A FRAMEWORK FOR DISTRIBUTED DATABASE DESIGN THE DESIGN
 THE DESIGN OF DATABASE FRAGMENTATION (分片设计) THE")
分布式数据库设计 A FRAMEWORK FOR DISTRIBUTED DATABASE DESIGN(概述) THE DESIGN OF DATABASE FRAGMENTATION (分片设计) THE ALLOCATION OF FRAGMENTS(分 配设计) Distributed DBMS University of Shanghai for Science and Technology Page 2. 1


Dimensions of the Problem 存取模式 动态 静态 部分信息 数据 知识级别 数据+程序 完整信息 共享 Distributed DBMS University of Shanghai for Science and Technology Page 2. 3

集中式数据库设计 1. Designing the “conceptual schema" which describes the integrated database 2. Designing the "physical database, " i. e. , mapping the conceptual schema to storage areas and determining appropriate access methods. Distributed DBMS University of Shanghai for Science and Technology Page 2. 4

分布式数据库设计的特殊要求 +3. Designing the fragmentation. + 4. Designing the allocation of fragments, i. e. mapped to physical images; also the replication of fragments is determined. Distributed DBMS University of Shanghai for Science and Technology Page 2. 5

关于分片和分配的几点注意 Fragmentation design been partially analyzed in centralized systems with multiple storage devices. The allocation problem has been studied as the "file allocation problem. " The distinction between two problems is conceptually relevant one deals with the "logical criteria" which motivate the fragmentation of a global relation one deals with the "physical" placement of data at the various sites. 这两个问题通常是相互关联的,不可能独立地解决它们 而能确定最优的fragmentaion和allocation Distributed DBMS University of Shanghai for Science and Technology Page 2. 6

关于APPLICATION考虑因素: 分布式数据库设计包括:分布式数据库设计和相应的分布式应 用设计 1. The site from which the application is issued (site of origin of the application). 2. The frequency of activation of the application (i. e. , 在单位时间内 被激活的次数); applications which can be issued at multiple sites, we need to know the frequency of activation of each application at each site. 3. The number, type, and the statistical distribution of accesses made by each application to each required data "object. " Distributed DBMS University of Shanghai for Science and Technology Page 2. 7
 Processing locality数据处理的本地性 Availability and reliability of distributed data 分 布式数据的有效性和可靠性冗余控制 Workload distribution 作负荷的合理分布")
设计目标(Objectives) Processing locality数据处理的本地性 Availability and reliability of distributed data 分 布式数据的有效性和可靠性冗余控制 Workload distribution 作负荷的合理分布 Storage costs and availability存储能力和费用 Distributed DBMS University of Shanghai for Science and Technology Page 2. 8

Processing locality Maximize processing locality corresponds to the simple principle of placing data as close as possible to the applications which use them. Maximizing processing locality (minimizing remote references) can be done by adding the number of' local and remote references corresponding to each candidate fragmentation and fragment, allocation, and selecting the best solution among them. The advantage of complete locality is not only the reduction of remote accesses, but also the increased simplicity in controlling the execution of the application. Distributed DBMS University of Shanghai for Science and Technology Page 2. 9

Availability and reliability of distributed data A high degree of availability for read-only applications is achieved by storing multiple copies of the same information; the system must be able to switch to an alternative copy when the one that should be accessed under normal conditions is not available. Reliability is also achieved by storing multiple copies of the same information - possible to recover from crashes or from the physical destruction of one of the copies by using the other still available copies. Distributed DBMS University of Shanghai for Science and Technology Page 2. 10

Workload distribution An important feature of distributed computer systems. To take advantage of the different powers or utilizations of computers at each site, Maximize the degree of parallelism of execution of applications. workload distribution might negatively affect processing locality - to consider the trade-off Distributed DBMS University of Shanghai for Science and Technology Page 2. 11

