Cache Coherence Protocols in Multicore Architectures Supervised by

Cache Coherence Protocols in Multicore Architectures Supervised by: Professor Gita Alaghband Shahab Helmi Anh Nguyen K. Harish Kodali Phuc Nguyen

Feel Free To Ask Questions Introduction Snooping Directory Conclusion

Outline Introduction Snooping Directory Conclusion

Cache Coherence Memory Cache 1 Cache 2 Cache 3 Cache 4 1 A 3 C 1 A 2 B 4 D 3 C 2 B 3 C 5 E 4 D 5 E Memory Cache 1 Cache 2 Cache 3 Cache 4 1 A 3 C 1 A 2 B 4 D 3 F 2 B 3 C 5 E 4 D 5 E Introduction Snooping Directory Conclusion

Cache Coherence Memory Cache 1 Cache 2 Cache 3 Cache 4 1 A 3 C 1 A 2 B 4 D 3 C 2 B 3 C 5 E 4 D 5 E Memory Cache 1 Cache 2 Cache 3 Cache 4 1 A 3 C 1 A 2 B 4 D 3 F 2 B 3 F 3 C 5 E 4 D 5 E Introduction Snooping Directory Conclusion

The Baseline System Core Cache Controller issued coherence requests & responses received coherence requests & responses Memory Controller issued coherence requests & responses Interconnection Network Memory loaded values Cache loads & stores received coherence requests & responses Interconnection Network The goal of a coherence protocol is to maintain coherence by enforcing the SWMR invariant: Single-Writer, Multiple-Read (SWMR) invariant: For any memory location “A”, at any given time, there exist only one core that may write to A or some number of cores that may read it. Introduction Snooping Directory Conclusion

Cache/Memory Controllers Core They are finite states machines to implement the SWMR invariant. Each coherence controller implements a set of finite state machines per block. In the core side: Interfaces to the processor core. Receives load and store from the core and returns values to the core. Cache Controller Interconnection Network In the network side: Interfaces to rest of the system using the interconnection network. If a cache miss occurs, issues a coherence request to get for that block. Could either receive data in response of its request or receives coherence requests from the network. Memory Controller Similar to cache controller but only has the network side. Introduction Snooping Directory Conclusion Interconnection Network Memory

States The state of a cache block contains of 4 main elements: A valid block has the most up-to-date value for this block. A valid block could be read, but written if it is also exclusive. a cache block is dirty if its value is the most up-to-date value, and this value differs from the value in the memory. a cache block is exclusive if it is the only copy of this block among all caches. a cache controller (or memory controller) is the owner of a block if it is responsible to for responding to coherence requests for that block. An owned block cannot be evicted without giving the ownership to another block. In most protocols, there is exactly one owner for each block. Introduction Snooping Directory Conclusion

Stable States Stable states: most protocols use a subset of the classic five state MOESI model (pounced MO-Zee). Each state has different combination of elements, described in the previous slide. valid, exclusive, owned, and potentially dirty. May be read or written. The only valid copy of this block. Should respond the requests for this block. The memory copy of this block is potentially stale. Valid, not exclusive, not dirty, and not owned. The cache has a readonly copy of this block. Other caches might have valid, read-only copies of the block is invalid. The cache either does not contain the block or have a stale version of it. It may not be read or written. the block is valid, owned and potentially dirty but not exclusive. The cache has a read-only copy of this block and should respond to the requests for this block. The memory copy is potentially stale. valid, exclusive, and not dirty. The cache has a read-only copy of this block. The memory copy of this block is up-to-date. Introduction Snooping Directory Conclusion

Transient States Transient states occur during the transition from one stable state to another one. XYz: the block is transition from stable state X to stable state Y and the transition will not be complete until an event of type Z occurs. IMD: denotes that a block was in the I state and will become in the M state when data (D) is received. Introduction Snooping Directory Conclusion

States of Blocks in the Memory There are 2 general approaches to naming states of blocks in the memory. The choice of the naming does not affect the functionality or performance. the state of block in the memory is an aggregation of the block in the caches. For example, if a block in all caches is in state I, the memory state for this block is I. If one or more copies are in S, then the block in S in memory. If block in one cache is in state M, it is in M in memory. the state of the block corresponds to the memory controller's permission to this block. For example, if all if a block in all caches is in I, the memory state for it will be O because the memory will behave like its owner. If they are all in S the memory state will be O. If the block is in M or O in one cache, then its memory state will be I since the memory has the invalid copy. Introduction Snooping Directory Conclusion

Maintaining the Block State To maintain the state of blocks in caches, the most common way is to add some extra bit at the end of each block. For example, in MOSEI we need 3 bits to show the state. To maintain the state of blocks in memory, we can use the same approach. Alternatively, we can use logical gates. For example we can use an NOR gate and if one of its inputs are OWNED = 1, the state of the block in memory would be I = 0. Block Data State 10011……. 000 -> I 11111……. 001 -> O 00000……. 101 -> M Block state in cache 1 State of block in memory Block state in cache 2 Block state in cache 3 Introduction Snooping Directory Conclusion

Transactions Most protocols have a similar set of transactions, because the basic goals of the coherence controllers are similar. Transactions are all initiated by cache controllers that are responding to requests from their associated cores Transaction Goal Get. Shared (Get. S) Obtain block in Shared (read-only) state. Get. Modified (Get. M) Obtain block in Modified (read-write) state. Upgrade (Upg) Upgrade block state from read-only (Shared or Owned) to read-write (Modified); Upg (unlike Get. M) does not require data to be sent to requestor. Put. Shared (Put. S) Evict block in Shared state. Put. Exclusive (Put. E) Evict block in Exclusive state. Put. Owned (Put. O) Evict block in Owned state. Put. Modified (Put. M) Evict block in Modified state. Introduction Snooping Directory Conclusion

Events are core requests to their cache controllers. Event Response of Cache Controller Load if cache hit, respond with data from cache; else initiate Get. S transaction Store if cache hit in state E or M, write data into cache; else initiate Get. M or Upg transaction Atomic read-modify-write if cache hit in state E or M, atomically execute readmodify-write semantics; else initiate Get. M or Upg transaction Instruction fetch if cache hit (in I-cache), respond with instruction from cache; else initiate Get. S transaction Read-only prefetch if cache hit, ignore; else may optionally initiate Get. S transaction Read-write prefetch If cache hit in state M, ignore; else may optionally initiate Get. M or Upg transaction Replacement depending on state of block, initiate Put. S, Put. E, Put. O, or Put. M transaction Introduction Snooping Directory Conclusion

