Beginselen van de Statistiek in de Kinesiologie Prof

Beginselen van de Statistiek in de Kinesiologie Prof. Dr. I. De Bourdeaudhuij Theorie : auditorium Oefeningen : SPSS pc klas UZ

Handboek : Statistiek in de Praktijk Davis Moore & George Mc. Cabe 2001 3 e herziene uitgave / Theorieboek Academic Service, Schoonhoven

Alles is te vinden op : • http: //allserv. rug. ac. be/~ibourd/index. htm

Inleiding • Redeneren, nadenken, inzicht <=> • Berekenen, computer • Link met praktijk : SPSS voor thesis

Wat is statistiek ? • Wetenschap van • verzamelen • organiseren • interpreteren van data of gegevens

Doel van statistiek ? • NIET het berekenen op zich • WEL het verwerven van inzicht uit getallen Doel van deze cursus = BEGRIJPEN

Hoofdstuk 1 Kijken naar gegevens & verdelingen

• Variabele = kenmerk van persoon of ding dat in een getal kan worden uitgedrukt • Waarde = getal voor die persoon of dat ding • Hoeveel variabelen ? H 1 = 1 variabele • Typen variabelen – Kwantitatieve variabelen (numeriek, bewerking) – Kwalitatieve variabelen (categorie)

1. 1. Weergeven van verdelingen met grafieken • Data beschrijven : exploratieve data-analyse • Twee basistrategieën – Eerst 1 variable dan verbanden – Eerst grafisch dan numeriek • H 1 : 1 variable , H 2 : 2 variabelen • Steeds eerst grafisch dan numeriek

A. Grafieken voor kwalitatieve variabelen • Kwalitatieve variabelen = categorie Burg. staat Nooit getrouwd Getrouwd Weduwe/weduwnaar Gescheiden Aantal (milj) 43. 9 116. 7 13. 4 17. 6 Percentage 22. 9 60. 9 7. 0 9. 2

Staafdiagram

Taartdiagram

• Grafieken voor kwalitatieve variabelen geven een goed overzicht, niet echt noodzakelijk • Grafieken voor kwantitatieve variabelen leren ons duidelijk iets meer, data op zich zeggen niet veel

B. Meting • Verzameling getallen 168 158 149 169 175 185 192 167 185 184 168 184 • Welke variabele wordt gemeten ? - goede methode / instrument ? - verschillend per wetenschap

• NADENKEN over getallen bv. dodelijke ongevallen 5000 60+ers 3000 18 -20 jarigen bv. werkloosheidscijfers bv. mortaliteitscijfers Verhoudingsgetallen !!!

C. Variatie • Verschillende metingen van hetzelfde fenomeen bij - 1 persoon - verschillende personen • In elke verzameling gegevens zekere variatie • Variatiepatroon van een kwantitatieve variabele = VERDELING

• In het midden van de verdeling : het gemiddelde • VERDELING = hoe vaak komt elke waarde voor ? Grafische voorstelling • DUS : gemiddelde & verdeling van variabelen zijn belangrijk

D. Stamdiagrammen • Of « stam-en-blad » = « stem-and-leaf » • Doel : vorm van de verdeling in beeld • Voorbeeld : doelpunten per seizoen 21 13 8 19 14 26 12 24 9 14 STAM BLAD 0 | 89 1 | 23449 2 | 146

• Rug-aan-rug stamdiagram : 2 vergelijken • stammen splitsen of afkappen • niet geschikt voor grote groepen • diagram op zijn kant zetten (scheefheid ? )

E. Onderzoeken van verdelingen EIGENSCHAPPEN : 1. Centrum van de verdeling = MEDIAAN 2. Een top of verschillende ? = UNI MODAAL 3. Vorm van de verdeling = SYMMETRISCH of SCHEEF 4. Afwijkingen van de algemene vorm = HIATEN of UITBIJTERS

