Calibration Guidelines Model development 1 Start simple add

Calibration Guidelines Model development 1. Start simple, add complexity carefully 2. Use a broad range of information 3. Be well-posed & be comprehensive 4. Include diverse observation data for ‘best fit’ 5. Use prior information carefully 6. Assign weights that reflect ‘observation’ error 7. Encourage convergence by making the model more accurate 8. Consider alternative models Model testing 9. Evaluate model fit 10. Evaluate optimal parameter values Potential new data 11. Identify new data to improve parameter estimates 12. Identify new data to improve predictions Prediction uncertainty 13. Use deterministic methods 14. Use statistical methods
 Start")
Model Development Guideline 1: Apply principle of parsimony (start simple, add complexity carefully) Start simple. Add complexity as warranted by the hydrogeology, the inability of the model to reproduce observations, the predictions, and possibly other things. But my system is so complicated!! DATA ARE LIMITED. SIMULATING COMPLEXITY NOT SUPPORTED BY THE DATA CAN BE USELESS AND MISLEADING.

Model complexity accuracy • Neither a million grid nodes nor hundreds of parameters guarantee a model capable of accurate predictions. • Here, we see that a model that fits all the data perfectly can be produced by adding many parameters, but the resulting model has poor predictive capacity. It is fitting observation error, not system processes. • We don’t know the ‘best’ level of complexity. We do know that we don’t want to start matching observation error. Observation error is evaluated when determining weights (Guideline 6).

Model complexity accuracy Model simplicity accuracy • General situation: Tradeoff between model fit and prediction accuracy with respect to the number of parameters model fit prediction error

Can 20% of the system detail explain 90% of the dynamics? • The principle of parsimony calls for keeping the model as simple as possible while still accounting for the main system processes and characteristics evident in the observations, and while respecting other system information. • Begin calibration by estimating very few parameters that together represent most of the features of interest. • The regression methods provide tools for more rigorously evaluating the relation between the model and the data, compared to trial and error methods. • It is expected (but not guaranteed) that this more rigorous evaluation produces more accurate models.

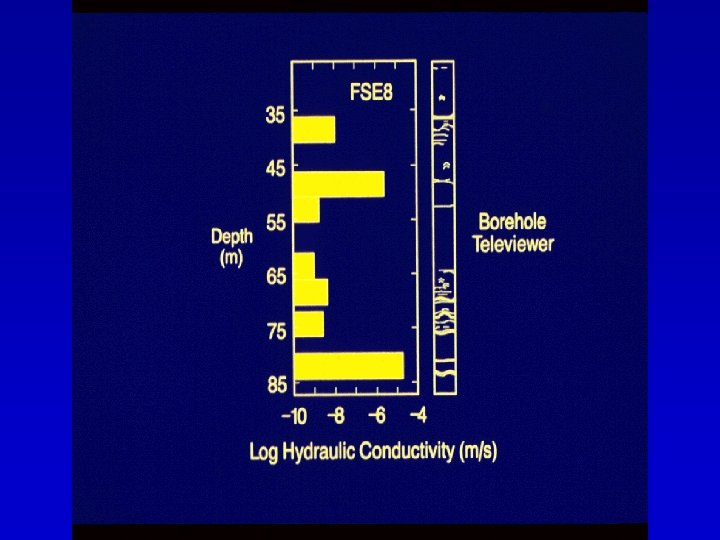
Flow through Highly Heterogeneous Fractured Rock at Mirror Lake, NH Tiedeman, et al. , 1998

20% of the system detail does explain 90% of the dynamics! MODFLOW Model with only 2 horizontal hydraulic conductivity parameters Conceptual Cross Section Through Well Field Fracture zones with high T Fractures with low T Fracture zones with high T

Apply principle of parsimony to all aspects of model development • Start by simulating only the major processes • Use a mathematical model only as complex as is warranted. • When adding complexity, test: § Whether observations support the additional complexity § Whether the additional complexity affects the predictions This can require substantial restraint!!!

