Automatic Indexing Automatic Text Processing by G Salton

Automatic Indexing Automatic Text Processing by G. Salton, Addison-Wesley, 1989. 1

Indexing l l l indexing: assign identifiers to text documents. assign: manual vs. automatic indexing identifiers: » objective vs. nonobjective text identifiers cataloging rules define, e. g. , author names, publisher names, dates of publications, … » controlled vs. uncontrolled vocabularies instruction manuals, terminological schedules, … » single-term vs. term phrase 2

Two Issues l Issue 1: indexing exhaustivity » exhaustive: assign a large number of terms » nonexhaustive l Issue 2: term specificity » broad terms (generic) cannot distinguish relevant from nonrelevant documents » narrow terms (specific) retrieve relatively fewer documents, but most of them are relevant 3

Parameters of retrieval effectiveness l Recall l Precision l Goal high recall and high precision 4

b Nonrelevant Items c a Relevant Items d Retrieved Part

A Joint Measure l F-score » is a parameter that encode the importance of recall and procedure. » =1: equal weight » <1: precision is more important » >1: recall is more important 6

Choices of Recall and Precision l l l Both recall and precision vary from 0 to 1. In principle, the average user wants to achieve both high recall and high precision. In practice, a compromise must be reached because simultaneously optimizing recall and precision is not normally achievable. 7
 l l Particular choices of indexing and search")
Choices of Recall and Precision (Continued) l l Particular choices of indexing and search policies have produced variations in performance ranging from 0. 8 precision and 0. 2 recall to 0. 1 precision and 0. 8 recall. In many circumstance, both the recall and the precision varying between 0. 5 and 0. 6 are more satisfactory for the average users. 8

Term-Frequency Consideration l l Function words » for example, "and", "or", "of", "but", … » the frequencies of these words are high in all texts Content words » words that actually relate to document content » varying frequencies in the different texts of a collect » indicate term importance for content 9

A Frequency-Based Indexing Method l l l Eliminate common function words from the document texts by consulting a special dictionary, or stop list, containing a list of high frequency function words. Compute the term frequency tfij for all remaining terms Tj in each document Di, specifying the number of occurrences of Tj in Di. Choose a threshold frequency T, and assign to each document Di all term Tj for which tfij > T. 10
 for term Tj where dfj (document")
Inverse Document Frequency l Inverse Document Frequency (IDF) for term Tj where dfj (document frequency of term Tj) is number of documents in which Tj occurs. » fulfil both the recall and the precision » occur frequently in individual documents but rarely in the remainder of the collection 11

New Term Importance Indicator l weight wij of a term Tj in a document di l Eliminating common function words Computing the value of wij for each term Tj in each document Di Assigning to the documents of a collection all terms with sufficiently high (tf x idf) factors l l 12

Term-discrimination Value l Useful index terms » distinguish the documents of a collection from each other l Document Space » two documents are assigned very similar term sets, when the corresponding points in document configuration appear close together » when a high-frequency term without discrimination is assigned, it will increase the document space density 13

A Virtual Document Space Original State After Assignment of good discriminator After Assignment of poor discriminator 14

Good Term Assignment l l When a term is assigned to the documents of a collection, the few objects to which the term is assigned will be distinguished from the rest of the collection. This should increase the average distance between the objects in the collection and hence produce a document space less dense than before. 15

Poor Term Assignment l l l A high frequency term is assigned that does not discriminate between the objects of a collection. Its assignment will render the document more similar. This is reflected in an increase in document space density. 16

Term Discrimination Value l definition where l dvj = Q - Qj Q and Qj are space densities before and after the assignments of term Tj. dvj>0, Tj is a good term; dvj<0, Tj is a poor term. 17

Variations of Term-Discrimination Value with Document Frequency N Low frequency Medium frequency High frequency dvj=0 dvj>0 dvj<0 18

Another Term Weighting l wij = tfij x dvj l compared with » : decrease steadily with increasing document frequency » dvj: increase from zero to positive as the document frequency of the term increase, decrease shapely as the document frequency becomes still larger. 19
 pairwise similarities l document centroid C =")
Document Centroid l Issue: efficiency problem N(N-1) pairwise similarities l document centroid C = (c 1, c 2, c 3, . . . , ct) l where wij is the j-th term in document i. space density 20

