Canonical Correspondence Analysis CCA And Other techniques Vamsi
 And Other techniques Vamsi Sundus Shawnalee")


 Dependent matrix – contains data to be ordinated, usually composed")

 that uses")

 Data must be collected from the same place at the")
 I forgot. Let’s say we want to observe the effects of a")


, means something is being optimized")
 correspondance analysis and canonical is the")

 and compute")








 Major difference in limitations: (Number of species + environmental variables) <")

 in")
 Fn = value of nth factor Lamdajn= loading variable j on")
 FA becomes an eigenvector problem hence Similar to PCA (eigenanalysis of correlation")





 Differs from other multivariate techniques Uses only one distance measure derived")





- Slides: 42
Canonical Correspondence Analysis (CCA) And Other techniques Vamsi Sundus Shawnalee
What is CCA? “Commonly used by researchers trying to understand the relationship between community composition and environmental factors. ” Or, more generally, comparing/testing one multivariate dataset against a second one. Like DECORANA (the last presentation), it’s based off of correspondence analysis (ordination technique).
CCA Purpose? To incorporate environmental data into the ordination so that a better final ordination diagram can be created.
What’s needed (Part I) Dependent matrix – contains data to be ordinated, usually composed of population estimates for a bunch of species) 2. Environmental matrix – describes environmental conditions. Must contain the same number of rows (observations) as the species data, but must have fewer columns than the number of observations. 1.
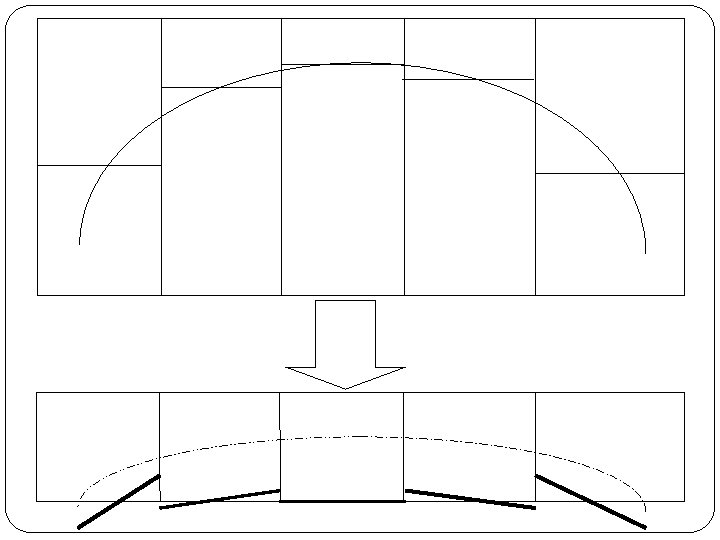
Problems Just like correspondence analysis, an arching effect may be found resulting in the second ordination axis “being a distortion of the first. ” We eliminated this previously using a detrended technique.
DCCA In the same manner, CCA has detrended canonical correspondence analysis (DCCA) that uses essentially the same algorithm to terminate the second ordination axis and eliminate the arch effect.
Complicated “Canonical correspondance analysis can be considered to be a form of direct ordination, although it is so much more complicated than conventional examples of direct ordination…being a hybrid of direct and indirect ordination. ”
What’s needed (Part II) Data must be collected from the same place at the same time. Autoregressive error? If not collected together error of pseudoreplication.
Pseudoreplication (Reteaching) I forgot. Let’s say we want to observe the effects of a drug on estrus (monthly period cycle). Let n=100. n 1 = 50, n 2 = 50, n = n 1 + n 2 Trt A, Trt B Have all mice in same room.
Problems with this design Inherent in this design are problems: Chemical cues for setting cycle. One mice influences the next. Like in colleges. Pseudoreplication, apparently independent, but not really, data.
Back to CCA End divergence.
Canonical Definition: Whenever used in this field (multivariate analysis), means something is being optimized against some other constraint.
The Steps The only major difference between (regular) correspondance analysis and canonical is the addition of two steps.
Step 1 - CA Start with a random weighting. It’s pretty kosher to start from 0. 0 100. 0 in whatever increments are needed. In our case, we’ll do (0, 50, 100) for (A, B, C) Use this formula for nth species rank:
Step 2 - CA Use the starter weights (which are arbitrary essentially) and compute a weighting for each of the years Year Counts 1 100 0 0 2 90 10 0 3 80 20 5 4 60 35 10 5 50 50 20 6 40 60 30 7 20 30 40 8 5 20 60 9 0 10 75 10 0 0 90 --> --> --> Y 1 0. 0 5. 0 14. 3 26. 2 37. 5 46. 2 61. 1 82. 4 94. 1 100. 0
Step 3 We can now calculate a new weighting for each species using these new year weightings. A Calculate similarly for B, C Old weightings for species S 10 S 1 a 0 19. 1 50 43. 9 100 78. 5 New calculated weightings for species
Step 4 These new weightings for each species though aren’t that useful, so we need to rescale them back to 0 100, instead of currently 19. 1 78. 5. So, to do this, simply use a logical rescaling method. S 1 a 19. 1 43. 9 78. 5
Step 4 cont. So, after computing the rescaled values, we find the following: S 10 0 50 100 S 1 a 19. 1 43. 9 78. 5 S 1 b 0. 00 41. 75 100. 00
Step 5 This is now one cycle of the CA completed. “Weightings for each year are recalculated using the new, rescaled weightings for the species. ” Eventually a stable patter will emerge. 10 -20 iterations.
CA vs. CCA Start with arbitrary but unequal site scores Calculate species scores as weighted average of site scores Calculate new site scores as weighted average of species scores. Standardize Stop if acceptable; otherwise iterate from step 2 Perform multiple regression of site scores on environmental variables Use multiple regression to derive new predicted values.
