Automatic Derivation and Verification of Synchronization Aspects in






 Sync. Gen Demonstration More Back-end translations: Lock-free translations, CAN Synchronization in component-oriented")

; rc : = rc +")
; r. p( ); mx 1.")

 1. Andrews’ Global Invariant (GI) approach 2. Aspect-oriented programming • Rational")
 approach 1. Specify a safety property of synchronization using")


 f( ) c 1. signal( ); c")
; Si;")

 Analysis/design models (How) Component")
 Use-case realizations (scenarios) Classes/objects")

 –")






; y : =")


 synchronized methods lock wait( ); notify( ); notify.")

 { synchronized")



 Generic. Job and override execute( ) 2. Devide")
 Linux running on MHz Xeon processors")

: at most n threads can be in R In. R Region")
: at most k threads can")
: threads can be in at most one region")
, (RC, NC), n): Initially, there are n resource items in the")
, (R 2, N 2), …, (Rn, Nn)): all Ni")

 ∧ Exclusion(Rw,")


, (R 2 , N")

 Roller Coaster Ride Problem There are n passengers and one roller")
![Scenarios for the coaster problem Car Thread Passenger thread [C 1] Wait until C](https://slidetodoc.com/presentation_image/b75267bf72277bf46139d2e00eb86489/image-53.jpg "Scenarios for the coaster problem Car Thread Passenger thread [C 1] Wait until C")

 Multiple Coaster Cars Problem Generalize the previous problem to contain M cars.")



![Scenarios Parent Bird [P 1] wait until a baby bird finds the dish empty](https://slidetodoc.com/presentation_image/b75267bf72277bf46139d2e00eb86489/image-59.jpg "Scenarios Parent Bird [P 1] wait until a baby bird finds the dish empty")


![Scenarios Consumer Producer [C 1] wait until the producer writes a message to the](https://slidetodoc.com/presentation_image/b75267bf72277bf46139d2e00eb86489/image-62.jpg "Scenarios Consumer Producer [C 1] wait until the producer writes a message to the")

 Fall 2001 Total 35 students (mostly graduate students)")
 1. Presented a methodology to develop concurrent programs in a scenariobased")
 Synchronization Aspect Specification")



![Concurrent Entering in Shared Memory Algorithms - Concurrent Entering - Proposed by Joung [1998],](https://slidetodoc.com/presentation_image/b75267bf72277bf46139d2e00eb86489/image-70.jpg "Concurrent Entering in Shared Memory Algorithms - Concurrent Entering - Proposed by Joung [1998],")
 wait unlock() Traditional monitor solution Path without waiting")























 BMDevice")




![Cool: Coordination Aspect Language -Based on Aspect. J [C. Lopes and G. Kiczales 1997]](https://slidetodoc.com/presentation_image/b75267bf72277bf46139d2e00eb86489/image-100.jpg "Cool: Coordination Aspect Language -Based on Aspect. J [C. Lopes and G. Kiczales 1997]")
![Bounded Buffer in Java class Bounded. Buffer { Object[] array; int put. Ptr =](https://slidetodoc.com/presentation_image/b75267bf72277bf46139d2e00eb86489/image-101.jpg "Bounded Buffer in Java class Bounded. Buffer { Object[] array; int put. Ptr =")
![Functional code Bounded. Buffer { public void push (Object o) { array[put. Ptr] =](https://slidetodoc.com/presentation_image/b75267bf72277bf46139d2e00eb86489/image-102.jpg "Functional code Bounded. Buffer { public void push (Object o) { array[put. Ptr] =")
 { while (used. Slots == array. length) { try")


![Synchronizers Frolund and Agha [1993] Synchronizers observe messages flowing between actors Maintains local state](https://slidetodoc.com/presentation_image/b75267bf72277bf46139d2e00eb86489/image-106.jpg "Synchronizers Frolund and Agha [1993] Synchronizers observe messages flowing between actors Maintains local state")


 { init amount : =")
![Composition Filters [AT 98] class Sync. Stack interface { : : inputfilters sync: Wait=](https://slidetodoc.com/presentation_image/b75267bf72277bf46139d2e00eb86489/image-110.jpg "Composition Filters [AT 98] class Sync. Stack interface { : : inputfilters sync: Wait=")
![Superimposition [L. Bouge 88][Chandy & Misra 88] Superimpose control computation on some basic computation](https://slidetodoc.com/presentation_image/b75267bf72277bf46139d2e00eb86489/image-111.jpg "Superimposition [L. Bouge 88][Chandy & Misra 88] Superimpose control computation on some basic computation")
![Basic computation protocol: *[ Bguard 1 a 1: < Bcompute 1> [] Bguard 2](https://slidetodoc.com/presentation_image/b75267bf72277bf46139d2e00eb86489/image-112.jpg "Basic computation protocol: *[ Bguard 1 a 1: < Bcompute 1> [] Bguard 2")