Invalidate vs. Update The other major design decision in a coherence protocol is to decide what to do when a core writes to a block. There are two options: when a core wishes to write to a block, it initiates a coherence transaction to invalidate the copies in all other caches. Thus; if other cores want to read this block, they need to issue a new request to obtain a new copy of this block. when a core wishes to write a block, it initiates a coherence transaction to update the copies in all other caches to reflect the new value it wrote to the block. Update protocols reduce the reading latency. They use more bandwidth since their messages are bigger (carry data as well). Introduction Snooping Directory Conclusion

Cache Coherence Protocols Introduction Snooping Directory Conclusion
 coherence requests in the same order. By")
Snooping Protocols all coherence controllers observe (snoop) coherence requests in the same order. By requiring that all requests to a given block arrive in order, a snooping system enables the distributed coherence controllers to correctly update the finite state machines that collectively represent a cache block’s state. Snooping protocols broadcast requests to all coherence controllers, including the controller that initiated the request. The coherence requests typically travel on an ordered broadcast network, such as a bus. Time C 1 C 2 Memory 0 A: I, Owner 1 A: Get. M from C 1 /M, Owner A: Get. M from C 1/I Get. M from C 1/ M 2 A: Get. M from C 2 /I A: Get. M from C 2/M, Owner Get. M from C 2/ M C 1 C 2 Memory 0 A: I, Owner 1 A: Get. M from C 1 /M, Owner A: Get. M from C 2/M, Owner Get. M from C 1/ M 2 A: Get. M from C 2 /I A: Get. M from C 1/I Get. M from C 2/ M Time Introduction Snooping Directory Conclusion
 cache Cache controller Private")
The baseline System core Cache controller core Private data (LI) cache Cache controller Private data (LI) cache Interconnection network LLC/direct ory controller Last-level cache (LLC) MULTICORE PROCESSOR CHIP MAIN MEMORY Introduction Snooping Directory Conclusion

MSI Implements 2 atomicity properties. states that a coherence request is ordered in the same cycle that it is issued. states that coherence transactions are atomic in that a subsequent request for the same block may not appear on the bus until after the first transaction completes (i. e. , until after the response has appeared on the bus). Introduction Snooping Directory Conclusion

MSI, Cache Controller S t a t e Core Events Bus Event Other Cores Transactions Own Transaction Load Store I Get. S/ISD ISD stall load stall store IMD stall load S Replacemen t data Get. S Get. M Put. M stall evict copy data into cache, load hit/S (A) (A) stall store stall evict copy data into cache, store hit/M (A) (A) load hit Get. M/SMD -/I SMD load hit stall store stall evict M load hit store hit Put. M, Send data to memory /I Introduction Snooping Get. S Get. M Put. M -/I copy data into cache, load hit/S Directory Conclusion (A) send data to req and memory/S send data to req/I (A)

MSI, Memory Controller state Bus Events Get. S Get. M Ior. S Send data block to requestor/M Ior. SD (A) M -/Ior. SD Introduction Put. M Update data block in memory/Ior. S -/Ior. SD Snooping Directory Data from Owner Conclusion

MSI, Advantages/Disadvantages Small table and few possible states. Easy to understand implement Multiple copy of a same block could be available because of the shared state. Many impossible states due to atomic transaction property and many stalls Lower throughput Higher latency Unnecessary broadcast of invalidate messages: when a core wants to write on block should get the block in the stat M and send an invalidate message to all other cores, no matter if it is the only copy of that block or not. Tradeoffs: downgrade from M to S or I? We need to predict if block is going to be used again or not. Introduction Snooping Directory Conclusion

MESI Implements atomic transactions and non-atomic request properties. The Exclusive state is used in almost all commercial coherence protocols because it optimizes a common case: a core first reads a block and then subsequently writes it. In MSI, a core needs to issue a Get. S message to get the read permission (in case a cache miss) and then have to issue a Get. M message to get the write permission. In MESI, a core can get the block in the exclusive state and no other block can access it anymore. Thus, the core does not need to issue a Get. M message. Introduction Snooping Directory Conclusion

MESI, Cache Controller Load Store Repl. I Get. S/ ISAD Get. M/ IMAD ISAD stall ISD stall IMAD stall IMD stall S hit SMAD Get. S Get. M Put. M - - - (A) (A) - - - stall (A) (A) Get. M/ SMAD -/I - hit stall - -/IMAD - SMD hit stall (A) (A) E hit/M Put. M/ EIA data to R & M/S data to R/I - M hit Put. M/ MIA data to R & M/S data to R/I - MIA hit stall data to M/I data to M & R/IIA data to R/IIA - EIA hit stall -/I data to M & R/IIA data to R/IIA - IIA stall -/I - - - Introduction Snooping -/ISD -/IMD -/SMD Directory Conclusion Data -/S -/M Data -/E

MESI, Memory Controller Get. S Get. M Put. M I data to R/Eor. M -/ID S data to R/Eor. M -/SD - -/Eor. MD ID (A) SD (A) Eor. MD (A) Introduction Data No. Data-E (A) write data to M/I -/I (A) write data to M/S -/S (A) write data to M/I -/Eor. M -/I Snooping Directory Conclusion

