Bio Perl n n An Introduction to Perl

Bio. Perl n n An Introduction to Perl – by Seung-Yeop Lee XS extension – by Sen Zhang Bio. Perl Introduction– by Hairong Zhao Bio. Perl Script Examples – by Tiequan Zhang

Part I. An Introduction to Perl by Seung-Yeop Lee

What is Perl? n Perl is an interpreted programming language that resembles both a real programming language and a shell. n n A Language for easily manipulating text, files, and processes Provides more concise and readable way to do jobs formerly accomplished using C or shells. Perl stands for Practical Extraction and Report Language. Author: Larry Wall (1986)

Why use Perl? n Easy to use n n n Fast n n Basic syntax is C-like Type-”friendly” (no need for explicit casting) Lazy memory management A small amount of code goes a long way Perl has numerous built-in optimization features which makes it run faster than other scripting language. Portability n One script version runs everywhere (unmodified).

Why use Perl? n Efficiency n For programs that perform the same task (C and Perl), even a skilled C programmer would have to work harder to write code that: n n n Correctness n Perl fully parses and pre-”compiles” script before execution. n n Runs as fast as Perl code Is represented by fewer lines of code Efficiently eliminates the potential for runtime SYNTAX errors. Free to use n Comes with source code

Hello, world! ‘#’ denotes a line commment interpreter path #!/usr/local/bin/perl Newline character # print “Hello, world n”; Delimits a string Terminator character Function which outputs arguments.

Basic Program Flow n n n No “main” function Statements executed from start to end of file. Execution continues until n End of file is reached. exit(int) is called. n Fatal error occurs. n

Variables n Data of any type may be stored within three basic types of variables: n n Scalar List Associative array (hash table) Variables are always preceded by a “dereferencing symbol”. n n n $ - Scalar variables @ - List variables % - Associative array variables

Variables n Notice that we did NOT have to n n n Declare the variable before using it Define the variable’s data type Allocate memory for new data values

Scalar variables n References to variables always being with “$” in both assignments and accesses: n For scalars: n n $x = 1; $x = “Hello World!”; $x = $y; For scalar arrays: n n $a[1] = 0; $a[1] = $b[1];

List variables n Lists are prefaced by an “@” symbol: @count = (1, 2, 3, 4, 5); @count = (“apple”, “bat”, “cat”); @count 2 = @count; n n n A list is simply an array of scalar values. Integer indexes can be used to reference elements of a list. To print an element of an array, do: print $count[2];

Associative Array variables n n Associative array variables are denoted by the % dereferencing symbol. Associative array variables are simply hash tables containing scalar values n Example: $fred{“a”} $fred{“b”} $fred{6} = $fred{1} = n = “aaa”; = “bbb”; “cc”; 2; To do this in one step: %fred = (“a”, “aaa”, “bbb”, 6, “cc”, 1, 2);

Statements & Input/Output n Statements n n Contains all the usual if, for, while, and more… Input/Output n n Any variable not starting with “$”, “@” or “%” is assumed to be a filehandle. There are several predefined filehandles, including STDIN, STDOUT and STDERR.

Subroutines n n n We can reuse a segment of Perl code by placing it within a subroutine. The subroutine is defined using the sub keyword and a name. The subroutine body is defined by placing code statements within the {} code block symbols. sub My. Subroutine { #Perl code goes here. }

Subroutine call n To call a subroutine, prepend the name with the & symbol: &My. Subroutine; n Subroutine may be recursive (call themselves).

