Approaches for Parallel Programs Parallel Programming Model Parallel





![2 并行程序构造方法 串行代码段 for ( i= 0; i<N; i++ ) A[i]=b[i]*b[i+1]; for (i= 0;](https://slidetodoc.com/presentation_image_h2/775f07229ee7f3b3aca0ce7e555cb03e/image-6.jpg "2 并行程序构造方法 串行代码段 for ( i= 0; i<N; i++ ) A[i]=b[i]*b[i+1]; for (i= 0;")






; T: =foo(3); end Process")


 {.")





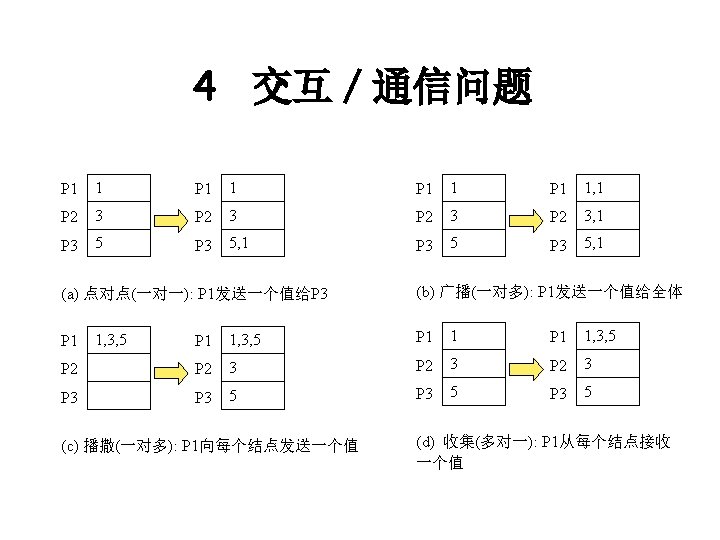


 … loop{ for (i=0; i<N; i++){ for")

{")





: dependence")
 read(X) write(X) X Shared variable 36")






 or bandwidth")

 § Ensure certain operations on certain data can be")
 receive (Y’) Y Y’")








 § Any set of positions can be")

 § Hardware supports independent physical address spaces § Can provide")
 § Example: Implementing Message Passing § Direct support at hardware")
 § Need to examine the issues and tradeoffs at every")
 § Uniprocessors play tricks with orders to gain parallelism or")

 Pipelining Divide and Conquer Speculation.")





