Azure SQL DB setup 2 3 Tier SLA


Azure SQL DB 実践編 - setup 2

3


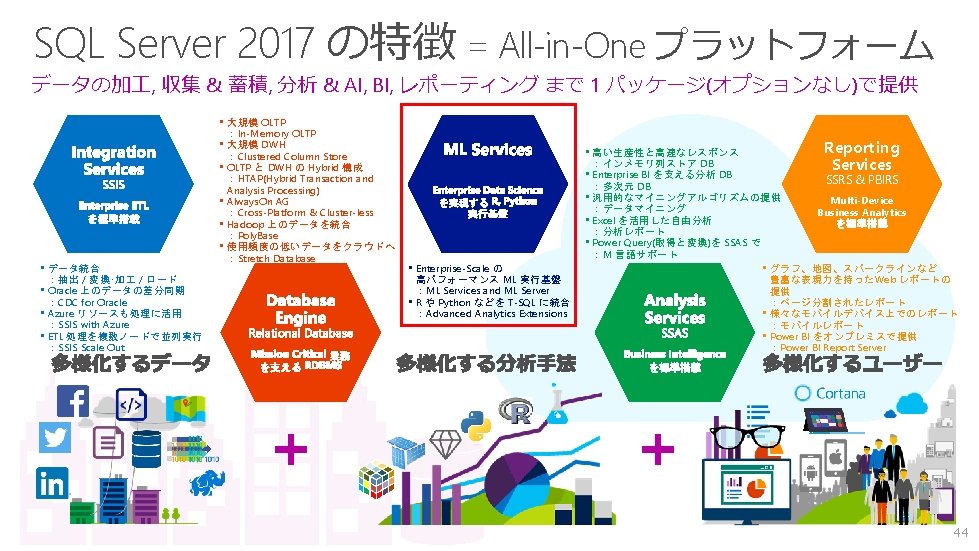
各サービス Tier ごとの詳細 機能 使用可能時間 SLA 最大 DB サイズ Basic S 0 99. 99% 2 GB 250 GB DTU (Database Throughput Units) 5 In-Memory OLTP ストレージサイズ N/A Point In Time Restore Standard S 1 S 2 10 20 P 1 P 2 P 11 P 15 99. 99% 500 GB 50 100 N/A 過去 7日間の任意 の時点 1 TB or 4 TB 125 250 500 1, 000 1, 750 4, 000 1 GB 2 GB 4 GB 8 GB 14 GB 32 GB 過去 35 日間の任意の時点 アクティブ Geo レプリケーション ( 最大 4 つまでの [読取可能] オンライン セカンダリー バックアップ ) Disaster Recovery パフォーマンス目標 S 3* Premium (※) P 4 P 6 1 時間当たりトラ ンザクション数 16, 600/h 1 分当たりのトランザクション数 521/m 934/m 2, 570/m 1 秒当たりのトランザクション数 5, 100/m 105/s 213/s 850/s 1, 488/s 3, 400/s 予測可能性 良い(時間単位) TPM 換算値 276 521 934 2, 570 5, 100 6, 300 13, 680 26, 820 44, 100 77, 175 176, 366 最大同時ログイン数 30 60 90 120 200 400 800 1, 600 2, 400 6, 400 1 時間当たりの料金 300 �. 78/時 600 2. 33/時 900 4. 66/時 1, 200 11. 65/時 2, 400 23. 28/時 30, 000 72. 05/時 30, 000 144. 08/時 30, 000 288. 66/時 1 ヶ月当たりの料金 612/月 1, 734/月 3, 468/月 8, 670/月 17, 340/月 53, 550/月 107, 202/月 214, 812/月 428, 808/月 808, 248/月 最大セッション数 高い(分単位) 425/s 最高(秒単位) SQL Database のオプションとパフォーマンス: 各サービス レベルで使用できる内容について理解する https: //docs. microsoft. com/ja-jp/azure/sql-database-service-tiers 30, 000 576. 30/時 1086. 30/時 ¥ 2, 482. 68/時 1, 847, 113. 92/月 ※Premium RS を別途提供:Premium から可用性を排した DWH などの用途 (1/4 の価格) 6

Active Geo-Replication l 最大 4 箇所の Azure リージョンにレプリカを作成 Active Geo-Replication 7

Azure SQL DB 実践編 -1 https: //docs. microsoft. com/ja-jp/azure/sql-database-get-started-portal 8

Azure SQL DB 実践編 -2 9

Azure SQL DB 実践編 -3 10

Azure SQL DB 実践編 -4 11

Azure SQL DB 実践編 -5 https: //docs. microsoft. com/en-us/sql-operations-studio/what-is 13

Azure SQL DB 実践編 -6 https: //powerbi. microsoft. com/ja-jp/desktop/ 14

15

Azure SQL Data Warehouse アーキテクチャ Application or User connection 500 DWU Control Engine Data Loading DMS (ADF, SSIS, REST, OLE, ODBC, SQL DB ADF, AZCopy, Power. Shell) Compute Compute DMS DMS DMS SQL DB SQL DB Dist_DB_1 Dist_DB_2 Dist_DB_13 Dist_DB_14 Dist_DB_25 Dist_DB_26 Dist_DB_37 Dist_DB_38 Dist_DB_49 Dist_DB_50 … … … Dist_DB_12 Dist_DB_24 Dist_DB_36 Dist_DB_48 Dist_DB_60 Premium Storage ・・・ (60 DB) 17

