An Introduction to Parallel Programming Peter Pacheco Parallel






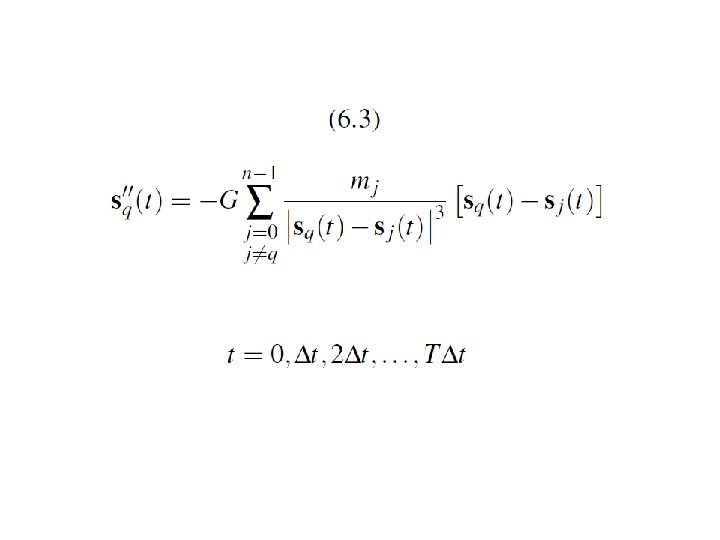


















![Problems Updates to forces[3] create a race condition. In fact, this is the case](https://slidetodoc.com/presentation_image_h/03b432deae85aeedaba79368e3618afd/image-27.jpg "Problems Updates to forces[3] create a race condition. In fact, this is the case")












")


")
")


")
")

 n n n An NP-complete problem. No known solution to")






 The digraph contains")
 n n n When a process")
 n n If another thread is")
 n In the case where a")




")
")

 numbers of times")


")







")
")


