Arithmetic Pipeline Pipeline unit for floating point addition



 R 2 memory(address")

















- Slides: 22
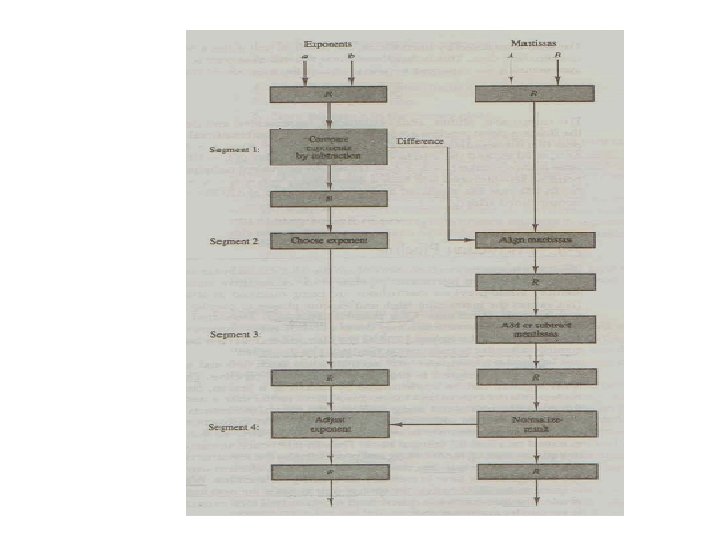
Arithmetic Pipeline • Pipeline unit for floating point addition and subtraction: Inputs are X = A * 2 a & Y = B * 2 b Four segments can be used
RISC pipeline • Simple instruction set so instruction pipeline can be implemented using small no. of suboperations • All data manipulation instructions have register to register operations so no need for calculation of effective addresses or fetching of operands from memory • Instruction pipeline can be implemented using 3 segments
• Instruction cycle of RISC processor can be divided into 3 suboperations and implemented in 3 segments • I : Instruction fetch • A : ALU operation • E : Execute instruction
Delayed load • • LOAD ADD STORE R 1 memory(address 1) R 2 memory(address 2) R 3 R 1 + R 2 memory(address 3) R 3 • If the 3 segment pipeline proceeds without interruption, there will be a data conflict in instruction 3 because the operand in R 2 is not yet available in A segment
Clock cycles 1 1. LOAD R 1 I 2. LOAD R 2 3. ADD R 1+R 2 4. STORE 2 A I 3 E A I 4 5 6 E A I E A E
Clock cycles 1 1. LOAD R 1 I 2. LOAD R 2 3. NO OP 4. ADD R 1+R 2 5. STORE 2 A I 3 E A I 4 E A I 5 6 7 E A I E A E
Delayed branch Clock cycles: 1 2 1. LOAD I A 2. INCR I 3. ADD 4. SUB 5. BRANCH TO X 6. NO OP 7. NO OP 8. INST IN X 3 E A I 4 E A I 5 E A I 6 E A I 7 8 9 10 E A E I A E
Clock cycles: 1 1. LOAD I 2. INCR 3. BRANCH TO X 4. ADD 5. SUB 6. INST IN X 2 A I 3 E A I 4 E A I 5 E A I 6 7 8 E A I E A E
Multiple Processor Organization • • Single instruction, single data stream - SISD Single instruction, multiple data stream - SIMD Multiple instruction, single data stream - MISD Multiple instruction, multiple data stream. MIMD
Single Instruction, Single Data Stream SISD • • Single processor Single instruction stream Data stored in single memory Uni-processor
SISD
Single Instruction, Multiple Data Stream - SIMD • Single machine instruction controls simultaneous execution of number of processing elements • Each processing element has associated data memory • Each instruction executed on different set of data by different processors • Eg. - Vector and array processors
SIMD
Multiple Instruction, Single Data Stream - MISD • A sequence of data is transmitted to set of processors • Each processor executes different instruction sequence • Never been implemented
Multiple Instruction, Multiple Data Stream- MIMD • Set of processors • Simultaneously execute different instruction sequences on different sets of data • SMPs, clusters and NUMA systems
Parallel Organizations - MIMD Shared Memory
Parallel Organizations - MIMD Distributed Memory
Taxonomy of Parallel Processor Architectures
Tightly Coupled - SMP • Processors share memory • Communicate via that shared memory • Symmetric Multiprocessor (SMP) – Share single memory or pool – Shared bus to access memory – Memory access time to given area of memory is approximately the same for each processor
Tightly Coupled - NUMA • Nonuniform memory access • Access times to different regions of memroy may differ
Loosely Coupled - Clusters • Collection of independent uniprocessors or SMPs • Interconnected to form a cluster • Communication via fixed path or network connections