- Slides: 115
Automatic Derivation and Verification of Synchronization Aspects in Object Oriented Systems Gurdip Singh Masaaki Mizuno Kansas State University This research was in supported in part by DARPA PCES Order K 203/AFRL #F 3361500 -C-3044 and NSF CRCD #EIA-9980321
Why aspect oriented Programming? -“Code tangling”: * code for a requirement is spread through many classes; * cross-cutting * code for different requirements are tangled -Programs are hard to maintain * modifying code for a specific requirement is not easy * redundancy
Aspect-Oriented Programming - Solution: * separate software into functional code and aspect code * Develop functional code independently * Develop code for each aspect separately * Weave functional code with aspect code
AOP Ordinary Program Better structured program Functional code Code for aspect 1 Code for aspect 2
Aspect-Oriented Programming - Solution: * separate software into functional code and aspect code * Develop functional code independently * Develop code for each aspect separately * Weave functional code with aspect code - Untangles code, eliminates redundancy - Code is easy to maintain and modify - Customized versions of software
Contents Why aspect oriented methodology ? Synchronization * Is it an aspect ? * Why should we treat it as an aspect ? An aspect oriented methodology * Andrew’s Global Invariant Approach * UML-based methodology * Translation for Java shared memory programs * Pattern-based approach * Examples
Contents (contd) Sync. Gen Demonstration More Back-end translations: Lock-free translations, CAN Synchronization in component-oriented embedded software Bottom-up methodologies * COOL * Composition Filters * Synchronizers * Superimposition Wrap-up
Synchronization The importance of concurrent programming has increased However, many programmers and designers are not appropriately trained to write correct and efficient concurrent programs Most OS textbooks teach ad-hoc techniques – Showing solutions in low-level synchronization primitives for a small number of well-known problems, such as readers/writers and dining philosophers problems – Such solutions do not generalize to complex real-life synchronization problems in various primitives
Readers/Writers with weak readers preference Reader: mx. p( ); rc : = rc + 1; if rc = 1 then wrt. p( ); mx. v( ); reading mx. p( ); rc : = rc – 1; if rc = 0 then wrt. v( ); mx. v( ); Writer: wrt. p( ); writing wrt. v( ); wrt W W R R mx W R R
Readers/writers with writers preference Reader mx 3. p( ); r. p( ); mx 1. p( ); rc : = rc + 1; if rc = 1 then w. p( ); mx 1. v( ); r. v( ); mx 3. v( ); reading mx 1. p( ); rc : = rc – 1; if rc = 0 then w. v( ); mx 1. v( ); Writer mx 2. p( ); nw : = nw + 1; if nw = 1 then r. p( ); mx 2. v( ); w. p( ); writing w. v( ); mx 2. p( ); nw : = nw – 1; if nw = 0 then r. v( ); mx 2. v( ); Courtois et. al, CACM 1971
The goals of our approach We need a more formal and structured approach to develop concurrent programs The methodology must be easy to use The resulting code must be efficient Our methodology is – based on global invariant approach, – in the aspect oriented programming paradigm – in the context of scenario based development methodologies (such as Rational Unified Process (RUP))
Outline (part 1) 1. Andrews’ Global Invariant (GI) approach 2. Aspect-oriented programming • Rational Unified Process (RUP) 3. Our concurrent program development methodology 4. Translations to find-grained synchronization code 5. 6. • Java synchronized blocks • Thread-pool model Pattern-based approach • Basic synchronization patterns and solution invariants • Composition of patterns • Applications of patterns Evaluation and Conclusion
Greg Andrew’s Global Invariant (GI) approach 1. Specify a safety property of synchronization using a global invariant (GI) e. g. , readers/writers problem Let nr be the number of readers currently reading Let nw be the number of writers currently writing Then, the GI may be
2. Mechanically derive a coarse-grained solution from the invariant Coarse grained solution links GI to the program in highlevel synchronization construct n <await B n <S > S> <await TRUE e. g. , nr must be incremented when a thread starts reading and decremented when a thread completes reading. < await > reading
3. Mechanically translate the coarse-grained solution to various fine-grained synchronization code in n Semaphores, n Monitors, n Active Monitors (message passing), n Java Synchronized Blocks, n Thread-Pool Model, etc. Each translation is guaranteed to preserve GI; therefore, the resulting code satisfies the safety property