")
 n n In developing the reduced MPI solution to the n-body")
 n n When deciding which API to use, we should consider")
 n n If the memory requirements are great or the distributed")
 n n In choosing between Open. MP and Pthreads, if there’s")
- Slides: 88
An Introduction to Parallel Programming Peter Pacheco Parallel Program Development
Roadmap n n n Solving non-trivial problems. The n-body problem. The traveling salesman problem. Applying Foster’s methodology. Starting from scratch on algorithms that have no serial analog.
TWO N-BODY SOLVERS
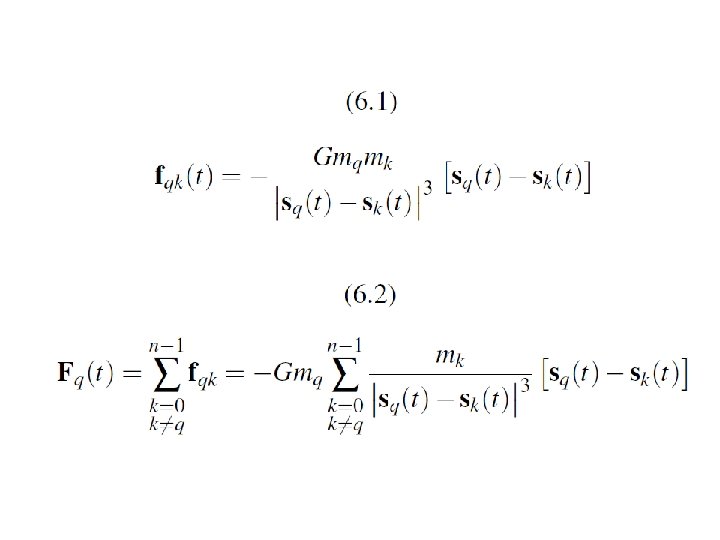
The n-body problem n n Find the positions and velocities of a collection of interacting particles over a period of time. An n-body solver is a program that finds the solution to an n-body problem by simulating the behavior of the particles.
Positiontime 0 mass Velocitytime 0 N-body solver Positiontime x Velocitytime x
Simulating motion of planets n Determine the positions and velocities: n n Newton’s second law of motion. Newton’s law of universal gravitation.
Serial pseudo-code
Computation of the forces
A Reduced Algorithm for Computing N-Body Forces
The individual forces
Using the Tangent Line to Approximate a Function
Euler’s Method
Parallelizing the N-Body Solvers n n n Apply Foster’s methodology. Initially, we want a lot of tasks. Start by making our tasks the computations of the positions, the velocities, and the total forces at each timestep.
Communications Among Tasks in the Basic N-Body Solver
Communications Among Agglomerated Tasks in the Basic N-Body Solver
Communications Among Agglomerated Tasks in the Reduced N-Body Solver q<r
Computing the total force on particle q in the reduced algorithm
Serial pseudo-code iterating over particles In principle, parallelizing the two inner for loops will map tasks/particles to cores.
First attempt Let’s check for race conditions caused by loop-carried dependences.
First loop
Second loop
Repeated forking and joining of threads The same team of threads will be used in both loops and for every iteration of the outer loop. But every thread will print all the positions and velocities.
Adding the single directive
Parallelizing the Reduced Solver Using Open. MP
Problems Updates to forces[3] create a race condition. In fact, this is the case in general. Updates to the elements of the forces array introduce race conditions into the code.
First solution attempt before all the updates to forces Access to the forces array will be effectively serialized!!!
Second solution attempt Use one lock for each particle.
First Phase Computations for Reduced Algorithm with Block Partition
First Phase Computations for Reduced Algorithm with Cyclic Partition
Revised algorithm – phase I
Revised algorithm – phase II
Parallelizing the Solvers Using Pthreads n n n By default local variables in Pthreads are private. So all shared variables are global in the Pthreads version. The principle data structures in the Pthreads version are identical to those in the Open. MP version: vectors are two-dimensional arrays of doubles, and the mass, position, and velocity of a single particle are stored in a struct. The forces are stored in an array of vectors.
Parallelizing the Solvers Using Pthreads n n n Startup for Pthreads is basically the same as the startup for Open. MP: the main thread gets the command line arguments, and allocates and initializes the principle data structures. The main difference between the Pthreads and the Open. MP implementations is in the details of parallelizing the inner loops. Since Pthreads has nothing analogous to a parallel for directive, we must explicitly determine which values of the loop variables correspond to each thread’s calculations.
Parallelizing the Solvers Using Pthreads n n n Another difference between the Pthreads and the Open. MP versions has to do with barriers. At the end of a parallel for Open. MP has an implied barrier. We need to add explicit barriers after the inner loops when a race condition can arise. The Pthreads standard includes a barrier. However, some systems don’t implement it. If a barrier isn't defined we must define a function that uses a Pthreads condition variable to implement a barrier.
Parallelizing the Basic Solver Using MPI n Choices with respect to the data structures: n n Each process stores the entire global array of particle masses. Each process only uses a single n-element array for the positions. Each process uses a pointer loc_pos that refers to the start of its block of pos. So on process 0 local_pos = pos; on process 1 local_pos = pos + loc_n; etc.
Pseudo-code for the MPI version of the basic n-body solver
Pseudo-code for output
Communication In A Possible MPI Implementation of the N-Body Solver (for a reduced solver)
A Ring of Processes
Ring Pass of Positions
Computation of Forces in Ring Pass (1)
Computation of Forces in Ring Pass (2)
Pseudo-code for the MPI implementation of the reduced n-body solver
Loops iterating through global particle indexes
Performance of the MPI n-body solvers (in seconds)
Run-Times for Open. MP and MPI N-Body Solvers (in seconds)