Azure SQL Data Warehouse アーキテクチャ Application or User connection 1000 DWU Control Engine Data Loading DMS (ADF, SSIS, REST, OLE, ODBC, SQL DB ADF, AZCopy, Power. Shell) Compute Compute Compute DMS DMS DMS SQL DB SQL DB SQL DB Dist_DB_1 Dist_DB_2 Dist_DB_7 Dist_DB_8 Dist_DB_13 Dist_DB_14 Dist_DB_19 Dist_DB_20 Dist_DB_25 Dist_DB_26 Dist_DB_31 Dist_DB 32 Dist_DB_37 Dist_DB_38 Dist_DB_43 Dist_DB_44 Dist_DB_49 Dist_DB_50 Dist_DB_55 Dist_DB_56 … … … … … Dist_DB_6 Dist_DB_12 Dist_DB_18 Dist_DB_24 Dist_DB_30 Dist_DB_26 Dist_DB_42 Dist_DB_48 Dist_DB_54 Dist_DB_60 Premium Storage ・・・ (60 DB) 18
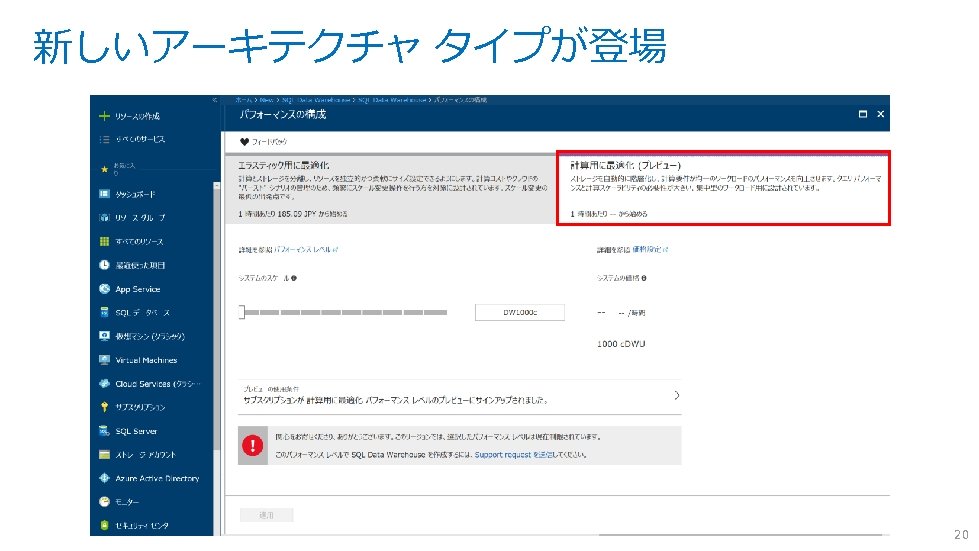
 21")
Optimized for compute(Pesto) 21


Azure SQL Data Warehouse 実践編 -1 https: //docs. microsoft. com/ja-jp/azure/sql-data-warehouse/create-data-warehouse-portal 23

Azure SQL Data Warehouse 実践編 -2 24

Azure SQL Data Warehouse 実践編 -3 25

Azure SQL Data Warehouse 実践編 -4 26

Azure SQL Data Warehouse 実践編 -5 https: //docs. microsoft. com/ja-jp/azure-functions/functions-create-first-azure-function https: //docs. microsoft. com/ja-jp/azure-functions/functions-create-scheduled-function 27

28
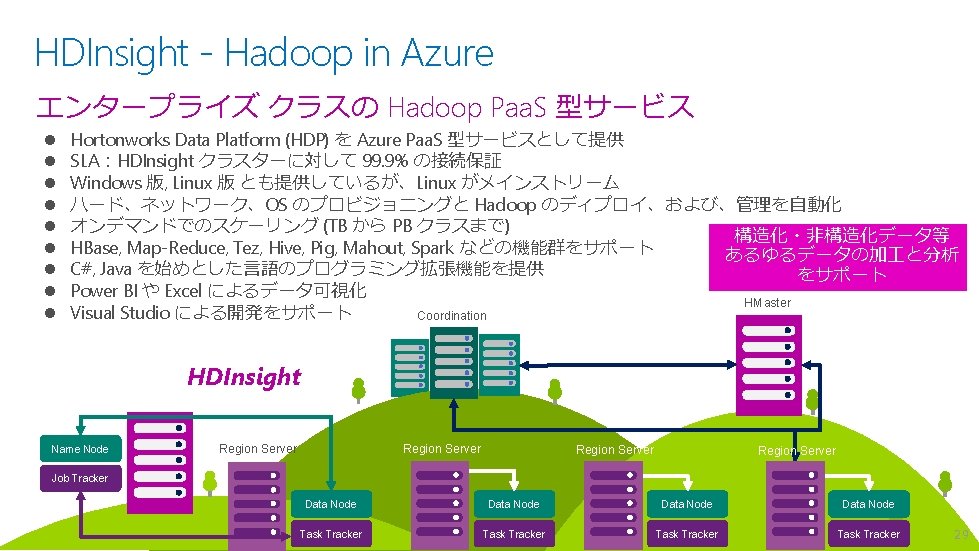

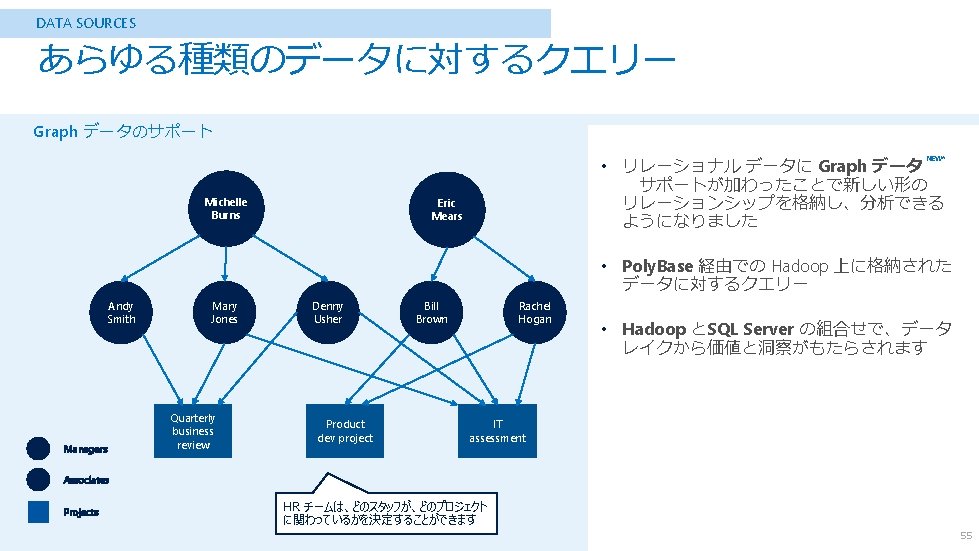
HDInsight の位置づけ Operational Analytical Streaming HDInsight HBase Non-Relational Map. Reduce/Tez Hive/Pig Spark Mahout . . . Document. DB Data Lake Tables Machine Learning SQL Database SQL Data Warehouse Storm Spark Streaming Event Hubs Stream Analytics 30

