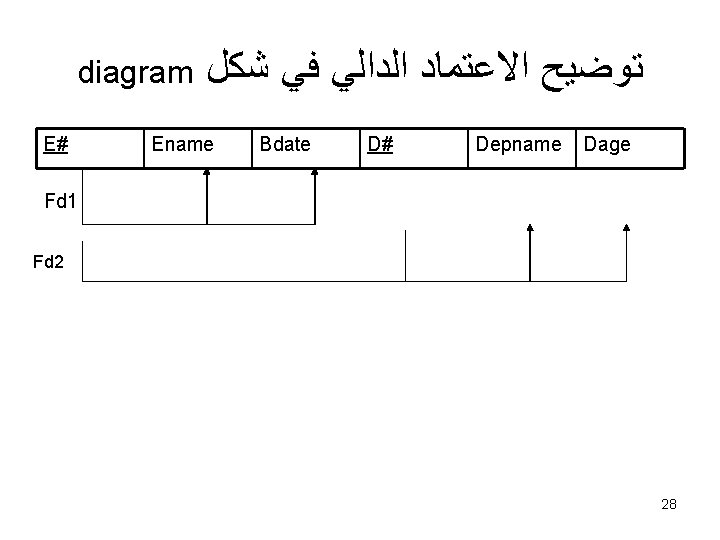
 ﻣﺜﺎﻝ Department ( Dep# , Dname, Dlocation) Department Dep-No D 1 D 2")





")
 •")




- Slides: 50
Chapter 10 Functional Dependencies and Normalization for Relational Databases 2
Informal Design Guidelines for Relational Databases • What is relational database design? – The grouping of attributes to form "good" relation schemas • Two levels of relation schemas – The logical "user view" level – The storage "base relation" level • Design is concerned mainly with base relations • What are the criteria for "good" base relations? 3
Informal Design Guidelines for Relational Databases • We first discuss informal guidelines for good relational design • Then we discuss formal concepts of functional dependencies and normal forms – - 1 NF (First Normal Form) – - 2 NF (Second Normal Form) – - 3 NF (Third Normal Form) 4
Informal design Guidelines For Good Relation • 1. 2. 3. 4. Four informal measures of quality for relation schema design: Semantics of the attributes. Reducing the redundant values in tuples. Reducing the null values in tuples. Disallowing the possibility of generating spurious tuples. 5
1. Semantics of the relation attributes : • • The relation is the set facts (each tuple in the relation represent a fact). Grouping of attributes in one relation determine the clearness of semantics (meaning) of the attribute values in the relation tuple. ( How the attribute values in tuple related to one another). 6
Guideline(1): • Design a relation schema so that it is easy to explain its meaning. • Do not combine attributes from multiple entity types and relationship types into a single relation. • If Relation schema corresponds to one entity type or one relationship type then the semantic of this relation is clear otherwise it becomes semantically unclear. 7
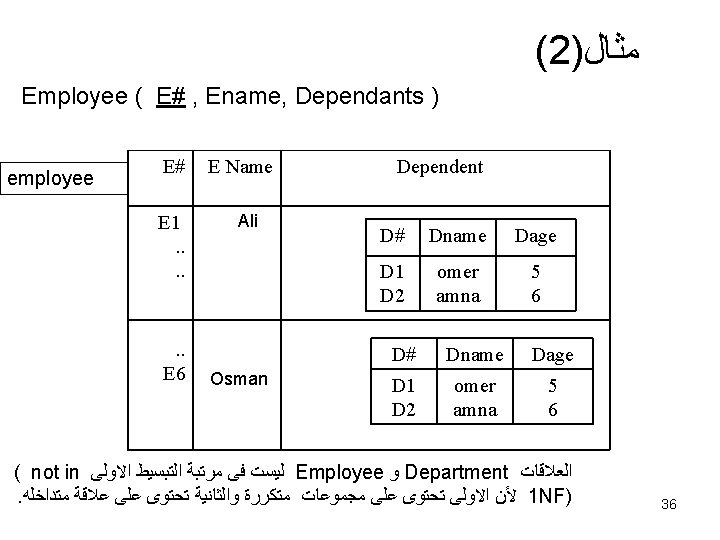
