Buddy Scheduling in Distributed Scientific Applications on SMT

Buddy Scheduling in Distributed Scientific Applications on SMT Processors Nikola Vouk December 20, 2004 In Fulfillment of Requirement for Master’s of Science at NCSU

Introduction • Background of Simultaneous Multi-Threading • Goals • Modified MPICH Communication Library Modifications • Low latency Synchronization Primitives • Promotional Thread Scheduler • Modified MPICH Evaluation • Conclusions/Future Work

Background • Simultaneous Multi-threading Architecture – Modern super-scalar processor – Multiple Program Contexts Core – Can fetch from any context and execute from all contexts simultaneously
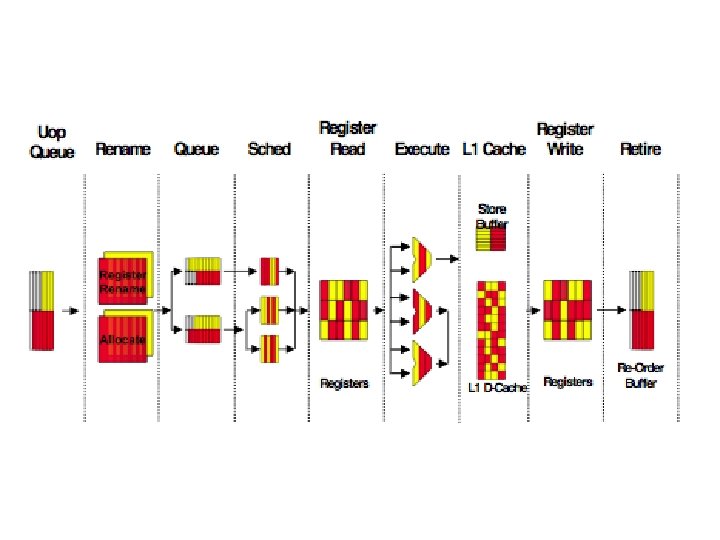

Problems –Not enough TLP in programs to fully utilize modern processors –Increase in TLP through multiple threads –On average faster

Parallel Scientific Applications – Designed for Multi-processors. – MPI+Open. MP - CPU Intensive – Legacy applications assume sole use of whole processor and cache – Compute/Communicate Model – Many suffer performance drops due to hardware sharing

Solutions • Take advantage of inherent concurrency in Compute/Communicate Model • Provide private access to whole processor • Minimize thread synchronization • Transparent to application

Modified MPICH • • MPI Communications Library Channel P 4 library - TCP/IP Serial library Application must stop computing to send/receive data synchronously or asynchronously

Modified MPICH • Asynchronous Communication functions handled by helper thread • New connections handled by helper thread • No longer uses signals, nor forked processes • Isend/Irecv handle setup of each function, then continues without waiting for function completion (short circuit) • Threads communicated through Request Queue
 { MPI_Isend(args); . . . }")
Normal MPICH Design Main Thread void main( ) { MPI_Isend(args); . . . } MPI_Isend(args) { …. return 0; } Listener Thread Void Listener( ) { while (!done) { wait. For. Network. Activity(); Signal. Main. Thread( ) } } CPU
 { MPI_Isend(args); . . .")
Modified MPICH DESIGN Helper Thread Primary/Master Thread void main() { MPI_Isend(args); . . . } MPI_Isend(args) { return enqueue(args); } CPU 1 SMT Threadvoid SMT_LOOP( ) { while (! done) { do { checkt. For. Request(); check. For. Network(); } while (no_request); action = dequeue. Request( ) retvalue = action->function(args); } } MPI_Isend_SMT( args ) {. . . return 0; CPU 2 }
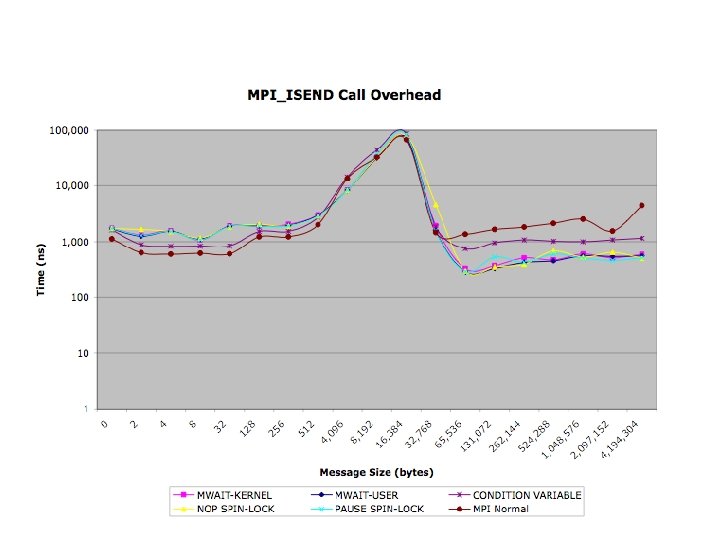