F. Histogrammen • Aantal of percentage waarnemingen in elk interval • HOE ? 1. Verdeel in klassen van gelijke breedte 2. Aantal per klasse = frequenties Frequentietabel 3. Histogram tekenen
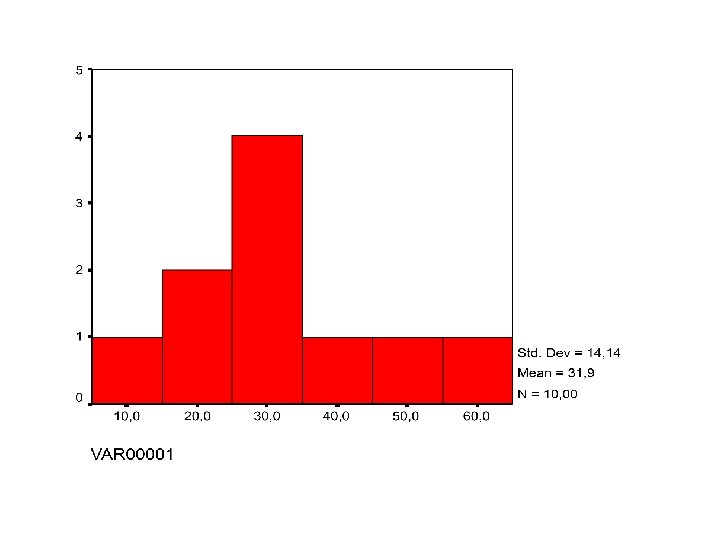

• In histogram frequenties of percentages = relatieve frequenties • Keuze maken over aantal te gebruiken klassen te weinig of te veel

G. Kijken naar gegevens • Globaal patroon en afwijkingen • Uitbijters of uitschieters : – oorzaak ? – Fouten = weglaten – Sterke beïnvloeding van gemiddelde – Soms hebben uitbijters een betekenis

H. Tijdreeksgrafieken • Gegevens uitzetten tegen tijd of volgorde • Belangrijk bij systematische verandering • Bv. Tijdreeksen : springen tijden in lopen/zwemmen • Observatie : trend seizoenvariatie fluctuaties cycli

1. 2. Verdelingen beschrijven • Eerst kijken naar de vorm van de verdeling op grafische manier • Dan beschrijven : – Centrum – Spreiding

A. Meten van het centrum : het gemiddelde Rekenkundig gemiddelde of gemiddelde = tel alle waarnemingen op en deel door het aantal x 1 + x 2 + x 3 + … +xn x = 1/n (x 1 + x 2 + x 3 + … +xn) x = 1/n xi

• Voorbeeld : Aantal doelpunten per match 2 3 1 0 0 1 2 1 2 0 0 3 = 18 / 14 = 1. 2857…. • Voorbeeld : Verspringen 623 684 598 385 654 589 = 3533 / 6 = 588. 83333…. = 3148 / 5 = 629. 6

• Zwakheid van gemiddelde : – > gevoelig voor extremen • bv. uitbijters of uitschieters • bv. scheve verdeling met 1 staart = gemiddelde is GEEN resistente maat

B. Meten van het centrum: de mediaan • Mediaan = middelste waarneming in geordende lijst • oneven = middelste • even = gemiddelde van twee middelste

• Voorbeeld : aantal doelpunten per match : 2 3 1 0 0 1 ordenen : 0 0 1 1 2 2 Mediaan = 1 2 3 • Mediaan gemakkelijk uit stamdiagram • Mediaan is resistente centrummaat

C. Gemiddelde versus mediaan • Bij symmetrische verdeling – gemiddelde = mediaan • Naarmate verdelingen schever worden – gemiddeld en mediaan verder uit elkaar • Dus : bij uitschieters – Goed bekijken, ev. Corrigeren of weglaten • Gemiddelde gebruiken – Uitschieters erin laten • Mediaan gebruiken

D. Meten van de verdeling: kwartielen • Bij het beschrijven van een verdeling : – > centrummaat + spreidingsmaat • Spreiding of variabiliteit van een verdeling • Gelijk gemiddelde en verschillende spreiding => andere betekenis (bv. inkomen)

• Percentiel 30 ste percentiel = de waarde zodat 30% van de verdeling hieronder valt of gelijk is bv. kind van 7 jaar weegt 22 kg. 50 ste percentiel = mediaan

