Aristotle University Department of Mathematics Master in Web

Aristotle University, Department of Mathematics Master in Web Science supported by Municipality of Veria Statistics in the Web I. Antoniou, P. Moissiadis, M. Vafopoulos

Contents • • • What is the Web? Web milestones Why is so successful? We knew the web was big. . . Web generations Studying the Web Data and Structure Web Function and Evolution Web policy April 8, 2010 23 rd ESI Conference - Veroia 2
 with unique addresses")
What is the Web? a system of interlinked hypertext documents (html) with unique addresses (URI) accessed via the Internet (http) April 8, 2010 23 rd ESI Conference - Veroia 3
 and Metakides")
Web milestones 1992: TBL presents the idea in CERN 1993: Dertouzos (MIT) and Metakides (EU) create W 3 C appointing TBL as director Two Greeks in the Web’s birth, How many in Web science’s? April 8, 2010 23 rd ESI Conference - Veroia 4
 which is: •")
Why is so successful? Is based on architecture (HTTP, URI, HTML) which is: • • • simple, free or cheap, open source, extensible tolerant networked fun & powerful universal (regardless hardware platform, software platform, application software, network access, public, group, or personal scope, language and culture operating system and ability) April 8, 2010 23 rd ESI Conference - Veroia 5

Why is so successful? • New experience of exploring & editing huge amount of information, people, abilities anytime, from anywhere • The biggest human system with no central authority and control but with log data (Yotta* Bytes/sec) • Has not yet revealed its full potential… *10248 April 8, 2010 23 rd ESI Conference - Veroia 6

We knew the Web was big. . . • • • 1 trillion unique URIs (Google blog 7/25/2008) 2 billion users Google: 300 million searches/day US: 15 billion searches/month 72% of the Web population are active on at least 1 social network … Source blog. usaseopros. com/2009/04/15/google-searches-per-day-reaches-293 million-in-march-2009/ April 8, 2010 23 rd ESI Conference - Veroia 7

Web: the new continent • Facebook: 400 million active users – 50% of our active users log on to Facebook in any given day – 35 million users update their status each day – 60 million status updates posted each day – 3 billion photos uploaded to the site each month • Twitter: 75 million active users – 141 employees • Youtube: 350 million daily visitors • Flickr: 35 million daily visitors April 8, 2010 23 rd ESI Conference - Veroia 8

Web: the new continent • Online advertising spending in the UK has overtaken television expenditure for the first time [4 billion Euros/year] (30/9/2009, BBC) • In US, spending on digital marketing will overtake that of print for the first time in 2010 • Amazon. com: 50 million daily visitors – 60 billion dollars market capitalization – 24. 000 employes April 8, 2010 23 rd ESI Conference - Veroia 9

Web generations eras description basic value source Pre Web 1980’s calculate The desktop is the platform Computations Web 1. 0: 90’s read Surfing Web: The browser is the platform hyper-linking of documents Web 2. 0: 00’s write Social Web: The Web is the platform social dimension of linkage properties Web 3. 0: 10’s discover Semantic Web: The Graph is the platform URI-based semantic linkages Web 4. 0: 20’s execute Metacomputing: The network is the platform Web of things (embedded systems, RFID) Almost everything is (or could be) a Web service Connection & production in a global computing system for everything New inter-creativity Web 2 w Combine all April 8, 2010 [no network effect] 23 rd ESI Conference - Veroia 10

New questions for the Web • • Safe surfing Find credible information Create successful e-business Reduce tax evasion Enable local economic development Communicate with potential voters Find existing research effort in a subject How will answer these questions? April 8, 2010 23 rd ESI Conference - Veroia 11

Studying the Web The Web is the largest human information construct in history. The Web is transforming society… It is time to study it systematically as standalone socio-technical artifact April 8, 2010 23 rd ESI Conference - Veroia 12