e. g. , Monitor lock g( ) f( ) c 1. signal( ); c 1. wait( ); … c 2. wait( ); c 1 c 2 x, y, z Monitor = class + mutex + condition
e. g. , Monitor < await while not Bi do Ci. wait( ); Si; < Sj > Sj Add Ck. signal( ) or Ck. signal. All( ) if execution of Si can potentially change the value of Bk to TRUE
Aspect Oriented Programming Properties to be implemented are classified into 1. Component which can be clearly encapsulated in a generalized procedure (i. e. , object, method, procedure, etc) 2. Aspect which cannot be clearly encapsulated in a general procedure (i. e. , synchronization, distribution, etc) This approach reduces complexity and code-tangling by separating cross-cutting concerns. We use • scenario based development methodology (i. e. , RUP) for component code development • GI approach for synchronization aspect code development
Rational Unified Process Actors Classes Use-case realizations Use-case model (What) Analysis/design models (How) Component code implementation
Rational Unified Process (RUP) Use-case realizations (scenarios) Classes/objects
Automatic Call Distribution System Need to wait
Threads A scenario is translated into a sequence of method calls (sequential program) – One program for the operator scenario – Another for the external call scenario Instantiate one thread for each operator phone and external line An advantage of concurrent programs: each activity can be written as a sequential program
Synchronization regions and clusters Synchronization region in use-case realization: – a thread waits for some event to occur or some state to hold – a thread may trigger an event or change a state for which a thread in some synchronization region is waiting Cluster: Partition of synchronization regions based on their reference relations
Rational Unified Process with synchronization aspect code development wakeup wait wakeup Identifying synchronization regions and clusters
Our development methodology RUP Actors Classes Use-cases Scenarios Specify a global invariant for each cluster Global invariants (patterns) Component code In scenarios, identify synchronization regions in which synchronization is required Coarsegrained solution Synchronization aspect code development Fine-grained code Complete code
Scenarios When an external call arrives 1. Record the arrival time 2. Wait until an operator becomes ready 3. {connected to an operator} record information for log When external call terminates 1. {external call has terminated} wait until the operator hangs up When an operator becomes free 1. Wait until an external call arrives 2. {connected to an external call} record the connection time and operator’s ID When the operator hangs up 1. {Operator has hung up} wait until the external call terminates 2. {external call has terminated} record the call termination time and log the record
Scenarios When an external call arrives 1. Record the arrival time 2. Wait until an operator becomes ready 3. {connected to an operator} record information for log When external call terminates 1. {external call has terminated} wait until the operator hangs up When an operator becomes free 1. Wait until an external call arrives 2. {connected to an external call} record the connection time and operator’s ID When the operator hangs up 1. {Operator has hung up} wait until the external call terminates 2. {external call has terminated} record the call termination time and log the record
Scenarios When an external call arrives 1. Record the arrival time 2. Call to the generated function 3. {connected to an operator} record information for log When external call terminates 1. Call to the generated function When an operator becomes free 1. Call to the generated function 2. {connected to an external call} record the connection time and operator’s ID When the operator hangs up 1. Call to the generated function 2. {external call has terminated} record the call termination time and log the record
Code Weaving Process scenario Region R Component code a. fun( ); y : = y + 3; . . M. eneter( ); buf [head] : = x; head : = (head+1)%N. . M. exit( ); . . x : = x + 2; m. g( ); Aspect code in instance M enter( ); exit( );