MESI, Advantages/Disadvantages Silent transition from the exclusive state to the modified/shared state. No unnecessary invalidate messages are issued. Read and write with issuing only request. Fewer number of messages. Less traffic on the bus, lower bandwidth usage. Extra hardware is needed to implement the exclusive state. Introduction Snooping Directory Conclusion
 When a cache has a block in state M or")
MOSI Snooping Protocol (1/7) When a cache has a block in state M or E and receives a Get. S from another core, if using the MSI protocol or the MESI protocol, the cache must change the block state from M or E to S send the data to both the requestor and the memory controller Questions raise that how a snooping protocol can minimize accesses to memory or eliminate 1. the extra data message to update the LLC/memory when a cache receives a Get. S request in the M (and E) state? 2. the potentially unnecessary write to the LLC? Augmenting the baseline state Introduction Snooping odified hared Directory nvalid protocol with the O(wned) Conclusion
 The key difference is what happens when a cache with")
MOSI Snooping Protocol (2/7) The key difference is what happens when a cache with a block in state M receives a Get. S from another core. In a MOSI protocol, the cache changes the block state to O (instead of S) and retains ownership of the block (instead of transferring ownership to the LLC/memory) The O state enables the cache to avoid updating the LLC/memory. The protocol adds two transient cache states in addition to the stable O state The transient OIA state helps handle replacements of blocks in the O The transient OMA state handles upgrades back to state M after a store Introduction Snooping Directory Conclusion
 States Processor Core Events load store issue Get. S/ISAD issue")
MOSI Snooping Protocol (3/7) States Processor Core Events load store issue Get. S/ISAD issue Get. M/IMAD ISAD stall ISD stall IMAD stall IMD stall S hit SMAD I Introduction Snooping replacement Bus Events Own. Get. S Own. Get. M Own. Put. M Other. Get. S Other. Get. M Other. Put. M - - - (A) (A) - - - stall (A) (A) issue Get. M/SMAD -/I - hit stall SMD hit stall (A) (A) O hit issue Get. M/OMA issue Put. M/OIA send data to requestor/I - OMA hit stall send data to requestor/IM - M hit issue Put. M/MIA send data to requestor/O send data to requestor/I - MIA hit stall send data to memory/I send data to requestor/OI A send data to requestor/II A - OIA hit stall send data to memory/I send data to requestor/IIA - IIA stall send No. Data to memory/I - - - Directory Conclusion -/ISD -/IMD -/SMD - -/M Own Data response -/S -/M - AD -/M
 States Bus Events Get. S Get. M Ior. S send")
MOSI Snooping Protocol (4/7) States Bus Events Get. S Get. M Ior. S send data to requestor/Mor. O Ior. SD (A) Mor. O - - Mor. OD (A) Introduction Snooping Put. M Data from Owner No. Data -/Ior. SD write data to memory/Ior. S -/Ior. S write data to memory/Ior. S -/Mor. OD Directory Conclusion
 MSI MOSI # Messages 6 13 # Stalls 20 24")
MOSI Snooping Protocol (5/7) MSI MOSI # Messages 6 13 # Stalls 20 24 MSI MOSI # Messages 2 2 # Stalls 0 0 Introduction Snooping Directory Conclusion
 Cycle 1: Core 2 Core 1 Cache Controller Cache issue")
MOSI Snooping Protocol (6/7) Cycle 1: Core 2 Core 1 Cache Controller Cache issue Get. S / ISAD BUS Introduction Snooping Directory Memory Controller Conclusion Cache Controller
 Cycle 2: Core 2 Core 1 Cache Controller BUS Introduction")
MOSI Snooping Protocol (6/7) Cycle 2: Core 2 Core 1 Cache Controller BUS Introduction Snooping Directory Memory Controller Conclusion Cache Controller issue Get. M / IMAD
 Cycle 3: Core 2 Core 1 Cache Controller request on")
MOSI Snooping Protocol (6/7) Cycle 3: Core 2 Core 1 Cache Controller request on BUS - Get. S (C 1) Introduction Snooping Directory Memory Controller Conclusion Cache Controller
 Cycle 4: Core 2 Core 1 Cache Controller Cache -")
MOSI Snooping Protocol (6/7) Cycle 4: Core 2 Core 1 Cache Controller Cache - / ISD BUS Introduction Memory Controller Snooping Directory Memory send data to C 1 / Ior. S Conclusion Cache Controller
 Cycle 5: Core 2 Core 1 Cache Controller data on")
MOSI Snooping Protocol (6/7) Cycle 5: Core 2 Core 1 Cache Controller data on BUS – data from LLC/mem Introduction Snooping Directory Memory Controller Conclusion
 Cycle 6: Core 2 Core 1 Cache Controller Cache copy")
MOSI Snooping Protocol (6/7) Cycle 6: Core 2 Core 1 Cache Controller Cache copy data from LLC/mem / S request on BUS – Get. M (C 2) Introduction Snooping Directory Memory Controller Conclusion Cache Controller
 Cycle 7: Core 2 Core 1 Cache Controller Cache -/I")
MOSI Snooping Protocol (6/7) Cycle 7: Core 2 Core 1 Cache Controller Cache -/I BUS Introduction Memory Controller Snooping Directory Memory send data to C 2 / Mor. O Conclusion Cache Controller - / IMD
 Cycle 8: Core 2 Core 1 Cache Controller data on")
MOSI Snooping Protocol (6/7) Cycle 8: Core 2 Core 1 Cache Controller data on BUS – data from LLC/mem Introduction Snooping Directory Memory Controller Conclusion
 Cycle 9: Core 2 Core 1 Cache Controller BUS Introduction")
MOSI Snooping Protocol (6/7) Cycle 9: Core 2 Core 1 Cache Controller BUS Introduction Snooping Directory Memory Controller Conclusion Cache Controller copy data from LLC/mem / M
 Cycle 10: Core 2 Core 1 Cache Controller Cache issue")
MOSI Snooping Protocol (6/7) Cycle 10: Core 2 Core 1 Cache Controller Cache issue Get. S / ISAD BUS Introduction Snooping Directory Memory Controller Conclusion Cache Controller
 Cycle 11: Core 2 Core 1 Cache Controller request on")
MOSI Snooping Protocol (6/7) Cycle 11: Core 2 Core 1 Cache Controller request on BUS - Get. S (C 1) Introduction Snooping Directory Memory Controller Conclusion Cache Controller
 Cycle 12: Core 2 Core 1 Cache Controller Cache -")
MOSI Snooping Protocol (6/7) Cycle 12: Core 2 Core 1 Cache Controller Cache - / ISD BUS Introduction Memory Controller Snooping Directory Memory - / Mor. O Conclusion Cache Controller send data to C 1 / O
 Cycle 13: Core 2 Core 1 Cache Controller data on")
MOSI Snooping Protocol (6/7) Cycle 13: Core 2 Core 1 Cache Controller data on BUS – data from C 2 Introduction Snooping Directory Memory Controller Conclusion Cache Controller
 Cycle 14: Core 2 Core 1 Cache Controller Cache copy")
MOSI Snooping Protocol (6/7) Cycle 14: Core 2 Core 1 Cache Controller Cache copy data from C 2 / S BUS Introduction Snooping Directory Memory Controller Conclusion Cache Controller
 The Owner state of a cache block supplies the data")
MOSI Snooping Protocol (7/7) The Owner state of a cache block supplies the data to another processor instead of having that processor read the data from memory. reduces the number of write backs to main memory runs with medium complexity When going from a Shared state to a Modified state, the block must pass through the Invalid state. Introduction Snooping Directory Conclusion
 Atomic Bus Address Bus Request 1 Data Bus Request 2 Response")