Advantages of starting simple and building complexity as warranted § Transparency: Easier to understand the simulated processes, parameter definition, parameter values, and their consequences. Can test whether more complexity matters. § Refutability: Easier to detect model error. § Helps maintain big picture view consistent with available data. § Often consistent with detail needed for accurate prediction. § Can build prediction scenarios with detailed features to test the effect f those features. § Shorter execution times

Issues of computer execution time • Computer execution time for inverse models can be approximated using the time forward models and the number of parameters estimated (NP) as: Tinverse = 2(NP) Tforward (1+NP) is the number of solutions per parameter-estimation iteration 2(NP) is an average number of parameter estimation iterations • To maintain overnight simulations, try for Tforward < about 30 minutes • Tricks: – Buffer sharp K contrasts where possible – Consider linear versions of the problem as much as possible (for gw problems: replace the water table with assigned thickness unless the saturated thickness varies alot over time; replace nonlinear boundary conditions such as EVT and RIV Packages of MODFLOW with GHB Package during part of calibration) – Parallel runs

Calibration Guidelines Model development 1. Start simple, add complexity carefully 2. Use a broad range of information 3. Be well-posed & be comprehensive 4. Include diverse observation data for ‘best fit’ 5. Use prior information carefully 6. Assign weights that reflect ‘observation’ error 7. Encourage convergence by making the model more accurate 8. Consider alternative models Model testing 9. Evaluate model fit 10. Evaluate optimal parameter values Potential new data 11. Identify new data to improve parameter estimates 12. Identify new data to improve predictions Prediction uncertainty 13. Use deterministic methods 14. Use statistical methods
 to constrain")
Model Development Guideline 2: Use a broad range of information (soft data) to constrain the problem • Soft data is that which cannot be directly included as observations in the regression • Challenge: to incorporate soft data into model so that it (1) characterizes the supportable variability of hydrogeologic properties, and (2) can be represented by a manageable number of parameters. • For example, in ground-water model calibration, use hydrology and hydrogeology to identify likely spatial and temporal structure in areal recharge and hydraulic conductivity, and use this structure to limit the number of parameters needed to represent the system. Do not add features to the model to attain model fit if they contradict other information about the system!!

Example: Parameterization for simulation of groundwater flow in fractured dolomite (Yager, USGS Water Supply Paper 2487, 1997) How to parameterize hydraulic conductivity in this complex system? Yager took advantage of data showing that the regional fractures that dominate flow are along bedding planes.

Example: Parameterization for simulation of groundwater flow in fractured dolomite § Transmissivity estimated from aquifer tests is roughly proportional to the number of fractures intersecting the pumped well. § Thus, assume all major fractures have equal T, and calculate T for each model layer from the number of fractures in the layer. § The heterogeneous T field can then be characterized by a single model parameter and multiplication arrays.

Data management, analysis, and visualization problems can be daunting. It is difficult to allocate project time between these efforts and modeling in an effective manner, because: • There are many kinds of data (point well data, 2 D and 3 D geophysics, cross sections, geologic maps, etc) and the subsurface is often very complex. Capabilities for integrating these data exist, but can be cumbersome. • The hardware and software change often. Thus far, products have been useful, but not dependable or comprehensive. • Low end: Rockworks ~US$2000. High end: Earthvision ~US$100, 000 +US$20, 000/yr GUI’s provide some capabilities

Calibration Guidelines Model development 1. Start simple, add complexity carefully 2. Use a broad range of information 3. Be well-posed & be comprehensive 4. Include diverse observation data for ‘best fit’ 5. Use prior information carefully 6. Assign weights that reflect ‘observation’ error 7. Encourage convergence by making the model more accurate 8. Consider alternative models Model testing 9. Evaluate model fit 10. Evaluate optimal parameter values Potential new data 11. Identify new data to improve parameter estimates 12. Identify new data to improve predictions Prediction uncertainty 13. Use deterministic methods 14. Use statistical methods

Model Development Guideline 3: Be Well-Posed & Be Comprehensive Well posed: Don’t spread observation data too thinly For a well-posed problem, estimated parameters are supported by the calibration observations, and the regression converges to optimal values. In earth systems, observations are usually sparse, so being well-posed often leads to models with few parameters. Comprehensive: Include many system aspects. Characterize as many system attributes as possible using defined model parameters. Leads to many parameters. Is achieving Guideline 3 possible? Challenge: Bridge the gap. Develop a useful model that has complexity the observation data can support and the predictions need.