Pattern Matching n n n Perl enables to compare a regular expression pattern against a target string to test for a possible match. The outcome of the test is a boolean result (TRUE or FALSE). The basic syntax of a pattern match is $my. Scalar =~ /PATTERN/ n “Does $my. Scalar contain PATTERN ? ”

Functions n n Perl provides a rich set of built-in functions to help you perform common tasks. Several categories of useful built-in function include n n Arithmetic functions (sqrt, sin, … ) List functions (push, chop, … ) String functions (length, substr, … ) Existance functions (defined, undef)

Perl 5 n Introduce new features: n n n A new data type: the reference A new localization: the my keyword Tools to allow object oriented programming in Perl New shortcuts like “qw” and “=>” An object oriented based liberary system focused around “Modules”

References n A reference is a scalar value which “points to” any variable. Variable Value Reference
 operator. $name")
Creating References n References to variables are created by using the backslash() operator. $name = “bio perl”; $reference = $name; $array_reference = @array_name; $hash_reference = %hash_name; $subroutine_ref = &sub_name;

Dereferencing a Reference n Use an extra $ and @ for scalars and arrays, and -> for hashes. print “$$scalar_referencen” “@$array_referencen” “$hash_reference->{‘name’}n”;

Variable Localization n local keyword is used to limit the scope of a variable to within its enclosing brackets. n Visible not only from within the enclosing bracket but in all subroutine called within those brackets $a = 1; sub my. Sub { local $a = 2; &my. Sub 1($a); } sub my. Sub 1 { print “a is $an”; } a is 2

Variable Localization – cont’d n my keyword hides the variable from the outside world completely. n Totally hidden $a = 1; sub my. Sub { my $a = 2; &my. Sub 1($a); } sub my. Sub 1 { print “a is $an”; } a is 1
 n Defining a class n A class is")
Object Oriented Programming in Perl (1) n Defining a class n A class is simply a package with subroutines that function as methods. #!/usr/local/bin/perl package Cat; sub new { … } sub meow { … }
 n Perl Object To initiates an object from")
Object Oriented Programming in Perl (2) n Perl Object To initiates an object from a class, call the class “new” method. n $new_object = new Class. Name; n Using Method n To use the methods of an object, use the “->” operator. $cat->meow();
 n Inheritance n Declare a class array called")
Object Oriented Programming in Perl (3) n Inheritance n Declare a class array called @ISA. n This array store the name and parent class(es) of the new species. package North. American. Cat; @North. American. Cat: : ISA = (“Cat”); sub new { … }

Miscellaneous Constructs n qw n The “qw” keyword is used to bypass the quote and comma character in list array definitions. @name = (“Tom”, “Mary”, “Michael”); @name = qw(Tom Mary Michael);

Miscellaneous Constructs n => n The => operator is used to make hash definitions more readable. %client = {“name”, , “Michael”, “phone” , ” 123 -3456”, “email” , ”mich@nj. net”}; %client = {“name” => “Michael”, “phone” => ” 123 -3456”, “email” => “mich@nj. net”};

Perl Modules n n A Perl module is a reusable package defined in a library file whose name is the same as the name of the package. Similar to C link library or C++ class package Foo; sub bar { print “Hello $_[0]n”} sub blat { print “World $_[0]n”: 1;

Names n n Each Perl module has a unique name. To minimize name space collision, Perl provides a hierarchical name space for modules. n n Components of a module name are separated by double colons (: : ). For example, n n Math: : Complex Math: : Approx String: : Bit. Count String: : Approx

Module files n n n Each module is contained in a single file. Module files are stored in a subdirectory hierarchy that parallels the module name hierarchy. All module files have an extension of. pm. Module Is stored in Config. pm Math: : Complex Math/Complex. pm String: : Approx String/Approx. pm

Module libraries n n The Perl interpreter has a list of directories in which it searhces for modules. Global arry @INC >perl –V @INC: /usr/local/lib/perl 5/5. 00503/sun 4 -solaris /usr/local/lib/perl 5/5. 00503 /usr/local/lib/perl 5/site-perl/5. 005/sun 4 -solaris /usr/local/lib/perl 5/site-perl/5. 005

Creating Modules n To create a new Perl module: . . /development>h 2 xs –X –n Foo: : Bar Writing Foo/Bar. pm Writing Foo/Bar/Makefile. PL Writing Foo/Bar/test. pl Writing Foo/Bar/Changes Writing Foo/Bar/MANIFEST. . /development>

Building Modules n To build a Perl module: Run test. pl Install your module perl Makefile. PL make test make install Create the makefile Create test directory blib and the installs the module in it.