HDInsight のアーキテクチャ Map. Reduce/Tez HBase Hive/Pig Spark Mahout Storm . . . HDInsight Cluster HDFS stores big unstructured files Hadoop Distributed File System (HDFS) API Azure Blobs Called Azure Storage Blobs (WASB) Data Lake Store (無制限 HDFS Storage) も選択可能 31
")
Spark in HDInsight 実践編 -1 https: //docs. microsoft. com/ja-jp/azure/hdinsight/spark/apache-spark-jupyter-spark-sql Spark on HDInsight を使ってみる (1) – 導入 32
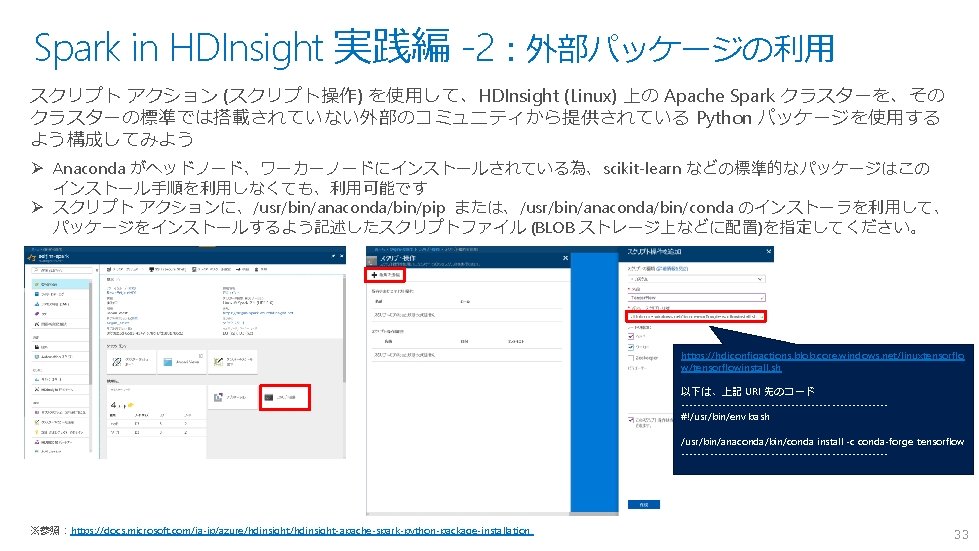

Spark in HDInsight 実践編 -3 • Jupyter Notebook import print( as 'Hello, Tensor. Flow!' ) 34
 としては、従来の RDD (Resilient")
Spark in HDInsight 実践編 -4:RDD を使ってみよう Py. Spark で利用可能な分散メモリ データセット (非永続ストレージ) としては、従来の RDD (Resilient Distributed Datasets) の他に、Spark から提供される (pandas. Data. Frame ではない) Data. Frames があります。 Data. Frames は、RDD より高速で、かつ、テーブル型で SQL ライクなメソッドを持つなど、高機能であり、 今後は、Data. Frames が主流になって行きます。 Spark では、Machine Learning ライブラリとして、spark. mllib と spark. ml の2つがありますが、前者が RDD、 後者が Data. Frames に対応しています。RDD と Data. Frames の関係同様、今後は、spark. ml が主流になって 行く予定です。 # Use Hive Context sql. Context = Hive. Context(sc) # Create Data. Frame from Hive table data df = sql. Context. sql("SELECT * FROM hivesampletable") # Show schema df. print. Schema() # Filter df. filter(df["country"] == "Japan"). count() # Group By df. group. By("country"). count(). show() # Filter df. filter(df["country"] == "Japan"). show() # Count df. count() ※参照:https: //spark. apache. org/docs/1. 6. 0/sql-programming-guide. html#Data. Frames 35