Anonymous and Specific Synchronization • Anonymous Synchronization: among anonymous threads (i. e. , any thread can synchronize with any other threads in the cluster) A single instance of fine-grained solution (synchronization code) is created and all the threads execute in the instance • Specific Synchronization: among a set of specific threads (called a group) multiple instances of the fine-grained solution are created, one for each group; all threads in the same group use the instance assigned to it. anonymous group 1 group 2 …. group. N
Translation to Java Synchronized Blocks Review of Java Synchronization Primitives • Object has a lock and one condition variable a. synchronized(obj) { critical section. may call obj. wait( ), obj. notify. All( ) } b. type method(…) { synchronized (this) { body of method } } is equivalent to synchronized type method(…) { body of method } • All threads in the same cluster sleep in the same condition variable
Java monitor Specific Notification (Cargill, 1996) synchronized methods lock wait( ); notify( ); notify. All( ); Condition lock c 1. wait( ); c 1. notify( ); c 2. wait( ); c 1 c 2 Condition
Our Translation to Java Synchronized Blocks 1. For each cluster, define one java class 2. For < await Bi → S i > 1. private Object oi = new Object( ); 2. pubic void methodi( ) { synchronized (o i) { while (! check. Bi( )) try {oi. wait( ); } catch (Interrupted. Exception e) { } } } 3. private synchronized Boolean check. B i ( ) { if (B i) { S i; return true; } else return false; }
3. 4. For <Sj > 1. public void method j ( ) { synchronized (this) { Sj; } } If execution of Si (or Sj) potentially change some Bk to ture, add 1. synchronized (ok) {ok. notify( ); }, or 2. synchronized (ok) {ok. notify. All( ); } Correctness: 1. Bi; Si; and Sj are all executed in synchronized (this) blocks 2. Nesting level of synchronized blocks is at most two; the order is always block on ok being outside and block on this inside. 3. oi. wait( ); is executed within a sole synchronized block on oi 4. Checking Bi and execution of oi. wait( ) are protected inside synchronized block on oi No missed notification.
Translation to Thread-Pool Model Thread-Pool model • It is widely used in web-servers and embedded systems • The system maintains a pool (pools) of job threads. When a request arrives, it is passed to a free job thread in the pool • When an execution needs to be blocked, synchronization code releases and returns the executing thread to the thread pool, rather than blocking the thread. This is not a context switch, rather a return from a function and a new call. • It is easy to remove blocked jobs from the system since no threads are associated with the jobs
Job objects and thread pools 1. A job object inherits Generic. Job and implements execute( ) 2. Thread. Pool maintains job. Queue (queue of Generic. Job) and provides the two operations void add. Job(Generic. Job job) {<job. Queue. enqueue(job)>} Generic. Job get. Job( ) { <await (not job. Queue. is. Empty( )) → return job. Queue. dequeu( )> } 3. Job threads execute the following code whlie(true){(thread. Pool. get. Job( )). execute( ); } job. Queue Generic. Job execute( ); blocked threads at <await>
Translation Algorithm 1. Declare one monitor for each cluster. 2. For each < await Bi →Si >, • declare queuei (queue of Generic. Job) • declare g. Methodi boolean g. Methodi(Generic. Job job) { if (not Bi) {queuei. enqueue(job); return false; } Si; return true; } 3. For each < Sj >, • declare ng. Methodj void ng. Methodj ( ) { Sj; } 4. Add singalk() after Si wherever necessary void signalk( ) { while ((not queuek. is. Empty( )) ∧Bi) { Si; thread. Pool. add. Job(queuei. dequeue( )); } }
Job objects 1. Inherit (or implement) Generic. Job and override execute( ) 2. Devide the scenario into phases by each appearance of 3. <await> statement 3. Body of execute( ) is switch (phase) { case 0: sequential code derived for phase 0 section of the scenario if (not synch. Object. g. Method 1(this))_{phase = 1; return; } case 1: …. }
Performance Evaluation (Jacobi Iteration 1000 x 1000) Linux running on MHz Xeon processors
Synchronization patterns • One possible drawback of GI approach is the difficulty to identify an appropriate global invariant that correctly and accurately implies the safety property of the synchronization requirement. • To cope with this problem, we have developed a set of useful synchronization patterns and their solution invariants.
Bound(R, n): at most n threads can be in R In. R Region R Out. R
K_Mu. Tex(R 1, R 2, …, Rn, k): at most k threads can be in (any) regions R 1 R 2 … Rn
