A New Psychometricinspired Evaluation Metric for Chinese Word


















- Slides: 20
A New Psychometric-inspired Evaluation Metric for Chinese Word Segmentation Peng Qian, Xipeng Qiu, Xuanjing Huang School of Computer Science, Fudan University
An Appetizer Case Different segmentation results that achieves the same Precision, Recall and F 1 -score. 白藜芦醇 是 一 种 酚类 物质 P 1: 白 藜芦 醇 是 一种 酚类 物质 P 2: 白藜 芦醇 是 一 种 酚类物 质
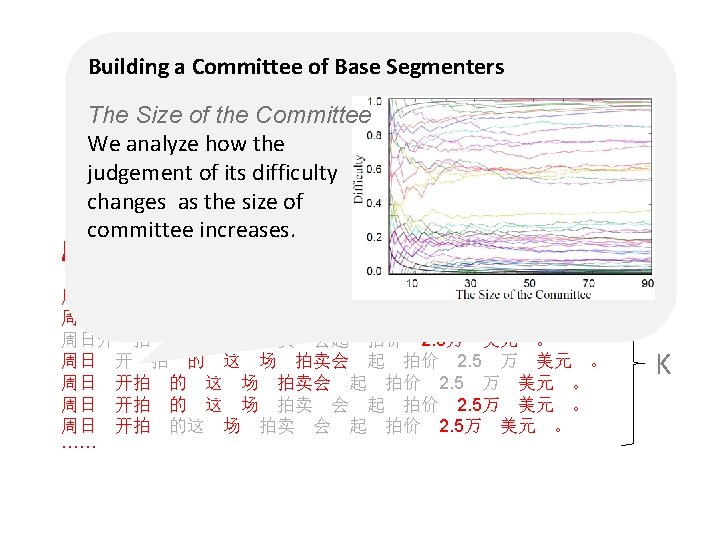
Motivation • With the successive improvements, standard metric is becoming hard to distinguish state-of-theart word segmentation systems. • The high performance is due to the fact that the distribution of difficulties of words is unbalanced. • Human judgment depends on difficulties of segmentations. A segmenter should earn extra credits when correctly segmenting a difficult word than an easy word. Conversely, a segmenter should take extra penalties when wrongly segmenting an easy word than a difficult word.
Metric Design From Psychometrics to NLP System Evaluation
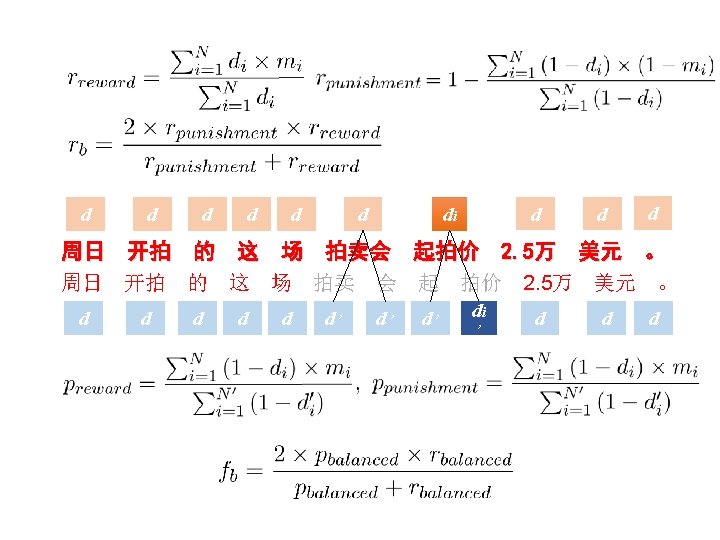
Item Analysis in Psychological Test Each item in the exam is given a credit. Difficult item gets more credits than easy one. According to psychometric theory, a reasonable difficulty can be computed by counting the ratio of the students who fail to answer the item correctly.
Transfer the Idea in Psychometrics to NLP System Evaluation Standardized test à e. g. Word Many subjects segmentation à Diverse segmenters Define the difficulty of an item in the test according à Define the difficulty of a to the collective test case according to performance. the collective performance of the NLP system.
Interpreting Difficulty
Validity and Reliability Correlation with Human Intuition Correlation in Parallel Tests
Validity: Evaluation of NLPCC 2015 • We demonstrate the effectiveness of the proposed method in a real evaluation by re-analyzing the submission results from NLPCC 2015 Shared Task. • We select the submissions of all 7 participants from the closed track and the submissions of all 5 participants from the open track. • We compare the standard precision, recall and Fscore with our new metric.
Validity: Comparison of f 1, fb, and Human Judgment on NLPCC 2015 Shared Task
Reliability: Parallel Test • We randomly split the test dataset into two halves. Different models are evaluated on the first half and then the second half. The performances of different models with our proposed evaluation metric are significantly correlated in two parallel tests. • We also include SIGHAN datasets: PKU, MSR, NCC, SXU
Reliability: Correlation between fb of parallel test sets We randomly split the test dataset into two halves. Different models are evaluated on the first half and then the second half. The performances of different models with our proposed evaluation metric are significantly correlated in two parallel tests.
Visualization
Conclusion • A new psychometric-inspired method for Chinese word segmentation evaluation by weighting all the words in test dataset based on the methodology applied to psychological tests and standardized exams. • Weighted evaluation metrics gives more reasonable and distinguishable scores and correlates well with human judgment. • The proposed evaluation metric can be easily extended to word segmentation task for other languages (e. g. Japanese) and other sequence labelling-based NLP tasks.
Thanks for Listening! All comments are welcome