Author Saeed Shiry With little change by Keyvanrad

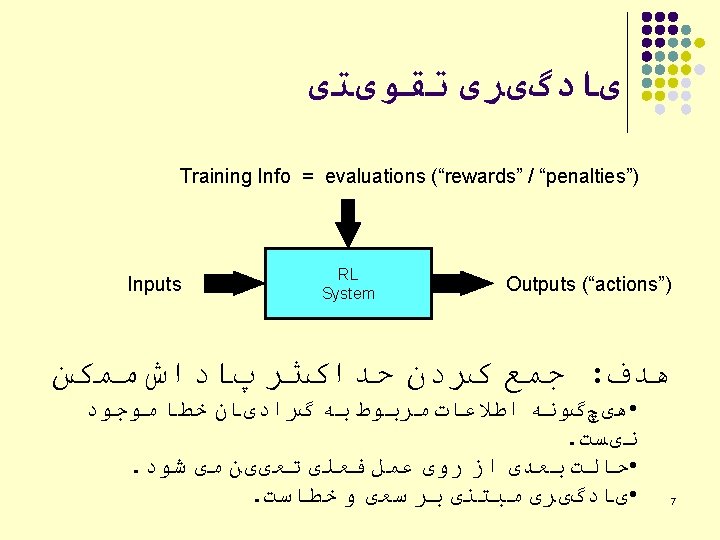
یﺎﺩگیﺮی ﺗﻘﻮیﺘی Author : Saeed Shiry With little change by: Keyvanrad Thanks to: Shiqi Zhang & Mitchell Ch. 13 1393 -1394 (Spring) 1



ﺑﺎ یﺎﺩگیﺮی ﺑﺎ RL ﻣﻘﺎیﺴﻪ ﻧﺎﻇﺮ Supervised Learning: Example Class Reinforcement Learning: … Situation Reward 5
 outputs Inputs Supervised Learning System")
یﺎﺩگیﺮی ﺑﺎ ﻧﺎﻇﺮ Training Info = desired (target) outputs Inputs Supervised Learning System Outputs Error = (target output – actual output) 6

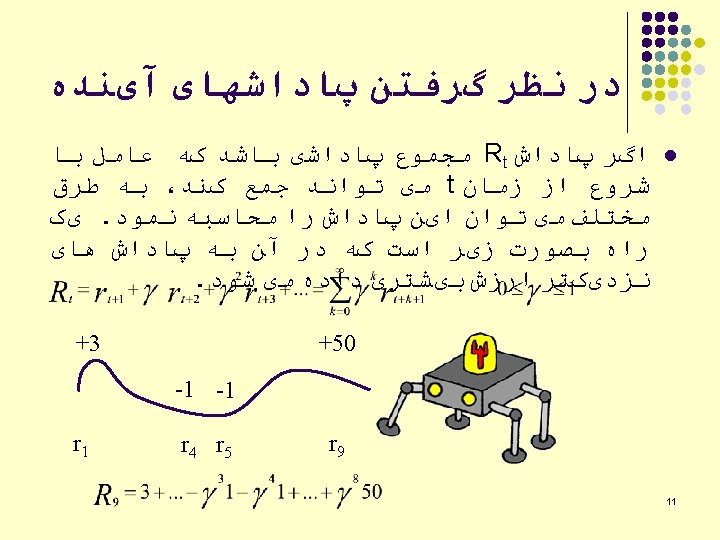




Reinforcement learning example Start S 2 S 4 S 3 Arrows indicate strength between two problem states Start maze … S 8 S 5 S 7 Goal 15

Start S 2 The first response leads to S 2 … S 4 S 3 S 8 S 7 The next state is chosen by randomly sampling from the possible next states weighted by their associative strength Associative strength = line width S 5 Goal 16

Start S 2 S 4 S 3 S 8 S 5 Suppose the randomly sampled response leads to S 3 … S 7 Goal 17

Start S 2 At S 3, choices lead to either S 2, S 4, or S 7. S 4 S 3 S 8 S 5 S 7 was picked (randomly) S 7 Goal 18

Start S 2 By chance, S 3 was picked next… S 4 S 3 S 8 S 5 S 7 Goal 19

Start S 2 Next response is S 4 S 3 S 8 S 5 S 7 Goal 20
 S 4 S 3")
Start S 2 And S 5 was chosen next (randomly) S 4 S 3 S 8 S 5 S 7 Goal 21

Start S 2 And the goal is reached … S 4 S 3 S 8 S 5 S 7 Goal 22

Start S 2 S 4 S 3 S 8 S 5 S 7 Goal is reached, strengthen the associative connection between goal state and last response Next time S 5 is reached, part of the associative strength is passed back to S 4. . . Goal 23

Start S 2 Start maze again… S 4 S 3 S 8 S 5 S 7 Goal 24

Start S 2 S 4 S 3 S 8 S 5 Let’s suppose after a couple of moves, we end up at S 5 again S 7 Goal 25

Start S 2 S 4 S 3 S 8 S 5 S 7 S 5 is likely to lead to GOAL through strenghtened route In reinforcement learning, strength is also passed back to the last state This paves the way for the next time going through maze Goal 26