Exclusion(R 1, R 2, …, Rn): threads can be in at most one region out of n regions n e. g. , Comb(3, 2) = {(1, 2), (1, 3), (2, 3)} R 1 R 2 … Rn
Resource((RP , NP), (RC, NC), n): Initially, there are n resource items in the resource pool. • When a thread executes RP , it produces NP resource items. • When a thread executes RC, it consumes NC items. If there are less than NC items in the pool, a thread trying to enter RC waits until there at least NC items in the pool RP , NP n RC , NC
n. Barrier((R 1, N 1), (R 2, N 2), …, (Rn, Nn)): all Ni threads in Ri (1 i n) meet, form a group, and leave the respective regions together e. g. , R 1 , N 1 R 2 , N 2 … Rn, Nn
n Asym. Barrier: Asymmetric version of Barrier, where entries of threads to a set of regions trigger departures of threads from a set of regions e. g. , R 1 , 2 R 2 , 3
Composition of patterns 1. Composition of invariants • Readers/Writers problem Bound(Rw, 1) ∧ Exclusion(Rw, RR) • Producers/Consumers with n-bounded buffer Resource((RP , 1), (RC , 1), 0) ∧Resource((RC , 1), (RP , 1), n) ∧ Bound(RP , 1) ∧Bound(RC , 1)
• Search, insert, and delete: Three kinds of threads share access to a singly linked list: searchers, inserters, and deleters • Searchers can execute concurrently with other searchers • Inserters must be mutually exclusive with other inserters • One inserter can proceed in parallel with multiple searchers • At most one deleter can access the list and must be mutually exclusive with searchers and inserters Bound(RI , 1) ∧Bound(RD , 1) ∧Exclusion(RD , RS) ∧ Exclusion(RD , RI)
2. Composition of sub-clusters • Readers/Writers problem Bound RR RW Exclusion RW RR Exclusion (1) (2)
• Information Exchanging Barrier ((R 1 , N 1), (R 2 , N 2), …(RN , NN) Bound (R 1 , N 1) Bound (R 2 , N 2) write (R 1 , N 1) (R 2 , N 2) read (R 1 , N 1) read (R 2 , N 2) Bound (RN , NN) …. . Barrier write (RN , NN) read (RN , NN)
Observation 1. When multi-stage synchronization is needed, composition of sub-clusters must be used (e. g. , Information Exchanging Barrier) 2. Composition of invariants may be viewed as a special case of composition of sub-clusters, in which all In counters of the sub-regions are incremented atomically, and so are the Out counters. • When the atomicity is not required, synchronization using composition of global invariants may be realized by composition of sub-clusters 3. Composition of sub-clusters has an advantage; we can construct a library of fine-grained implementation of the basic patterns.
Examples 1. (A) Roller Coaster Ride Problem There are n passengers and one roller coaster car. • The car holds C passengers and can go around the track only when it is full. The car takes T seconds to go around the track. • The passengers repeatedly wait to take rides in the car. After getting a ride, each passenger wanders around the amusement park for a random amount of time before returning to the coaster for another ride.
Scenarios for the coaster problem Car Thread Passenger thread [C 1] Wait until C passengers have gotten on the car [C 2] Go around the track (elapse T seconds) [C 3] Stop and have the passengers get off the car [C 4] Wait until all C passengers have left [P 1] Wait until his/her turn comes and get on the car [P 2] Wait until the car goes around and stops [P 3] Get off the car [P 4] Wander around the amusement park Synchronization regions and appropriate patterns Steps [C 1] and [P 1]: Barrier((RC 1, 1), (RP 1, C)) Steps [C 3] and [P 2]: Asym. Barrier([(RC 3, 1)], [(RP 2, C)]) Steps [C 4] and [P 3]: Asym. Barrier([(RP 3, C)], [(RC 4, 1)])
Coaster Thread Barrier C 1 Passenger Thread RC 1 RP 1 1 C P 1 C 2 Asym. Barrier P 4 C 3 RP 2 1 C C 4 RP 3 1 C P 2 P 3
1. (B) Multiple Coaster Cars Problem Generalize the previous problem to contain M cars. For passenger safety, only one car at a time is permitted to go around the track
Coaster Thread Info Exchanging Barrier C 1 C 2 Bound Passenger Thread RC 1 RP 1 1 C P 1 P 4 Rc 2 P 2 Specific Asym. Barrier C 3 RP 2 1 C C 4 RP 3 1 C P 3
Coaster Thread C 1 Info Exchanging Barrier Bound Passenger Thread RC 1 RP 1 1 C P 1 Rc 2 C 2 P 4 P 2 Specific Asym. Barrier C 3 RP 2 1 C C 4 RP 3 1 C P 3
2. Hungry Birds Problem Given are N baby birds and one parent bird. There is a dish which initially contains F portions of food. • Each baby bird repeatedly fetches one portion of food at a time, eats it, sleeps for a while, and then comes back to eat. If the dish becomes empty when a baby bird picks up food, he awakens the parent bird. • When the parent bird wakes up, it finds F portions of food, puts them in the dish, and goes back to sleep.