Snooping Advances (1/3) Atomic Bus Address Bus Request 1 Data Bus Request 2 Response 1 Request 3 Response 2 Response 3 To implement atomic transactions, the simplest way is to use a shared-wire bus with an atomic bus protocol – all bus transactions of an indivisible request-respond pair unpipelined processor core no way to overlap activities that could proceed in parallel Be simple but sacrifice performance Limited by the sum of the latencies for a request and response (including any wait cycles between them) Introduction Snooping Directory Conclusion
 Pipelined (non-atomic) Bus provides responses in the same order as the")
Snooping Advances (2/3) Pipelined (non-atomic) Bus provides responses in the same order as the requests. Address Bus Request 1 Request 2 Request 3 Data Bus Response 1 Response 2 Response 3 Split Transaction (non-atomic) Bus provides responses in an order different from the request order. Address Bus Request 1 Request 2 Request 3 Data Bus Introduction Response 2 Snooping Directory Response 3 Conclusion Response 1
 Key advantage of a non-atomic bus: “NOT having to wait for")
Snooping Advances (3/3) Key advantage of a non-atomic bus: “NOT having to wait for a response before a subsequent request can be serialized on the bus” The bus can achieve much higher bandwidth using the same set of shared wire. The advantage of a split-transaction bus, with respect to a pipelined bus, is that “A low-latency response does not have to wait for a long-latency response to a prior request” One issue raised by a split-transaction bus is matching responses with requests. The response must carry the identity of the request or the requestor. Introduction Snooping Directory Conclusion
 FIFO queues for buffering incoming & outgoing")
MSI Protocol with a Split-Transaction Bus (1/5) FIFO queues for buffering incoming & outgoing messages Memory controller does not have a connection to make requests Introduction Snooping Directory Conclusion
 States Processor Core Events load store issue")
MSI Protocol with a Split-Transaction Bus (2/5) States Processor Core Events load store issue Get. S/ISAD issue Get. M/IMAD ISAD stall stall ISA stall IMAD stall stall IMA stall S hit issue Get. M/SMAD -/I SMAD hit stall istall SMD hit stall SMA hit stall M hit issue Put. M/MIA hit stall IIA stall I Introduction replacement Snooping Bus Events Own. Get. S or Own. Get. M Own. Put. M Other. Get. M Other. Put. M Own Data response (for own request) - - - - stall - -/IMAD -/SMA stall store hit/M - -/IMA send data to requestor and to memory/S send data to requestor/I send data to requestor and to memory/IIA send data to requestor/IIA -/I - - -/ISD load hit/S -/IMD store hit/M -/SMD store hit/M Directory Other. Get. S Conclusion -/-/ISA load hit/S - -/IMA store hit/M -
 States Processor Core Events load store issue")
MSI Protocol with a Split-Transaction Bus (2/5) States Processor Core Events load store issue Get. S/ISAD issue Get. M/IMAD ISAD stall stall ISA stall IMAD stall stall IMA stall S hit issue Get. M/SMAD -/I SMAD hit stall istall SMD hit stall SMA hit stall M hit issue Put. M/MIA hit stall IIA stall I It now can receive an Other-Get. S Bus Events Introduction Snooping replacement Own. Get. S or Own. Get. M Own. Put. M Other. Get. M Other. Put. M Own Data response (for own request) - - - - stall - -/IMAD -/SMA stall store hit/M - -/IMA send data to requestor and to memory/S send data to requestor/I send data to requestor and to memory/IIA send data to requestor/IIA -/I - - -/ISD load hit/S -/IMD store hit/M -/SMD store hit/M Directory Other. Get. S Conclusion -/-/ISA load hit/S - -/IMA store hit/M -
 States Bus Events Get. S Ior. S")
MSI Protocol with a Split-Transaction Bus (3/5) States Bus Events Get. S Ior. S send data to requestor, set Owner to requestor/M clear Owner/Ior. SD set Owner to requestor clear Owner/Ior. SD - write data to memory/Ior. S A Ior. SD stall - write data to memory/Ior. SA clear Owner/Ior. S - M Introduction Get. M Snooping Put. M from Owner Put. M from Non-Owner Data - Directory Conclusion
 MSI with Split-Transaction Bus # Messages 6")
MSI Protocol with a Split-Transaction Bus (4/5) MSI with Split-Transaction Bus # Messages 6 5 # Stalls 20 33 MSI with Split-Transaction Bus # Messages 2 2 # Stalls 0 3 Introduction Snooping Directory Conclusion
 (until data arrives to satisfy the in-flight")
MSI Protocol with a Split-Transaction Bus (5/5) (until data arrives to satisfy the in-flight request) 1. It sacrifices performance. 2. Stalling raises the potential of deadlock (because of circular chains of stalls). 3. It enables a requestor to observe a response to its request before processing its own request. Introduction Snooping Directory Conclusion
 By stalling a request, the protocol stalls all")
An Optimized, Non-stalling MSI Protocol (1/3) By stalling a request, the protocol stalls all requests after the stalled request and delays those transactions from completing. How a coherence controller processes requests behind the stalled one? Process all messages, in order, instead of stalling Add transient states that reflect messages that the coherence controller has received but must remember to complete at a later event. For example, A cache with a block in state ISD stalled instead of processing an Other-Get. M for that block. In this case, if the cache controller observes an Other-Get. M on the bus, then it changes the block state to ISDI “in I, going to S, waiting for data, and when data arrives will go to I” Introduction Snooping Directory Conclusion
 States Processor Core Events store replacement issue Get.")
An Optimized, Non-stalling MSI Protocol (2/3) States Processor Core Events store replacement issue Get. S/ISAD issue Get. M/IMAD ISAD stall stall ISA stall ISDI stall IMAD stall stall IMA stall IMDI stall IMDSI I load Bus Events Own. Get. S or Own. Get. M Own. Put. M Other. Get. S Other. Get. M Other. Put. M Own Data response (for own request) - - - -/ISDI - - - -/IMDS -/IMDI - - stall - - store hit, send data to Get. M requestor/I stall - -/IMDSI store hit, send data to Get. M requestor and mem/S stall - store hit, send data to Get. M requestor and mem/I S hit issue Get. M/SMAD -/I SMAD hit stall istall SMD hit stall SMA hit stall SMDI hit stall SMDS hit SMDSI -/ISD load hit/S -/IMD store hit/M -/ISA load hit/S load hit/I - -/IMA store hit/M - -/IMAD -/SMA -/SMDS -/SMDI store hit/M - -/IMA stall - - store hit, send data to Get. M requestor/I stall - -/SMDSI store hit, send data to Get. M requestor and mem/S hit stall - - store hit, send data to Get. M requestor and mem/I M hit issue Put. M/MIA send data to requestor and to memory/S send data to requestor/I MIA hit stall send data to requestor/I send data to requestor and to memory/II A send data to requestor/II A IIA stall -/I - - -/SMD store hit/M -
 States Bus Events Get. S Ior. S send")
An Optimized, Non-stalling MSI Protocol (3/3) States Bus Events Get. S Ior. S send data to requestor, set Owner to requestor/M clear Owner/Ior. SD set Owner to requestor clear Owner/Ior. SD - write data to memory/Ior. SA Ior. SD stall - write data to memory/Ior. SA clear Owner/Ior. S - M Introduction Get. M Snooping Put. M from Owner Put. M from Non-Owner Data - Directory Conclusion