Discussions l l dvj and idfj global properties of terms in a document collection ideal term characteristics that occur between relevant and nonrelevant documents of a collection 21

Probabilistic Term Weighting l l Goal Explicit distinctions between occurrences of terms in relevant and nonrelevant documents of a collection Definition Given a user query q, and the ideal answer set of the relevant documents l From decision theory, the best ranking algorithm 22
, Pr(x|nonrel): occurrence probabilities of document x in")
Probabilistic Term Weighting l l l Pr(x|rel), Pr(x|nonrel): occurrence probabilities of document x in the relevant and nonrelevant document sets Pr(rel), Pr(nonrel): document’s a priori probabilities of relevance and nonrelevance Further assumptions Terms occur independently in relevant documents; terms occur independently in nonrelevant documents. 23
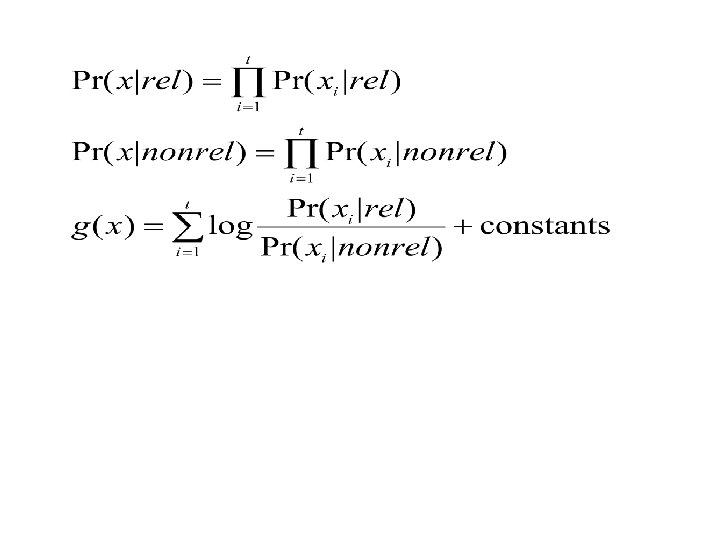

Derivation Process 25
, the retrieval value of D")
Given a document D=(d 1, d 2, …, dt), the retrieval value of D is: where di: term weights of term xi.

Assume di is either 0 or 1. 0: i-th term is absent from D. 1: i-th term is present in D. pi=Pr(xi=1|rel) 1 -pi=Pr(xi=0|rel) qi=Pr(xi=1|nonrel) 1 -qi=Pr(xi=0|nonrel)

")
The retrieval value of each Tj present in a document (i. e. , dj=1) is: term relevance weight

New Term Weighting l l l term-relevance weight of term Tj: trj indexing value of term Tj in document Dj: wij = tfij *trj Issue It is necessary to characterize both the relevant and nonrelevant documents of a collection. how to find a representative document sample feedback information from retrieved documents? ? 30

Estimation of Term-Relevance l Little is known about the relevance properties of terms. » The occurrence probability of a term in the nonrelevant documents qj is approximated by the occurrence probability of the term in the entire document collection qj = dfj / N » The occurrence probabilities of the terms in the small number of relevant documents is equal by using a constant value pj = 0. 5 for all j. 31

When N is sufficiently large, N-dfj N, = idfj 32

Estimation of Term-Relevance l Estimate the number of relevant documents rj in the collection that contain term Tj as a function of the known document frequency tfj of the term Tj. p j = rj / R qj = (dfj-rj)/(N-R) R: an estimate of the total number of relevant documents in the collection. 33

Term Relationships in Indexing l Single-term indexing » Single terms are often ambiguous. » Many single terms are either too specific or too broad to be useful. l Complex text identifiers » subject experts and trained indexers » linguistic analysis algorithms, e. g. , NP chunker » term-grouping or term clustering methods 34