Web science timeline 2005: The Web Science Workshop, London • Chairs: Tim Berners-Lee, Wendy Hall • Organizing Committee: J. Hendler, N. Shadbolt, D. Weitzner 11/2006: Web Science Research Initiative is established 2007: “A Framework for Web Science” is published 2007: the book is translated to Greek/introduced in Univ. 4/2008: EU FET workshop in Web science 4/2008: 2 nd Web Science Workshop, China 7/2008: Summer Doctoral Program, Oxford 9/2008: Web science curriculum workshop, UK 9/2008: establishment of W 3 F 2009: 1 st World Conference in Web science 18 -20/3 /2009, Athens Greece www. websci 09. org 10/2009: master in Web science Greece, UK 3/2010: UK gov. invests 40 million euros in WS institute 4/2010: Rensselaer Polytechnic Institute (41 st ranked in US) announce Undergraduate program in Web Science April 8, 2010 23 rd ESI Conference - Veroia 3/18 13

The Web Science framework the basis: • Data Analysis Statistics • Mathematical Models • The “Econometrics” paradigm • Statistics in Economics Initially, not accepted from economists Commerce and Accounting become Economics Now, the base of Economics Evaluation of theories/models about function, structure & evolution of economic phenomena – Public policy and business strategy – – April 8, 2010 23 rd ESI Conference - Veroia 14

Web Data and Structure April 8, 2010 23 rd ESI Conference - Veroia 15

What kind of Data we have from Networks? • Enumerated data. Such data are collected in an exhaustive way from the full population i. e. from all the nodes of the network. – For instance, in some social network studies. such as those that might involve the graduates from a school or a university, it is quite easy to collect data that are uploaded from the members involved. – The same is true for networks of collaborations between researchers or between scientific journals for which there exist databases containing citation indexes and other parameters for a great window of time. April 8, 2010 23 rd ESI Conference - Veroia 16

What kind of Data we have from Networks? • Partial Data. Such data are collected from a full enumeration of only a subset of the population. – For example in order to study the network between users of Aristotle University of Thessaloniki (AUTh) we must collect information for all the nodes-users of AUTh. These data can help the researchers to find out a number of characteristics of the network but fail to handle some others having interaction with other networks. For instance the network traffic collected from this network cannot say anything for the probability of the network to crush out, because all the traffic, not only between the members of AUTh, is needed. April 8, 2010 23 rd ESI Conference - Veroia 17

What kind of Data we have from Networks? • Sampled Data. They are produced by selecting first a sample of the units-nodes by using some random technique. They not only be a subset of the whole possible data but they also not give an exhaustive view of some sub-population. Unless the graph is random, the nodes are not independent, while their meaning varies. – For example, let us take a random sample of a doctors’ network where the link means that they have common patients. Then the response will be different if some of the most famous doctors of this network included in the sample than the case none of them be selected. April 8, 2010 23 rd ESI Conference - Veroia 18