• Kwartielen 1 ste kwartiel = 25 ste percentiel 2 de kwartiel = 50 ste percentiel of mediaan 3 de kwartiel = 75 ste percentiel -> waarnemingen ordenen Mediaan bepalen Mediaan van waarnemingen hieronder Mediaan van waarnemingen hierboven

• Kwartielen en mediaan leren iets over de verdeling Q 1 = 14€ M = 20€ Q 3 = 33€ -> scheefheid naar rechts • Met computer soms iets andere waarden voor kwartielen : andere regels – Kleine verschillen = afrondingsfouten

E. Meten van de verdeling : de interkwartielafstand • Interkwartielafstand IKA = afstand Q 3 - Q 1 = 50% van de data resistente maat : uitschieters spelen geen rol 33€ - 14€ = 19€

• 1. 5 keer IKA boven 3 e kwartiel of onder 1 e kwartiel = verdachte uitschieters 1. 5 keer 19€ = 28. 5€ Q 1= 14€ - 28. 5€ = -14. 5€ Q 3= 33€ + 28. 5€ = 61. 5€

F. De vijf getallen samenvatting en de doosdiagrammen • Vijf getallen samenvatting Minimum, Q 1, M, Q 3, Maximum => Geeft ons nuttige informatie over het centrum en de spreiding van een verdeling

• Boxdiagram of doosdiagram = visuele voorstelling van vijf getallen samenvatting – 1. Randen van de doos = kwartielen – 2. Mediaan = lijn – 3. Snorharen = Minimum en maximum die geen uitschieters zijn – 4. Uitschieters worden apart aangegeven • Met computer soms snorharen tot uitersten binnen 1. 5 keer IKA en resterende waarnemingen afzonderlijk of zonder uitschieters
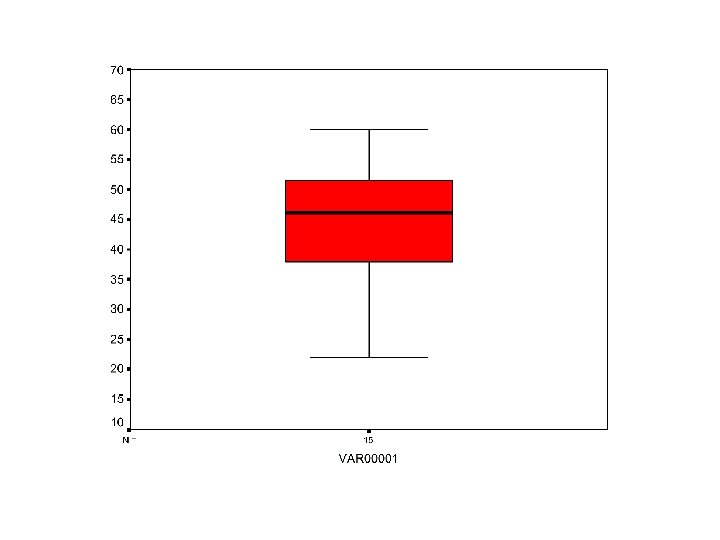

G. Verdelingen vergelijken • Boxdiagrammen om verschillende verdelingen met elkaar te vergelijken

H. Meten van de spreiding: de standaardafwijking • Meest gebruikte spreidingsmaat • Spreiding rond het gemiddelde • Gebruiken als gemiddelde centrummaat is • Gebaseerd op afwijking van elke waarneming van het gemiddelde xi - gemiddelde

• afwijkingen zullen positief en negatief zijn – Want waarnemingen boven en onder het gemiddelde • som van alle afwijkingen zal altijd 0 zijn – Juist omdat we gemiddelde aftrekken • Oplossing : afwijkingen kwadrateren • VARIANTIE = gemiddelde van de gekwadrateerde afwijkingen (s 2) ver van gemiddelde : grote gekwadr. afwijk. dicht bij gemiddelde : kleine gekw. afw.
2 + (x 2 - x)2 +")
• S 2= (x 1 - x)2 + (x 2 - x)2 + … en delen door n-1 S 2= 1/(n-1) (xi - x)2 waarom delen door n-1 en niet door n ? => aangezien som van afwijkingen steeds 0 is kan laatste afwijking gevonden worden uit eerste n-1, dus n-1 kunnen vrij bewegen = aantal vrijheidsgraden