Storage costs and availability Should reflect the cost and availability of storage at the different sites. It is possible to have specialized sites in the network for data storage, or conversely to have sites which do not support mass storage at all. 通常存储的费用并不是非常重要(Compared to CPU, I/O, Transmission of network). Distributed DBMS University of Shanghai for Science and Technology Page 2. 12

设计方法 Top-Down Approach自顶向下 Bottom-Up Approach自底向上 Distributed DBMS University of Shanghai for Science and Technology Page 2. 13

Top-down approach 已有DB… 如何分割数据及如何分配这些数据到不同站点 过程 start by designing the global schema designing the fragmentation of the database then by allocating the fragments to the sites, creating the physical images The approach is completed by performing, at each site, the "physical design" of the data which are allocated to it. Distributed DBMS University of Shanghai for Science and Technology Page 2. 14

Requirements Analysis Top-Down Design Objectives User Input Conceptual Design View Integration Access Information GCS Distribution Design LCS’s Physical Design LIS’s View Design ES’s User Input

特点 能先看到雏形 the distributed database is developed as the aggregation of existing databases, it is not easy to follow the top-down approach. The global schema is often produced as a compromise between existing data descriptions. 问题:When Distributed DBMS University of Shanghai for Science and Technology Page 2. 16
,无设计 问题(信息集成)! Based on the integration of")
Bottom-up approach Existing databases are aggregated(还可能是异构 heterogeneous 或完全自治autonomous),无设计 问题(信息集成)! Based on the integration of existing schemata into a single, global schema. By integration, the merging of common data definitions and the resolution of conflicts among different representations given to the same data. Distributed DBMS University of Shanghai for Science and Technology Page 2. 17

bottom-up approach Horizontal fragments of a same global relation must have the same relation schema - easily enforced in a top-down design, while it is difficult to "discover" it. The integration process should attempt to modify the definitions of local relations, so that they can be regarded as horizontal fragments of a common, global relation. Distributed DBMS University of Shanghai for Science and Technology Page 2. 18
 The selection of a common database model for describing the global")
bottom-up design requires(异构情况下) The selection of a common database model for describing the global schema of the database. The translation of each local schema into the common data model. The integration of the local schemata into a common global schema. Distributed DBMS University of Shanghai for Science and Technology Page 2. 19

DDB设计的两个问题 Fragmentaion Horizontal Fragmentation Vertical fragmentation Allocation 通常分片设计和分配设计需要统筹考 虑 Distributed DBMS University of Shanghai for Science and Technology Page 2. 20

Horizontal Fragmentation Primary fragmentation 初级分片 Derived horizontal fragmentation导出 分片 Distributed DBMS University of Shanghai for Science and Technology Page 2. 21

 DEPT={1, 2} JOB={‘P’,")
水平分片-例 例子 EMP ( E#, NAME, DEPT, JOB, SAL, TEL, …) DEPT={1, 2} JOB={‘P’, ‘-P’} 假定,应用经常查询的内容是属于部门 1且是程 序员的职员。(80/20原则) 则可能有的水平分片限定(Qualification) P={ DEPT=1} P={DEPT=1, JOB=‘P’, SAL>500} Distributed DBMS University of Shanghai for Science and Technology Page 2. 23

如何保证分片原则 “手 ”检查! e. g. , F 1 = loc=‘Sa’ E ; F 2 = loc=‘Sb’ E 生成具有满足分段原则的predicate谓词 Distributed DBMS University of Shanghai for Science and Technology Page 2. 24