Using Modules n A module can be loaded by calling the use function. use Foo; bar( “a” ); blat( “b” ); n n Calls the eval function to process the code. The 1; causes eval to evaluate to TRUE.

End of Part I. Thank You…
extension n Sen Zhang")
Part II: XS(e. Xternal subroutine)extension n Sen Zhang

XS n n XS is an acronym for e. Xternal Subroutine. With XS, we can call C subroutines directly from Perl code, as if they were Perl subroutines.

Perl is not good at: n n very CPU-intensive things, like numerical integration. very memory-intensive things. Perl programs that create more than 10, 000 hashes run slowly. system software, like device drivers. things that have already been written in other languages.

Usually… n These things are done by other highly efficient system programming languages such as CC++.

Can we call C subroutine from Perl? n Solution is: Perl C API

When perl talks with C subroutine using perl C API n two things must happen: n control flow - control must pass from Perl to C (and back) n C program execution n Perl program execution n data flow - data must pass from Perl to C (and back) n C data representation n Perl data representation

In order to use perl C API n n What is Perl's internal data structures. How the Perl stack works, and how a C subroutine gets access to it. How C subroutines get linked into the Perl executable. Understand the data paths through the Dyna. Loader module that associate the name of a Perl subroutine with the entry point of a C subroutine

If you do code directly to the Perl C API n You will find You keep writing the same little bits of code n n n to move parameters on and off the Perl stack; to convert data from Perl's internal representation to C variables; to check for null pointers and other Bad Things. When you make a mistake, you don't get bad output: you crash the interpreter. It is difficult, error-prone, tedious, and repetitive.

Pain killer is n XS

What is XS? n n Narrowly, XS is the name of the glue language More broadly, XS comprises a system of programs and facilities that work together : n Maker, n Xsub glue routine, n XS language itself, n xsubpp, n h 2 xs, n Dyna. Loader.

Maker -tool n Perl's Maker facility can be used to provide a Makefile to easily install your Perl modules and scripts.

n n n Maker, Xsub glue routine, XS language itself, xsubpp, h 2 xs, Dyna. Loader.

n n n Maker, Xsub glue routine, XS language itself, xsubpp, h 2 xs, Dyna. Loader.

Xsub n n The Perl interpreter calls a kind of glue routine as an xsub. Rather than drag the Perl C API into all our C code, we usually write glue routines. (We'll refer to an existing C subroutine as a target routine. )

Xsub- control flow n n The glue routine converts the Perl parameters to C data values, and then calls the target routine, passing it the C data values as parameters on the processor stack. When the target routine returns, the glue routine creates a Perl data object to represent its return value, and pushes a pointer to that object onto the Perl stack. Finally, the glue routine returns control to the Perl interpreter.

Xsub-data flow n n Something has to convert between Perl and C data representations. The Perl interpreter doesn't, so the xsub has to. Typically, the xsub uses facilities in the Perl C API to get parameters from the Perl stack and convert them to C data values. To return a value, the xsub creates a Perl data object and leaves a pointer to it on the Perl stack.

n n n Maker, Xsub glue routine, XS language itself, xsubpp, h 2 xs, Dyna. Loader.

n n n Maker, Xsub glue routine, XS language itself, xsubpp, h 2 xs, Dyna. Loader.

XS - language n n n Glue routines provide some structure for the data flow and control flow, but they are still hard to write. So we don't. Instead, we write XS code. XS is, more or less, a macro language. It allows us to declare target routines, and specify the correspondence between Perl and C data types. XS is a collection of macros , while Perl docs refer to XS as a language, it is a macro language.

n n n Maker, Xsub glue routine, XS language itself, xsubpp, h 2 xs, Dyna. Loader.

n n n Maker, Xsub glue routine, XS language itself, xsubpp, h 2 xs, Dyna. Loader.