Be Well-Posed and Be Comprehensive § Often harder to be well posed than to be comprehensive. • Easy to add lots of complexity to a model. • Harder to limit complexity to what is supported by the observations and most important to predictions. § Keeping the model well-posed can be facilitated by: • Scaled sensitivities, parameter correlation coefficients, leverage statistics • Independent of model fit. Can use before model is calibrated • Cook’s D, DFBeta’s (influence statistics) • Advantage -- integrate sensitivities and parameter correlations. • Caution -- dependent on model fit. Use cautiously with uncalibrated model.
")
Dimensionless Scaled Sensitivities: Support of each observation for each parameter (example from Death Valley) • Estimation of parameter K 4 seems to be dominated by 4 observations: 3 heads and 1 flow. • Scaled sensitivities neglect parameter correlation, so some observations may be more important than indicated. In groundwater problems, flows are very important for reducing correlations. Heads: obs # 1 -501 Flows: obs # 502 -517 3 dominant head obs 1 dominant flow obs

Composite Scaled Sensitivities: Support of whole observation set for each parameter • CSS for initial Death Valley model with only 9 parameters. Supportable model complexity • Graph clearly reveals relative support the observations as a whole provide towards estimating each parameter. • Observations provide much information about RCH and 2 or 3 of the K parameters; little information about ANIV or ETM The observations provide enough information to add complexity to the K and RCH parameterization

Composite Scaled Sensitivities: Support of whole observation set for each parameter Supportable model complexity • Black bars: parameters estimated by regression. • Grey bars: not estimated by regression because of parameter correlation, insensitivity, or other reasons. Good way to show the observation support as the number of defined parameters becomes large. This graph is from the final Death Valley model.

Parameter correlations: DVRFS model Parameter pair Correlation GHBgs K 7 -0. 99 K 2 RCH 3 0. 98 RCH 3 Q 2 0. 97 K 1 RCH 3 0. 96 pcc >0. 95 for 4 parameter pairs in the three-layer DVRFS model with: • all 23 parameters active • no prior information • 501 head observations • 16 flow observations. • With head data alone, all parameters except vertical anisotropy are perfectly correlated -- Multiply all by any positive number, get identical head distribution. By Darcy’s Law. • The flow observations reduce the correlation to what is shown above.

Influence Statistics • Like DSS, they help indicate if parameter estimates are largely affected by just a few observations • Like DSS, they depend on the type, location, and time of the observation • Unlike DSS, they depend on model fit to the observed value. • Unlike DSS, they include the effect of pcc (parameter correlation coefficient) (Leverage does this, too) • Cook’s D: a measure of how a set of parameter estimates would change with omission of an observation, relative to how well the parameters are estimated given the entire set of observations.

Cook’s D – Which observations are most important to estimating all the parameters? (3 -layer Death Valley example) Accounts for sensitivities, parameter correlations, and model fit Estimation dominated by ~10% of the observations 5 obs very important: heads, 2 flows. 3 Importance of flows is better reflected by Cook’s D than scaled sensitivities. In gw problems, flows often resolve extreme correlation. Need flows to uniquely estimate parameter values. Although dependent on model fit, relative values of Cook’s D can be useful for uncalibrated models. flow obs (502 -517)

Sensitivity Analysis for 2 parameters • • • CSS DSS Leverage Cook’s D DFBETAS Conclusion: flow qleft has a small sensitivity but is critical to uncoupling otherwise completely correlated parameters.

Which statistics address which relations? ? Observations – Parameters - Predictions dss pss css ppr pcc leverage Parameter cv AIC BIC DFBETAS Cook’s D Observations -------- Predictions opr

Problems with Sensitivity Analysis Methods • Nonlinearity of simulated values with respect to the parameters • Inaccurate sensitivities

Nonlinearity: sensitivities differ for different parameter values. § Scaled sensitivities change for different parameter values because (1) the sensitivities are different and (2) the scaling. [dss= ( y/ b)bw 1/2] § Consider decisions based on scaled sensitivities to be preliminary. Test by trying to estimate parameters. If conclusions drawn from scaled sensitivities about what parameters are important and can be estimated change dramatically for different parameter values, the problem may be too nonlinear for this kind of sensitivity analysis and regression to be useful. § Parameter correlation coefficients commonly differ for different parameter values. § Extreme correlation is indicated if pcc=1. 0 for all parameter values; regression can look okay – but beware! (see example in Hill and Tiedeman, 2003) (pcc) From Poeter and Hill, 1997. See book p. 58

Inaccurate sensitivities How accurate are the sensitivities? • Most accurate: sensitivity-equation method. MODFLOW-2000. [Generally 57 digits] • Less accurate: Perturbation methods. UCODE_2005 or PEST. [Often only 23 digits] Both programs can use model-produced sensitivities if available. When does it NOT matter? • Scaled sensitivities, regression often do not require accurate sensitivities. Regression convergence improves with more accurate sensitivities for problems on the edge. [Mehl and Hill, 2002] When does it matter? • Parameter correlation coefficients. [Hill and Østerby, 2003] – Values of 1. 00 and – 1. 00 reliably indicate parameter correlation; smaller absolute values do not guarantee lack of correlation unless the sensitivities are known to be sufficiently accurate. – Parameter correlation coefficients have more problems as sensitivity accuracy declines for all parameters, but it is most severe for pairs of parameters for which one parameter or both parameters have small composite scaled sensitivity.

