Apache Storm and Kafka Boston Storm User Group

Apache Storm and Kafka Boston Storm User Group September 25, 2014 P. Taylor Goetz, Hortonworks @ptgoetz

What is Apache Kafka?

A pub/sub messaging system. Re-imagined as a distributed commit log.

Apache Kafka Fast “A single Kafka broker can handle hundreds of megabytes of reads and writes per second from thousands of clients. ” http: //kafka. apache. org

Apache Kafka Scalable “Kafka is designed to allow a single cluster to serve as the central data backbone for a large organization. It can be elastically and transparently expanded without downtime. ” http: //kafka. apache. org

Apache Kafka Durable “Messages are persisted on disk and replicated within the cluster to prevent data loss. Each broker can handle terabytes of messages without performance impact. ” http: //kafka. apache. org

Apache Kafka Distributed “Kafka has a modern cluster-centric design that offers strong durability and fault-tolerance guarantees. ” http: //kafka. apache. org

Apache Kafka: Use Cases • Stream Processing • Messaging • Click Streams • Metrics Collection and Monitoring • Log Aggregation

Apache Kafka: Use Cases • Greek letter architectures • Which are really just streaming design patterns
")
Apache Kafka: Under the Hood Producers/Consumers (Publish-Subscribe)

Apache Kafka: Under the Hood Producers write data to Brokers Consumers read data from Brokers This work is distributed across the cluster

Apache Kafka: Under the Hood Data is stored in topics. Topics are divided into partitions. Partitions are replicated.

Apache Kafka: Under the Hood Topics are named feeds to which messages are published. http: //kafka. apache. org/documentation. html

Apache Kafka: Under the Hood Topics consist of partitions. http: //kafka. apache. org/documentation. html

Apache Kafka: Under the Hood A partition is an ordered and immutable sequence of messages that is continually appended to. http: //kafka. apache. org/documentation. html

Apache Kafka: Under the Hood A partition is an ordered, immutable sequence of messages that is continually appended to. http: //kafka. apache. org/documentation. html

Apache Kafka: Under the Hood Sequential disk access can be faster than RAM! http: //kafka. apache. org/documentation. html

Apache Kafka: Under the Hood Within a partition, each message is assigned a unique ID called an offset that identifies it. http: //kafka. apache. org/documentation. html

Apache Kafka: Under the Hood Zoo. Keeper is used to store cluster state information and consumer offsets. http: //kafka. apache. org/documentation. html

Storm and Kafka A match made in heaven.

Data Source Reliability • A data source is considered unreliable if there is no means to replay a previously-received message. • A data source is considered reliable if it can somehow replay a message if processing fails at any point. • A data source is considered durable if it can replay any message or set of messages given the necessary selection criteria.

Data Source Reliability • A data source is considered unreliable if there is no means to replay a previously-received message. • A data source is considered reliable if it can somehow replay a message if processing fails at any point. • A data source is considered durable if it can replay any message or set of messages given the necessary selection criteria. Kafka is a durable data source.

Reliability in Storm • Exactly once processing requires a durable data source. • At least once processing requires a reliable data source. • An unreliable data source can be wrapped to provide additional guarantees. • With durable and reliable sources, Storm will not drop data. • Common pattern: Back unreliable data sources with Apache Kafka (minor latency hit traded for 100% durability).

Storm and Kafka Apache Kafka is an ideal source for Storm topologies. It provides everything necessary for: • At most once processing • At least once processing • Exactly once processing Apache Storm includes Kafka spout implementations for all levels of reliability. Kafka Supports a wide variety of languages and integration points for both producers and consumers.

Storm-Kafka Integration • Included in Storm distribution since 0. 9. 2 • Core Storm Spout • Trident Spouts (Transactional and Opaque. Transactional)
: •")
Storm-Kafka Integration Features: • Ingest from Kafka • Configurable start time (offset position): • • Earliest, Latest, Last, Point-in-Time Write to Kafka (next release)

Use Cases
")
Core Storm Use Case Cisco Open Security Operations Center (Open. SOC)

Analyzing 1. 2 Million Network Packets Per Second in Real Time

O p e n S O C : Breaches occur in sec. /min. /hrs. , but take days/weeks/months to discover.