Xsubpp-tool n n xsubpp is a XS language processor, xsubpp is the program that translates XS code to C code. xsubpp will compile XS code into C code by embedding the constructs necessary to let C functions manipulate Perl values and creates the glue necessary to let Perl access those functions. xsubpp expands XS macros into the bits of C code(xsub-glue routines) necessary to connect the Perl interpreter to your Clanguage subroutines. write XS code so that xsubpp will do the right thing.

n n n Maker, Xsub glue routine, XS language itself, xsubpp, h 2 xs, Dyna. Loader.

n n n Maker, Xsub glue routine, XS language itself, xsubpp, h 2 xs, Dyna. Loader.

H 2 xs - tool n n h 2 xs was originally written to generate XS interfaces for existing C libraries. h 2 xs is a utility that reads a. h file and generates an outline for an XS interface to the C code.

n n n Maker, Xsub glue routine, XS language itself, xsubpp, h 2 xs, Dyna. Loader.

n n n Maker, Xsub glue routine, XS language itself, xsubpp, h 2 xs, Dyna. Loader.

Dyna. Loader-module n In order for a C subroutine to become an xsub, three things must happen n Loading: the subroutine has to be loaded into memory n Linking: the Perl interpreter has to find its entry point n Installation: the interpreter has to set the xsub pointer in a code reference to the entry point of the subroutine

Dyna. Loader. n n n Fortunately, all this is done for us by a Perl module called the Dyna. Loader. When we write an XS module, our module inherits from Dyna. Loader. When our module loads, it makes a single call to the Dyna. Loader: : bootstrap method. bootstrap locates our link libraries, loads them, finds our entry points, and makes the appropriate calls.

Development time Pure perl code Some Manual change . h . c h 2 xs Complier, linker XS code nxsubpp Perl module Xsub(glue subrutine) Input Dyna. Loader. Perl C API Perl interprator Output Running time library
 n n n Sequence alignment is an important problem in the")
An Example- Needleman-Wunsch(NW) n n n Sequence alignment is an important problem in the bleeding-edge field of genomics. Sequence alignment is a combinatorial problem, and naive algorithms run in exponential time. The Needleman-Wunsch algorithm runs in (more or less) O(n^3), Dynamic programming algorithm for global optimal sequence alignment.

Algorithm

Score matrix
 step in the NW algorithm is filling in the")
Complexity analysis n The O(n^3) step in the NW algorithm is filling in the score matrix; everything else runs in linear time. We want to n use the C implementation to fill in the score matrix, n use the Perl implementation for everything else, n and use XS to call from one to the other.

Our approach § § Implement the algorithm as a straight Perl module Analyze (or benchmark) the code for performance Reimplement performance-critical methods (score matrix filling) in C Write XS to connect the C routines to the Perl module

Performance comparison n a straight Perl implementation of the NW algorithm aligns 2 200 -character sequences in 300 seconds. XS version runs the benchmark 200 x 200 alignment in 3 seconds. XS version is about 100 times faster than the Perl implementation.

Bio: : Tools: : p. SW - pairwise Smith Waterman object Bioperl project has p. SW implementation. n p. SW is an Alignment Factory. It builds pairwise alignments using the smith waterman algorithm. n The alignment algorithm is implemented in C and added in using an XS extension. § The Smith-Waterman algorithm needs O(n^2) time to find the highest scoring cell in the matrix. n

The end of Part II n Thanks

Bioperl Introduction Hairong Zhao

What’s Bioperl? n n Bioperl is not a new language It is a collection of Perl modules that facilitate the development of Perl scripts for bio-informatics applications.

Bioperl Modules Perls script Perl Interpreter output Bioperl and Perl input

Why Bioperl for Bio-informatics? n n n Perl is good at file manipulation and text processing, which make up a large part of the routine tasks in bio-informatics. Perl language, documentation and many Perl packages are freely available. Perl is easy to get started in, to write small and medium-sized programs.