Synchronization Primitives

Evaluation Kernel 1 - Latency MWAIT User: 41, 000 ns MWAIT KERNEL: 2, 900 ns Condition Variable: 10, 700 ns PAUSE Spin-Lock: 500 ns NOP Spin-Lock: 500 ns

Evaluation Kernel 2 Notification Call Overhead MWAIT User: 450 ns MWAIT KERNEL: 3, 400 ns Condition Variable: 5, 200 ns PAUSE Spin-Lock: 500 ns NOP Spin-Lock: 500 ns

Evaluation Kernel 3 Resource Impact MWAIT User: 61, 000 ns MWAIT KERNEL: 57, 000 ns Condition Variable: 63, 000 ns PAUSE Spin-Lock: 129, 500 ns NOP Spin-Lock: 131, 000 ns

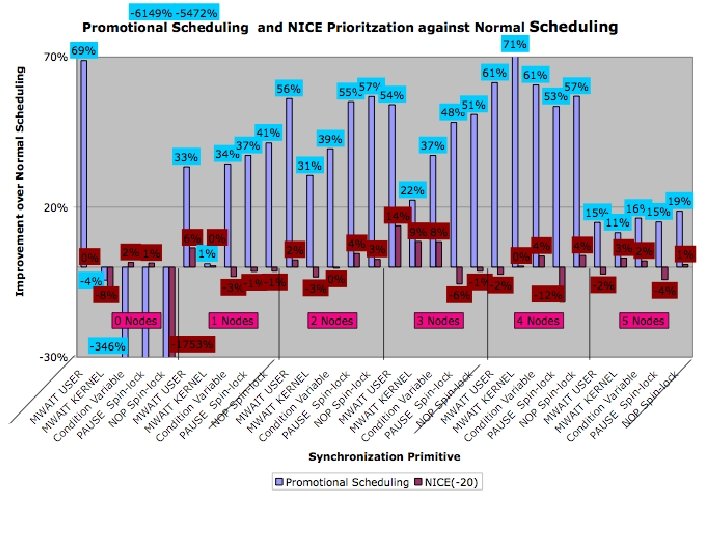
Promotional Buddy Scheduling • • Master and Buddy Tasks Master task is a regular task scheduled as normal Buddy task is a regular task when master not scheduled Whenever Master Task runs, Buddy Task is co-scheduled ahead of all other tasks • Remains scheduled until blocks, or master gets unscheduled Purpose: • Provide low latency IPC, • Minimize scheduling latency • Isolate master and buddy with processor

Promotional Thread Scheduling Kernel • 0 to 5 background task • Measure latency of notification