Calibration Guidelines Model development 1. Start simple, add complexity carefully 2. Use a broad range of information 3. Be well-posed & be comprehensive 4. Include diverse observation data for ‘best fit’ 5. Use prior information carefully 6. Assign weights that reflect ‘observation’ error 7. Encourage convergence by making the model more accurate 8. Consider alternative models Model testing 9. Evaluate model fit 10. Evaluate optimal parameter values Potential new data 11. Identify new data to improve parameter estimates 12. Identify new data to improve predictions Prediction uncertainty 13. Use deterministic methods 14. Use statistical methods
 in")
Model Development Guideline 4: Include many kinds of data as observations (hard data) in the regression § Adding different kinds of data generally provides more information about the properties of the simulated system. § In ground-water flow model calibration s Flow data are important. With only head data, if all major K and Recharge parameters are being estimated, extreme values of parameter correlation coefficients will likely occur (Darcy’s Law). s Advective transport (or concentration first-moment data) can provide valuable information about the rate and direction of ground-water flow. § In ground-water transport model calibration s. Advective transport (or concentration first-moment data) important because they are more stable numerically and the misfit increases monotonically as the fit to observations becomes worse. (Barth and Hill, 2005 a, b, Journal of Contaminant Hydrology)

Here, model fit does not change with changes in the parameter values unless overlap occurs From Barth and Hill (2005 a). Book p. 224
 § Has the advantage")
Contoured or kriged data values as ‘observations’? (book p. 284) § Has the advantage of creating additional ‘observations’ for the regression. § However, a significant disadvantage is that the interpolated values are not necessarily consistent with processes governing the true system, e. g. the physics of ground-water flow for the true system. For example, interpolated values could be unrealistically smooth across abrupt hydrogeologic boundaries in the true subsurface. § This can cause estimated parameter values to representative of the true system poorly. Proceed with Caution !!!!

Calibration Guidelines Model development 1. Start simple, add complexity carefully 2. Use a broad range of information 3. Be well-posed & be comprehensive 4. Include diverse observation data for ‘best fit’ 5. Use prior information carefully 6. Assign weights that reflect ‘observation’ error 7. Encourage convergence by making the model more accurate 8. Consider alternative models Model testing 9. Evaluate model fit 10. Evaluate optimal parameter values Potential new data 11. Identify new data to improve parameter estimates 12. Identify new data to improve predictions Prediction uncertainty 13. Use deterministic methods 14. Use statistical methods

Model Development Guideline 5: Use prior information carefully § Prior information allows some types of soft data to be included in objective function (e. g. T from aquifer test) § Prior information penalizes estimated parameter values that are far from ‘expected’ values through an additional term in the objective function. nh S (b) = å w i (hi - h'i (b)) 2 +… i =1 HEADS FLOWS § What are the ‘expected’ values? PRIOR

Ground-Water Modeling Hydrologic and hydrogeologic data: less accurate Relate to model inputs Ground-Water Model -- Parameters Dependent variable observations: more accurate Relate to model outputs - calibration Predictions Prediction uncertainty Societal decisions

Suggestions • Begin with no prior information, to determine the information content of the observations. • Insensitive parameters (parameters with small css): – Can include in regression using prior information to maintain a wellposed problem – Or during calibration exclude them to reduce execution time. Include them when calculating prediction uncertainty and associated measures (Guidelines 12 – 14). • Sensitive parameters: – Do not use prior information to make unrealistic optimized parameter values realistic. – Figure out why model + calibration data together cause regression to converge to unrealistic values (see Guideline 9).