Scenarios Parent Bird [P 1] wait until a baby bird finds the dish empty [P 2] find F portions of food and put them in the dish [P 3] inform the waiting baby bird Baby Bird [B 1] sleep for a while [B 2] check if the dish is (was) empty (n = 0) [B 3] if so, wait until parent places F portions of food in the dish [B 4] set n : = F [B 5] pick up one portion of food in the dish (n : = n – 1) [B 6] check whether the dish becomes empty (n = 0) [B 7] if so, inform parent [B 8] eat food
parent baby B 1 B 2 Asym. Barrier P 1 B 3 P 2 B 4 B 5 B 6 B 7 P 3 B 8 Bound
3. Atomic Broadcasting One producer and n consumers share a buffer. The producer deposits messages into the buffer, and consumers fetch them. Every message deposited by the producer has to be fetched by all n consumers before the producer can deposit another message into the buffer. The producer should not be blocked by consumers until right before it actually deposits a message.
Scenarios Consumer Producer [C 1] wait until the producer writes a message to the buffer [P 1] wait until n consumers have read the message from the buffer (first time, this step is skipped: staggering property) [C 2] read the message [C 3] notify the producer [P 2] write a message [P 3] notify n consumers Cluster [C 3, P 1]: staggered Asym. Barrier Cluster [P 3, C 1]: Asym. Barrier
Consumer n Consumer 2 Consumer 1 Producer …. Write Read
Evaluation CIS 720 (Advanced Operating Systems) Fall 2001 Total 35 students (mostly graduate students) A. Questionnaire 1 2 3 4 5 (easiest) Ave. (most difficult) Ad-hoc 6 7 10 2 0 2. 3 GI no patterns 1 2 8 11 2 3. 5 GI with patterns 0 1 3 7 13 4. 3 B. Exams Exam 1 (covered ad-hoc, GI without patterns): average 62. 1 Final Exam (covered GI with patterns): average 87. 2
Conclusion (part 1) 1. Presented a methodology to develop concurrent programs in a scenariobased development approach (such as RUP), in the aspect oriented programming paradigm. • Structured, high-level, based on theoretical foundation provided by Global Invariant approach • Aspect synchronization codes are obtained mechanically from invariants 2. Presented translation algorithms for Java synchronized blocks and threadpool model 3. Presented a set of synchronization patterns and their solution invariants • Demonstrated the effectiveness by applying them to solve various synchronization problems
Tool Architecture UML Tools Functional Core Code Templates (Java, C++, …) Synchronization Aspect Specification Tool Invariant & Region tags Intermediate Representation Generator Solver/ Prover Functional Core Code Template Instantiation (Java, C++, …) Traditional Development Environment Course-grain solution Synchronization Fine-grain Aspect solution Back-end Bandera Analysis & Transformation Safety Properties Liveness Properties Bandera Finite State Models Code Weaver Specialization Engine Optimized Woven Code
Verification Read a value from the gyroscope Unsynchronized components Wait until gyroscope value is in buffer Wait until the buffer becomes empty Read value from buffer Write a new value in the buffer Core Code Model Actuate rudder based on value Bandera Use Cases Sync Code Model Named Synchronization Points/Regions Resource(RG, RR , 0) + Resource(RR, RG , 1) + Exclusion(RG, RR) Synchronization Specification System Model Automatic verification of critical safety and liveness properties of woven embedded code … built on top of Bandera
Verification Read a value from the gyroscope Unsynchronized components Wait until gyroscope value is in buffer Wait until the buffer becomes empty Read value from buffer Write a new value in the buffer Core Code Model Actuate rudder based on value Bandera Use Cases Named Synchronization Points/Regions Sync Spec Model Resource(RG, RR , 0) + Resource(RR, RG , 1) + Exclusion(RG, RR) Synchronization Specification Derived from specification System Model IV. Automatic verification of critical safety and liveness properties of woven embedded code RW State space: Full Java: 1, 559, 250 Hybrid: 534
Generating Fine-Grain Solution <await B 1 -> C 1++> Java <await B 2 -> C 2++> C++ Posix Threads <await B 3 -> C 3++> C++ w/ CORBA Event Channel C w/ CAN Message Passing <await B 4 -> C 4++> <await Bn -> Cn++> Back end Translators