一些定义 谓词:用来执行分片选择操作的条件 1. A simple predicate 简单谓词: Attribute = value eg. : DEPT=1 2. A minterm predicate(小项谓词) y :给定简单谓 词集 P= { p 1, p 2, . . pn }, y= pi P pi* 也既是p 1* p 2* … pn* where (pi* = pi or pi* = NOT pi) and y ≠ false 3. A fragment is the set of all tuples for which a minterm predicate holds. Distributed DBMS University of Shanghai for Science and Technology Page 2. 25
诸如: A<10, A>5, Loc = Sa, Loc = Sb 生成")
谓词生成过程 找到常用的AP查询的simple predicate (Ai Value)诸如: A<10, A>5, Loc = Sa, Loc = Sb 生成 “小项” 谓词 消除可能出现的无用谓词 Distributed DBMS University of Shanghai for Science and Technology Page 2. 26
 Assume: some important APs")
Example Global relation EMP (EMPNUM, NAME, SAL, TAX, MGRNUM, DEPTNUM) Assume: some important APs require information about employees who are members of department; other important APs which require only the data of employees who are programmers; these last APs can be issued at any site, and reference all programmers with the same probability. Assume : that there are only two departments, 1 and 2; thus, DEPT = 1 → DEPT≠ 2, and vice versa. Two simple predicates are DEPT =1 and JOB = "P" (programmer). The minterm predicates for these two predicates are DEPT = 1 AND JOB= "P" DEPT = 1 AND JOB ≠"P" DEPT ≠ 1 AND JOB= "P" DEPT≠ 1 AND JOB ≠"P" Distributed DBMS University of Shanghai for Science and Technology Page 2. 27

讨论 All the above simple predicates are relevant e. g. SAL > 50 is not a relevant predicate; Distributed DBMS University of Shanghai for Science and Technology Page 2. 28

complete and minimal Let P = {p 1, p 2, … , pn} be a set of simple predicates. 为了正确有效进行分片,则P必须是complete and minimal 1. P of predicates is complete if any two tuples belonging to the same fragment are referenced with the same probability by any application. 2. P is minimal if all its predicates are relevant. Distributed DBMS University of Shanghai for Science and Technology Page 2. 29

Example P 1 = {DEPT = 1} is not complete -the applications reference tuples of programmers with a greater probability within each fragment produced by P 1. P 2 ={DEPT = 1, JOB ="P" } is complete and minimal. P 3= {DEPT = 1, JOB = "P", SAL > 50} is complete but not minimal, since SAL > 50 is not relevant. Distributed DBMS University of Shanghai for Science and Technology Page 2. 30

Fragmentation Method Basis Consider a predicate p 1 which partitions the tuples of R into two parts which are referenced differently by at least one application. Let P = {p 1} Method Consider a new simple predicate pi which partitions at least one fragment of P into two parts which are referenced in a different way by at least one application. Set P← P pi. Eliminate nonrelevant predicates from P. Repeat this step until the set of the minterm fragments of P is complete. Distributed DBMS University of Shanghai for Science and Technology Page 2. 31

Example Consider: SAL>50: if programmers have average salary greater than 50, it determines two sets of employees who are referenced differently by the applications. P 1= { SAL > 50} Consider: DEPT = 1; this predicate is relevant and is added to the previous one, P 2 ={ SAL > 50, DEPT = 1}. Consider: JOB = "P". The predicate is relevant, set P 3={SAL > 50, DEPT = 1, JOB = "P" }. then SAL > 50 is not relevant in P 3, thus, the final set P 4={DEPT = 1, JOB = "P" }, which is complete and minimal. Distributed DBMS University of Shanghai for Science and Technology Page 2. 32

A "reasonable" way 1. Concentrating on a few important applications 2. Not distinguishing fragments whose features are very similar Distributed DBMS University of Shanghai for Science and Technology Page 2. 33
 important applications: 1. Administrative applications, issued only at sites")
DEPT (DEPTNUM, NAME, AREA, MGRNUM) important applications: 1. Administrative applications, issued only at sites 1 and 3; administrative applications about departments in the northern area are issued at site 1; those about departments in the southern area are issued at site 3. 2. Applications about work conducted at each department; they can be issued at any department, but they reference tuples of the departments which are closer to their site of origin with higher probability than the tuples of other departments. Distributed DBMS University of Shanghai for Science and Technology Page 2. 34