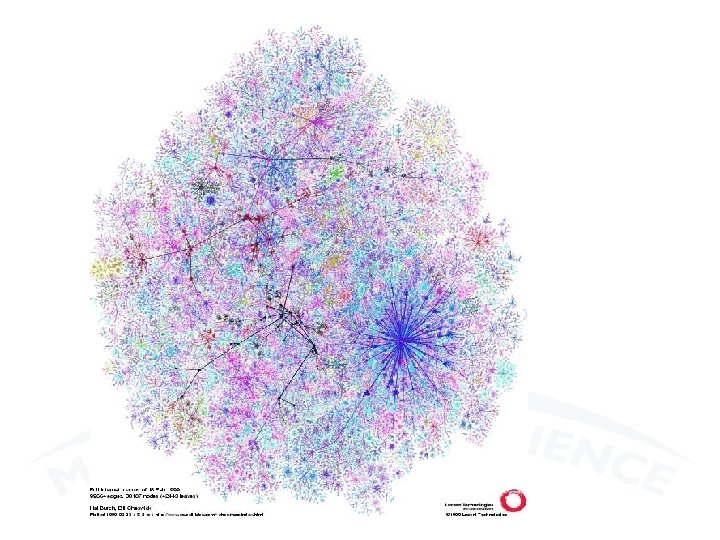
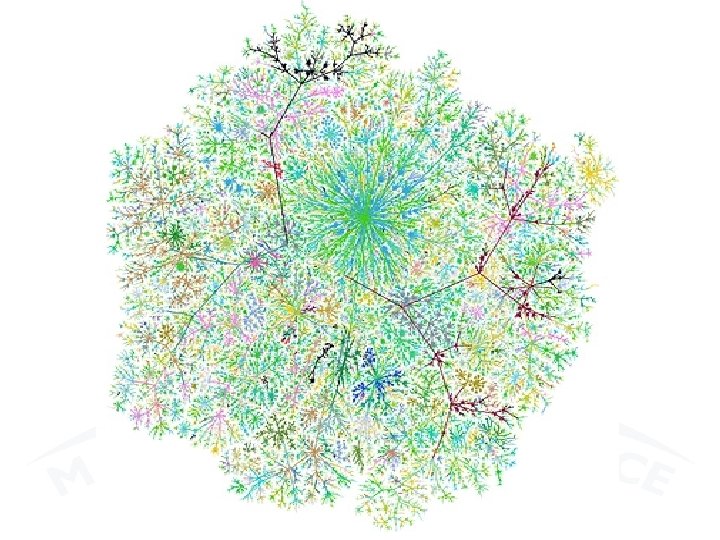
Drawing a network • The statistical analysis of a network is affected even by the way of drawing the network. The graph may be seen as a “geometric representation of relations between the nodes”. When the nodes are only a few it is possible to construct the graph by hand successfully, and one can realize the importance of a good design. For instance three graphs below represent the same graph but the sensation they produce is different. April 8, 2010 23 rd ESI Conference - Veroia 19
![Drawing a network • From Kolaczyk’s book [1] we have • 3 views of](http://slidetodoc.com/presentation_image_h/26c07ac7d8daa2ff53403d956a1f415b/image-20.jpg "Drawing a network • From Kolaczyk’s book [1] we have • 3 views of")
Drawing a network • From Kolaczyk’s book [1] we have • 3 views of the «Zachary’s ‘karate club’ network» It is centered on the actors a 1 and a 34. The yellow links actors from Two ego-centric different groups. views of the same network. The above is viewed from a 1 and the below from a 34 Easy Community Detection April 8, 2010 23 rd ESI Conference - Veroia 20

Drawing a network • A number of algorithms have been developed for drawing graphs and networks in such a way that the graphs reveal the relevant information in an aesthetically pleasant way. • Known packages as: – Mathematica, USINET, Snap, Tuchgraph, igraph (of R), Node. XL (of Excel) and many others have incorporated such algorithms for achieving optimal drawing of graphs. In the most of them the user can react to change the algorithm, or to move some nodes in order to make the graph more readable. As Kolaczyk points out the graph drawing involves not only “science” but also some “art”. April 8, 2010 23 rd ESI Conference - Veroia 21

Drawing a network • For some networks it is needed to make some statistical analysis before the drawing. – Let us consider that in a biological study we have N genes {1, 2, …, N} and that for any gene we observe its performance under m separate experimental conditions, gives rise to an m 1 vector xi=(xi 1, xi 2, …, xim)΄ for every gene i. – A usual simple measure of association of two genes i and j is by comparing the corresponding vectors xi and xj, or equivalently to find the correlation coefficient ρij of these two vectors. If this coefficient is big enough, the two genes involved are considered to be associated. So in the graph with nodes the genes we add the edge joining the associated genes, constructing sequentially the set of edges E. – It is obvious that in order to decide when the coefficient is big enough we must perform a hypotheses test for a suitable threshold. April 8, 2010 23 rd ESI Conference - Veroia 22

