A Overview of Recent Trends in NLP ELMo

 What is a good word embedding? l Complex characteristics of")
 Key Point l Trained with a coupled language model objective")



 Pre-trained language representations Difficulty l Feature-based")


 Key Point Using Transformer Step l Unsupervised pre-training")


 Key Point Multi-Task Learning l MTL")
 Key Point l Larger corpus 8")

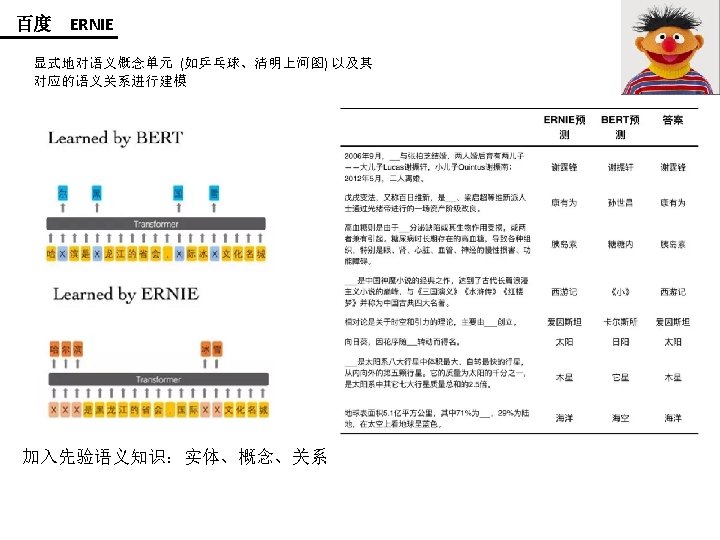

- Slides: 17
A Overview of Recent Trends in NLP ELMo 、ULMFi. T、GPT、Bert、MT-DNN、GPT-2、ERNIE
Deep contextualized word representations(ELMo) What is a good word embedding? l Complex characteristics of word use , e. g. syntax and semantics l Used vary across linguistic contexts The problems of current method 游戏 polysemy Play 演奏 比赛
Embeddings from Language Models(ELMo) Key Point l Trained with a coupled language model objective on a large text corpus. l Contextualized context-dependent context-independent Token representation Softmax layer
Feature extracted by deep neural network More lower layers , more basic feature
The highlight of ELMo Task specific combination semantic features syntactic features word features j-th layer Using ELMo softmax-normalized weights scale the entire ELMo vector
ELMo Evaluation Nearest neighbors to “play” using Glo. Ve and ELMo
Universal Language Model Fine-tuning for Text Classification(ULMFi. T) Pre-trained language representations Difficulty l Feature-based Pre-Training: ELMo l Fine-tuning: ULMFi. T、Bert…. retain previous knowledge avoid catastrophic forgetting during finetuning Step l General-domain LM pretraining l Target task LM fine-tuning l Target task classifier fine-tuning
ULMFi. T Target task LM fine-tuning and Classofier fine-tuning Discriminative fine-tuning Spatial dimensions Slanted triangular learning rates Avoid catastrophic forgetting Time dimensions Gradual unfreezing First unfreeze the last layer and fine-tune all unfrozen layers for one epoch, then unfreeze the next lower frozen layer and repeat.
ULMFi. T Evaluation
Improving Language Understanding by Generative Pre-Training(GPT) Key Point Using Transformer Step l Unsupervised pre-training l Supervised fine-tuning LM as an auxiliary objective
GPT Evaluation 9 out of the 12 datasets achieve SOTA
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding Key Point Bidirectional Transformers Larger corpus l Unsupervised pre-training Masked LM Next Sentence Prediction
Multi-Task Deep Neural Networks for Natural Language Understanding(MT-DNN) Key Point Multi-Task Learning l MTL provides an effective way of leveraging supervised data from many related tasks. l multi-task learning profits from a regularization effect via alleviating overfitting to a specific task Single-Sentence Classification Text Similarity Pairwise Text Classification Relevance Ranking
Language Models are Unsupervised Multitask Learners(GPT 2. 0) Key Point l Larger corpus 8 million l Deeper network GPT 1. 0 BERT GPT 2. 0 l Bidirectional Transformers Focus on Zero-shot task
Conclusion ELMo 、ULMFi. T、GPT、Bert、MT-DNN、GPT-2、ERNIE l l l Universal Language Model Pre-training transfer learning Multi- task Money