Cache Coherent Distributed Shared Memory Motivations Small processor

Cache Coherent Distributed Shared Memory

Motivations • Small processor count – SMP machines – Single shared memory with multiple processors interconnected with a bus • Large processor count – Distributed Shared Memory Machines – Largely message passing architectures

Programming Concerns • Message passing – Access to memory involve send/request packets – Communication costs • Shared memory model – Ease of programming – But not very scalable • Scalable and easy to program?

Distributed Shared Memory • Physically distributed memory • Implemented with a single shared address space • Also known as NUMA machines since memory access times are non-uniform – Local access times < Remote access times

DSM and Memory access • Big difference in accessing local versus remote data • Large differences make it difficult to hide latency • How about caching? – In short, it’s difficult – Cache coherence

Cache coherence • Cache Coherence – Different processors may access values at same memory location – How to ensure data integrity at all times? • An update by a processor at time t is available for other processors at time t+1 – Snoopy protocol – Directory based protocol

Snoopy Coherence Protocols • Transparent to user • Easy to implement • For a read – Data fetched from other cache or from memory • For a write – All data at other caches are invalidated – Delayed or immediate write-back. • The Bus plays an important role

Example

But it does not scale! • Not feasible for machines with memory distributed across a large number of systems • Broadcast on bus approach is bad • Leads to bus saturation • Waste of processor cycles to snoop all caches in system

Directory-Based Cache Coherence • A directory tracks which processor have cached a block of memory • Directory contains information for all cache blocks in system • Each cache block can have 1 of 3 states – Invalid – Shared – Exclusive • To enter exclusive state, all other cache blocks for same memory location is invalidated

Original form not popular • Compared to snoopy protocols – Directory systems avoid broadcasting on bus • But requests served by 1 directory server – May saturate a directory server • Still not scalable • How about distributing the directory – Load balancing – Hierarchical model?

Distributed Directory Protocol • Involved sending messages among 3 node types – Local node • Requesting processor node – Home node • Node containing memory location – Remote node • Node containing cache block in exclusive state

3 Scenarios • Scenario 1 – Local node sends request to home node – Home node sends data back to local node • Scenario 2 – Local node sends request to home node – Home node redirects request to remote node – Remote node sends data back to local node • Scenario 3 – Local node sends request for exclusive state – Home node redirects request to other remote nodes for invalidation

Example

Stanford DASH Multiprocessor • 1 st operational multiprocessor to support scalable coherence protocol • Demonstrates scalability and cache coherence are not incompatible • 2 hypotheses – Shared memory machines easier to program – Cache coherence vital

Past experience • From experience – Memory access times differ widely between physical location – Latency and bandwidth is important for shared memory systems – Caching helps amortize cost of memory access in a memory hierarchy

DASH Multiprocessor • Relaxed memory consistency model • Observation – Most programs use explicit synchronization – Sequential consistency is not necessary – Allows system to perform writes without waiting till all invalidations are performed • Offers advantages in hiding memory latency

DASH Multiprocessor • Non-Binding software prefetch – Prefetches data into cache – Maintains coherence – Transparent to user • Compiler can issue such instructions to help runtime performance – If data is invalidated, it will refresh the data when it is accessed • Helps to hide latency as well

DASH Multiprocessor • Remote Access Cache – Remote access combined and buffered within individual nodes – Can be likened to having a 2 -level cache hierarchy

Lessons • High performance require careful planning of remote data access • Scaling applications depend on other factors – Load balancing – Limited parallelism – Difficult to scale application into using more processor

Challenges • Programming model? – Model that helps programmers reason about code rather than fine-tuning for a specific machine • Fault tolerance and recovery? – More computers = Higher chance of failure • Increasing latency? – Increasing hierarchies = Larger variety of latencies