Spark in HDInsight 実践編 -5:Hive に保存してみよう CSV ファイルを RDD に読み込んだ後、Data. Frames に変換して、ODBC や JDBC でアクセス可能な Hive テーブルとして保存することが可能です。 from pyspark. sql import * # Use Hive Context sql. Context = Hive. Context(sc) # Create an RDD from sample data hvac. Text = sc. text. File("wasbs: ///Hdi. Samples/Sensor. Sample. Data/hvac/HVAC. csv") # Create a schema for our data Entry = Row('Date', 'Time', 'Target. Temp', 'Actual. Temp', 'Building. ID') # Parse the data and create a schema hvac. Parts = hvac. Text. map(lambda s: s. split(', ')). filter(lambda s: s[0] != 'Date') hvac = hvac. Parts. map(lambda p: Entry(str(p[0]), str(p[1]), int(p[2]), int(p[3]), int(p[6]))) # Infer the schema and create a table hvac. Table = sql. Context. create. Data. Frame(hvac) hvac. Table. register. Temp. Table('hvactemptable') dfw = Data. Frame. Writer(hvac. Table) dfw. save. As. Table('hvac. Table. Seijim') 「hvactableseijim」という名称のテーブルとして保存 %%sql SELECT Building. ID, MIN(Actual. Temp) min. Temp, MAX(Actual. Temp) max. Temp, AVG(Actual. Temp) avg. Temp FROM hvac. Table. Seijim GROUP BY Building. ID ORDER BY avg. Temp DESC LIMIT 10 Hive テーブルの実体(データファイル配置先) 36
")
Spark in HDInsight 実践編 -6:JDBC で SQLDB にアクセス Spark 2. 1 (HDInsight 3. 6) では、”/usr/hdp/2. 6. 2. 3 -1/hive/lib” ディレクトリ以下に、SQL Server 用の JDBC Driver (sqljdbc 41. jar) がインストール済みの為、JDBC 接続文字列だけですぐに利用可能です。 SQL Server Management Studio で 事前に作成したテーブルとデータ from pyspark. sql import * # Use Sql. Context sql. Context = SQLContext(sc) # Load from RDB table using JDBC jdbc. Url = “jdbc: sqlserver: //******. database. windows. net: 1433; database=******; user=******; password=******" table. Name. Query = "(SELECT * FROM test. T 1 WHERE mykey = '1') t 1“ # Sub query df = sql. Context. read. format('jdbc'). options( url=jdbc. Url, dbtable=table. Name. Query ). load() df. show() # Create a new Data. Flame data = [("101", "Delaware"), ("102", "Virginia"), ("103", "Maryland"), ("104", "South Carolina")] rdd = sc. parallelize(data) Entry = Row("mykey", "myvalue") t 1_rdd = rdd. map(lambda p: Entry(str(p[0]), str(p[1]))) t 1_df = sql. Context. create. Data. Frame(t 1_rdd) t 1_df. show() # Write to RDB table using JDBC # - mode # append: Append contents of this : class: Data. Frame to existing data. # overwrite: Overwrite existing data. # ignore: Silently ignore this operation if data already exists. # error (default case): Throw an exception if data already exists. table. Name = "test. T 1" t 1_df. write. jdbc(url=jdbc. Url, table=table. Name, mode="append") # Show result df = sql. Context. read. format('jdbc'). options( url=jdbc. Url, dbtable=table. Name ). load() df. show() 対象の SQLDW / SQLDB から Data. Frame へ の読み込み。パラメータの dbtable は、 SELECT 文 の FROM 句としての記述である為、 テーブル名以外に、サブクエリを記述可能。 Data. Frame として作成したコレクション (INSERT 先のテーブルのカラム名やデータ型 は、合わせておく必要あり) をテーブルに 追加する例。 パラメータの mode=“overwrite” を指定する と、既存のテーブルが DROP されるので、注 意が必要。 37

Spark in HDInsight 実践編 -7 38
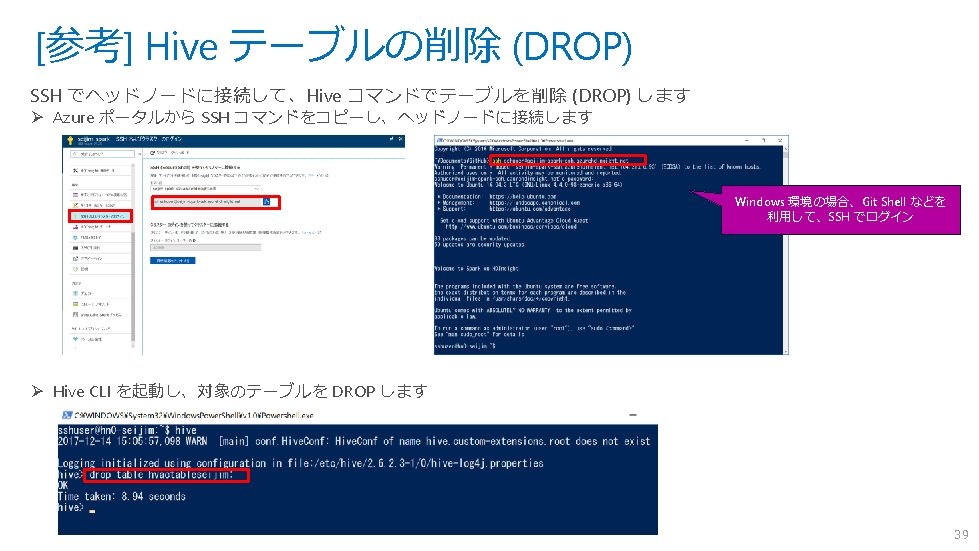
![[参考] Hive テーブルへのデータロード SSH でヘッドノードに接続して、Hive コマンドでテーブルにデータをロードします Ø Azure ポータルから SSH コマンドをコピーし、ヘッドノードに接続します(前頁参照) Ø Hive CLI](http://slidetodoc.com/presentation_image/4293561c8f97a5729d88f9aba6d9fb72/image-40.jpg "[参考] Hive テーブルへのデータロード SSH でヘッドノードに接続して、Hive コマンドでテーブルにデータをロードします Ø Azure ポータルから SSH コマンドをコピーし、ヘッドノードに接続します(前頁参照) Ø Hive CLI")
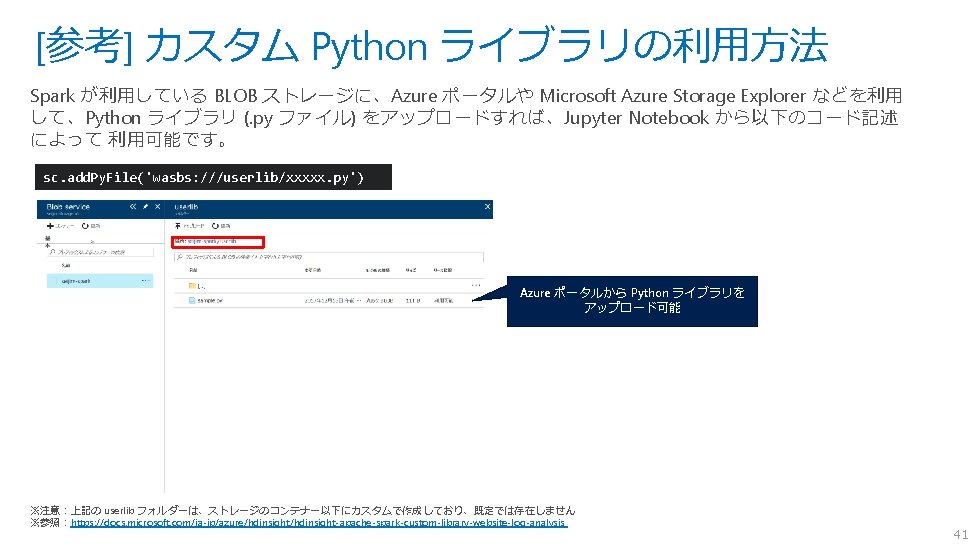
[参考] Hive テーブルへのデータロード SSH でヘッドノードに接続して、Hive コマンドでテーブルにデータをロードします Ø Azure ポータルから SSH コマンドをコピーし、ヘッドノードに接続します(前頁参照) Ø Hive CLI を起動し、テーブル (以下例では “T 1”) を作成します -- Create Table CREATE TABLE IF NOT EXISTS T 1 ( key 1 INT, data 1 STRING, datetime 1 TIMESTAMP ) PARTITIONED BY (dt STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY ', ' STORED AS TEXTFILE; Ø Spark が利用している BLOB ストレージに、Azure ポータルや、Microsoft Azure Storage Explorer 、 Az. Copy などを 利用して、データファイル (CSV, TSV など) をコピーします Ø Hive CLI コマンドを利用して、データをロードします (圧縮ファイルも指定可能です) -- Load Data (Partition 4) LOAD DATA INPATH 'wasbs: ///userdata/data_p 4. csv. gz' OVERWRITE INTO TABLE T 1 PARTITION (dt='2017 -04 -01'); -- Load Data (Partition 5) LOAD DATA INPATH 'wasbs: ///userdata/data_p 5. csv. gz' OVERWRITE INTO TABLE T 1 PARTITION (dt='2017 -05 -01'); -- Show Result SELECT * FROM T 1; OK 1 お試し1 2017 -04 -02 15: 30: 24 2017 -04 -01 2 お試し2です 2017 -04 -09 17: 13: 55 2017 -04 -01 11 お試しパーティション2個目です。その1 2017 -05 -09 14: 23: 52 12 お試しパーティション2個目です。その2 2017 -05 -21 09: 15: 36 データ内容 2017 -05 -01 ※参照:https: //docs. microsoft. com/ja-jp/azure/machine-learning-data-science-move-hive-tables#a-nameload-dataaload-data-to-hive-tables ※構文やデータ型の詳細:https: //cwiki. apache. org/confluence/display/Hive/Language. Manual+DDL#Language. Manual. DDL-Create. Table. Create/Drop/Truncate. Table 40