Bioperl Project n n n It is an international association of developers of open source Perl tools for bioinformatics, genomics and life science research Started in 1995 by a group of scientists tired of rewriting BLAST and sequence parsers for various formats Now there are 45 registered developers, 10 -15 main developers, 5 core coordinate developers Project website: http: //bioperl. org Project FTP server: bioperl. org

How many people use Bioperl? n n Bioperl has been used worldwide in both small academic labs through to enterprise level computing in large pharmaceutical companies since 1998 Bioperl Usage Survey http: //www. bioperl. org/survey. html

The current status of Bioperl n n n The latest mature and stable version 1. 0 was released in March 2002. This new version contains 832 files. The test suite contains 93 scripts which collectively perform 3042 functionality tests. This new version is "feature complete" for sequence handling, the most common task in bioinformatics, it adds some new features and improve some existing features

The future of Bioperl It is far from mature: n Except sequence handling, all other modules are not complete. n The portability is not very good, not all modules will work with on all platforms.

Bioperl resources n n www. bioperl. org http: //www. bioperl. org/Core/bptutorial. html Example code, in the scripts/ and examples/ directories. Online course written at the Pasteur Institute. See: http: //www. pasteur. fr/recherche/unites/sis/f ormation/bioperl.

Biopython, biojava n n Similar goals implemented in different language Most effort to date has been to port Bioperl functionality to Biopython and Biojava, so the differences are fairly peripheral In the future, some bio-informatics tasks may prove to be more effectively implemented in java or python, interoperability between them is necessary CORBA is one such framework for interlanguage support, and the Biocorba project is currently implementing a CORBA interface for bioperl

Bioperl-Object Oriented n n The Bioperl takes advantages of the OO design to create a consistent, well documented, object model for interacting with biological data in the life sciences. Bioperl Name space The Bioperl package installs everything in the Bio: : namespace.

Bioperl Objects n Sequence handling objects n n Sequence objects Alignment objects Location objects Other Objects: 3 D structure objects, tree objects and phylogenetic trees, map objects, bibliographic objects and graphics objects

Sequence handling n Typical sequence handling tasks: n n n Access the sequence Format the sequence Sequence alignment and comparison n Search for similar sequences Pairwise comparisons Multiple alignment

Sequence Objects n n n Sequence objects: Seq, Rich. Seq, Seq. With. Quality, Primary. Seq, Locatable. Seq, Live. Seq, Large. Seq, Seq. I Seq is the central sequence object in bioperl, you can use it to describe a DNA, RNA or protein sequence. Most common sequence manipulations can be performed with Seq.

Sequence Annotation n n Bio: : Seq. Feature Sequence object can have multiple sequence feature (Seq. Feature) objects - eg Gene, Exon, Promoter objects associated with it. Bio: : Annotation A Seq object can also have an Annotation object (used to store database links, literature references and comments) associated with it

Sequence Input/Output n The Bio: : Seq. IO system was designed to make getting and storing sequences to and from the myriad of formats as easy as possible.

Diagram of Objects and Interfaces for Sequence Analysis

Accessing sequence data n n Bioperl supports accessing remote databases as well as local databases. Bioperl currently supports sequence data retrieval from the genbank, genpept, Ref. Seq, swissprot, and EMBL databases

Format the sequences n Seq. IO object can read a stream of sequences in one format: Fasta, EMBL, Gen. Bank, Swissprot, PIR, GCG, SCF, phd/phred, Ace, or raw (plain sequence), then write to another file in another format use Bio: : Seq. IO; $in = Bio: : Seq. IO->new('-file' => "inputfilename", '-format' => 'Fasta'); $out = Bio: : Seq. IO->new('-file' => ">outputfilename", '-format' => 'EMBL'); while ( my $seq = $in->next_seq() ) {$out->write_seq($seq); }
; # the human read-able id of the sequence $seqobj->subseq(5,")
Manipulating sequence data n $seqobj->display_id(); # the human read-able id of the sequence $seqobj->subseq(5, 10); # part of the sequence as a string $seqobj->desc() # a description of the sequence $seqobj->trunc(5, 10) # truncation from 5 to 10 as new object $seqobj->revcom # reverse complements sequence $seqobj->translate # translation of the sequence …