Set of predicates: P 1: DEPTNUM < 10 P 2: 10 < DEPTNUM < 20 P 3: DEPTNUM > 20 P 4: AREA = "North" P 5: AREA = "South" Distributed DBMS University of Shanghai for Science and Technology Page 2. 35

可能的谓词限定 Y 1: DEPTNUM < 10 and AREA = "North“ Y 2: DEPTNUM < 10 and AREA = "South“ Y 3: 10 < DEPTNUM < 20 and AREA = "North“ Y 4: 10 < DEPTNUM < 20 and AREA = "South“ Y 5: DEPTNUM > 10 and AREA = "North“ Y 6: DEPTNUM > 10 and AREA = "South“ Distributed DBMS University of Shanghai for Science and Technology Page 2. 36

Reduce, e. g. AREA = "North" implies that DEPNUM > 20 y 1: DEPTNUM < 10 y 2: (10 < DEPTNUM < 20) AND (AREA = "North") y 3: (10 < DEPTNUM < 20) AND (AREA = "South") y 4: DEPTNUM > 20 Distributed DBMS University of Shanghai for Science and Technology Page 2. 37

Derived Horizontal Fragmentation导出分片 DHF:从另一个关系的属性性质或水平分片 推导出来 采用DHF可以使分片之间的join操作更加容 易 Distributed DBMS University of Shanghai for Science and Technology Page 2. 38
 S ( S#, SNAME. AGE, SEX) 分段设计 Define fragment")
DHF分片example eg: SC(S#, C#, GRADE) S ( S#, SNAME. AGE, SEX) 分段设计 Define fragment SC 1 as Select SC. S#, C#, GRADE From SC, S Where SC. S#=S. S# and SEX=‘M’ Define fragment SC 2 as Select SC. S#, C#, GRADE From SC, S Where SC. S#=S. S# and SEX=‘F’ Distributed DBMS University of Shanghai for Science and Technology Page 2. 39

分布式数据库中的join 连接操作 distributed join graphs Total Simple partitioned Distributed DBMS University of Shanghai for Science and Technology Page 2. 40

连接图定义 圆圈:数据分片 无向边:两个分片之间有相 同属性值的元组存在 Distributed DBMS University of Shanghai for Science and Technology Page 2. 41

完全连接图定义 A join graph is total when it contains all possible edges between fragments of R and S; Distributed DBMS University of Shanghai for Science and Technology Page 2. 42

部分连接图定义 A reduced join graph is partitioned if the graph is composed of two or more subgraphs without edges between them Distributed DBMS University of Shanghai for Science and Technology Page 2. 43

简单连接图定义 A reduced join graph is simple if it is partitioned and each subgraph has just one edge Distributed DBMS University of Shanghai for Science and Technology Page 2. 44
 SUPPLY (SNUM, PNUM, DEPTNUM, QUAN) SUPPLY is always used together with")
General example (continued) SUPPLY (SNUM, PNUM, DEPTNUM, QUAN) SUPPLY is always used together with another relation Some applications require information about supplies of given suppliers - join SUPPLY and SUPPLIER on the SNUM attribute. The other applications require information about supplies at a given department - join SUPPLY and DEPT on the DEPTNUM attribute. Distributed DBMS University of Shanghai for Science and Technology Page 2. 45

DEPT is horizontally fragmented according to values taken by the attribute DEPTNUM SUPPLIER is horizontally fragmented according to values taken by the attribute SNUM. There are two possible derived fragmentations SUPPLY one through the semi-join with SUPPLIER on SNUM one through the semi-join with DEPT on DEPTNUM both of them are correct. The selection between these alternatives should take into account which one of the two corresponding joins is more used by applications. Distributed DBMS University of Shanghai for Science and Technology Page 2. 46