42

SQL Server 2017 Industry-leading performance on the most secure data platform, with built-in intelligence for all your data 7 年間で最も脆弱性が少ない 最高 100 万回/秒 の予測性能 あらゆるデータ, あらゆる言語, あらゆるプラットフォームに対応 Native R and Python integration Java, PHP, node. js, . NET A L H P SA e. S AN Q 2 gr Po st cle DB M IB Q y. S M rv Se L ra L 200 180 160 140 120 100 80 60 40 20 0 SQ #1 リアルタイム インテリジェンス er Vulnerabilities (2010 -2016) TPC-E, TPC-H で No. 1 の性能 あらゆるアプリケーションに 世界最高の安全性 O 世界最高の性能 オンプレミスからクラウドまで、最も一貫したエクペリエンスを提供 あらゆる状況下で、最高の TCO を実現
")
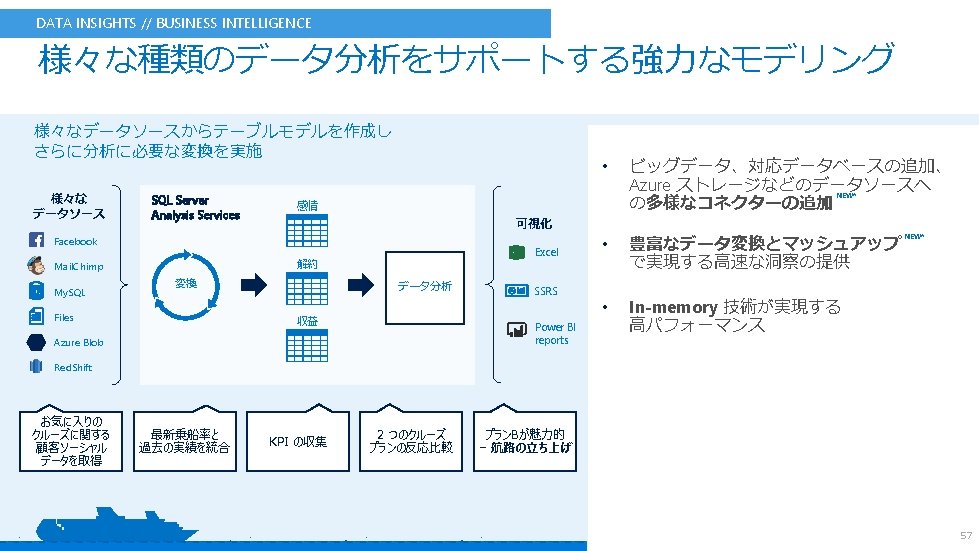
ML Services : リアルタイム AI の実現 従来のアプリケーションを使いながら、最先端の AI を実現 l オペレーショナル データで学習 (GPU 利用のディープラーニングも対応) l ストアド プロシージャでスコアリング (予測, 自動化) 2 1 Application 3 Stored Proc call Results SQL Server 2017 SQL Server Machine Learning Services R/Python Runtimes Execution The stored procedure contains R/Python code and executes in-database exec sp_execute_external_script @language = ‘Python’ , @script = -- Python code – exec sp_execute_external_script @language = ‘R’ , @script = -- R code -- 45