- Slides: 67
并行程序设计基础 § 并行程序设计概述 § Approaches for Parallel Programs § Parallel Programming Model § Parallel Programming Paradigm 2
Parallel Programming is a Complex Task § The development of parallel applications largely dependent on the availability of adequate software tools and environments. § Parallel software developers handle issues/challenges such as: § Non-determinism, communication, synchronization, data partitioning and distribution, load-balancing, faulttolerance, heterogeneity, shared or distributed memory, deadlocks, and race conditions. 4
Users’ Expectations from Parallel Programming Environments § Currently, only few expert developers have the knowledge of programming parallel and distributed systems. § Parallel computing can only be widely successful if parallel software is able to meet expectations of the users, such as: § § § § § provide architecture/processor type transparency; provide network/communication transparency; be easy-to-use and reliable; provide support for fault-tolerance; accommodate heterogeneity; assure portability; provide support for traditional high-level languages; be capable of delivering increased performance; and finally, to provide parallelism transparency. 5
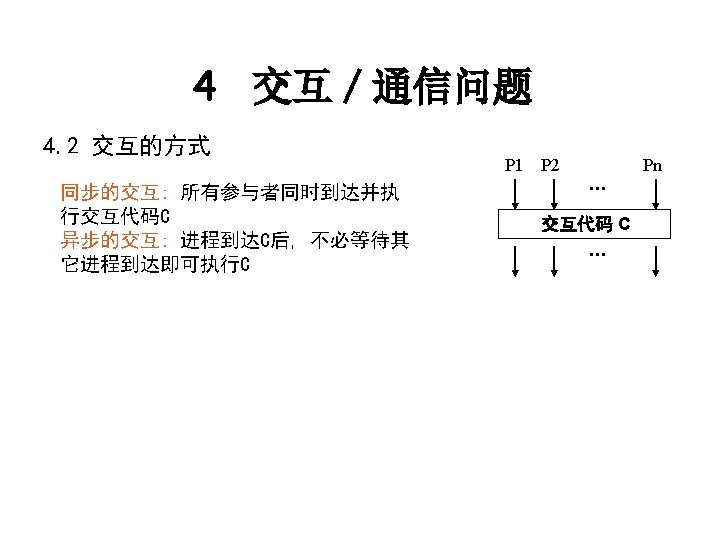
2 并行程序构造方法 串行代码段 for ( i= 0; i<N; i++ ) A[i]=b[i]*b[i+1]; for (i= 0; i<N; i++) c[i]=A[i]+A[i+1]; (a) 使用库例程构造并行程序 id=my_process_id(); p=number_of_processes(); for ( i= id; i<N; i=i+p) A[i]=b[i]*b[i+1]; barrier(); for (i= id; i<N; i=i+p) c[i]=A[i]+A[i+1]; 例子: MPI, PVM, Pthreads (c) 加编译注释构造并行程序的方法 #pragma parallel #pragma shared(A, b, c) #pragma local(i) { # pragma pfor iterate(i=0; N; 1) for (i=0; i<N; i++) A[i]=b[i]*b[i+1]; # pragma synchronize # pragma pfor iterate (i=0; N; 1) for (i=0; i<N; i++)c[i]=A[i]+A[i+1]; } 例子:SGI power C (b) 扩展串行语言 my_process_id, number_of_processes(), and barrier() A(0: N-1)=b(0: N-1)*b(1: N) c=A(0: N-1)+A(1: N) 例子: Fortran 90 6
3 并行性问题 开发动态并行性的一般方法: Fork/Join Process A: begin Z: =1 fork(B); T: =foo(3); end Process B: begin fork(C); X: =foo(Z); join(C); output(X+Y); end Process C: begin Y: =foo(Z); end Fork: 派生一个子进程 Join: 强制父进程等待子进程 13
Levels of Parallelism PVM/MPI Threads Compilers CPU Task i-l func 1 ( ) {. . . . } a ( 0 ) =. . b ( 0 ) =. . + Task i func 2 ( ) {. . . . } a ( 1 )=. . b ( 1 )=. . x Task i+1 func 3 ( ) {. . . . } a ( 2 )=. . b ( 2 )=. . Load Code-Granularity Code Item Large grain (task level) Program Medium grain (control level) Function (thread) Fine grain (data level) Loop (Compiler) Very fine grain (multiple issue) With hardware 16
Responsible for Parallelization Grain Size Code Item Parallelised by Very Fine Instruction Processor Fine Loop/Instruction block Compiler Medium (Standard one page) Function Programmer Large Program/Separate heavy-weight process Programmer 17
Approaches for Parallel Programs Development § Implicit Parallelism § Supported by parallel languages and parallelizing compilers that take care of identifying parallelism, the scheduling of calculations and the placement of data. § Explicit Parallelism § In this approach, the programmer is responsible for most of the parallelization effort such as task decomposition, mapping task to processors, the communication structure. § This approach is based on the assumption that the user is often the best judge of how parallelism can be exploited for a particular application. 25
Strategies for Development 26
Sample Sequential Program FDM (Finite Difference Method) … loop{ for (i=0; i<N; i++){ for (j=0; j<N; j++){ a[i][j] = 0. 2 * (a[i][j-1] + + a[i+1][j] + a[i][j]); } } a[i][j+1] + a[i-1][j] } … 27
Parallelization Procedure Assignment Decomposition Sequential Computation Tasks Process Elements Mapping Orchestration Processors 28
Parallelize the Sequential Program § Decomposition a task … loop{ for (i=0; i<N; i++){ for (j=0; j<N; j++){ a[i][j] = 0. 2 * (a[i][j-1] + a[i][j+1] + a[i-1][j] + a[i+1][j] + a[i][j]); } } } … 29
Parallelize the Sequential Program § Assignment PE Divide the tasks equally among process elements PE PE PE 30
Parallelize the Sequential Program § Orchestration PE need to communicate and to synchronize PE PE PE 31
Parallelize the Sequential Program § Mapping PE PE Multiprocessor 32
Parallel Programming Models § Sequential Programming Model § Shared Memory Model (Shared Address Space Model) § DSM § Threads/Open. MP (enabled for clusters) § Java threads (HKU JESSICA, IBM c. JVM) § Message Passing Model § PVM § MPI § Hybrid Model § Mixing shared and distributed memory model § Using Open. MP and MPI together 33
Sequential Programming Model § Functional § Naming: Can name any variable in virtual address space § Hardware (and perhaps compilers) does translation to physical addresses § Operations: Loads and Stores § Ordering: Sequential program order 34
Sequential Programming Model § Performance § Rely on dependences on single location (mostly): dependence order § Compilers and hardware violate other orders without getting caught § Compiler: reordering and register allocation § Hardware: out of order, pipeline bypassing, write buffers § Transparent replication in caches 35
SAS Programming Model System Thread (Process) read(X) write(X) X Shared variable 36