Drawing a network • Regression models can also be used for network drawing. – Let us consider a social network G(V, E), where V is the set of individuals constituting the nodes of the network. – If the links in this network (friendship, collaborationism, nativeness, etc) are not known but can be estimated from some controllable variables such as age, sex, speciality then we represent by Y the link (i. e. Y=1 if link exists, Y=0 if link does not exist) and by X the vector of predictors. – Afterwards, we estimate the probability P(Yij=1|Xi=xi, Xj=xj) and if it exceeds some limit we add edge ij in Ε, constructing, by this way, sequentially the whole set of edges E. April 8, 2010 23 rd ESI Conference - Veroia 23
=4 1. 7 2 d(1)=2 5 d(5)=1 0. 5 1. 2 0.")
Node Degrees d(2)=4 1. 7 2 d(1)=2 5 d(5)=1 0. 5 1. 2 0. 2 1 din(2)=3, dout(2)=1 3 din(1)=1, dout(1)=1 3 2 5 9 1 2 3 d(3)=2 2. 1 21 4 din(4)=1, dout(4)=2 d(4)=3 April 8, 2010 4 din(3)=1, dout(3)=2 23 rd ESI Conference - Veroia 28
 = P(D ≤ k) is the distribution function of the")
The degree distribution P(k) = P(D ≤ k) is the distribution function of the random variable D that counts the degree of a randomly chosen node. April 8, 2010 23 rd ESI Conference - Veroia 29

Distances, Eccentricity, Cliques… • We estimate the distribution of distances, or of eccentricities, or of other graph characteristics. • We use different statistics, as the mean distance or the mean connected distance by dividing the sum of distances with number m of edges instead of n(n-1). • We estimate the clustering coefficient cv=qv/(kv(kv − 1)/2), where kv are the neighbors of node v and qv the number of links between the neighbors of node v (0 qv kv(kv − 1)/2), or the global clustering coefficient c = c(p) = v cv/n April 8, 2010 23 rd ESI Conference - Veroia 30

Example of clustering coefficient a April 8, 2010 b c graph a b c qi 10 4 0 kv(kv − 1)/2 10 10 10 ci=qi/kv(kv − 1)/2 1 0. 4 0 23 rd ESI Conference - Veroia 31
 has on average")
Degree Distribution of random graphs A random graph from G(n, p) has on average edges. The distribution of the degree of any particular vertex is binomial: P(k): the probability that a node has k links For large N P(k) can be replaced by a Poisson distribution April 8, 2010 23 rd ESI Conference - Veroia 32

Degree distribution of the SW model The degree distribution of a random graph with the same parameters is plotted with filled symbols. April 8, 2010 23 rd ESI Conference - Veroia 33

Self-Similar = Scale-free Networks • The degree distribution follows a power law, at least asymptotically. That is: P(k) ~ k−γ where γ is a constant whose value is typically in the range 2<γ<3, although occasionally it may lie outside these bounds. • the clustering coefficient distribution, decreases as the node degree increases. This distribution also follows a power law. April 8, 2010 23 rd ESI Conference - Veroia 34
∼ k−γ power law a, Outgoing links")
Distribution of links on the World-Wide Web P(k)∼ k−γ power law a, Outgoing links (URLs found on an HTML document); b, Incoming links Web. c, Average of the shortest path between two documents as a function of system size [Barabasi, ea 1999] April 8, 2010 23 rd ESI Conference - Veroia 35

ψ In-degree and out-degree distributions subscribe to the power law. Power law also holds if only off-site (or "remote-only") edges are considered. April 8, 2010 23 rd ESI Conference - Veroia 36

example • For a graph G let and • This gives a metric between 0 and 1, such that graphs with low S(G) are "scale-rich", and graphs with S(G) close to 1 are "scale-free". This definition includes the notion of selfsimilarity implied in the name "scale-free". April 8, 2010 23 rd ESI Conference - Veroia 37

Sampling in networks • Sampling is necessary when the enumeration of data for the whole network is impossible. Kolaczyk’s Example: • Consider a network G=(V, E), with Nv nodes and Ne edges. Then suppose that we have measurements from a subset V* of V and from a subset E* of E that define the pair (V*, E*). The pair G*=(V*, E*) may be a subgraph of G but this is not always the case. Should G*=(V*, E*) be a subgraph for best statistical estimations? April 8, 2010 23 rd ESI Conference - Veroia 38