Modified MPICH Evaluation Benchmarks • s. PHOT – Very light network activity (Gather/Scatter 2 x) • s. PPM – Exclusively isend/irecv , few messages, – large packets - (30 MB total/thread) • SMG 2000 – Isend, Irecv - High message volume, small packets • IRS – Gather/Scatter/Bcast Predominate • Sweep 3 D – Send/Recv - Medium volume of messages
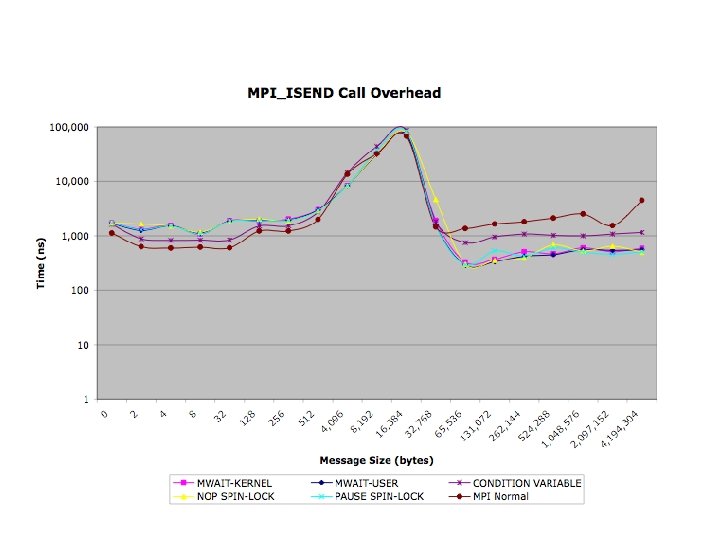
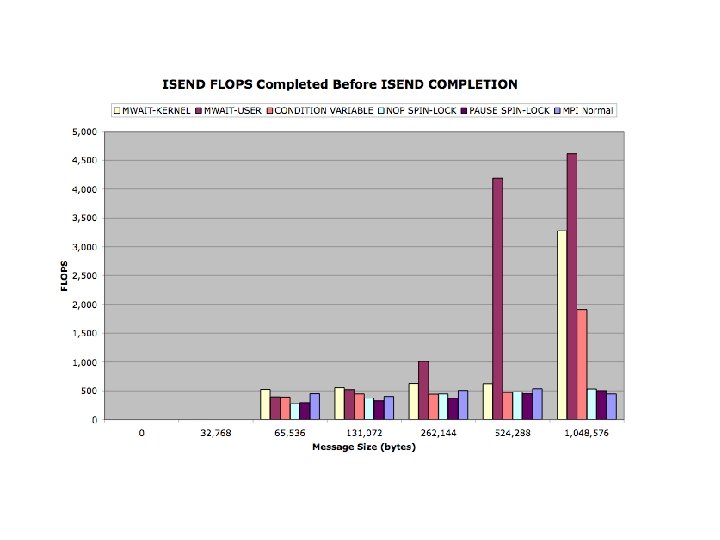
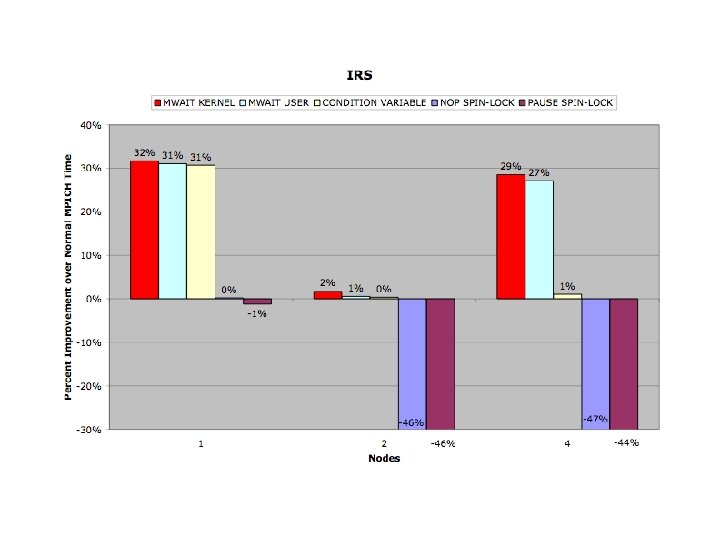
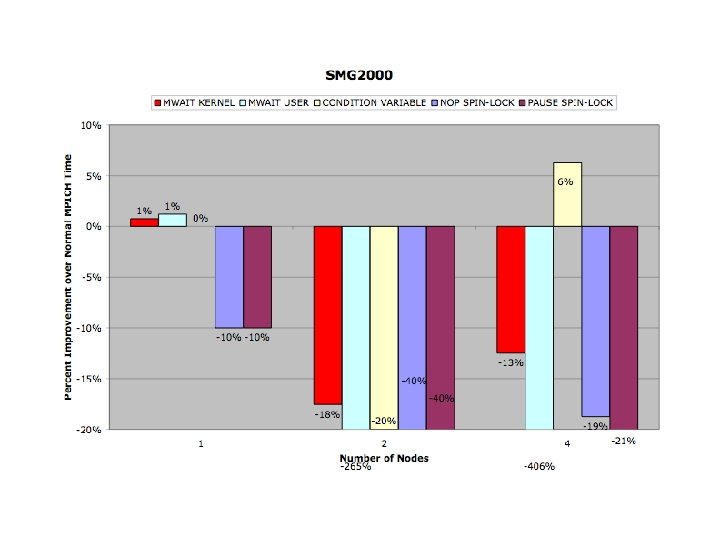