46

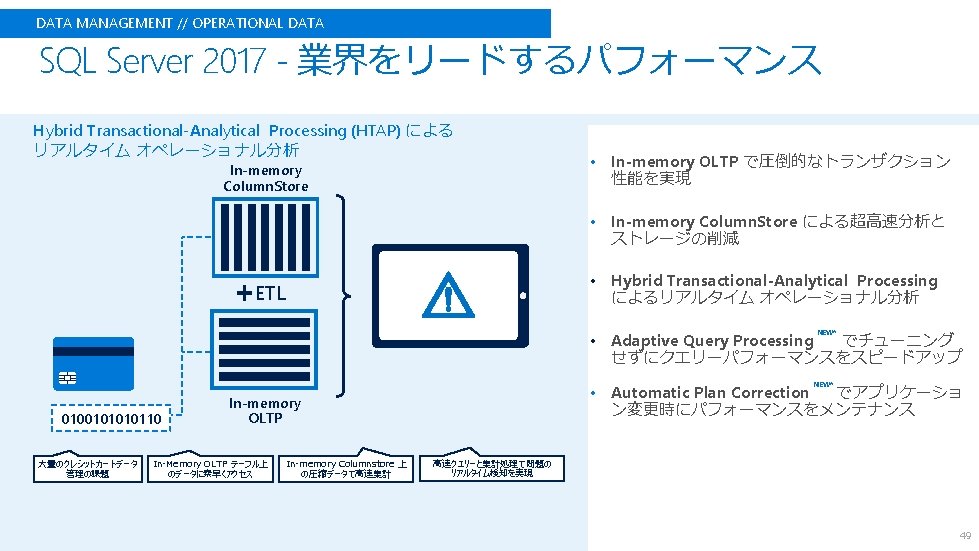
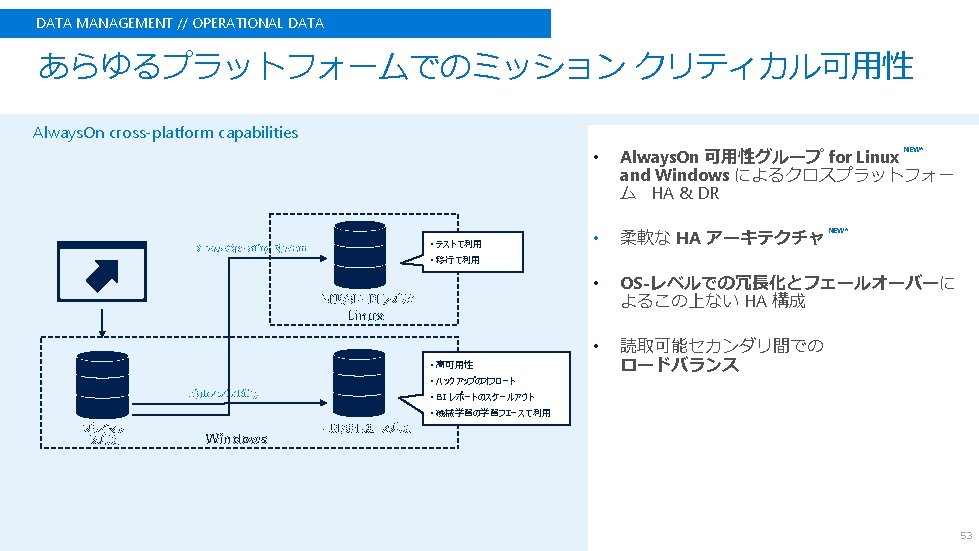
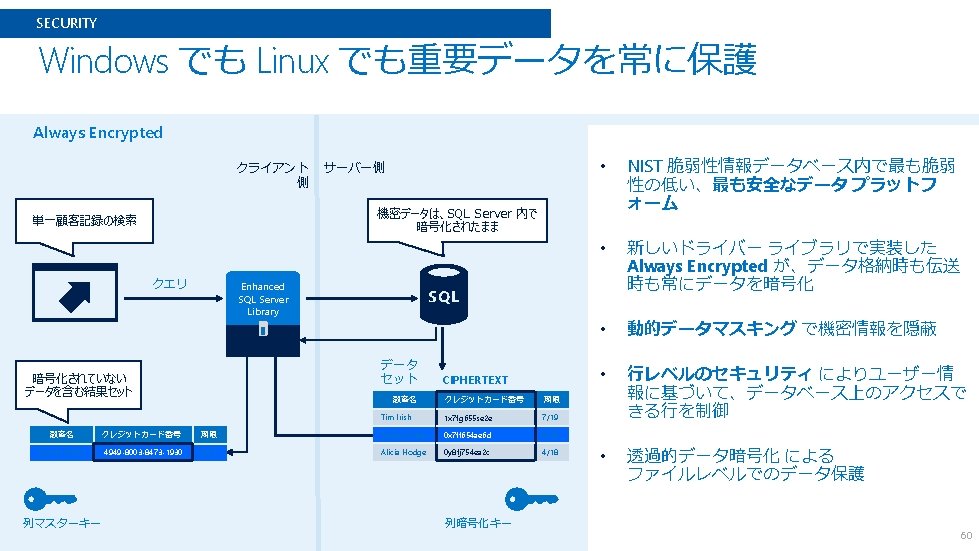
DATA MANAGEMENT // Linux SQL Server 2017 on Linux • SQL Server Operating System (SOS/SQLOS) • 内部抽象化レイヤ - tasks, schedules, memory, … • Drawbridge project • Microsoft Research late 2011 • Application sandboxing – isolating, picoprocesses, library OS, … • SQL Platform Abstraction Layer (SQL PAL) • Shared-disk clustering using Pacemaker • Pacemaker != WSFC • Availability Groups • 全ての機能をサポート • Read-only routing, Auto-seeding, Windows のコードを Linux でも効果的に利用 Distributed/subnets, Failover options OSS を効果的に利用 47