Vertical Fragmentation Vertical Clustering objective: 将某个AP频繁使用的属性聚集 在一起,当有多个APs有时候需要权衡 利弊。 Distributed DBMS University of Shanghai for Science and Technology Page 2. 47
")
Vertical Fragmentation 为一全局关系R进行分片是不容易的, 因为随着R 的属性数目增加,可能的分片数目也大幅度增加 (the number of possible clusters is even larger. ) 两种启发式方法(heuristic approaches) The split approach in which global relations are progressively split into fragments分裂法 The grouping approach in which attributes are progressively aggregated to constitute fragments成组法 Distributed DBMS University of Shanghai for Science and Technology Page 2. 48
 EMP(EMPNUM, NAME, SAL, TAX, MGRNUM, DEPTNUM) APP 1、 Administrative applications, concentrated")
General example (continued) EMP(EMPNUM, NAME, SAL, TAX, MGRNUM, DEPTNUM) APP 1、 Administrative applications, concentrated at site 3, requiring NAME, SAL, and TAX of employees. APP 2、Applications about work conducted at each department, requiring NAME, MGRNUM, and DEPTNUM of employees; these applications are issued at all sites, and reference tuples of employees in the same group of departments with 80 percent probability. Distributed DBMS University of Shanghai for Science and Technology Page 2. 49
 EMP 2(EMPNUM, NAME, MGRNUM, DEPTNUM) Distributed DBMS University")
结果 EMP 1(EMPNUM, NAME, TAX, SAL) EMP 2(EMPNUM, NAME, MGRNUM, DEPTNUM) Distributed DBMS University of Shanghai for Science and Technology Page 2. 50

Mixed Fragmentation the simplest ways : 1. Applying horizontal fragmentation to vertical fragments 2. Applying vertical fragmentation to horizontal fragments Distributed DBMS University of Shanghai for Science and Technology Page 2. 51
 The simplest method is a “best-fit”")
THE ALLOCATION OF FRAGMENTS nonredundant allocation( easier ) The simplest method is a “best-fit” (最佳适应) approach; a measure is associated with each possible allocation, and the site with the best measure is selected. redundant allocation Replication introduces further complexity, 例如复 制程度,如何检索和更新等 Distributed DBMS University of Shanghai for Science and Technology Page 2. 52

讨论 在进行redundant allocation冗余分配时,通常先求 nonredundant allocation非冗余分配的解,在此基础 上再求redundant allocation冗余分配的解 The "additional replication" method is a typical heuristic approach; with this method, it is possible to take into account that the increase in the degree of redundancy is progressively less beneficial. Distributed DBMS University of Shanghai for Science and Technology Page 2. 53
 : 1. Determine the set of all sites where")
Two methods (for reduntant allocation) : 1. Determine the set of all sites where the benefit of allocating one copy of the fragment is higher than the cost, and allocate a copy of the fragment to each element of this set; this method selects “all beneficial sites. “ 所有得益站 点法 2. Determine first the solution of the nonreplicated problem, and then progressively introduce replicated copies starting from the most beneficial; the process is terminated when no “additional replication”(附加复制法) is beneficial. 这种方法随着冗余度的增加而得益逐渐减 少 Distributed DBMS University of Shanghai for Science and Technology Page 2. 54

HOW TO Measure of Costs and Benefits of Fragment Allocation Distributed DBMS University of Shanghai for Science and Technology Page 2. 55

General Criteria for Fragment Allocation i is the fragment index j is the site index k is the application index fkj is the frequency of application k at site j rki is the number of retrieval references of application k to fragment i uki is the number of update references of application k to fragment i nki = rki + uki Distributed DBMS University of Shanghai for Science and Technology Page 2. 56
 1 Using the “best-fit” (最佳适应法)approach for a nonreplieated allocation, we place")
Horizontal fragmentation (nonredundatn) 1 Using the “best-fit” (最佳适应法)approach for a nonreplieated allocation, we place Ri at the site where the number of references to Ri is maximum. The number of local references of Ri at site j is Bij =∑k fkj nki Ri is allocated at site j* such that Bij* is maximum. Distributed DBMS University of Shanghai for Science and Technology Page 2. 57