Start S 2 The situation after lots of restarts … S 4 S 3 S 8 S 5 S 7 Goal 27




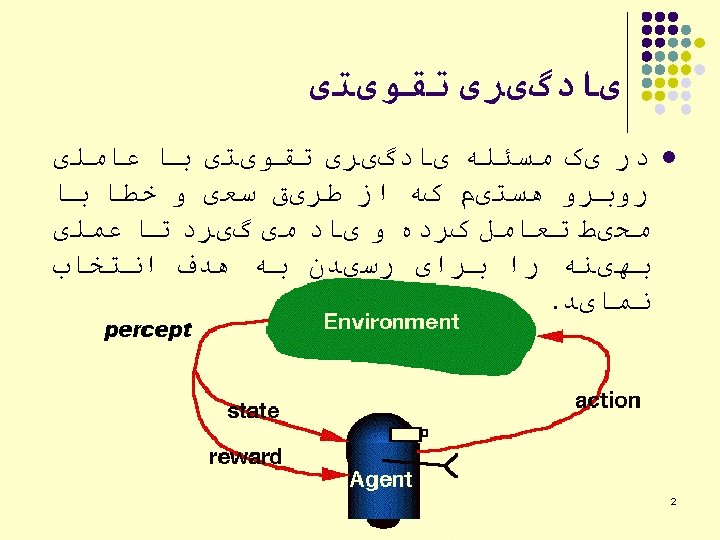
Q ﺍﻟگﻮﺭیﺘﻢ یﺎﺩگیﺮی l l l For each s, a initialize the table entry Observe the current state s Do forever: l Select an action a and execute it receive immediate reward r Observe the new state s’ update the table entry for as follows l s s’ l l l to zero 31
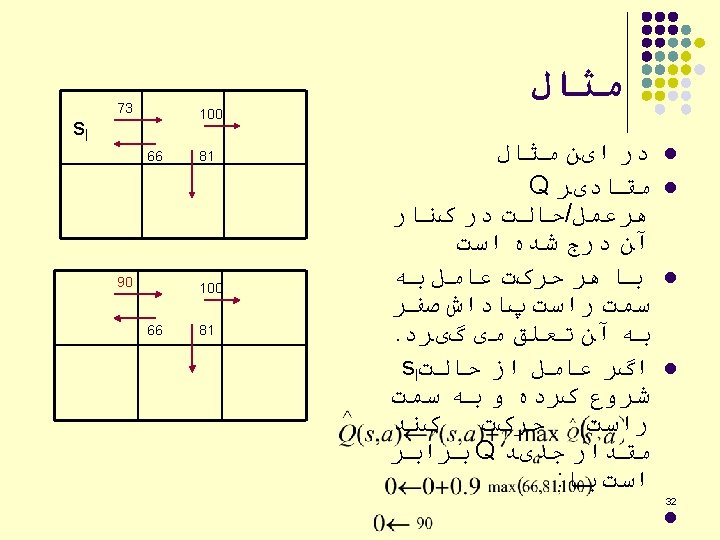



. The aim")
Problem Description l Environment A to E: rooms, F: outside building (target). The aim is that an agent to learn to get out of building from any of rooms in an optimal way. 36

l Modeling of the environment 37

e, Action, Reward and Q-value l Reward matrix 38

l Q-table and the update rule Q table update rule: :learning parameter 39

Q-Learning l l Given : State diagram with a goal state (represented by matrix R) Find : Minimum path from any initial state to the goal state (represented by matrix Q) 1. 2. 3. Set parameter γ , and environment reward matrix R Initialize matrix Q as zero matrix For each episode: ・ Select random initial state ・ Do while not reach goal state ・ Select one among all possible actions for the current state ・ Using this possible action, consider to go to the next state ・ Get maximum Q value of this next state based on all possible actions ・ compute ・ Set the next state as the current state End Do End For 40

Algorithm to utilize the Q table Input: Q matrix, initial state 1. 2. 3. 4. Set current state = initial state From current state, find action that produce maximum Q value Set current state = next state Go to 2 until current state = goal state The algorithm above will return sequence of current state from initial state until goal state. Comments: Parameter γ has range value of 0 to 1( ). If γ is closer to zero, the agent will tend to consider only immediate reward. If γ is closer to one, the agent will consider future reward with greater weight, willing to delay the reward. 41

Numerical Example Let us set the value of learning parameter and initial state as room B. 42
 of matrix R. There are")
Episode 1 Look at the second row (state B) of matrix R. There are two possible actions for the current state B, that is to go to state D, or go to state F. By random selection, we select to go to F as our action. 43

Episode 2 This time for instance we randomly have state D as our initial state. From D; it has 3 possible actions, B, C and E. We randomly select to go to state B as our action. 44
 The next state is B, now become the current state. We")
Episode 2 (cont’d) The next state is B, now become the current state. We repeat the inner loop in Q learning algorithm because state B is not the goal state. There are two possible actions from the current state B, that is to go to state D, or go to state F. By lucky draw, our action selected is state F. No change 45

After Many Episodes If our agent learns more and more experience through many episodes, it will finally reach convergence values of Q matrix as 46

Once the Q matrix reaches almost the convergence value, our agent can reach the goal in an optimum way. To trace the sequence of states, it can easily compute by finding action that makes maximum Q for this state. For example from initial State C, using the Q matrix, we can have the sequences C – D – B – F or C-D-E-F 47
- Slides: 47