TREE SEARCH
Tree search problem (TSP) n n n An NP-complete problem. No known solution to TSP that is better in all cases than exhaustive search. Ex. , the travelling salesperson problem, finding a minimum cost tour.
A Four-City TSP
Search Tree for Four-City TSP
Pseudo-code for a recursive solution to TSP using depth-first search
Pseudo-code for an implementation of a depth-first solution to TSP without recursion
Pseudo-code for a second solution to TSP that doesn’t use recursion
Using pre-processor macros
Run-Times of the Three Serial Implementations of Tree Search (in seconds) The digraph contains 15 cities. All three versions visited approximately 95, 000 tree nodes.
Making sure we have the “best tour” (1) n n n When a process finishes a tour, it needs to check if it has a better solution than recorded so far. The global Best_tour function only reads the global best cost, so we don’t need to tie it up by locking it. There’s no contention with other readers. If the process does not have a better solution, then it does not attempt an update.
Making sure we have the “best tour” (2) n n If another thread is updating while we read, we may see the old value or the new value. The new value is preferable, but to ensure this would be more costly than it is worth.
Making sure we have the “best tour” (3) n In the case where a thread tests and decides it has a better global solution, we need to ensure two things: 1) That the process locks the value with a mutex, preventing a race condition. 2) In the possible event that the first check was against an old value while another process was updating, we do not put a worse value than the new one that was being written. n We handle this by locking, then testing again.
First scenario process x local tour value 22 global tour value 30 22 27 process y local tour value 27 3. test 1. test 6. lock 2. lock 7. test again 4. update 8. update 5. unlock 9. unlock
Second scenario process x local tour value 29 global tour value 30 27 process y local tour value 27 3. test 1. test 6. lock 2. lock 7. test again 4. update 8. unlock 5. unlock
Pseudo-code for a Pthreads implementation of a statically parallelized solution to TSP
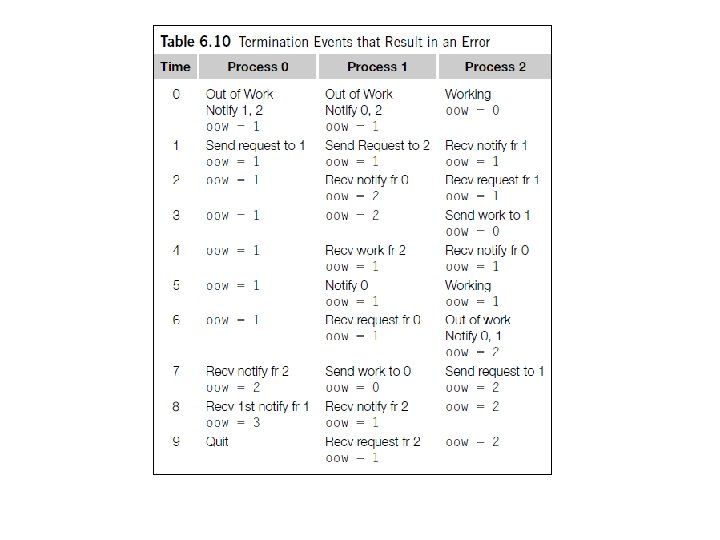
Dynamic Parallelization of Tree Search Using Pthreads n n Termination issues. Code executed by a thread before it splits: n n n It checks that it has at least two tours in its stack. It checks that there are threads waiting. It checks whether the new_stack variable is NULL.
Pseudo-Code for Pthreads Terminated Function (1)
Pseudo-Code for Pthreads Terminated Function (2)
Grouping the termination variables
Run-times of Pthreads tree search programs 15 -city problems (in seconds) numbers of times stacks were split Copyright © 2010, Elsevier Inc. All rights Reserved
Parallelizing the Tree Search Programs Using Open. MP Same basic issues implementing the static and dynamic parallel tree search programs as Pthreads. A few small changes can be noted. n n s d a e r h Pt O pe n. M P
Open. MP emulated condition wait
Performance of Open. MP and Pthreads implementations of tree search (in seconds)
IMPLEMENTATION OF TREE SEARCH USING MPI AND STATIC PARTITIONING
Sending a different number of objects to each process in the communicator
Gathering a different number of objects from each process in the communicator
Checking to see if a message is available
Terminated Function for a Dynamically Partitioned TSP solver that Uses MPI.
Modes and Buffered Sends n MPI provides four modes for sends. n n Standard Synchronous Ready Buffered
Printing the best tour
Terminated Function for a Dynamically Partitioned TSP solver with MPI (1)
Terminated Function for a Dynamically Partitioned TSP solver with MPI (2)
Packing data into a buffer of contiguous memory
Unpacking data from a buffer of contiguous memory
Performance of MPI and Pthreads implementations of tree search (in seconds)
Concluding Remarks (1) n n In developing the reduced MPI solution to the n-body problem, the “ring pass” algorithm proved to be much easier to implement and is probably more scalable. In a distributed memory environment in which processes send each other work, determining when to terminate is a nontrivial problem.
Concluding Remarks (2) n n When deciding which API to use, we should consider whether to use shared- or distributed-memory. We should look at the memory requirements of the application and the amount of communication among the processes/threads.
Concluding Remarks (3) n n If the memory requirements are great or the distributed memory version can work mainly with cache, then a distributed memory program is likely to be much faster. On the other hand if there is considerable communication, a shared memory program will probably be faster.
Concluding Remarks (3) n n In choosing between Open. MP and Pthreads, if there’s an existing serial program and it can be parallelized by the insertion of Open. MP directives, then Open. MP is probably the clear choice. However, if complex thread synchronization is needed then Pthreads will be easier to use.