• • • What operational features are available on Linux? • • • 48
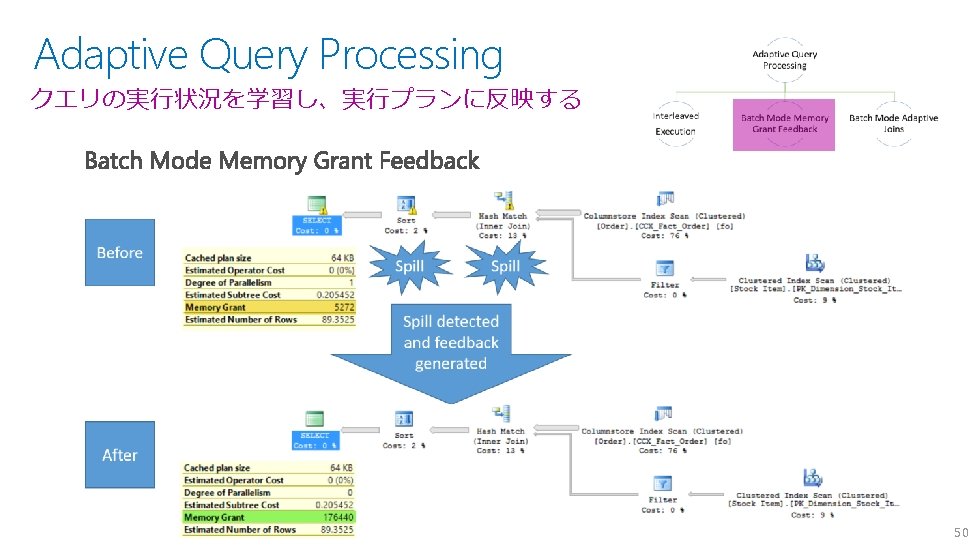

Automatic Tuning Query Store の情報に基づいて、最も良好だった最新の実行プランを適用 Detect with dm_db_tuning_recommendations and force manually Turn on Auto and system corrects Reverts back to “last known good” 52

DATA MANAGEMENT // DATA WAREHOUSING ペタバイト スケールのデータウェアハウス #1 performance and value for TPC-H 1 TB benchmark non-clustered SQL Server 2017 on Red Hat Enterprise Linux and HPE Proliant hardware GREAT PERFORMANCE HPE server with SQL Server 2016 on Microsoft Windows GREAT VALUE 1 TB world record benchmark で最も効率的なクエリー処理 • Windows と Linux でペタバイト スケールのデータウェアハウス (Data Warehouse Fast Track Reference Architecture) • TPC-H #1 price/performance 717, 101 QUERY PER HOUR (QPHH) 678, 492 #1 $/QUERY PER HOUR ($/QPHH) #1 • HPE server with SQL Server 2017 on Red Hat Enterprise Linux $0. 64 HPE server with SQL Server 2016 on Microsoft Windows $0. 61 • HPE server with SQL Server 2017 on Red Hat Enterprise Linux Read the performance brief at hpe. com/servers/benchmarks. Microsoft and Windows are U. S. registered trademarks of Microsoft Corporation. Red Hat, Red Hat Enterprise Linux, and the Shadowman logo are registered trademarks of Red Hat, Inc. Linux is a registered trademark of Linus Torvalds. Intel and Xeon are trademarks of Intel Corporation in the U. S. and other countries. TPC and TPC-H are trademarks of the Transaction Processing Performance Council. TPC-H results show the HPE Pro. Liant DL 380 Gen 9 with a result of 717, 101 Qph. H @ 1000 GB and $0. 61/Qph. H USD with system availability as of 10 -19 -2017 (results published 04 -19 -2017; see http: //www. tpc. org/xxxx ); the HPE Pro. Liant DL 380 Gen 9 with a result of 678, 492 Qph. H @1000 GB and $0. 64/Qph. H @ 1000 GB with system availability as of 07 -31 -2016 (results published 03 -24 -2016; see tpc. org/3320). The TPC believes that comparisons of TPC-H results published with different scale factors are misleading and discourages such comparisons. Please see tpc. org for up-to-date information. Competitive claims valid as of 04 -19 -2017. NEW* (1 TB, 10 TB, 30 TB の非クラスターカテゴリー) 主要ハードウェアパートナーから提供され るリファレンスアーキテクチャ 54
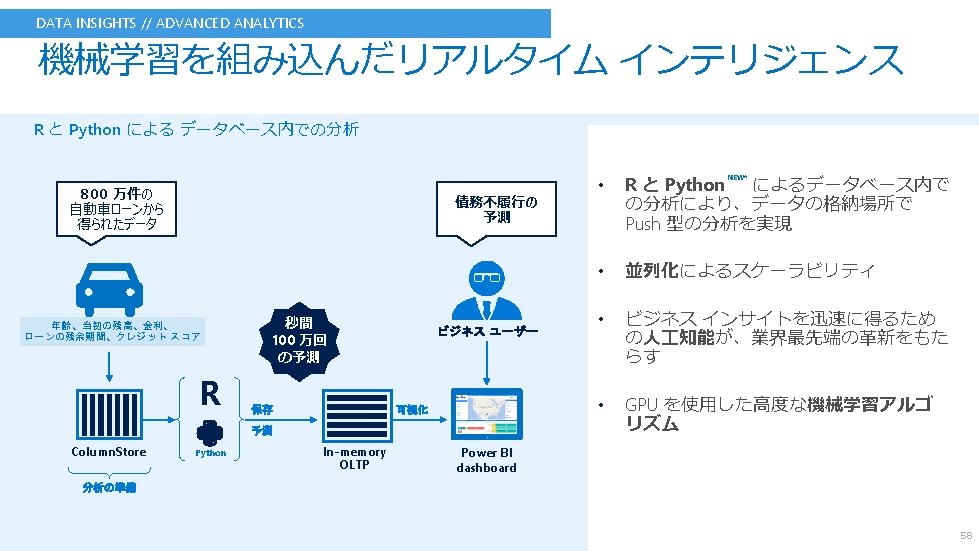