Highly parameterized models • # parameters > # observations • Methods – Pilot points (de Marsily, Rama. Rao, La. Venue) – Pilot points with smoothing (Tikhonov) – Pilot points with regularization (Alcolea, Doherty) – Sequential self calibration (Gomez-Hernandez, Hendricks Franssen) – Representer (Valstar) – Moment mehod (Guadagnini, Neuman) • Most common current usage: PEST regularization capability, by John Doherty

Why highly parameterize? • Can easily get close fits to observations • Intuitive appeal to resulting distributions – We know the real field varies – Highly parameterized methods can be used to develop models with variable distributions – Mostly used to represent K; can use if for other aspects of the system

Why not highly parameterize? • Are the variations produced by highly parameterized fields real? • Perhaps NO if they are produced because of – Data error (erroneous constraint) – Lack of data (no constraint) – Instability • How can we know? • Here, consider synthetic problem. – Start with no observation error – Add error to observations
 . . . *. *. *. . .")
(From Hill and Tiedeman, 2006, Wiley) . . . *. *. *. . . . Model Layer 1 . . . 11 Observations: 10 heads (*), 1 flow (to river) 6 Parameters: HK_1 HK_2 (multiplier) RCH_1, RCH_2 K_RB (prior) VK_CB (prior) Steady state * * Model Layer 2 Top layer really homogeneous. * Consider using 36 pilot points to represent it.

Initial run with no data error Here, use the constrained minimization regularization capability of PEST Variogram inputs: Nugget=0. 0 a=3 x 107 Variance=0. 1 Interpolation inputs: Search radius=36, 000 Max points=36 Fit Criterion phi=1 x 10 -5 Consistent with the constant value that actually occurs. Equals fit achieved with a single HK_1 parameter given a correct model and observations with no error

Introducing variability The variogram and interpolation input reflects a much better understanding of the true distribution than would normally be the case. To create a more realistic situation, use β, the regularization weight factor S(b)= (y - yobs)T w (y - yobs) + β (Δp - 0)T w (Δp - 0) To the extent that β can be small, variability is allowed in the K distribution. Increased s 2 ln. K

No data error. Correct model. Perform regression starting from values other than the true values Percent error for each parameter calculated as 100 |(btrue-best)/btrue| For HK_1, best= exp(ln. K) ln. K=mean of the ln K’s of the 36 pilot points Also report s 2 ln. K If β is restricted to be close to 1. 0, the estimates are close to the true and s 2 ln. K is small, as expected. What happens if β can be small?

No data error. Correct model. Perform regression starting from values other than the true values Percent error for each parameter calculated as 100 |(btrue-best)/btrue| For HK_1, best= exp(ln. K) ln. K=mean of the ln K’s of the 36 pilot points s 2 ln(k)= 0. 1 β=

No data error. Correct model. Perform regression starting from another set of values Same good fit to obs

No data error. Correct model. Parameter estimates depend on starting parameter values • Disturbing. • Means that in the following results as β becomes small discrepancies may not be caused by observation error.

Data error. Correct model. • Parameter error • Distribution of K in layer 1
= 1. 2 Not possible to")
Data error. Correct model. Parameter error s 2 ln(k)= 1. 2 Not possible to determine for which phi values will be accurate. Small parameter error Accurate predictions? Depends on effect of the variability.

Lessons • Inaccurate solutions? – Possibly. Variability can come from actual variability, or from data error or instability of the HP method. • Exaggerated uncertainty? – Possibly, if include variability caused by data error and instabilities. True of Moore and Doherty method? ? • How can we take advantage highly parameterized methods? – Use hydrogeology to detect unrealistic solutions. – Analyze observation errors and accept that level of misfit. Set phi accordingly. – Consider weighting of regularization equations. Use b=1? – Check how model fit changes as phi changes. – Use sensitivity analysis to identify extremely correlated parameters and parameters dominated by one observation. Use parsimonious overlays.

Calibration Guidelines Model development 1. Start simple, add complexity carefully 2. Use a broad range of information 3. Be well-posed & be comprehensive 4. Include diverse observation data for ‘best fit’ 5. Use prior information carefully 6. Assign weights that reflect ‘observation’ error 7. Encourage convergence by making the model more accurate 8. Consider alternative models Model testing 9. Evaluate model fit 10. Evaluate optimal parameter values Potential new data 11. Identify new data to improve parameter estimates 12. Identify new data to improve predictions Prediction uncertainty 13. Use deterministic methods 14. Use statistical methods

“Observation” error? ? ? Measurement error vs. model error Should weights account for only measurement errors, or also some types of model error? • A useful definition of observation error that allows for inclusion of some types of model error is: – Any error with an expected value of zero that is related to aspects of the observation that are not represented in the model (could be, for example, the model configuration and/or the simulated processes). • Unambiguous measurement errors: Errors associated with the measuring device and the spatial location of the measurement. • More ambiguous errors: Heads measured in wells that partially penetrate a model layer. Here, even in a model that perfectly represents the true system, observed and simulated heads will not necessarily match. The weights could be adjusted to account for this mismatch between model and reality if the expected value of the error is zero.