Case Study: Sun Starfire E 10000 Uses MOESI Non-atomic requests and transactions. Supports up to 64 bit processors. Wired snooping busses consume lots of energy; thus, they do not scale up to large number of cores. To solve this problem. E 10000 uses point-to-point links instead. Uses a separate bus for sending out-of-order data response messages. Introduction Snooping Directory Conclusion
: implements 8 applications: LU: dense matrix manipulation. OCEAN: large-scale movements. Cholesky:")
Evaluation SPLASH-2 (2007): implements 8 applications: LU: dense matrix manipulation. OCEAN: large-scale movements. Cholesky: sparse matrix manipulation. Radix: sorting radix-based integers … SPECjbb: benchmark for computing the performance of java servers, applications … PARSEC: benchmark for shared memory, multithreaded programs. Processor utilization Bus utilization Number of accesses to physical memory Introduction Snooping Directory Conclusion

Evaluation, Effects of Cache Size Benchmark suite: Splash-2 Benchmark application: Gem 5, SE mode Hardware: four CPUs. Each CPU has private L 1 cache of 32 KB with associativity 4. Default cache line size is 64 bytes which we configure for our experiment. L 1 Cache Size (KB) Write-Back /Memory References 16 17300 32 12672 64 5251 128 0 15000 10000 5000 0 16 32 64 128 Write backs 20000 Snooping Write-Back/ Memory References 16 11214 32 12350 64 12672 128 13001 14000 13000 12000 110000 16 L 1 cash size (KB) Introduction L 1 Block Size (bytes) 32 64 L 1 block size (bytes) Directory Conclusion 128

Evaluations, # of Cores, Energy Consumption Benchmark suite: SPEC Benchmark applications: blackscholes, bodytrack, fluidanimate, freqmine, raytrace, and swaptions. canneal, facesim, Protocols: MESI, MOSI, and MOESI (compared to MSI). Across all the benchmarks and input sizes, MESI and MOESI reduce the number of broadcasts 7% on average. MOSI and MOESI, reduce the number of write-backs is reduced by 5% on average. Introduction Snooping Directory Conclusion
 Since MOSI and MOESI substantially reduce the")
Evaluation, # of Cores, Energy Consumption (cont’d) Since MOSI and MOESI substantially reduce the number of write-backs for workloads, they reduce the energy consumption of the LLC by %4 on average. MOSI and MOESI are only showing very little increasing benefits with regard to write-back traffic reduction compared to MSI and MESI. Introduction Snooping Directory Conclusion

Evaluations, Bus Traffic Benchmark suite: Splash-2 Benchmark applications: Barnes-Hut, LU, OCEAN, Radiosity, Radix, Ray Trace Protocols: MESI and MSI Hardware: ? Introduction Snooping Directory Conclusion

Evaluations, # of Invalidate Messages Protocols: MSI and MESI, MOESI Hardware Splash-2 inputs and applications Introduction Snooping Directory Conclusion

Motivation Directory protocols were originally developed to address the lack of scalability of snooping protocols. Directory protocols is to avoid the broad cast nature of snooping. Snooping systems broadcast all requests on a totally ordered interconnection network and all requests are snooped by all coherence controllers. But the, directory protocols uses indirection to avoid both the ordered broadcast network and having each cache controller process every request. Directory based protocols should be competitive with snoopy protocols
 cache Cache controller Private data (LI) cache")
core Cache controller core Private data (LI) cache Cache controller Private data (LI) cache Interconnection network LLC/direct ory controller MAIN MEMORY Last-level cache (LLC) directory MULTICORE PROCESSOR CHIP

Protocol Ordered network Advantages disadvantages Snooping protocol Yes Simple Difficult to scale Directory based protocol No Scalable Indirection, extra hardware

A directory in the directory system model maintains a global view of the coherence state of each block. Keeps track of copies of cached blocks and their states. Every block has associated directory information. Every request goes to directory and the directory then sends directives to each cache. One restriction on the interconnection network that is that it enforces pointto-point ordering. That is, if controller A sends two messages to controller B, then the messages arrive at controller B in the same order in which they were sent.