redundant allocation approach I 2. Using the "all beneficial sites" method for replicated allocation, Ri at all sites j where the cost of retrieval references of applications is larger than the cost of update references to Ri from applications at any other site. Bij =∑k fkjrki - C * ∑k∑j’≠j fkj'uki C is a constant, measures the ratio between the cost of an update and a retrieval access; typically, (C> 1). Ri is allocated at all sites j* such that Bij is positive; when all Bij are negative, a single copy of Ri is placed at the site such that Bij is maximum. Distributed DBMS University of Shanghai for Science and Technology Page 2. 58

redundant allocation approach II 3. Using the "additional replication", in terms of increased reliability and availability of the system di : degree of redundancy of Ri Fi :the benefit-Ri fully replicated at each site In [1] : β(di)= (1 – 21 -di)Fi Note that, β(1) = 0, β(2)=Fi/2, β(3) = 3 Fi/4, and so on. Bij= ∑kfkjrki - C *∑k∑j’≠j fkj'uki +β(di) [1]V. Lum et al. , "1978 New Orleans Data Base Design Workshop Report, " IBM Report PJ 2554(33154), 7/13/79, IBM Pres. Lab. , San Jose, CA, part of this report is also published in the Fifth VLDB, Pio de Janeiro, 1979. Distributed DBMS University of Shanghai for Science and Technology Page 2. 59

Vertical fragmentation 1. As and At: set of applications, issued at sites s or t, which use only attributes of Rs or Rt 2. A 1:set of applications local to r which use only attributes of Rs or Rt 3. A 2:set of applications local to r which reference attributes of both Rs and Rt 4. A 3 :set of applications at sites different than r, s, or t We evaluate the benefit of this partitioning as Bist=BAS+BAT-BA 1 -BA 2 -BA 3 =∑k As fksnki + ∑k Atfktnki -∑k A 1 fktnki -∑k A 22 X fkrnki ∑k A 3∑j r, s, tfkjnki Distributed DBMS University of Shanghai for Science and Technology Page 2. 60