Sampling in networks Estimation of the Average Degree of the nodes of G: April 8, 2010 23 rd ESI Conference - Veroia 39

Sampling in networks • For testing the estimating method 1500 nodes selected randomly forming the subset V*, while for the edges two design methods applied. – Design 1: For every node i of V* we observe all edges {i. j} E involving i; each such edge becomes an element of E*. – Design 2: For each pair {i, j} V*, we observe whether or not {i. j} E; in this case, that edge becomes an element of E*. • After 10000 selections the average degree estimated under the two design methods and the histogram of the estimated values was formed. April 8, 2010 23 rd ESI Conference - Veroia 40

Sampling in networks The blue histogram is for the estimated average degrees under Design 1, while the red one is for Design 2. It is obvious from the figure that Design 1 gives better estimates. In fact the estimate under Design 1, was 12. 117 with s. e. 0. 3797, while under Design 2 was 3. 528 with s. e. 0. 2260. It is notable that in Design 1 the node degrees are the ones in graph G, but the pair (G*, E*) does not form a graph. The Design 2 on the other hand forms a subgraph (the induced subgraph) but the average degree under-estimated by approximately n/Nv. April 8, 2010 23 rd ESI Conference - Veroia 41
 is not a subgraph • Why?")
Best statistical estimations are obtained when G*=(V*, E*) is not a subgraph • Why? A crucial point for web statistics! April 8, 2010 23 rd ESI Conference - Veroia 42

Network Link Estimation • If we know the nodes but we have limited information about the links, • How can we estimate the unknown links? April 8, 2010 23 rd ESI Conference - Veroia 43

Node type Estimation Example: – Can we estimate the gender of persons (being nodes in a network of friends) from some knowledge of the network? A strategy for the estimation: • Consider each node as missing • Compute the probability to have more links with friends with the gender of interest. • Compare with the known situation • One may form ROC curves. --------------------- Kolaczyk, Eric. Statistical Analysis of Network Data, Methods and Models, Springer 2009. April 8, 2010 23 rd ESI Conference - Veroia 44

Web Function and Evolution Traffic on the Internet [Ivanov, Antoniou Prigogine Model Log-Normal Power Law Web Traffic April 8, 2010 23 rd ESI Conference - Veroia 45

Web Function and Evolution • • Google Pagerank Algorithm Hyperlink Matrix Web Traffic not included initially Random surfer assumption April 8, 2010 23 rd ESI Conference - Veroia 46

Web as a Communication Channel Web Users

Web Papadimitriou, ea Amarantidis, Antoniou, Vafopoulos Users Queries Topics

Web Users Social networks Queries Topics

Statistics and the Web • Games: Utility, Auctions • Webmetrics: statistical models for the Web Structure, Function and Evolution in order to evaluate individual, business and public policies April 8, 2010 23 rd ESI Conference - Veroia 50

Aristotle University, Department of Mathematics supported by Municipality of Veria Master in Web Science Web assessment, mathematical modeling and operation combined with business applications and societal transformations in the knowledge society. www. Webscience. gr

Master in web science winter spring Web science Economics and Business in the Web Technologies Knowledge Processing in the Web Networks and Discrete Mathematics Statistical Analysis of Networks Information Processing and Networks Mathematical Modeling of the Web April 8, 2010 23 rd ESI Conference - Veroia 52

Information about Information now! April 8, 2010 23 rd ESI Conference - Veroia 53

Computational social science • The capacity to collect and analyze massive amounts of data has transformed such fields as physics (i. e. CERN experiment)and biology (semantic search, ontologies, system biology) • This not the case for “computational social science” (i. e. economics, sociology, and political science) • Computational social science is a reality in Web business (i. e. Google) and governments (i. e. CIA) • How will be practiced in the open academic environment ? April 8, 2010 23 rd ESI Conference - Veroia 3/18 54

Review • • • What is the Web? Web milestones Why is so successful? We knew the web was big. . . Web generations Studying the Web Data and Structure Web Function and Evolution Web policy April 8, 2010 23 rd ESI Conference - Veroia 55
- Slides: 55