Data 3 V is not getting any smaller…

"Traditional Security analytics tools scale up, not out. ” "Open. SOC is a software application that turns a conventional big data platform into a security analytics platform. ” - James Sirota, Cisco Security Solutions https: //www. youtube. com/watch? v=b. QTZ 8 Og. Day. A
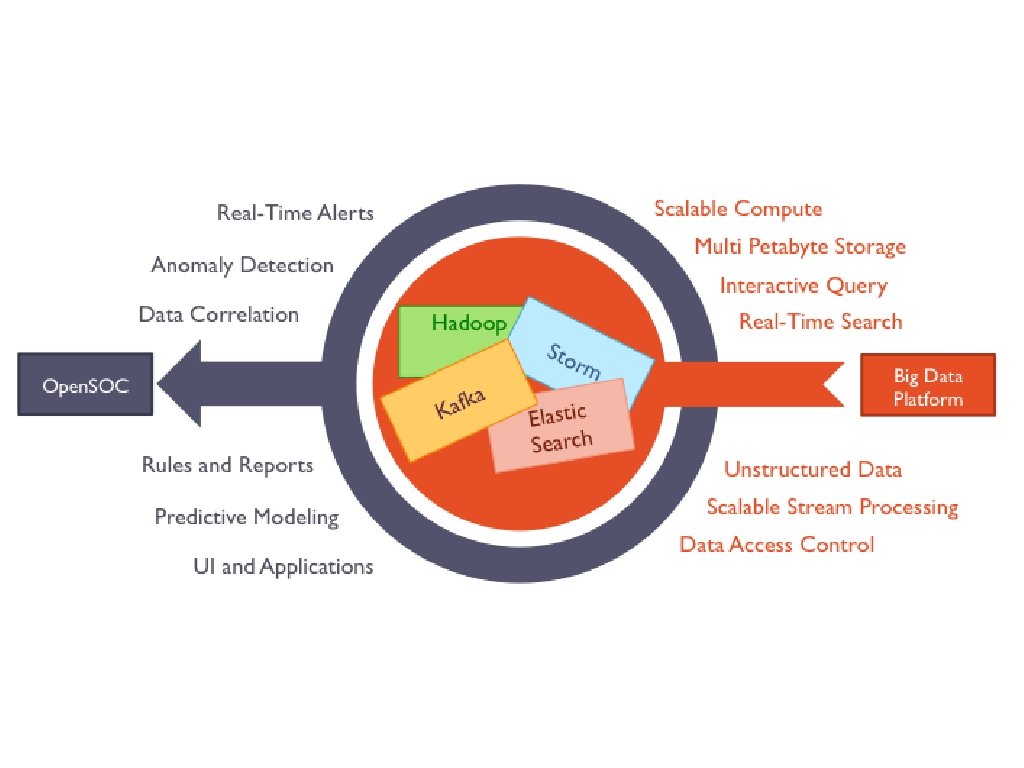

Open. SOC Conceptual Model

Open. SOC Architecture

PCAP Topology

Telemetry Enrichment Topology

Enrichment

Analytics Dashboards

Open. SOC Deployment @ Cisco

Trident Use Case Health Market Science Master Data Management

Health Market Science • “Master File” database of every healthcare practitioner in the U. S. • Kept up-to-date in near-real-time • Represents the “truth” at any point in time (“Golden Record”)

Health Market Science • Build products and services around the Master File • Leverage those services to gather new data and updates

Master Data Management


Data In

Data Out

MDM Pipeline

Polyglot Persistence Choose the right tool for the job.

Data Pipeline
 •")
Why Trident? • Aggregations and Joins • Bulk update of persistence layer (Micro-batches) • Throughput vs. Latency
 { Batch. Statement batch = new Batch.")
Cassandra. Cql. State public void commit(Long txid) { Batch. Statement batch = new Batch. Statement(Type. LOGGED); batch. add. All(this. statements); client. Factory. get. Session(). execute(batch); } public void add. Statement(Statement statement) { this. statements. add(statement); } public Result. Set execute(Statement statement){ return client. Factory. get. Session(). execute(statement); }

Cassandra. Cql. State. Updater public void update. State(Cassandra. Cql. State state, List<Trident. Tuple> tuples, Trident. Collector collector) { for (Trident. Tuple tuple : tuples) { Statement statement = this. mapper. map(tuple); state. add. Statement(statement); } }
 { Insert statement = Query. Builder.")
Mapper Implementation public Statement map(List<String> keys, Number value) { Insert statement = Query. Builder. insert. Into(KEYSPACE_NAME, TABLE_NAME); statement. value(KEY_NAME, keys. get(0)); statement. value(VALUE_NAME, value); return statement; } public Statement retrieve(List<String> keys) { Select statement = Query. Builder. select(). column(KEY_NAME). column(VALUE_NAME). from(KEYSPACE_NAME, TABLE_NAME). where(Query. Builder. eq(KEY_NAME, keys. get(0))); return statement; }

Storm Cassandra CQL {tuple} <— <mapper> —> CQL Statement Trident Batch == CQL Batch git@github. com: hmsonline/storm-cassandra-cql. git

Customer Dashboard

Thanks! P. Taylor Goetz, Hortonworks @ptgoetz
- Slides: 57