Alignment n n Searching for ``similar'' sequences, Bioperl can run BLAST locally or remotely, and then parse the result. Aligning 2 sequences with Smith-Waterman (p. SW) or blast n n n The SW algorithm itself is implemented in C and incorporated into bioperl using an XS extension. Aligning multiple sequences (Clustalw. pm, TCoffee. pm) n bioperl offers a perl interface to the bioinformaticsstandard clustalw and tcoffee programs. Bioperl does not currently provide a perl interface for running HMMER. However, bioperl does provide a HMMER report parser.

Alignment Objects n n Early versions used Univ. Aln, Simple. Align Ver. 1. 0 only support Simple. Align. It allows the user to: n n convert between alignment formats extracting specific regions of the alignment generating consensus sequences. …

n Sequence handling objects n n n Sequence objects Alignment objects Location objects

Location Objects n n Bio: : Locations: a collection of rather complicated objects A Location object is designed to be associated with a Sequence Feature object to indicate where on a larger structure (eg a chromosome or contig) the feature can be found.
 to use")
Conclusion Bioperl is n n n Powerful Easy Waiting for you (biologist) to use

Scripts Examples by Using Bioperl Tiequan zhang

Simple. Align module n Description: It handles multiple alignments of sequences Lightweight display/formatting and minimal manipulation

Method: n new Usage Function Returns Args n : my $aln = new Bio: : Simple. Align(); : Creates a new simple align object : Bio: : Simple. Align : -source => string representing the source program where this alignment came from each_seq Usage : foreach $seq ( $align->each_seq() ) Function : Gets an array of Seq objects from the alignment Returns : an array n length() Usage : $len = $ali->length() Function : Returns the maximum length of the alignment. To be sure the alignment is a block, use is_flush
 Function : Makes a strict consensus Args")
n consensus_string Usage : $str = $ali->consensus_string($threshold_percent) Function : Makes a strict consensus Args : Optional treshold ranging from 0 to 100. The consensus residue has to appear at least threshold % of the sequences at a given location, otherwise a '? ' character will be placed at that location. (Default value = 0%) n is_flush Usage : if( $ali->is_flush() ) Function : Tells you whether the alignment is flush, ie all of the same length Returns : 1 or 0 n percentage_identity Usage : $id = $align->percentage_identity Function: The function calculates the average percentage identity Returns : The average percentage identity n no_sequences Usage : $depth = $ali->no_sequences Function : number of sequence in the sequence alignment Returns : integer

testaln. pfam 1433_LYCES/9 -246 REENVYMAKLADRAESDEEMVEFMEKVSNSLGS. EELTVEERNLLSVAYKNVIGARRAS$ 1434_LYCES/6 -243 REENVYLAKLAEQAERYEEMIEFMEKVAKTADV. EELTVEERNLLSVAYKNVIGARRAS$ 143 R_ARATH/7 -245 RDQYVYMAKLAEQAERYEEMVQFMEQLVTGATPAEELTVEERNLLSVAYKNVIGSLRAA$ 143 B_VICFA/7 -242 RENFVYIAKLAEQAERYEEMVDSMKNVANLDV. . . ELTIEERNLLSVGYKNVIGARRAS$ 143 E_HUMAN/4 -239 REDLVYQAKLAEQAERYDEMVESMKKVAGMDV. . . ELTVEERNLLSVAYKNVIGARRAS$ BMH 1_YEAST/4 -240 REDSVYLAKLAEQAERYEEMVENMKTVASSGQ. . . ELSVEERNLLSVAYKNVIGARRAS$ RA 24_SCHPO/6 -241 REDAVYLAKLAEQAERYEGMVENMKSVASTDQ. . . ELTVEERNLLSVAYKNVIGARRAS$ RA 25_SCHPO/5 -240 RENSVYLAKLAEQAERYEEMVENMKKVACSND. . . KLSVEERNLLSVAYKNIIGARRAS$ 1431_ENTHI/4 -239 REDCVYTAKLAEQSERYDEMVQCMKQVAEMEA. . . ELSIEERNLLSVAYKNVIGAKRAS$