Concurrent Entering in Shared Memory Algorithms - Concurrent Entering - Proposed by Joung [1998], Hadzilacos [2001] * If there does not exist a conflicting request, then a request must not be delayed due to any other request. - Algorithms for concurrent entering in Group Exclusion [Joung 88, Hadzilacos 2001]
Concurrent Entering Shared Memory algorithms lock() wait unlock() Traditional monitor solution Path without waiting for other requests Highly concurrent algorithm using fetch-and-add instruction [Singh 02] Algorithm using atomic read/write variables
Message Passing Solutions P 1, …, Pn : processes/components R 1, …, Rm: regions St 1, …, Stn: await statements Stx: <await(Condx) ctx++> Message passing system
Asynchronous message passing systems Extensions of Lamport’s algorithm and Ricart and Agarwala’s algorithm Message passing system
Controller Area Networks Centralized solution Active Monitor proxies Controller Area Network
Controller Area Networks Decentralized solution Controller Area Network
Component-based Programming Integration Infrastructure
Boeing Bold Stroke Platform Periodic & Aperiodic Many Computers Focus Domain Nav Sensors Multiple Safety Criticalities Weapon Management Information Security Multiple Buses Mission Computer Vehicle Mgmt Weapons Hard & Soft Real-Time Constrained Tactical Links Data Links Radar COTS O(106) Lines of Code
Control-Push Data-Pull Structure 1. Logical GPS component receives a periodic event indicating that it should read the physical GPS device. 2. Logical GPS publishes DATA_AVAILABLE event 3. Airframe component fetches GPS data by calling GPS Get. Data method 4. Airframe updates its position data and publishes DATA_AVAILABLE event 5. Nav. Display component fetches Air. Frame data by calling Air. Frame Get. Data method 6. Nav. Display updates the physical display
System Architecture Event propagation Data propagation Event Service Data Service ORB
Event Service Controller Sensor 1 Actuator 1 Sensor 2 Sensor 3 Actuator 2 Actuator 3 Event Service - One-way communication - Anonymous communication
Existing Development Methodology Bold Stroke Components … XML Configuration Specification Configurator Configured Build Synchronization specifications - component behavior is modified by including control code in the components
Cadena CCM Interface Definition Language CCM IDL 3 level component development <CONFIGURATION_PASS> <HOME> <…> <COMPONENT> <ID> <…></ID> <EVENT_SUPPLIER> <…events this component supplies…> </EVENT_SUPPLIER> </COMPONENT> </HOME> </CONFIGURATION_PASS> XML Configurator Info RT Aspect Specs State Transitions High-level Connection specification System Configuration High-level Specification Language Eclipse Plug-In Integrated Development Environment Analysis and Qo. S Aspect Synthesis
Modal. SP
Three Synchronized Graphical Views View Scenario Description Spreadsheet View Textual View Single Internal Representation
Textual View
Graphical View
Spreadsheet View …ports for component type …port types RT Attributes …distribution sites …rate group …port connections
Aspect Synthesis Dependency-driven rate assignment to event handlers 5 Hz 20 Hz 20 Hz 1 Hz
Specifying Synchronization gps dynamic correlation radar 1 nav. Display airframe 20 hz tracksensor 1 tracksensor 2 Both must be on at the same time tracksensor 3 tracksensor 4 coherent track 1 track 2 track 3 track 4 track 5 track 6 track 7 track 8 track 9 track 10 hud tactical. Display 1 tactical. Steering Mode 1: read from track 1, 2, 4 Mode 2: read from track 1, …, 10 tactical. Display 2 atomic radar
Specifying Synchronization Event-driven system: Components react to events - e. published: number of events of type e published so far - e. notified : number of notifications for event e pushed so far - C. mode: mode of component C - invariant: assertion over publish, notified, mode variables -e 1. notified <= e 2. notified <= e 1. notified + 1 * regulates the flow of notifications of e 1 and e 2 to a component so that these notifications alternate
Tao’s Real Time Event Channel Consumer Proxies Dispatching module Event correlation Subscription and filtering Supplier Proxies Supplier - Filtering and correlation is on per-consumer basis
Event Distribution and Coordination Service Consumer Proxies Dispatching module Event correlation Synch Module derived from the invariant Subscription and filtering Supplier Proxies - Synch_Module can observe the flow of events and control it