Tree-Dependence Model l l Only certain dependent term pairs are actually included, the other term pairs and all higher-order term combinations being disregarded. Example: sample term-dependence tree 35
, (school, girls), (school, boys) (children, girls), (children, boys) (school, girls, boys), (children,")
(children, school), (school, girls), (school, boys) (children, girls), (children, boys) (school, girls, boys), (children, achievement, ability) 36
 37")
Term Classification (Clustering) 37
 l l Column part Group terms whose corresponding column representation reveal")
Term Classification (Clustering) l l Column part Group terms whose corresponding column representation reveal similar assignments to the documents of the collection. Row part Group documents that exhibit sufficiently similar term assignment. 38

Linguistic Methodologies l Indexing phrases: nominal constructions including adjectives and nouns » Assign syntactic class indicators (i. e. , part of speech) to the words occurring in document texts. » Construct word phrases from sequences of words exhibiting certain allowed syntactic markers (noun-noun and adjective-noun sequences). 39

Term-Phrase Formation l Term Phrase a sequence of related text words carry a more specific meaning than the single terms e. g. , “computer science” vs. computer; Thesaurus transformation Phrase transformation Document Frequency N 40
 a term")
Simple Phrase-Formation Process l l l the principal phrase component (phrase head) a term with a document frequency exceeding a stated threshold, or exhibiting a negative discriminator value the other components of the phrase medium- or low- frequency terms with stated co-occurrence relationships with the phrase head common function words not used in the phrase-formation process 41

An Example l Effective retrieval systems are essential for people in need of information. » “are”, “for”, “in” and “of”: common function words » “system”, “people”, and “information”: phrase heads 42

The Formatted Term-Phrases effective retrieval systems essential people need information 2/5 5/12 *: phrases assumed to be useful for content identification 43

The Problems l l A phrase-formation process controlled only by word cooccurrences and the document frequencies of certain words in not likely to generate a large number of high-quality phrases. Additional syntactic criteria for phrase heads and phrase components may provide further control in phrase formation. 44

Additional Term-Phrase Formation Steps l l Syntactic class indicator are assigned to the terms, and phrase formation is limited to sequences of specified syntactic markers, such as adjective-noun and noun-noun sequences. Adverb-adjective adverb-noun The phrase elements are all chosen from within the same syntactic unit, such as subject phrase, term phrase, and verb phrase. 45

Consider Syntactic Unit l l effective retrieval systems are essential for people in the need of information subject phrase » effective retrieval systems l verb phrase » are essential l term phrase » people in need of information 46
![Phrases within Syntactic Components [subj effective retrieval systems] [vp are essential ] for [obj](http://slidetodoc.com/presentation_image_h/dcc754e21e314eca845d8488bdca91dc/image-47.jpg "Phrases within Syntactic Components [subj effective retrieval systems] [vp are essential ] for [obj")
Phrases within Syntactic Components [subj effective retrieval systems] [vp are essential ] for [obj people need information] l l Adjacent phrase heads and components within syntactic components » retrieval systems* » people need » need information* 2/3 Phrase heads and components co-occur within syntactic components » effective systems 47

Problems l l More stringent phrase formation criteria produce fewer phrases, both good and bad, than less stringent methodologies. Prepositional phrase attachment, e. g. , The man saw the girl with the telescope. l Anaphora resolution He dropped the plate on his foot and broke it. 48
 l Any phrase matching system must be able to deal with the")
Problems (Continued) l Any phrase matching system must be able to deal with the problems of » synonym recognition » differing word orders » intervening extraneous word l Example » retrieval of information vs. information retrieval 49

Equivalent Phrase Formulation l l Base form: text analysis system Variants: » » l system analyzes the text is analyzed by the system carries out text analysis text is subjected to system analysis Related term substitution » text: documents, information documents » analysis: processing, transformation, manipulation » system: program, process 50

Thesaurus-Group Generation l Thesaurus transformation » broadens index terms whose scope is too narrow to be useful in retrieval » a thesaurus must assemble groups of related specific terms under more general, higher-level class indicators Phrase transformation Thesaurus transformation Document Frequency N Low frequency Medium frequency High frequency dvj=0 dvj>0 dvj<0 51