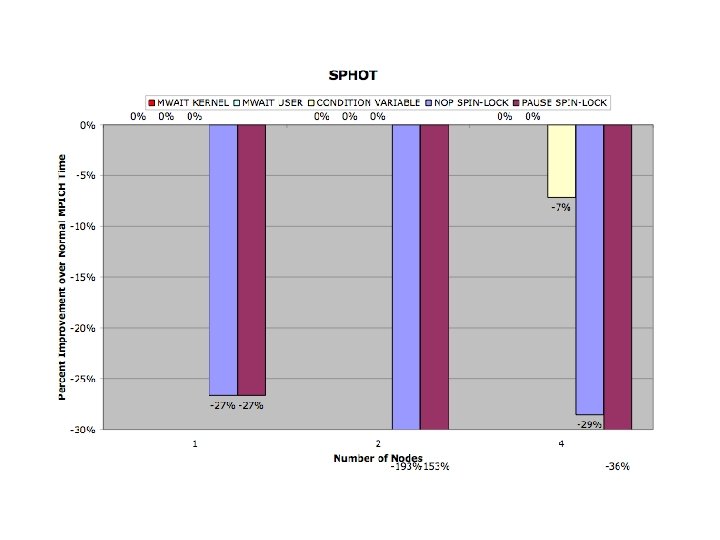
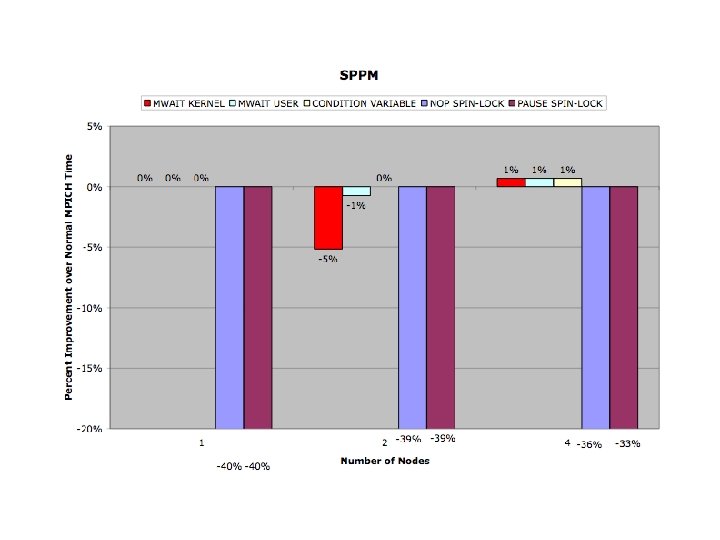
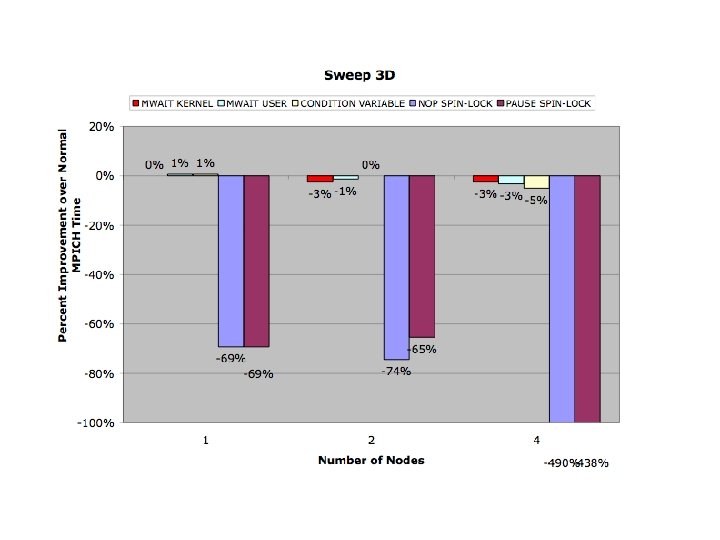

Conclusions • Benchmarks reflect strengths and weaknesses of threading model • Promotional Scheduler Kernel Successful • Synchronization Kernels reflected in code

Future Work • Future work will include looking into gang scheduling to further evaluate the promotional scheduling • Modify MPICH for page-locked requests, to prevent page faults for MWAIT User • Red-Black Kernels • Allow sub-32 k isends to complete normally
- Slides: 30