Approximate Graph Matching R Srikant ECECSL UIUC Coauthor

















")








")









 Epinions Social Network Fraction of initially correct matches Slashdot Social")
 Witness-Based")





")



 Problems • Other random graph models • E. g. : Models with")
- Slides: 49
Approximate Graph Matching R. Srikant ECE/CSL UIUC
Coauthor Joseph Lubars
Problem Statement Given two correlated graphs… One with known node identities, One with unknown (or incorrect) node identities… Goal: Infer the identities of the nodes in the second graph
Problem Given two correlated graphs… One with known node identities, One with unknown (or incorrect) node identities… Goal: Infer the identities of the nodes in the second graph • The two graphs are not identical (Edges 0 -2, 0 -6 exist in the first graph, but not the second)
Computational Complexity Requirement We are interested in very large graphs (e. g. , collaboration network of physicists):
Problem Goes by Many Names • Approximate Graph Matching • Random Graph Isomorphism: Special case • Network Deanonymization: Privacy • Network Alignment: Biology • …
Application 1: Social Networks Friendship Graph Bob Alice Carol Sample edges from an underlying friendship graph to obtain social networks Alice Carol
Application 1: Social Networks ? Bob ? Alice ? Carol Use the graph topology of one social network to deanonymize members of another network
Application 2: Protein Interaction Human Network Mouse Network Q 8 WUU 5 Q 920 S 3 P 06436 P 58391 Q 9 Y 365 P 62805 Q 9 JMD 3 P 62806 Find proteins with similar functions across different species based on the topologies of their interaction networks
Application 3: Wikipedia Articles English Wikipedia French Wikipédia Hydrosphère Hydrosphere Sun Soleil Terre Earth Solar System Supercontinent Système solaire Supercontinent Automatically find or correct corresponding articles in different versions of Wikipedia based on the graph of article links.
Mathematical Model Note: permuting the node identities or giving them different identities, or erasing the node identities, are equivalent Permute node labels of one graph
Prior Results
Mismatch Metric
Convex Relaxation
Other Approaches
Seed-Based Approaches (Narayanan-Shmatikov, 2009)
Seed-Based Approaches
Seed-Based Approaches
Our Model/Results
Our Model
Our Model Sample Edges Permute node labels
Motivation
Main Result
Main Result
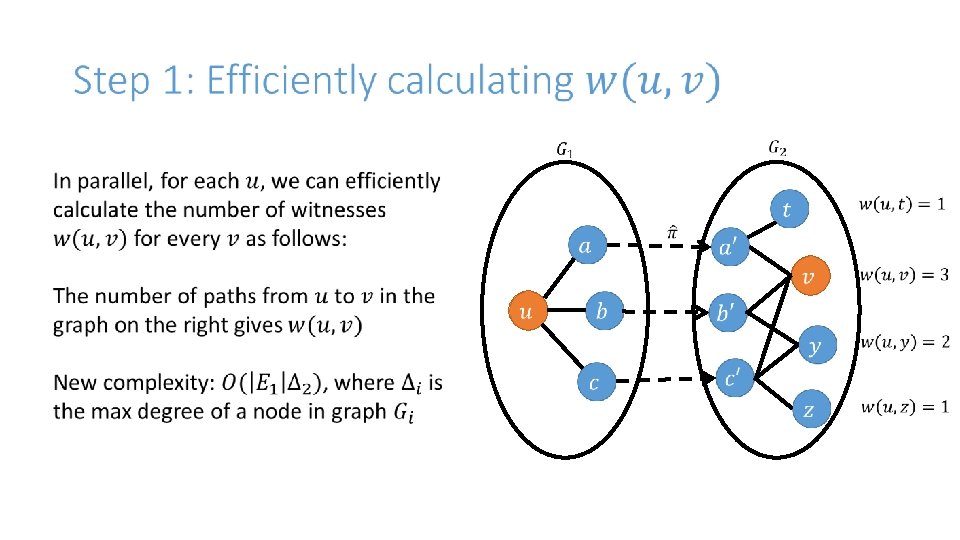
The Algorithm: Witnesses (Korula-Lattanzi)
MWM on Bipartite Graphs
Step 2: Greedy Matching, instead of MWM
The Algorithm: Interpretation
Why Does Greedy Matching Work?
Why Does Greedy Matching Work?
Why Does Greedy Matching Work?
Simulations • In practice, the algorithm can be run repeatedly • Suppose 10% of the matches are correct initially, then by running the algorithm once, one may increase this to something larger than 10% • Run it again, increase the number of correct matches • Repeat several times…. • Threshold phenomenon: if the initial number of correct matches is small, doesn’t help; otherwise, can match “all” nodes correctly
E-R Graphs Running the Algorithm Once Fraction of initially correct matches Running the Algorithm Iteratively Fraction of initially correct matches
Performance on Various Graph Models Stochastic Block Model Fraction of initially correct matches Barabási-Albert Model Fraction of initially correct matches
Real-World Graphs (Simulated Sampling) Epinions Social Network Fraction of initially correct matches Slashdot Social Network Fraction of initially correct matches
Possible Algorithm for Seedless Matching Seedless Algorithm (e. g. , Convex Relaxation Approach) Witness-Based Correction Technique
Seedless Matching In Practice
Small Number of Seeds
Proof Outline
Witnesses for a Correct Match
Witnesses for a Correct Match
Witnesses for an Incorrect Match (u, v)
Witnesses for an Incorrect Match • This time, we use the following Chernoff Bound: • Probability that the number of witnesses is too large:
Finishing the Proof
Conclusions
Related (Open) Problems • Other random graph models • E. g. : Models with heavy-tailed degree distributions • Performance of our algorithm • Information-theoretic achievability bounds for graph matching • Effect of a small number of seeds on seedless graph matching algorithms • E. g. : Convex relaxation • A small number of seeds empirically improves performance dramatically • Incorporating meta-information for nodes into our model • Anonymizing nodes before releasing graph structure