• Door te kwadrateren krijgen we een andere eenheid bv. cm wordt cm 2 • STANDAARDAFWIJKING = de wortel uit de variantie wat de spreiding rond het gemiddelde in de oorspronkelijke schaal meet

I. Eigenschappen van de standaardafwijking • Eigenschappen van s – s meet de spreiding rond het gemiddelde (gemiddelde is centrummaat) – s = o als er geen spreiding is (alle waarnemingen zijn gelijk), anders is s > 0 • s is geen resistente maat, door kwadraten zelfs nog gevoeliger • s is vooral belangrijk bij symmetrische verdelingen (normaalverdelingen)

J. Het kiezen van centrum- en spreidingsmaten • Voor een scheve verdeling of sterke uitschieters : - Vijf getallen samenvatting • Voor een redelijk symmetrische verdeling zonder uitschieters - Gemiddelde en standaarddeviatie => DUS altijd eerst grafische voorstelling maken

K. Meeteenheid veranderen • Beschrijvingen van een verdeling kunnen geconverteerd worden van de ene naar de andere meeteenheid – > lineaire transformatie xnieuw = a + bx = optellen van een constante a = vermenigvuldigen met constante b (b>0) – bv. mijl in kilometer – bv. graden celcius en Fahrenheit

• Lineaire transformaties hebben geen effect op de vorm van de verdeling – symmetrisch blijft symmetrisch – scheef naar rechts blijft scheef naar rechts • Maar centrum en spreiding kunnen wel veranderen – gemiddelde, mediaan en kwartielen : vermenigvuldigen met b en a optellen – IKA en standaardafwijking vermenigvuldigen met b

1. 3. De normale verdeling • 1. 2. 3. Tot nu toe : Teken de gegevens : grafiek Kijk naar patroon en afwijkingen Bereken centrum en spreiding • Volgende stap : 4. Soms is patroon zo regelmatig dat we kunnen beschrijven door gladde kromme
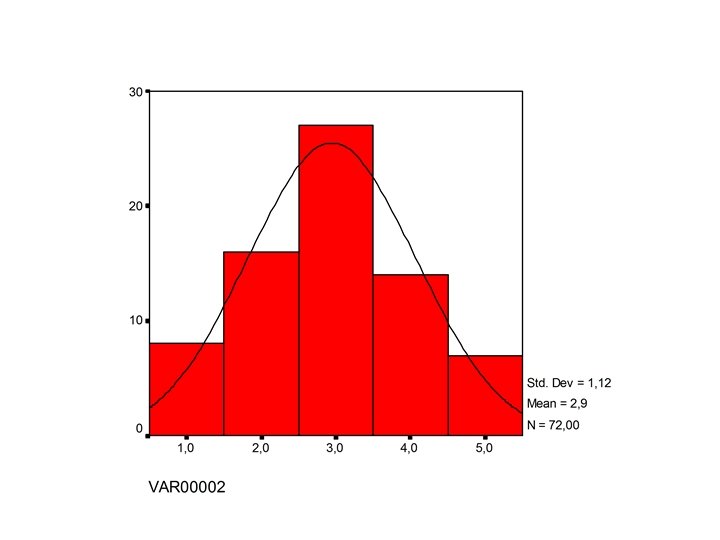

• Maken van een wiskundig model van een verdeling • Doel : volledige verdeling beschrijven met enkele uitdrukkingen + regels die gelden voor vele verdelingen • Punten zullen niet exact op het model liggen, maar bij benadering