Script: use Bio: : Align. IO $str = Bio: : Align. IO->new('-file' => 'testaln. pfam'); $aln = $str->next_aln(); print $aln->length, "n"; print $aln->no_residues, "n"; print $aln->is_flush, "n"; print $aln->no_sequences, "n"; print $aln->percentage_identity, "n"; print $aln->consensus_string(50), "n"; $pos = $aln->column_from_residue_number('1433_LYCES', 14); # = 6; foreach $seq ($aln->each_seq) { $res = $seq->subseq($pos, $pos); $count{$res}++; } foreach $res (keys %count) { printf "Res: %s Count: %2 dn", $res, $count{$res}; }

Result: argerich-54 bio>: perl align. pl 242 103 1 16 66. 9052451661147 RE? ? VY? AKLAEQAERYEEMV? ? MK? VAE? ? ? ELSVEERNLLSVAYKNVIGARRA SWRIISSIEQKEE? ? G? N? ? ? LIKEYR? KIE? EL? ? IC? DVL? LLD? ? LIP? A? ? ? ESK VFYLKMKGDYYRYLAEFA? G? ? RKE? AD? SL? AYK? A? DIA? AEL? PTHPIRLGLALNF SVFYYEILNSPD? AC? LAKQAFDEAIAELDTL? EESYKDSTLIMQLLRDNLTLWTSD? ? ? Res: Q Count: 5 Res: Y Count: 10 Res: . Count: 1 argerich-55 bio>:

Swiss. Prot, Seq and Seq. IO modules n Description: Swiss. Prot is a curated database of proteins managed by the Swiss Bioinformatics Institute. This is in contrast to EMBL/Gen. Bank/DDBJ Which are archives of protein information. It allows the dynamic retrieval of Sequence objects (Bio: : Seq)

Seq. IO can be used to convert different formats: 8. Fasta FASTA format EMBL format Gen. Bank format swiss Swissprot format SCF tracefile format PIR Protein Information Resource format GCG format raw Raw format 9. ace 1. 2. 3. 4. 5. 6. 7. ACe. DB sequence format

Objective: n n loading a sequence from a remote server Create a sequence object for the BACR_HALHA Swiss. Prot entry n Print its Accession number and description n Display the sequence in FASTA format
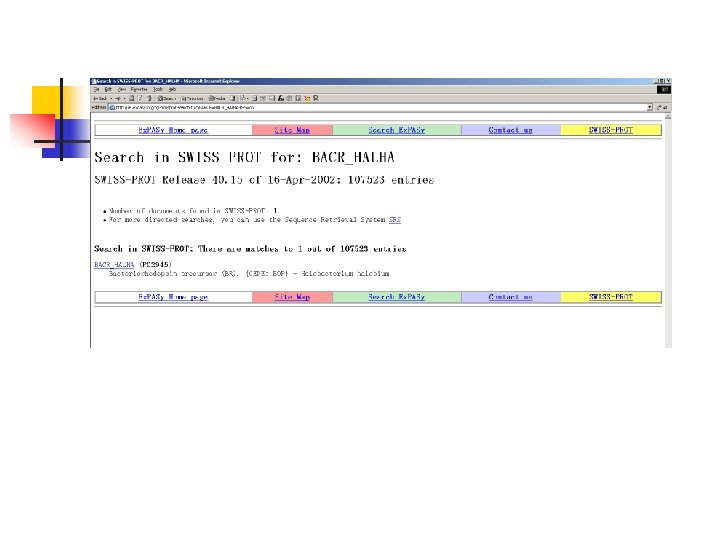