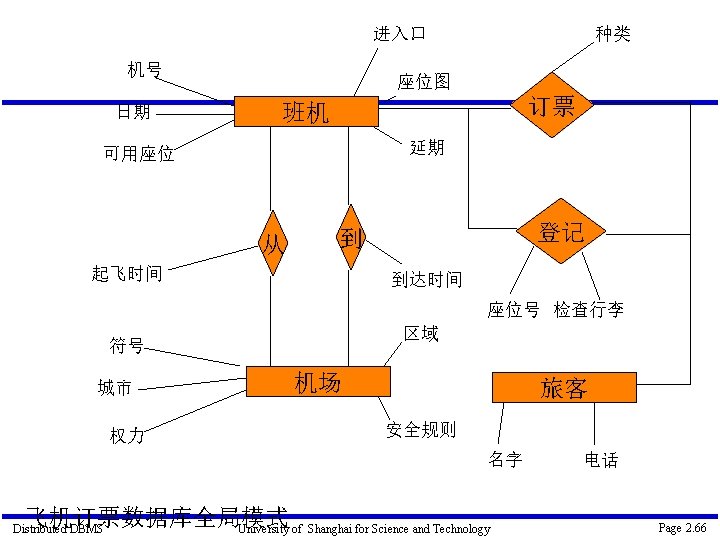
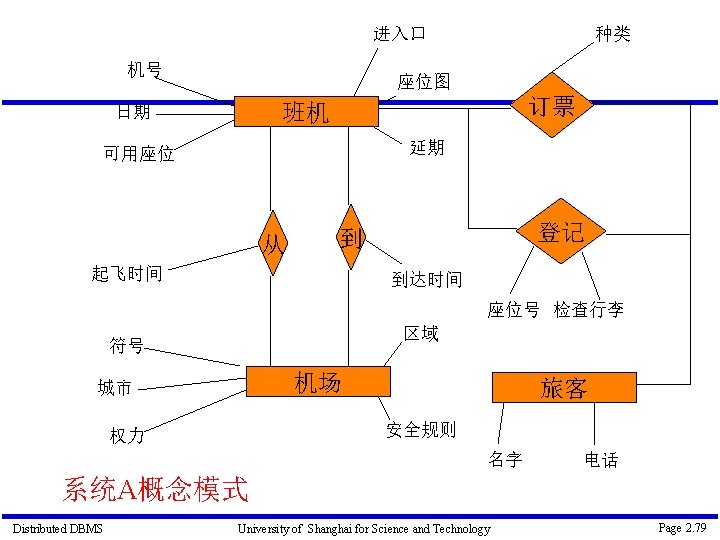
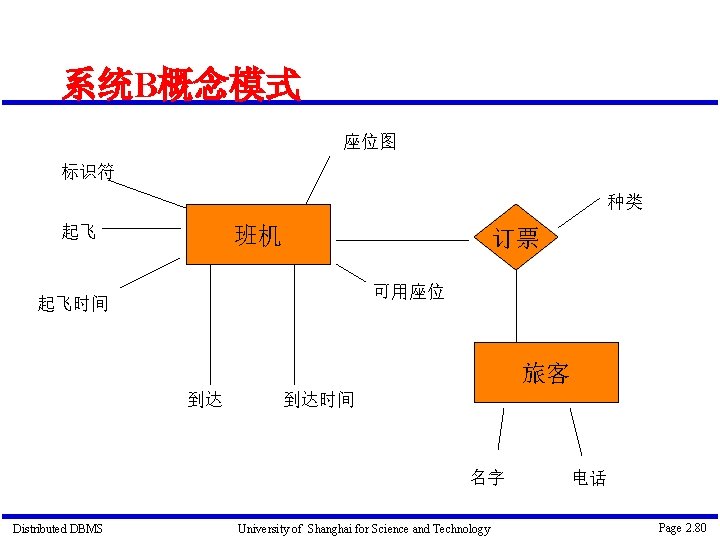
实例研究-飞机订票系统 三个应用 订票应用 登记应用 起飞应用 Distributed DBMS University of Shanghai for Science and Technology Page 2. 65
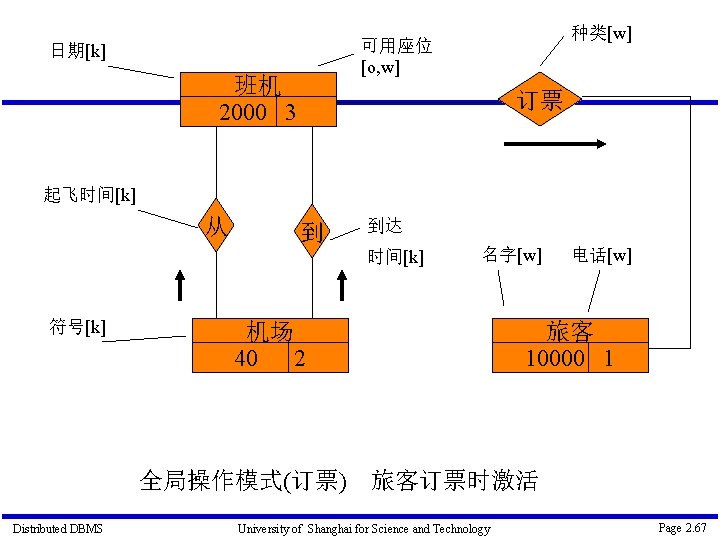