Shared Address Space Architectures § Any processor can directly reference any memory location § Communication occurs implicitly as result of loads and stores § Convenient: § Location transparency § Similar programming model to time-sharing on uniprocessors § Except processes run on different processors § Good throughput on multiprogrammed workloads § Naturally provided on wide range of platforms § History dates at least to precursors of mainframes in early 60 s § Wide range of scale: few to hundreds of processors § Popularly known as shared memory machines or model § Ambiguous: memory may be physically distributed among processors 37
Shared Address Space Model § Process: virtual address space plus one or more threads of control § Portions of address spaces of processes are shared Machine physical address space Virtual address spaces for a collection of processes communicating via shared addresses Load P 1 Pn pr i v at e Pn P 2 Common physical addresses P 0 St or e Shared portion of address space Private portion of address space P 2 pr i vat e P 1 pr i vat e P 0 pr i vat e Writes to shared address visible to other threads (in other processes too) • Natural extension of uniprocessor model: conventional memory operations for comm. ; special atomic operations for synchronization 38 • OS uses shared memory to coordinate processes •
Communication Hardware for SAS § Also natural extension of uniprocessor § Already have processor, one or more memory modules and I/O controllers connected by hardware interconnect of some sort § Memory capacity increased by adding modules, I/O by I/O controllers devices Mem Mem Interconnect Mem I/O ctrl Interconnect Processor Add processors for processing! 39
History of SAS Architecture § “Mainframe” approach § § § Motivated by multiprogramming Extends crossbar used for mem bw and I/O Originally processor cost limited to small § later, cost of crossbar P P I/O C § Bandwidth scales with p § High incremental cost; use multistage instead M M M $ $ P P § “Minicomputer” approach § § § Almost all microprocessor systems have bus Motivated by multiprogramming Used heavily for parallel computing Called symmetric multiprocessor (SMP) Latency larger than for uniprocessor Bus is bandwidth bottleneck § caching is key: coherence problem § Low incremental cost I/O C C 40
Example: Intel Pentium Pro Quad CPU P-Pro module 256 -KB Interrupt L 2 $ controller Bus interface P-Pro module PCI bridge PCI bus PCI I/O cards PCI bridge PCI bus P-Pro bus (64 -bit data, 36 -bit address, 66 MHz) Memory controller MIU 1 -, 2 -, or 4 -way interleaved DRAM § All coherence and multiprocessing glue integrated in processor module § Highly integrated, targeted at high volume § Low latency and bandwidth 41
Example: SUN Enterprise § Memory on processor cards themselves § 16 cards of either type: processors + memory, or I/O § But all memory accessed over bus, so symmetric § Higher bandwidth, higher latency bus 42
Scaling Up “Dance hall” Distributed memory § Problem is interconnect: cost (crossbar) or bandwidth (bus) § Dance-hall: bandwidth still scalable, but lower cost than crossbar § latencies to memory uniform, but uniformly large § Distributed memory or non-uniform memory access (NUMA) § Construct shared address space out of simple message transactions across a general-purpose network (e. g. read-request, read-response) 43
Shared Address Space Programming Model § Naming § Any process can name any variable in shared space § Operations § Loads and stores, plus those needed for ordering § Simplest Ordering Model § Within a process/thread: sequential program order § Across threads: some interleaving (as in time-sharing) § Additional orders through synchronization 44
Synchronization § Mutual exclusion (locks) § Ensure certain operations on certain data can be performed by only one process at a time § No ordering guarantees § Event synchronization § Ordering of events to preserve dependences § e. g. producer —> consumer of data § 3 main types: § § § point-to-point global group 45
MP Programming Model Node A Node B process send (Y) receive (Y’) Y Y’ message 46
Message-Passing Programming Model Match Receive. Y, P, t Address. Y Send. X, Q, t Address. X § § § Local process address space Process P Process Q Send specifies data buffer to be transmitted and receiving process Recv specifies sending process and application storage to receive into Memory to memory copy, but need to name processes User process names only local data and entities in process/tag space In simplest form, the send/recv match achieves pairwise synch event § Many overheads: copying, buffer management, protection 47
Message Passing Architectures § Complete computer as building block, including I/O § Communication via explicit I/O operations § High-level block diagram similar to distributed-memory SAS § § § But comm. needn’t be integrated into memory system, only I/O Easier to build than scalable SAS Can use clusters of PCs or SMPs on a LAN § Programming model: directly access only private address space (local memory), comm. via explicit messages (send/receive) § Programming model more removed from basic hardware operations § Library or OS intervention 48