New Filtering mechanisms Consumer Proxies 0/1 Dispatching module Event correlation Subscription and filtering Supplier 0/1 Synch Module Update state Supplier Proxies Synch_event are redirected to the Synch_Module Notifications for Synch_notify events are redirected to the Synch_Module
Condition Event Consumer Proxies Dispatching module Event correlation Subscription and filtering Supplier Proxies Synch Module Update state Condition events
Synch Code generation Scenario Specification BMDevice Monolithic. Impl Synch. Specification BMDevice. CCM (context) BMDevice Monolithic. Wrapper Home. CCMObject. Impl Synch_Module Configured Event Service
Existing Development Methodology Bold Stroke Components … XML Configuration Specification Configurator Configured Build Synchronization specifications - component behavior is modified by including control code in the components
Development Methodology Bold Stroke Components … XML Configuration Specification Configurator Synch Module Configured Build Synchronization specifications -Different synchronization specifications result in different Synch_Module
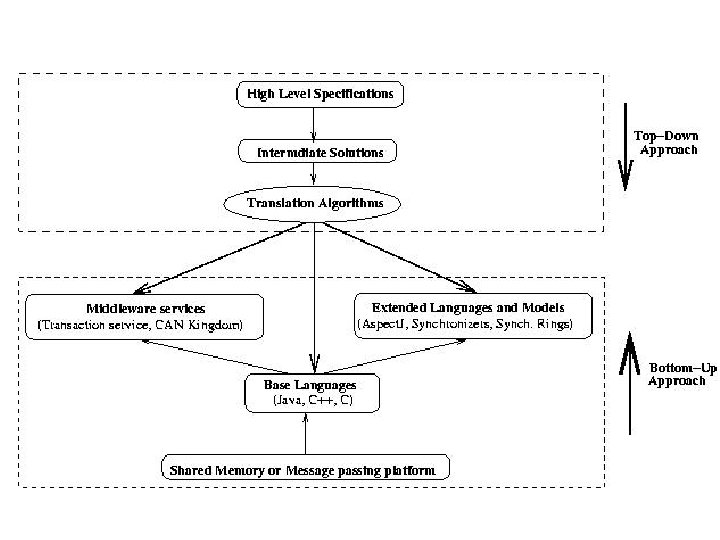
Related Work: - Top down approach vs Bottom-up approach - Complimentary approaches
Bottom-up Approach Cool Synchronizers Composition filters Superimposition
Cool: Coordination Aspect Language -Based on Aspect. J [C. Lopes and G. Kiczales 1997] - Coordinator: coordinates one or more classes * selfexclusive * mutexclusive * condition variables
Bounded Buffer in Java class Bounded. Buffer { Object[] array; int put. Ptr = 0, take. Ptr = 0; int used. Slots = 0; Bounded. Buffer(int capacity){ array = new Object[capacity]; }
Functional code Bounded. Buffer { public void push (Object o) { array[put. Ptr] = o; put. Ptr = (put. Ptr+1)%array. length; used. Slots++; } public Object pop() { Object old = array[take. Ptr]; array[take. Ptr] = null; take. Ptr = (take. Ptr+1)%array. length; used. Slots--; return old; } }
Tangling synchronized void push(Object o) { while (used. Slots == array. length) { try { wait(); } catch (Interrupted. Exception e) {}; } array[put. Ptr] = o; put. Ptr = (put. Ptr +1 ) % array. length; if (used. Slots==0) notifyall(); used. Slots++; if (used. Slots++==0) notifyall(); }
Coordinator coordinator Bounded. Stack. Coord : Bounded. Stack { selfexclusive {pop, push} mutexlcusive {pop, push} cond boolean full= false, empty= true; push : requires !full; on exit { if (sp == Max) full=true; ) if (sp == 1) empty = false; } pop: requires !empty; on exit { if (sp == 0) empty =true; if (sp == Max – 1) full = false } }
Implementation Model Coordinator 2 3 4 1 6 Object 5
Synchronizers Frolund and Agha [1993] Synchronizers observe messages flowing between actors Maintains local state that is changed based on the observations May delay or reorder messages
Synchronizers constraining messages to objects atomicity disabling enabling • message patterns • constraints
Synchronizer for allocation policy for two objects adm 1 and adm 2 Allocation. Policy(adm 1, adm 2, max) { init prev = 0; prev>= max disable (adm 1. request or adm 2. request) updates prev : = prev + 1, (adm 1. release or adm 2. release) updates prev : = prev – 1, }
Vending machine synchronizer Vending. Machine(accepter, applies, bananas, apple_price, banana_price) { init amount : = 0; amount < apple_price disables apples. open, amount < banana_price disables banana. open, accepter. insert(v) updates amount : = amount + v, (accepter. refund or apples. open or bananas. open) updates amount : = 0 }
Composition Filters [AT 98] class Sync. Stack interface { : : inputfilters sync: Wait= {Nonempty=>pop, True=>*pop} }; specifies synchronization constraints -Filters are used to block, buffer and reorder methods
Superimposition [L. Bouge 88][Chandy & Misra 88] Superimpose control computation on some basic computation Basic computation: a set of guarded commands Control computation: a set of guarded command that may access variables of basic computation and may delay the basic computation
Basic computation protocol: *[ Bguard 1 a 1: < Bcompute 1> [] Bguard 2 a 2: < Bcompute 2> [] Bguard 3 a 3: <Bcompute 3> : ] Control protocol: *[ Cguard 1 a 1: < Ccompute 1> [] Cguard 3 a 3: < Ccompute 3> [] : : ] Merged protocol: *[ Bguard 1 / Cguard 1 a 1: <Bcompute 1; Ccompute 1 > [] Bguard 2 a 2: <Bcompute 2> [] Bguard 3 / Cguard 3 a 3: <Bcompute 3; Ccompute 3> : : }
Protocol Composition Bi-directional data transfer Flow control Token-passing
Conclusion Aspect oriented approach to synchronization Sync. Gen Complimentary to bottom-up approach Several back-end translations