Model Development Guideline 6: Assign weights that reflect ‘observation’ error • Model calibration and uncertainty evaluation methods that do not account for ‘observation’ error can be misleading and are not worth using. • ‘Observation’ errors commonly are accounted for by weighting • Can use large weights (implied small ‘observation’ error) to investigate solution existence. • For uncertainty evaluation the weights need to be realistic

Model Development Guideline 6: Assign weights that reflect ‘observation’ error Strategy for uncorrelated errors § Assign weights equal to 1/s 2, where s 2 is the best estimate of the variance of the measurement error (details given in Guideline 6 of the book). § Values entered can be variances (s 2), standard deviations (s) or coefficients of variation (CV). Model calculates variance as needed. Advantages § Weight more accurate observations more heavily than less accurate observations – intuitively appealing § This produces squared weighted residuals that are dimensionless, so they can be summed in the objective function. § Use information that is independent of model calibration, so statistics used to calculate the weights generally are not changed during calibration. § This weighting strategy is required for common uncertainty measures to be correct. § Without this the regression becomes difficult and arbitrary.

If weights do not reflect ‘observation’ error, regression becomes difficult and arbitrary Interested in predictions for large values of x. y=b 0+b 1 x y Will accuracy of predictions be improved by weighting this observation more? x No, not if the model is correct and the other data are important.
 a")
Determine weights by evaluating errors associated with the observations Often can assume (1) a normal distribution and (2) different error components are additive. If so, two things are important. (a) add variances, not standard deviations or coefficients of variation! (b) Mean needs to equal zero! Quantify possible magnitude of error using • range that is symmetric about the observation or prior information • probability with which the true value is expected to occur within the range. Examples: • Head observation with three sources of error • Streamflow loss observation
 Head measurement is thought to be")
Head observation with three sources of error (1) Head measurement is thought to be good to within 3 feet. (2) Well elevation is accurate to 1. 0 feet. (3) Well located in the model within 100 feet. Local gradient is 2%. • Quantify “good to within 3 feet” as “there is a 95 -percent chance the true value falls within ± 3 feet of the measurement. ” – Use a normal probability table to determine that a 95 -percent confidence interval is a value ± 1. 96 times the standard deviation, s. – This means that 1. 96 x s = 3 ft. , so s = 1. 53 ft. • Quantify well elevation error similarly to get s=0. 51 ft. • Quantify “located in the model within 100 feet. Locally the gradient is 2%” as “there is a 95 -percent chance the true value falls within plus and minus 2 feet” – Using the procedure above, s=1. 02 ft. • Calculate observation statistic. Add variances: (1. 53)2 + (0. 51)2 + (1. 02)2 = 3. 64 ft 2 s=1. 91 ft. Specify variance or standard deviation in the input file.

Streamflow loss observation Streamflow gain observation derived by subtracting flow measurements with known error range and probability. • Upstream and downstream flow measurements: 3. 0 ft 3/s and 2. 5 ft 3/s loss observation = 0. 5 ft 3/s. The first flow measurement is considered ‘fair’, the second is ‘good’. Carter and Anderson (1963) suggest that a good streamflow measurement has a 5% error. • Quantify the error. ± 5% forms a 90% confidence interval on the ‘fair’ upstream flow; plus and minus 5% forms a 95% confidence interval on the ‘good’ downstream flow. Using values from a normal probability table, the standard deviations of the two flows are 0. 091 and 0. 64. • Calculate observation statistic Add variances: [(0. 091)2 + (0. 64)2]1/2 = 0. 0124. Coefficient of variation: 0. 0124/0. 5 = 0. 22, or 22 percent. Specify variance, standard deviation or coefficient of variation in the input file

What if weights are set to unrealistically large values? Objective function surfaces (contours of objective function calculated for combinations of 2 parameters) With flow weighted using a reasonable coefficient of variation of 10% From Hill and Tiedeman, 2002. Book p. 82. Heads only With flow weighted using an unreasonable coefficient of variation of 1%

Unrealistically large weights: Hazardous consequences for predictions Unreasonable weighting results in misleading calculated confidence interval – excludes true value of 1737 m From Hill and Tiedeman, 2002. Book p. 303
- Slides: 61