Other Techniques There are many other techniques that are available for multivariate analysis. COR CVA FA MDS MRPP MANCOVA MANOVA NMS NMDS Procustes Rotation RDA PRC
COR Canonical Correlation Analysis Similar to CCA. Continuation of the progression from bivariate to multiple linear regression. Bivariate = 1 independent to explain 1 dependent Multivariate = n independent to explain 1 dependent Canonical = n independent to explain m dependent
COR (cont. ) Major difference in limitations: (Number of species + environmental variables) < number of sites. //COR Weaker requirement for CCA (Number of environmental variables alone < number of observations. //CCA Both result in similar outputs. CCA is preferred. (easier limitations to meet on allowable number of variables).
CVA Canonical Variates Analysis Purpose: generate a score for each inidvidual, which, using a 1 way anova by category would return the highest possible F value Maximize variance within dataset hence canonical. Limitations: multivariate normality, categories need to be known a priori.
FA Factor Analysis is used as a synonym for PCA (Principal component analysis) in the US How it began: School students – scores in Classics, French, English, Math, Discrimination of Pitch, and Music Abilities in each due to smaller number of fundamental skills (factors). Derive absolute parameter estimates.
FA (cont. ) Fn = value of nth factor Lamdajn= loading variable j on factor n ej = residual for variable j P = number of variables M = number of factors
FA (cont) FA becomes an eigenvector problem hence Similar to PCA (eigenanalysis of correlation matrix). “…the results are…difficult to interpret and based on assumptions that are probably invalid. ” “FA is not worth the time necessary to understand perform it. ” (Hills 1977)
MDS Multidimensional Scaling Takes square matrix of distances between individuals and recreates maps Discussed previously
MRPP Multiresponse Permutation Procedure Assesses the probability that two or more groups consisting of multivariate data differ Different from normal mulivariate ANOVA in that it’s non-parametric can be used on biological data without worrying about multivariate normality
MANCOVA Multivariate Analysis of Covariance Multivariate equivlent of ANOVA Assumption of normality Lacks non-parametric test though
MANOVA Multivariate ANOVA Analagous to univariate ANOVA provides estimate of the probability that the observed patter arises from random data. Each mean is treated as a coordinate in multivariate space. Used specifically in assessing whether “an overall response has occurred, but will not identify which variables contributed to treatments if significance is found. ” Requires normality, or else. Or else use MRPP
NMS, NMDS Non-metric multidimensional scaling Ordinal scaling Square distance matrix map reconstructed Differs from other multivariate techniques
NMS, NMDS (cont) Differs from other multivariate techniques Uses only one distance measure derived from ranked differences between individuals. So, can be used with non-normal, discontinuous or questionable distributions. Ordinations axes will differ according to how many axes are requested. Where two or more ordination axes are requested, the first axis need not be more important than the second or higher axes. axis numbering is arbitrary. A lot of subjectivity in the technique in choice of axis, hence not used that often.
Procrustes Rotation Compares two different ordinations applied to the same data. Has m 2 statistic (residual sum of squares) to assess after Procrustes operations have been applied. No significance test No clear guildelines to interpret m 2 values
Procrustes Rotation Named is derived from Greek mythology. Inn keeper who ensured al his customers fittyed perfectly to his bed by stretching them or chopping their feet off.
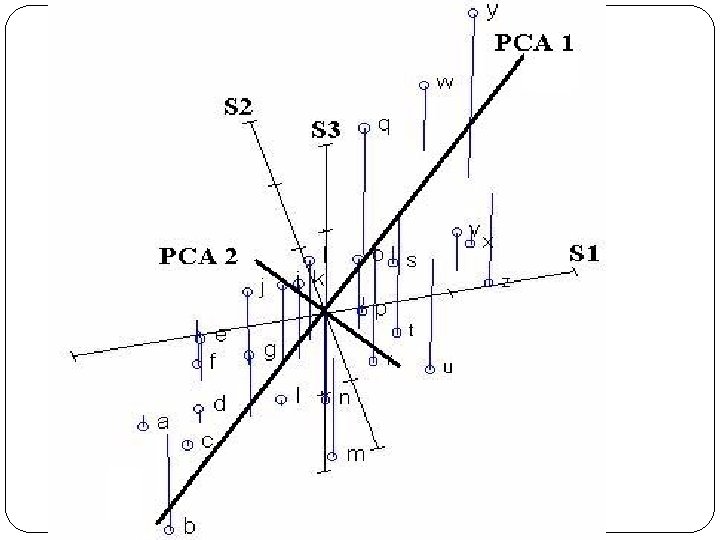
RDA Redundancy Analysis Derivative or PCA with bonus feature Values entered into analysis aren’t original data but the best-fit values estimated from a multiple linear regression between each variable and second matrix of environmental data. Thus, this is a canonical version of PCA Constrained to optimally correlate with another dataset. Interpretation is by biplot Collinearity, which is likely in biological data, makes canonical coefficients unreliable. RDA = technique that underlies PRC
PRC Principal response curves 1999, New technique Derived from RDA and specfically intended to help interpret planned experiements on biological communities. Two treatments, one is a control Reapeated sampling <not enough details>
END