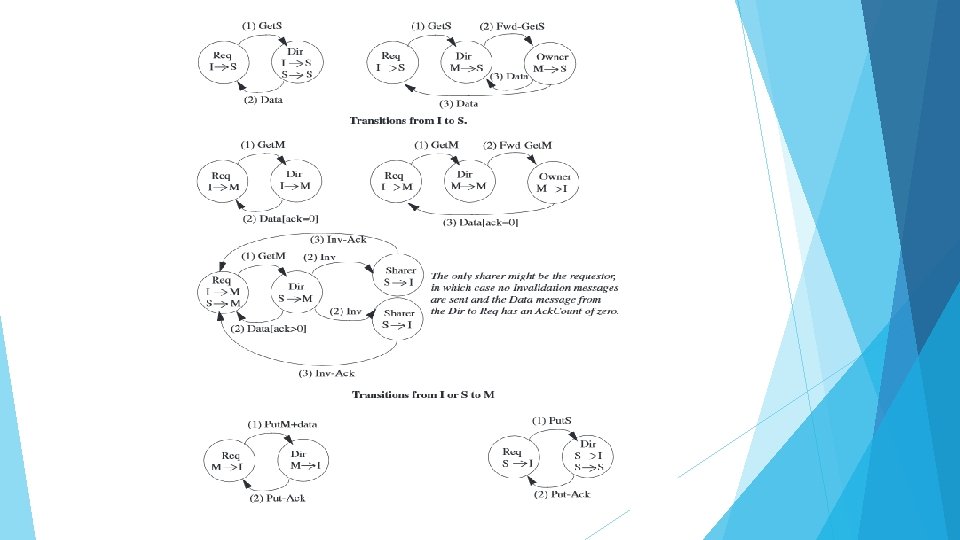
High-Level Protocol Specification: In Figure, we show the transactions in which a cache controller issues coherence requests to change permissions from I to S, I or S to M, M to I, and S to I. Cache sends request to Get. M to the directory, and the directory takes two actions. First, it responds to the requestor with a message that includes the data and the Ack. Count. It is the number of current sharers of the block. Second, the directory sends an Invalidation message to all of the current sharers. Each sharer, upon receiving the Invalidation, sends an Invalidation-Ack to the requestor. Put. M message that includes the data to the directory. The directory responds with a Put-Ack. If the Put. M did not carry the data with it, then the protocol would require a third message—a data message from the cache controller to the directory with the evicted block that had been in state M—to be sent in a Put. M transaction.

MSI Directory Protocol – Cache Controller

MSI Directory Protocol – Directory Controller
 The cache controller sends a Get.")
Protocol Operations I to S (common case #1) The cache controller sends a Get. S request to the directory and changes the block state from I to ISD. The directory receives this request and, if the directory is the owner (i. e. , no cache currently hast he block in M), the directory responds with a Data message, changes the block’s state to S (if it is not S already), and adds the requestor to the sharer list. When the Data arrives at the requestor, the cache controller changes the block’s state to S, completing the transaction. I to S (common case #2) The cache controller sends a Get. S request to the directory and changes the block state from I to ISD. If the directory is not the owner (i. e. , there is a cache that currently has the block in M), the directory forwards the request to the owner and changes the block’s state to the transient state SD. The owner responds to this Fwd-Get. S message by sending Data to the requestor and changing the block’s state to S. The now-previous owner must also send Data to the directory since it is relinquishing ownership to the directory, which must have an up-to-date copy of the block. When the Data arrives at the requestor, the cache controller changes the block state to S and considers the transaction complete. When the Data arrives at the directory, the directory copies it to memory, changes the block state to S, and considers the transaction complete.

Adding Exclusive state:

MESI Directory Protocol – Cache Controller

MESI Directory Protocol – Directory Controller

Assumptions Consider a complete directory maintaining complete state of each block, including the full set of caches that may have shared copies Point-to-point ordering for the Forwarded Request network