A. Dichtheidskrommen • Gladde kromme overheen histogram – compacte beschrijving – details verdwijnen • De hoekigheid van histogram verdwijnt
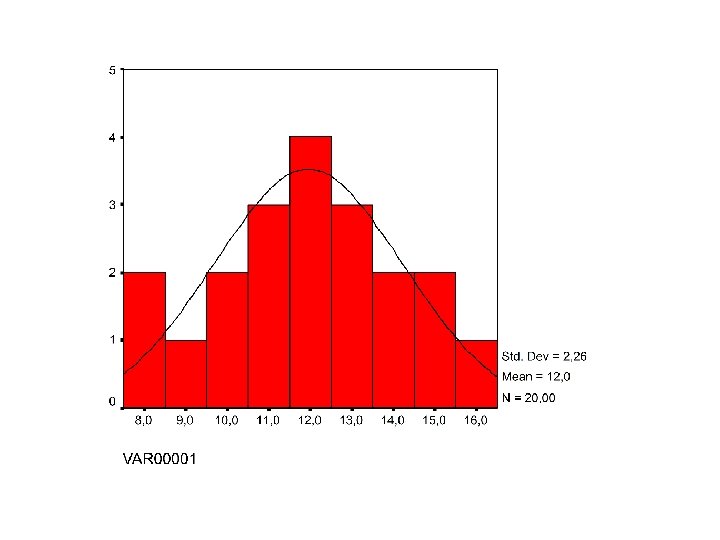

• Totaal van de percentages over alle waarnemingen = 100% of relatieve frequentie 1 => oppervlakte onder de kromme = 1 oppervlakte = relatieve frequentie => dichtheidskromme

B. Het meten van centrum en spreiding voor dichtheidskrommen • Maten van centrum en spreiding zijn toepasbaar op dichtheidskrommen - p de percentiel : p% oppervlakte links 100 - p% oppervlakte rechts - mediaan : punt van gelijke oppervlaktes - kwartielen : 4 gelijke oppervlaktes - IKA : afstand tussen Q 1 en Q 3

• Gemiddelde of beter verwachting van een dichtheidskromme: punt waar de kromme in evenwicht zou zijn

• Bij symmetrische krommen : – Mediaan = gemiddelde • Bij scheve krommen : – Gemiddelde wordt dichter naar de staart getrokken (meer beïnvloed) • Feitelijke waarnemingen : x en s • Dichtheidskromme (geïdealiseerd) µ (Griekse letter mu) en (sigma)

C. Normale verdelingen • Normale verdelingen zijn : – symmetrische – ééntoppige – klokvormige dichtheidskrommen • Verwachting µ in centrum = mediaan • Standaardafwijking = spreiding

• Normale krommen met gelijke verwachting maar andere waarden voor • Van steile naar zwakke dalingstendens verandering in de kromme dit punt aan weerszijden

• Waarom zijn normale verdelingen zo belangrijk in de statistiek ? 1. Ze zijn goede modellen voor verdelingen met echte data : groot aantal pp. 2. Goede benaderingen van toevallige uitkomsten : bv. Gooien dobbelsteen 3. Vele statistische inferentie procedures gebaseerd op normale verdeling gelden voor andere, min of meer normale verdelingen

• Normaalverdelingen – toets bij de bevolking – herhaald meten van zelfde grootheid – karakteristieken van biologische populaties • MAAR : ook veel verdelingen zijn niet normaal – inkomen – levensverwachting

D. De 68 - 95 - 99. 7 regel • Er bestaan vele normale krommen maar ze voldoen allemaal aan de 68 - 95 - 99. 7 regel • Voor elke normaalverdeling geldt : – 68% van de waarnemingen ligt binnen de afstand van het gemiddelde µ – 95% van de waarnemingen ligt binnen de afstand 2 van het gemiddelde µ – 99. 7% van de waarnemingen ligt binnen de afstand 3 van het gemiddelde µ

• Voorbeeld : lengte vrouwen 18 -24 jaar – µ = 166. 4 cm = 6. 4 cm – 95% tussen 153. 6 cm en 179. 2 cm – 99. 7% tussen 147. 2 cm en 185. 6 cm • Korte notatie : N(µ, ) dus N(166. 4, 6. 4) • Steeds eerst nagaan of je een normaalverdeling hebt vooraleer conclusies met 68 - 95 - 99. 7 regel
 een normale verdeling heeft,")
E. Gestandaardiseerde waarnemingen • Als een variabele X (bv. lengte) een normale verdeling heeft, met verwachting µ en standaarddeviatie X is N (µ, ) • Eigenlijk zijn alle normale verdelingen identiek als de metingen gebeuren met als eenheid en µ als het centrum