Scripts: #!/usr/bin/perl use strict; use Bio: : DB: : Swiss. Prot; use Bio: : Seq. IO; my $database = new Bio: : DB: : Swiss. Prot; my $seq = $database->get_Seq_by_id('BACR_HALHA'); print "Seq: ", $seq->accession_number(), " -- ", $seq->desc(), "nn"; my $out = Bio: : Seq. IO->new. Fh ( -fh => *STDOUT, -format => 'fasta'); print $out $seq;
. >BACR_HALHA")
Result: argerich-47 bio>: perl protein. pl Seq: P 02945 -- BACTERIORHODOPSIN PRECURSOR (BR). >BACR_HALHA BACTERIORHODOPSIN PRECURSOR (BR). MLELLPTAVEGVSQAQITGRPEWIWLALGTALMGLGTLYFLVKGMGVSDPDAKKFYAITT LVPAIAFTMYLSMLLGYGLTMVPFGGEQNPIYWARYADWLFTTPLLLLDLALLVDADQGT ILALVGADGIMIGTGLVGALTKVYSYRFVWWAISTAAMLYILYVLFFGFTSKAESMRPEV ASTFKVLRNVTVVLWSAYPVVWLIGSEGAGIVPLNIETLLFMVLDVSAKVGFGLILLRSR AIFGEAEAPEPSAGDGAAATSD argerich-48 bio>:

Summary n n Perl language and modules Perl XS Bioperl Example scripts
![References: [1] L. Wall and R. Schwarz. Programming Perl. O’Reilly & Associates, Inc, 1991.](http://slidetodoc.com/presentation_image_h/b15899c4a1b88ac18e4c981d6cb5e40c/image-115.jpg "References: [1] L. Wall and R. Schwarz. Programming Perl. O’Reilly & Associates, Inc, 1991.")
References: [1] L. Wall and R. Schwarz. Programming Perl. O’Reilly & Associates, Inc, 1991. [2] Web Developer’s Virtual Library. http: //www. wdvl. com/Authoring/Languages/Perl/5/ [3] O’Reily Perl. com. http: //www. perl. com/ [4] http: //archive. ncsa. uiuc. edu/General/Training/Perl. Intro/ [5] http: //www. vis. ethz. ch/manuals/Perl/intro. html [6] http: //www. fukada. com/selena/tutorials/perl 5/index. html [7] http: //world. std. com/~swmcd/steven/perl/module_mechanics. html [8] http: //www. sdsc. edu/~moreland/courses/Intro. Perl/ [9] www. bioperl. org/Core/POD/Bio/Seq. IO. html [10] http: //docs. bioperl. org/releases/bioperl-1. 0/Bio/Simple. Align. html [11] www. pasteur. fr/recherche/unites/sis/formation/bioperl/index. html
![References: [12] www. bioinformatics. com [13] ] Bioperl: Standard Perl Modules for Bioinformatics by](http://slidetodoc.com/presentation_image_h/b15899c4a1b88ac18e4c981d6cb5e40c/image-116.jpg "References: [12] www. bioinformatics. com [13] ] Bioperl: Standard Perl Modules for Bioinformatics by")
References: [12] www. bioinformatics. com [13] ] Bioperl: Standard Perl Modules for Bioinformatics by Stephen A Chervitz, Georg Fuellen, Chris Dagdigian, Steven E Brenner, Ewan Birney and Ian Korf Objects in Bioinformatics '98 [15] http: //cvs. open-bio. org/cgi-bin/viewcvs. cgi/bioperlpapers/bioperldesign [16] http: //www. cpan. org [17] http: //www. maths. tcd. ie/~lily/pres 2/sld 008. htm [18] http: //www. sbc. su. se/~per/molbioinfo 2001/dynprog/dynamic. html [19] http: //world. std. com/~swmcd/steven/perl/pm/xs/intro/index. html
- Slides: 116