Example • Employee (emp#, emp-name, salary, birthdate, DNum) • Department (DNum, DName, Dmang#) • Emp-project(emp#, project #, no of hours) Three above relations have clear semantics why? • Emp-Dep (emp#, emp-name, salary, birthdate, DNum, DName, Dmang#) • Emp-project-Dep (emp#, project #, D#. no of hours) The last two relations have unclear semantics why? 8
2. Reducing the redundant values in tuples : • • • 1. 2. One goal of schema design is to minimize the storage space that base relations (files) occupy. Grouping of attributes in relation affected on storage space. Redundancy problems: Wasting of storage space. Update anomalies problems ( ﺍﻟﺸﺎﺫ )ﺍﻟﺘﺤﺪﻳﺚ 9
Example Empdep Emp# empname salary Birthdate DNum DName Dmanager# E 1 Ali 10, 000 1972 D 15 Cs E 5 E 2 Osman 100, 000 1960 D 14 Stat E 6 E 3 Khalid 50, 000 1970 D 14 Stat E 6 E 4 A/Rahman 70, 000 1968 D 14 Stat E 6 The above relation is suffering from redundancy, What are the other problems of this relation? 10
• Update anomalies classified as : 1. 2. 3. Insertion anomalies. Deletion anomalies. Modification anomalies. 11
1. Insertion anomalies: • To insert new employee in emp-dep relation , if the employee does not work for a department as yet so that the attribute values for department must be null values. If the employee department is determined say D 14 , so we must enter the attribute values for D 14 so that they consistent with values for D 14 in other tuples. Also insertion new department may leads to insertion anomalies, how? • • 12
2. Deletion anomalies: If we delete an employee tuple from emp-dep , and that employee represents the last employee working for a particular department , then the information concerning that department is lost from DB. Example: delete employee E 1 from emp-dep. Leeds to loosing of D 15 information. 13
3. Modification anomalies: In emp-dep if we change the manager of D 14 , we must update all the tuples of all employees who are working in that department. Guideline (2): • Design the base relation so that no insertion, deletion, or modification anomalies are present in the relation. • second guideline is consistent with, and in a way a restatement of the first guideline. 14