• Dus : als de verdeling van een variabele normaal is kan ze worden gestandaardiseerd STANDAARDISEREN = – door verwachting af te trekken – en dit te delen door de standaardafwijking Een gestandaardiseerde waarde = z-score x - µ z = ----
")
• Gevolg : hoeveel standaardafwijking ligt de waarde van de verwachting (van 0) – positief : groter dan verwachting – negatief : kleiner dan verwachting • Voorbeeld : – x wordt na standaardisering = 0. 5 dit wil zeggen een halve standaardafwijking boven gemiddelde

• Voorbeeld : lengte jonge vrouwen – µ = 166. 4 cm en = 6. 4 cm – gestandaardiseerde lengte z = lengte - 166. 4 – bv. 176 cm : z = 1. 5 of 1. 5 stand. afw. boven µ – bv. 152 cm : z = -2. 25 of 2. 25 stand. afw. onder µ

F. De standaardnormale verdeling • Door standaardiseren zetten we alle normale verdelingen om in één enkele verdeling : deze nieuwe variabelen hebben de standaardnormale verdeling • N (0, 1) is de standaardnormale verdeling • Z = X - µ

• Tabel A geeft de oppervlaktes onder de standaardnormale kromme • Voor elke waarde z kan men opzoeken welke oppervlakte hier links van ligt • Voorbeeld: welk percentage vrouwen heeft een dergelijke lengte ? Oppervlakte onder de kromme => dit opzoeken in tabel A 1. 5 komt overeen met 0. 9332 dus 93% en 7%

G. Berekeningen bij de normale verdeling • Het gebruik van tabel A is zeer handig om vraagstukken op te lossen m. b. t. A. Hoeveel % heeft een score • • • Lager dan. . Hoger dan Tussen …. B. Welke waarde komt overeen met xx % • Ook via Tabel A maar OMGEKEERD

H. Normaal-kwantiel-diagrammen • Telkens eerst normaliteit vaststellen vooraleer er berekeningen worden gedaan die hiervan uitgaan 1. Op basis van figuur : histogram of stamdiagram 2. Vergelijkingen met de 68 - 95 - 99. 7 regel 3. Normaal-kwantiel-diagram : meer precieze methode

• Principe aan de hand van een voorbeeld : 12 12 14 13 13 12 11 10 9 11 – eerst de data ordenen – dan voor elk punt percentiel vastleggen (P 10, P 20, … – Tabel A kijken naar welke z met deze oppervlakte overeenkomt. – elk punt met zijn z-waarde uittekenen => data zijn normaal als ze dicht bij een rechte lijn liggen (met computer)
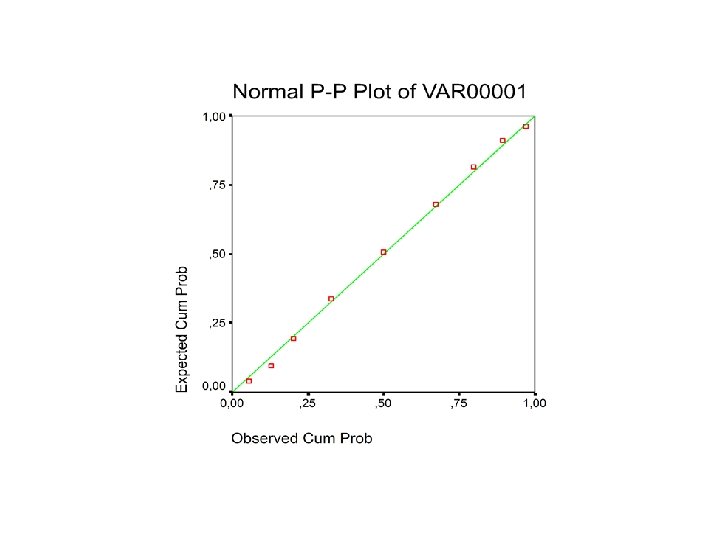

• Soms veel keer dezelfde meting = op een stapel dit noemt korreligheid (is meestal geen probleem) • Op basis van normaal-kwantiel-diagram is een normaal model passend ? – Uitschieters ver van de lijn – Kleine afwijkingen, kronkels geen probleem – Bij benadering normaal – Zeer veel gebruikt in statistiek
- Slides: 76