Sample Classes of Roget’s Thesaurus 52

Methods of Thesaurus Construction l l l dij: value of term Tj in document Di sim(Tj, Tk): similarity measure between Tj and Tk possible measures 53

Term-classification strategies l single-link Each term must have a similarity exceeding a stated threshold value with at least one other term in the same class. Produce fewer, much larger term classes l complete-link Each term has a similarity to all other terms in the same class that exceeds the threshold value. Produce a large number of small classes 54
 l l l Identify the individual words in the document")
The Indexing Prescription (1) l l l Identify the individual words in the document collection. Use a stop list to delete from the texts the function words. Use an suffix-stripping routine to reduce each remaining word to wordstem form. For each remaining word stem Tj in document Di, compute wij. Represent each document Di by Di=(T 1, wi 1; T 2, wi 2; …, Tt, wit) 55

Word Stemming l l l effectiveness --> effective --> effect picnicking --> picnic king --> k 56

Some Morphological Rules l l l Restore a silent e after suffix removal from certain words to produce “hope” from “hoping” rather than “hop” Delete certain doubled consonants after suffix removal, so as to generate “hop” from “hopping” rather than “hopp”. Use a final y for an I in forms such as “easier”, so as to generate “easy” instead of “easi”. 57
 l l l l Identify individual text words. Use stop")
The Indexing Prescription (2) l l l l Identify individual text words. Use stop list to delete common function words. Use automatic suffix stripping to produce word stems. Compute term-discrimination value for all word stems. Use thesaurus class replacement for all low-frequency terms with discrimination values near zero. Use phrase-formation process for all high-frequency terms with negative discrimination values. Compute weighting factors for complex indexing units. Assign to each document single term weights, term phrases, and thesaurus classes with weights. 58

Query vs. Document l Differences » Query texts are short. » Fewer terms are assigned to queries. » The occurrence of query terms rarely exceeds 1. Q=(wq 1, wq 2, …, wqt) where wqj: inverse document frequency Di=(di 1, di 2, …, dit) where dij: term frequency*inverse document frequency 59

Query vs. Document l When non-normalized documents are used, the longer documents with more assigned terms have a greater chance of matching particular query terms than do the shorter document vectors. or 60

Relevance Feedback l l Terms present in previously retrieved documents that have been identified as relevant to the user’s query are added to the original formulations. The weights of the original query terms are altered by replacing the inverse document frequency portion of the weights with term-relevance weights obtained by using the occurrence characteristics of the terms in the previous retrieved relevant and nonrelevant documents of the collection. 61

Relevance Feedback l l Q = (wq 1, wq 2, . . . , wqt) Di = (di 1, di 2, . . . , dit) New query may be the following form Q’ = a{wq 1, wq 2, . . . , wqt}+ {w’qt+1, w’qt+2, . . . , w’qt+m} The weights of the newly added terms Tt+1 to Tt+m may consist of a combined term-frequency and termrelevance weight. 62

Final Indexing l l l l Identify individual text words. Use a stop list to delete common words. Use suffix stripping to produce word stems. Replace low-frequency terms with thesaurus classes. Replace high-frequency terms with phrases. Compute term weights for all single terms, phrases, and thesaurus classes. Compare query statements with document vectors. Identify some retrieved documents as relevant and some as nonrelevant to the query. 63

Final Indexing l l l Compute term-relevance factors based on available relevance assessments. Construct new queries with added terms from relevant documents and term weights based on combined frequency and term-relevance weight. Return to step (7). Compare query statements with document vectors ……. . 64

Summary of expected effectiveness of automatic indexing l l l Basic single-term automatic indexing Use of thesaurus to group related terms in the given topic area +10% to +20% Use of automatically derived term associations obtained from joint term assignments found in sample document collections 0% to -10% Use of automatically derived term phrases obtained by using cooccurring terms found in the texts of sample collections +5% to +10% Use of one iteration of relevant feedback to add new query terms extracted from previously retrieved relevant documents +30% to +60% 65
- Slides: 65