• The first and second guidelines may sometimes have to be violated in order to improve the performance of certain queries. 15
3. null values in the tuples: • 1. 2. 3. Problems of null values: Wasting of storage space. Problem of joining between relations Problems when aggregate operations such as count, sum, or average are used , how to account null values. • Reasons for nulls: – Attribute not applicable or invalid – Attribute value unknown (may exist) – Value known to exist, but unavailable Guideline(3): As far as possible avoid placing attributes in a base relation whose values may frequently be null 16
4. Generation of spurious tuples: Spurious tuples, tuples resulting from joining between two relations with incorrect information (data or facts). 17
Example 18
19
20
21
Guideline(4): design relation schemas so that they can be joined with equality conditions on attributes that are either primary keys or foreign keys to guarantee that no spurious tuples are generated. 22
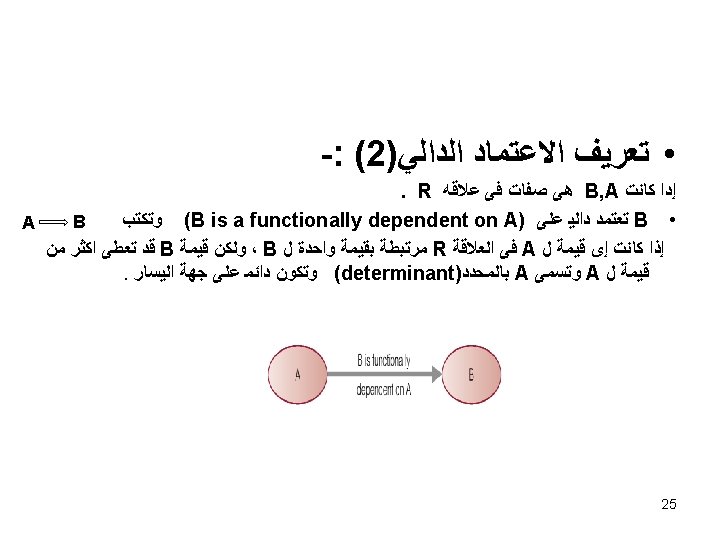
: (1) • ﺗﻌﺮﻳﻒ ﺍﻻﻋﺘﻤﺎﺩ ﺍﻟﺪﺍﻟﻲ • A functional dependency denoted by x y , between two sets of attributes x and y that are subsets of relation R specifies a constraint on possible tuples that can form a relation state r of R. the constraint is that , for any two tuples t 1 and t 2 in r that have t 1[x]=t 2[x], we must also have t 1[y]=t 2[y]. • X is functionally determines y • y is functionally dependent on x • x: left hand side of FD, y : R. h. s of FD 24
-: ﻣﺜﺎﻝ -: employee ﺍﻟﻌﻼﻗﺔ ﺧﺎﺭﻃﺔ Employee (E#, Ename , Bdate , D# , Depname , Dage) E# {Ename , Bdate} D# Ename ( Ename is not FD on D # ) {E# , D#} {Depname , Dage} FD={E# {Ename , Bdate} , {E# , D#} {Depname , Dage}} 27