Evolution of Message-Passing Machines § Early machines: FIFO on each link § synchronous ops § Replaced by DMA, enabling non-blocking ops § Buffered by system at destination until recv § Diminishing role of topology § § Store&forward routing: topology important Introduction of pipelined routing made it less so Cost is in node-network interface Simplifies programming 49
Example: IBM SP-2 § § Made out of essentially complete RS 6000 workstations Network interface integrated in I/O bus (bw limited by I/O bus) § Doesn’t need to see memory references 50
Example Intel Paragon § Network interface integrated in memory bus, for performance 51
Message Passing Programming Model § Naming § Processes can name private data directly. § No shared address space § Operations § Explicit communication: send and receive § Send transfers data from private address space to another process § Receive copies data from process to private address space § Must be able to name processes 52
Message Passing Programming Model § Ordering § Program order within a process § Send and receive can provide pt-to-pt synch between processes § Can construct global address space § Process number + address within process address space § But no direct operations on these names 53
Design Issues Apply at All Layers § Programming model’s position provides constraints/goals for system § In fact, each interface between layers supports or takes a position on § § § Naming model Set of operations on names Ordering model Replication Communication performance 54
Design Issues Apply at All Layers (Cont’d) § Any set of positions can be mapped to any other by software § Let’s see issues across layers § How lower layers can support contracts of programming models § Performance issues 55
Naming and Operations § Naming and operations in programming model can be directly supported by lower levels, or translated by compiler, libraries or OS § Example § Shared virtual address space in programming model § Hardware interface supports shared physical address space § Direct support by hardware through v-to-p mappings, no software layers 56
Naming and Operations (Cont’d) § Hardware supports independent physical address spaces § Can provide SAS through OS, so in system/user interface § v-to-p mappings only for data that are local § remote data accesses incur page faults; brought in via page fault handlers § Or through compilers or runtime, so above sys/user interface § shared objects, instrumentation of shared accesses, compiler support 57
Naming and Operations (Cont’d) § Example: Implementing Message Passing § Direct support at hardware interface § But match and buffering benefit from more flexibility § Support at sys/user interface or above in software (almost always) § Hardware interface provides basic data transport (well suited) § Send/receive built in sw for flexibility (protection, buffering) § Or lower interfaces provide SAS, and send/receive built on top with buffers and loads/stores 58
Naming and Operations (Cont’d) § Need to examine the issues and tradeoffs at every layer § Frequencies and types of operations, costs § Message passing § No assumptions on orders across processes except those imposed by send/receive pairs § SAS § How processes see the order of other processes’ references defines semantics of SAS § Ordering very important and subtle 59
Naming and Operations (Cont’d) § Uniprocessors play tricks with orders to gain parallelism or locality § These are more important in multiprocessors § Need to understand which old tricks are valid, and learn new ones § How programs behave, what they rely on, and hardware implications 60
Message Passing Model / Shared Memory Model Message Passing Shared Memory Architecture any SMP or DSM Programming difficult easier Performance good better (SMP) worse (DSM) Cost less expensive very expensive Sun. Fire 15 K $4, 140, 830 61
Parallelisation Paradigms § § § Task-Farming/Master-Worker Single-Program Multiple-Data (SPMD) Pipelining Divide and Conquer Speculation. 62
Master Worker/Slave Model § Master decomposes the problem into small tasks, distributes to workers and gathers partial results to produce the final result. § Mapping/Load Balancing § Static § Dynamic § When number of tasks are larger than the number of CPUs / they are know at runtime / CPUs are heterogeneous. Static 63
Single-Program Multiple-Data § Most commonly used model. § Each process executes the same piece of code, but on different parts of the data. —splitting the data among the available processors. § geometric/domain decomposition, data parallelism. 64
Pipelining § Suitable for fine grained parallelism. § Also suitable for application involving multiple stages of execution, but need to operate on large number of data sets. 65
Divide and Conquer § A problem is divided into two or more sub problems, and each of these sub problems are solved independently, and their results are combined. § 3 operations: split, compute, and join. § Master-worker/task-farming is like divide and conquer with master doing both split and join operation. § (seems like a “hierarchical” master-work technique) 66
Speculative Parallelism § It used when it is quite difficult to achieve parallelism through one of the previous paradigms. § Problems with complex dependencies – use “look ahead “execution. § Employing different algorithms for solving the same problem—the first one to give the final solution is the one that is chosen. 67