Windows Job Object process pool conhost. exe Local User Account conhost. exe This is all local! MSSQLLAUNCHPAD Service SID MSSQLSERVER Service SID launchpad. exe sqlservr. exe sp_execute_external_script compile input data query Send message to pipe Execute input query Push results Pull results interleaved R script rlauncher. dll pipe rlauncher. dll low privileges Open R python 35. dll rterm. exe python. exe rxlink. dll pylink. dll Create. Process pythonlauncher. dll Python script SQLOS XEvent Scale. R Bxl. Server. exe sqlsatellite. dll SNI/TCP – lower level comm (not TDS) Retrieve input rows and params Send back results and output params stdout and stderr Create. Process – named pipe SQLOS XEvent Scale. R Bxl. Server. exe sqlsatellite. dll “satellite” processes Local User Account low privileges 59
,")
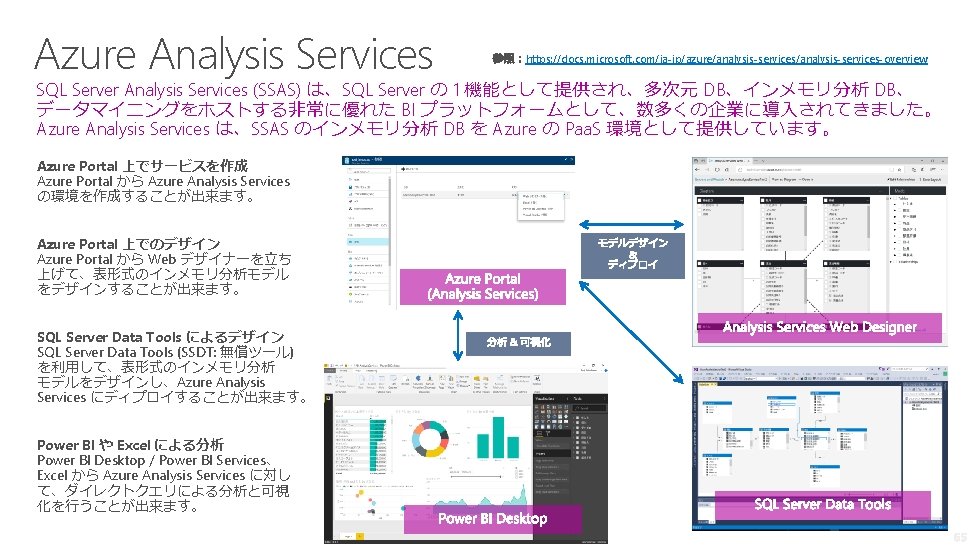
FLEXIBILITY SQL Server 稼働プラットフォームの選択肢 Windows Linux/Windows コンテナ Linux • Red. Hat Enterprise Linux (RHEL), Ubuntu, および SUSE Enterprise Linux (SLES) を含む Linux ディストリビューションのサポート • Windows Server / Windows 10 のサポート • Docker: Windows および Linux コンテナ • パッケージベースのインストール、 yum インストール、Apt-Get, Zypper など 61

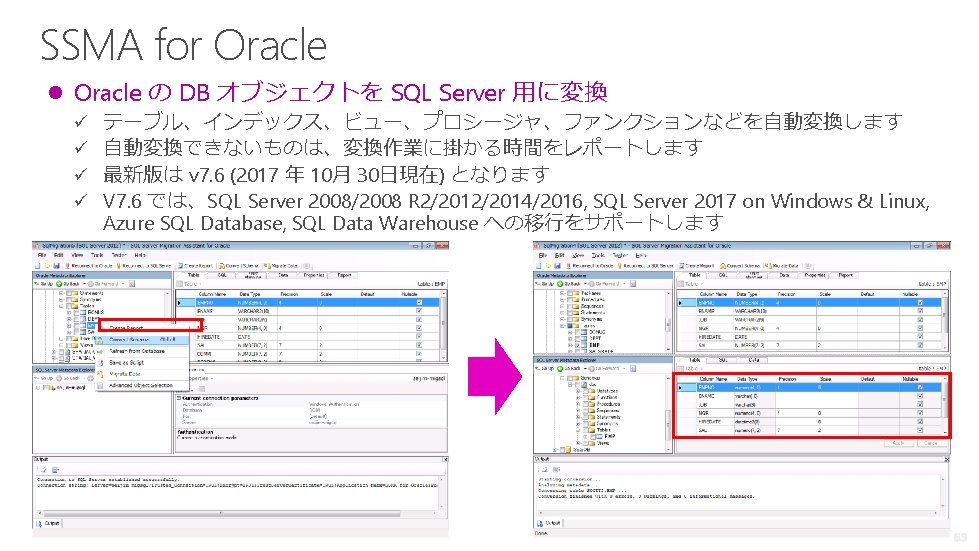
参照:https: //docs. microsoft. com/ja-jp/sql/ssma/sql-server-migration-assistant 62

64

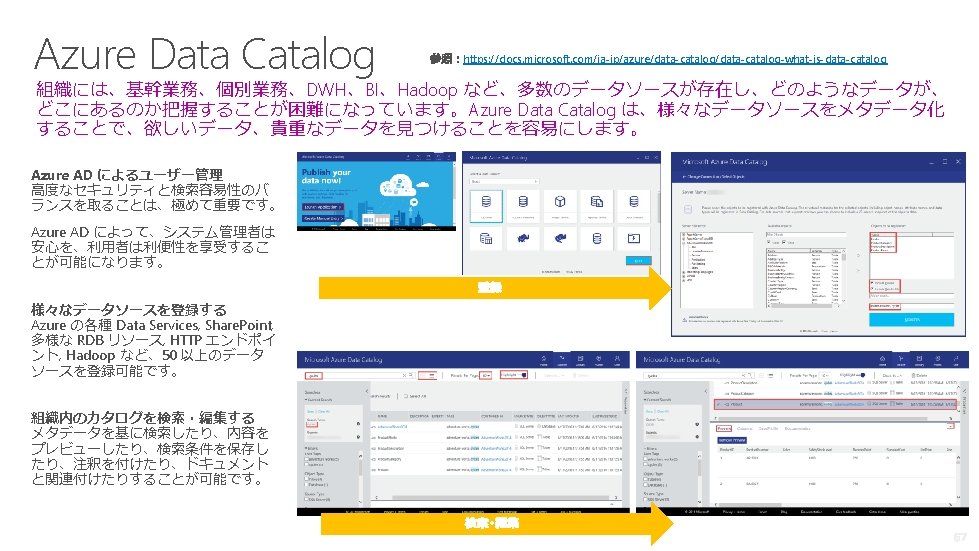

- Slides: 67