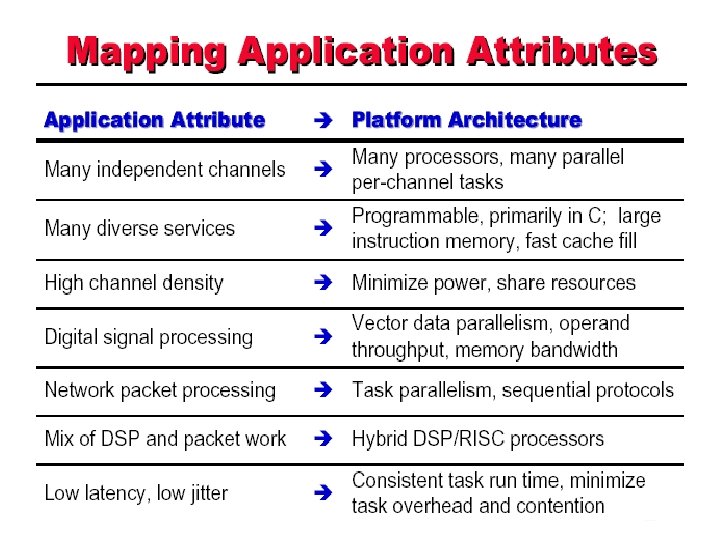
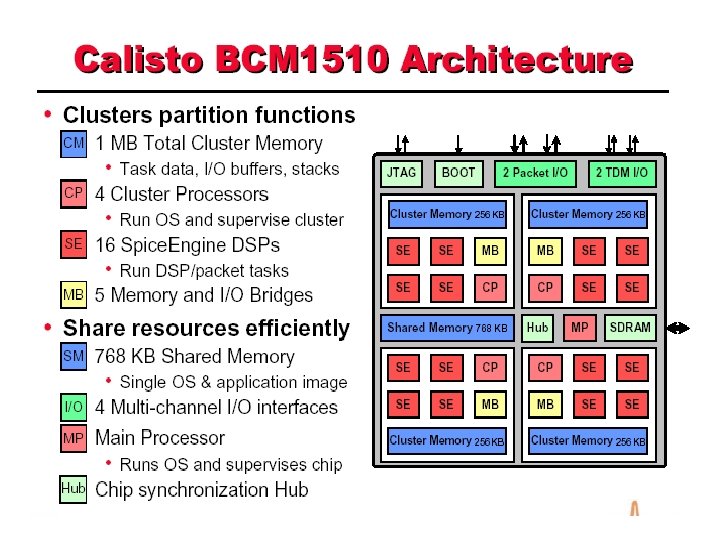
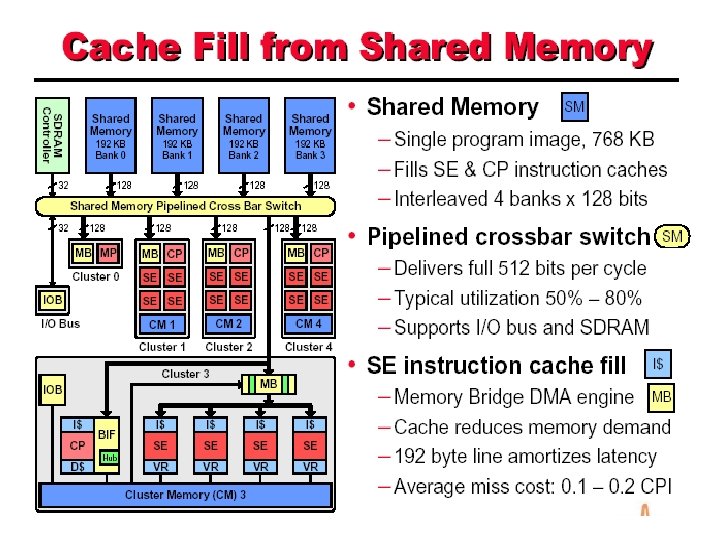
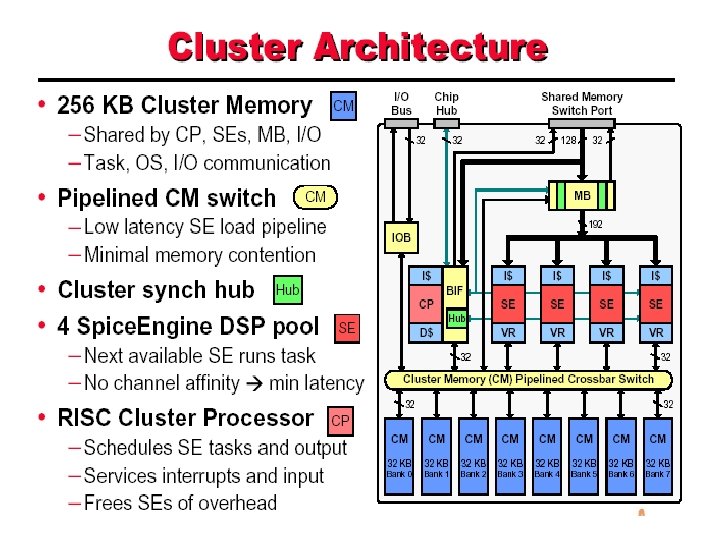
Callisto • Previously networking gateways – Handle diverse set of services – Handles 1000 s of channels – Complex designs involving many chips – High power requirement • Callisto is a gateway on a chip – Used to implement communication gateways for different networks

In a nutshell • Integrates DSPs, CPUs, RAM, IO channels on chip • Programmable multi-service platform • Handles 60 to 240 channels per chip • An array of Callisto chips can fit in a small space – Power efficient – Handles a large number of channels



- Slides: 30