Adding the owned state Recall: if a cache has a block in the Owned state, then the block is valid, read-only, dirty (i. e. , it must eventually update memory), and owned (i. e. , the cache must respond to coherence requests for the block) Adding Owned State changes the protocols (compare with MSI) in three important ways: 1. More coherence requests are satisfied by caches (in O state) than by the LLC/mem 2. There are more 3 -hop transactions
 Fwd-Get.")
If directory is the owner If directory is not the owner (2) Fwd-Get. S (1) Get. S Req I S S S Req I S Dir M O O O Req I S Owner M O O O I ISD S send Get. S to Dir/ISD Last-Inv. Ack Inv-Ack Ack. Count from Dir Data from Owner (ack >0) Data form Dir (ack =0) Put-Ack Inv Fwd-get. M Fwd-Get. S replaceme nt store load MOSI Directory Protocol – Cache Controller
 Get.")
If directory is the owner If directory is not the owner (1) Get. S Req I S S S (2) Fwd-Get. S Dir M O O O Req I S Owner M O O O send Get. S to Dir/ISD Stall S Stall -/S Last-Inv. Ack Inv-Ack Ack. Count from Dir Data from Owner (ack >0) Data form Dir (ack =0) Put-Ack Inv Stall Fwd-get. M Stall Fwd-Get. S replacement I store load MOSI Directory Protocol – Cache Control
 Get. S If directory is the owner Req I S S S Req")
(1) Get. S If directory is the owner Req I S S S Req I S (2) Data (2) Fwd-Get. S (1) Get. S If directory is not the owner Stall S Hit Stall -/S Last-Inv-Ack Ack. Count from Dir Data form Dir (ack =0) Put-Ack Inv Stall Fwd-get. M Stall Fwd-Get. S replacement ISD Store Send Get. S to Dir/ISD Data from Owner (ack >0) (3) Data ISD: I -> S, waits for D I Owner M O O O Dir M O O O Req I S load
 Get. M Req I S S M Req I M Sharer S I")
(1) Get. M Req I S S M Req I M Sharer S I Dir S M Sharer S I I IMAD IMA S SMAD SMA M Send Get. M to Dir/IMAD Last-Inv. Ack Inv-Ack Ack. Count from Dir Data from Owner (ack >0) Data form Dir (ack =0) Put-Ack Inv Fwd-get. M Fwd-Get. S replacement Store load • IMAD: the cache wants I -> M, waits for D + possibly Ack • The cache know how many ack it expects to receive
 Get. M Req I S S M Req I M Sharer S I")
(1) Get. M Req I S S M Req I M Sharer S I (2) Inv Dir S M Sharer S I (2) Inv (2) Data[ack>0] Stall S Ack-- -/M -/SMA -/M Ack-- Send Inv. Ack to Req/I Send Get. M to Dir/SMAD Hit Stall SMA Hit Stall M -/M Send Get. M to Dir/IMAD Send Inv. Ack to Req/IMAD Last-Inv. Ack Stall -/IMA Inv-Ack Stall -/M Inv-Ack IMA Ack. Count from Dir Stall Data from Owner (ack >0) Stall Data form Dir (ack =0) Stall Put-Ack Fwd-get. M Stall Inv Fwd-Get. S Stall I Store IMAD load replaceme nt (2) Data [ack =0]
 Inv-Ack Req I S S M Stall Stall S Hit Send Get. M")
(3) Inv-Ack Req I S S M Stall Stall S Hit Send Get. M to Dir/SMAD send Put. S to Dir/SIA SMAD Hit Stall SMA Hit Stall M Hit Send Put. M + data to Dir/MIA Send data to Req/Q Send data to Req/I -/M -/IMA -/M Ack-- -/M -/SMA -/M Ack-- Inv-Ack IMA Ack. Count from Dir Stall (3) Inv-Ack Data from Owner (ack >0) Fwd-get. M Stall Put-Ack Fwd-Get. S Stall Inv replacement Stall Store Stall load IMAD Sharer S I (2) Inv Data form Dir (ack =0) (2) Data[ack>0] (2) Data [ack =0] I Dir S M Inv-Ack Req I M Sharer S I (2) Inv (1) Get. M Send Get. M to Dir/IMAD Send Inv. Ack to Req/IMAD -/I Last-Inv-Ack (1) Get. M
 Inv-Ack Sharer S I (2) Inv (1) Get. M Dir O M Req")
(3) Inv-Ack Sharer S I (2) Inv (1) Get. M Dir O M Req O M (2) Inv Sharer S I (2) Ack. Count Send Get. M to Dir/OMAM Send Put. O+data to Dir/OIA Send data to Req/I OMAC Hit Stall Send data to Req/IMAD OMA Hit Stall Send data to Stall Req -/OMA Ack- - Last-Inv-Ack Hit Inv-Ack O Inv-Ack Send data to Req/Q Req/I Ack. Count from Dir Send Put. M + data to Dir/MIA Data from Owner (ack >0) Hit Data form Dir (ack =0) Hit Put-Ack M Inv Fwd-get. M Store Fwd-Get. S load replacement (3) Inv-Ack -/I Ack - -/M
 Put. S Dir S I S S Fwd-get. M Send Put. M +")
(1) Put. S Dir S I S S Fwd-get. M Send Put. M + data to Dir/MIA Send data to Req/Q Send data to Req/I MIA Stall Send data to Req/OIA Send data to Req/IIA O Hit Send Get. M to Dir/OMAM Send Put. O+data to Dir/OIA Send data to Req/I OMAC Hit Stall Send data to Req/IMAD OMA Hit Stall Send data to Req Stall OIA Stall Send data to Req/IIA Stall Stall Data from Owner (ack >0) Fwd-Get. S Hit Data form Dir (ack =0) replacement Hit (2) Put-Ack Store M Inv load (2) Put-Ack Last-Inv. Ack (2) Put_ack Dir M I Req M I Inv-Ack Req S I Inv-Ack Dir O M Req O I (1) Put. M + data Ack. Count from Dir (1) Put. O + data Ack-- -/M -/I -/OMA Ack= Ack -/I Send Inv-Ack to Req/IIA -/I -/M

Stall Stall IMA Stall Stall S Hit Send Get. M to Dir/SMAD send Put. S to Dir/SIA SMAD Hit Stall SMA Hit Stall M Hit Send Put. M + data to Dir/MIA Send data to Req/Q Send data to Req/I MIA Stall Send data to Req/OIA Send data to Req/IIA O Hit Send Get. M to Dir/OMAM Send Put. O+data to Dir/OIA Send data to Req/I OMAC Hit Stall Send data to Req/IMAD OMA Hit Stall Send data to Req Stall OIA Stall Send data to Req/IIA Stall Stall -/S Last-Inv. Ack IMAD Stall Inv-Ack Stall Ack. Count from Dir Stall Data from Owner (ack >0) ISD Data form Dir (ack =0) Send Get. M to Dir/ISAD Put-Ack Send Get. S to Dir/ISD Inv Fwdget. M Fwd-Get. S Store replacem ent load I -/S -/M -/IMA -/M Ack-- -/M -/SMA -/M Ack-- Send Inv-Ack to Req/IMAD -/I -/OMA Ack= Ack -/I Send Inv-Ack to Req/IIA -/I -/M

MOSI - Directory Controller Get. S I Get. M from Owner Non. Owner: send Data Get. M from to Req, add Owner Req to Sharers/S S send Data to Req, add Req to Sharers O forward Get. S to Owner, add Req to Sharers M forward Get. S to Owner, add Req to Sharers/O send Ack. Count to Req, send Inv to Sharers, clear Sharers/M Put. S – Non. Leaf data Put. S-Last send Data to Req, set Owner to Req/M send Put-Ack to Req Send Put-Ack to Req send Data to Req, send Inv to Sharers, set Owner to Req, clear Sharers/M remove Req from Sharers, send Put. Ack to Req Remove Req from Sharers, send Put-Ack to Req/I remove Req from Sharers, send Put-Ack to Req forward Get. M to Owner, send Inv to Sharers, set Owner to Req, clear Sharers, send Ack. Count to Req/M remove Req from Sharers, send Put. Ack to Req remove Req from Sharers, send Put-Ack to Req forward Get. M to Owner, send Put-Ack set Owner to Req Put. M+data from Owner remove Req from Sharers, copy data to mem, send Put-Ack to Req, clear Owner/S send Put-Ack copy data to to Req mem, send Put. Ack to Req, clear Owne/I Put. O+data from Non. Owner remove Req from Sharers, send Put-Ack to Req Put. O + dat Send Put-Ack to Req copy data to memory, send Put-Ack to Req, clear Owner/ S remove Req from Sharers, send Put -Ack to Req remove send Put Req -Ack from to Req Sharers, send Put -Ack to Req