Additional Examples of FD constraints • Social security number determines employee name – SSN -> ENAME • Project number determines project name and location – PNUMBER -> {PNAME, PLOCATION} • Employee ssn and project number determines the hours per week that the employee works on the project – {SSN, PNUMBER} -> HOURS Slide 10 - 29
Inference Rules for FDs (1) • Given a set of FDs F, we can infer additional FDs that hold whenever the FDs in F hold • Armstrong's inference rules: – IR 1. (Reflexive) If Y subset-of X, then X -> Y – IR 2. (Augmentation) If X -> Y, then XZ -> YZ • (Notation: XZ stands for X U Z) – IR 3. (Transitive) If X -> Y and Y -> Z, then X -> Z • IR 1, IR 2, IR 3 form a sound and complete set of inference rules – These are rules hold and all other rules that hold can be deduced from these Slide 10 - 30
Inference Rules for FDs (2) • Some additional inference rules that are useful: – Decomposition: If X -> YZ, then X -> Y – Union: If X -> Y and X -> Z, then X -> YZ – Psuedotransitivity: If X -> Y and WY -> Z, then WX -> Z • The last three inference rules, as well as any other inference rules, can be deduced from IR 1, IR 2, and IR 3 (completeness property) Slide 10 - 31
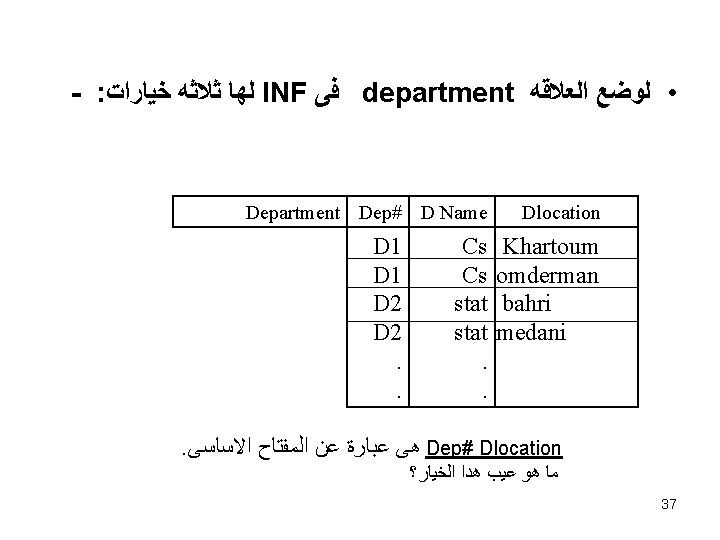
(1) ﻣﺜﺎﻝ Department ( Dep# , Dname, Dlocation) Department Dep-No D 1 D 2 D Name Dlocation Cs Khartoum omderman Stat Bahri Medani 35
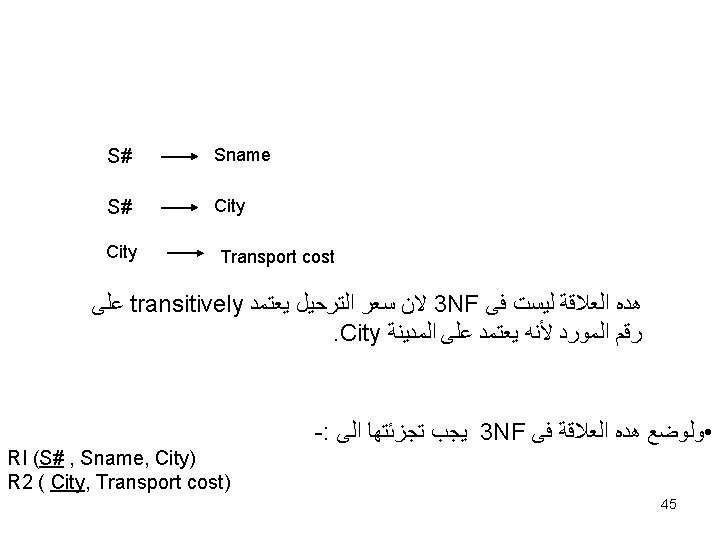
ﻣﺜﺎﻝ • Suppliers ( S# , Sname , City , Transport cost ) Suppliers S# S 1 S 2 S 3 S 4 Sname Amar Yasseen Amin omer City transport cost PS GD GD PS 500 400 500 44
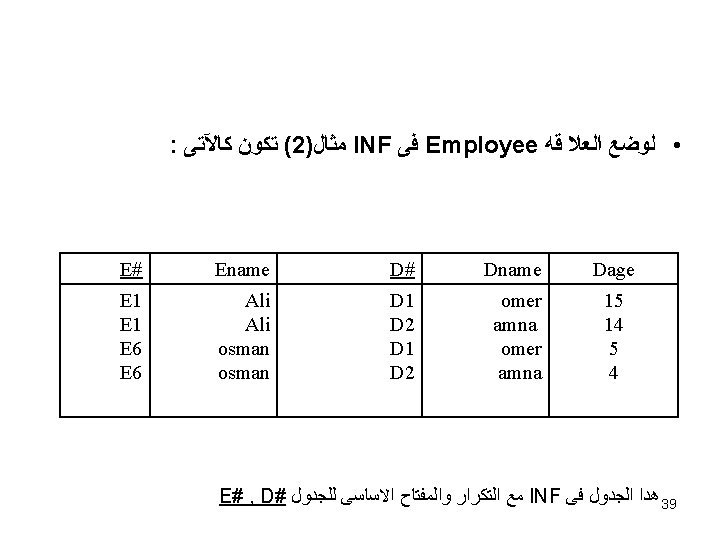
ﻣﺜﺎﻝ • R ( Person ID, Project No, Budget, No of hours) • R in INF -: 2 NF ﻫﻞ ﻫﻰ ﻓﻰ R • ﻧﺨﺘﺒﺮ {Person ID, project. No } project. No No of hours Budget ﻟﻤﺎﺫﺍ؟ 2 NF ﻓﻰ ﻟﻴﺴﺖ R 46
Summery • • • Normalization of data means a process of analyzing the given relation schemas based on their FDs and primary keys to achieve properties of : 1 -minimizing the redundancy 2 -minimizing update anomalies. 49