MOSI statistic Comparison between cache controller on MSI and MOSI Total # of messages 15 20 Total # of stalls 31 38 Comparison between memory controller on MSI and MOSI Total # of messages 19 28 Total # of stalls 2 2

Representing Directory State We have assumed a complete directory maintaining the complete state of each blocks, including the full set of caches that may have shared copies Coarse directories and limited pointers are two ways to reduce how much state directory maintains 2 -bit state C-bit log 2 C-bit owner complete sharer list (bit error) Complete directory: each bit in sharer list represents one cache C/K-bit coarse sharer list (bit error) i*log 2 C-bit pointers to I sharers Coarse directory: each bit in sharer list represents K caches Limited directory: sharer list is divided into i entries, each of which is a pointer to a cache

Multiple directories provides greater bandwidth of coherence transactions Idea: in a system with N directories, block B’s directory might be at directory B modulo N because the allocation of memory address to nodes is often static. Memory core Cache controller Cache Directory controller directory Memory core Cache controller Interconnection network Cache directory Performance and Scalability Optimization (1/4) Directory controller
 Recall: one of the limitation of directory protocols is")
Performance and Scalability Optimization (2/4) Recall: one of the limitation of directory protocols is that the stall situation happens frequently When a cache controller has a block in state IMA and receives a Fwd-Get. S, it processes the request and changes the block’s state to IMAS. This state indicates that after the cache controller’s Get. M transaction completes (i. e. , when the last Inv-Ack arrives), the cache controller will change the block state to S. the cache controller must also send the block to the requestor of the Get. S and to the directory, which is now the owner. Conclude: By not stalling on the Fwd-Get. S, the cache controller can improve performance by continuing to process other forwarded requests behind that Fwd-Get. S in its incoming queue.
 NOTE: So far, we now do not have point-to-point")
Performance and Scalability Optimization (3/4) NOTE: So far, we now do not have point-to-point ordering in interconnection network Considering MOSI situation as an example (a) Example with point-to-point ordering (b) Example without point-to-point ordering. Note that C 2’s Fwd-Get. S arrives at C 1 in state I and thus C 1 does not respond. One of the approaches is to have a customized message to take care of the situation
 Adaptive routing is the solution to enable a message")
Performance and Scalability Optimization (4/4) Adaptive routing is the solution to enable a message to dynamically choose its path as its traverses the network Congested links and switches can be avoided Moreover, point-to-point ordering problem could also be solved (a) Adaptive Routing Example

Case Studies: SGI Origin 2000 Flat memory-based directory protocol Uses a bit vector directory representation Consists 512 nodes Two processors per node, but there is no snooping protocol within a node –combining multiple processors in a node reduces cost

Case Studies: SGI Origin 2000 Distinguishing Features As its scalability, each directory entry contains fewer bits than necessary to present every possible cache that could be sharing a block. § Since network provides no ordering, there are several new messages have been used for reordering purposes § Directory dynamically choose coarse bit vector or limited pointer presentation Protocol considers all of these conditions by not enforcing ordering in the network Use only two networks request and response to avoid deadlock. Note that directory has three types of message (request, forwarded request and response)

Advantages/Disadvantages of Directory Protocols Supports scalability Able to take care of ordering messages More complicated than Snooping Has many transactions -> inefficient in time as they require an extra message when the home is not owner High storage overhead of directory data structure

Performance Evaluation Plan Benchmarks: § SPLASH-2: fft, Barnes-Hut, LU, Ocean, Radiosity, Radix, Ray Trace § SPECibb: benchmark for computing the performance of java servers, applications § PERSEC: benchmark for shared memory, multithreaded programs. Metrics § System performance (time efficiency) § Processor Utilization (time spent waiting for memory) § Directory utilization § Number of access to physical mem § Power consumption (difficult)

Evaluation, Effects of Cache Size Benchmark suite: Splash-2 Benchmark application: Gem 5, SE mode Hardware: Hydra (UCDenver) Example results: L 1 Cache Size (KB) Write-Back /Memory References 16 17300 32 12672 64 5251 128 0 black -0. 5 -1 Red Write backs 0 L 1 Block Size (bytes) Write-Back/ Memory References 16 11214 32 12350 64 12672 128 13001 14000 13000 12000 110000 16 32 64 L 1 block size (bytes) L 1 cash size (KB) 128

Evaluations, # of Cores, Energy Consumption Benchmark suite: SPEC Benchmark applications: blackscholes, bodytrack, fluidanimate, freqmine, raytrace, and swaptions. canneal, Protocols: MESI, MOSI, and MOESI (compared to MSI). Calculate the number of message exchange between entities Analysis the results obtained facesim,
 LLC power consumption Sincerity to the number")
Evaluation, # of Cores, Energy Consumption (cont’d) LLC power consumption Sincerity to the number of cores Example results:
![References [1] – Daniel J. S. , Mark D. H. , and David A.](http://slidetodoc.com/presentation_image_h/8447f7f724cfc12dd27d692fe5f693a4/image-103.jpg "References [1] – Daniel J. S. , Mark D. H. , and David A.")
References [1] – Daniel J. S. , Mark D. H. , and David A. W. , “A Primer on Memory Consistency and Cache Coherence, ” Morgan Claypool Publishers, 2011. [2] – Linda Suleman, Bigelow Veynu, and Narasiman Aater, “An Evaluation of Snoop-Based Cache Coherence Protocols, ” [3] – Anoop Tiwari, “Performance comparison of cache coherence protocol on multi-core architecture, ” Diss. 2014. [4] – Chang, Mu-Tien, Shih-Lien Lu, and Bruce Jacob. “Impact of Cache Coherence Protocols on the Power Consumption of STT-RAM-Based LLC, ” [5] – CMU 15 -418: Parallel Architecture and Programming. Lecture Series. Spring 2012. Introduction Snooping Directory Conclusion

Q&A Introduction Snooping Directory Conclusion
- Slides: 104