Distributed DBMS University of Shanghai for Science and Technology Page 2. 68

Distributed DBMS University of Shanghai for Science and Technology Page 2. 69

 订票 班机 1 登记 到 BC Distributed DBMS 从 旅客 1 u 旅客")
分布结果(A) 订票 班机 1 登记 到 BC Distributed DBMS 从 旅客 1 u 旅客 4 u 旅客 5 u 旅客 7 到 机场 1 站点 1的局部模式 University of Shanghai for Science and Technology Page 2. 71
 订票 班机 2 登记 到 从 旅客 2 u 旅客 4 u 旅客")
分布结果(B) 订票 班机 2 登记 到 从 旅客 2 u 旅客 4 u 旅客 6 u 旅客 7 到 站点 2的局部模式 AC Distributed DBMS 机场 2 University of Shanghai for Science and Technology Page 2. 72
 订票 班机 3 登记 到 AB Distributed DBMS 从 旅客 3 u 旅客")
分布结果(C) 订票 班机 3 登记 到 AB Distributed DBMS 从 旅客 3 u 旅客 5 u 旅客 6 u 旅客 7 到 机场 3 站点 3的局部模式 University of Shanghai for Science and Technology Page 2. 73

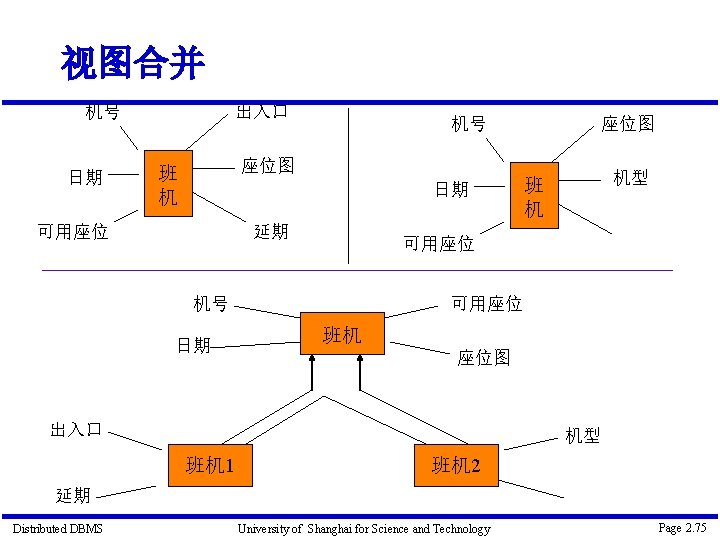


举例 View 1 技术人员 View 2 程师 技术人员 => Is-A 程师 View 1 View 2 学生 职 View 1 程师 => 不可并 Employee View 2 办事员 => 程师 Distributed DBMS University of Shanghai for Science and Technology 办事员 Page 2. 77

举例-续 View 1 1 n 技术人员 View 2 程 作 1 n 程师 程 作 => 1 人员 技术员 Distributed DBMS n 作 程 程师 University of Shanghai for Science and Technology Page 2. 78
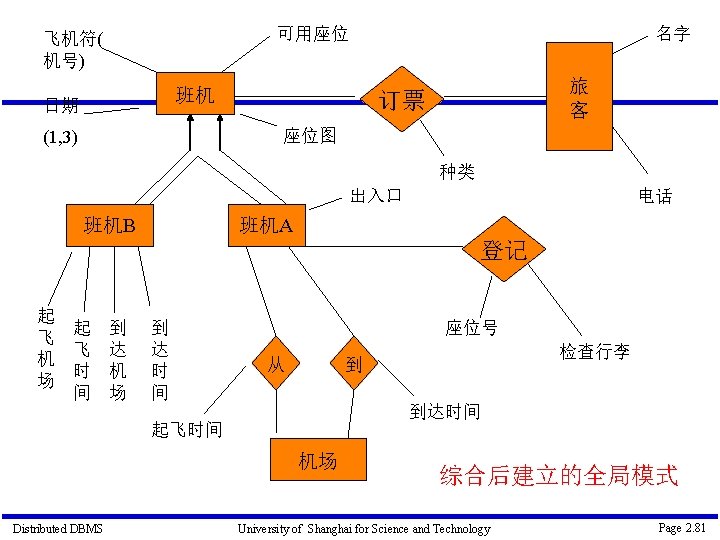

数据集成 • XML • Ontology • View Distributed DBMS University of Shanghai for Science and Technology Page 2. 82
- Slides: 82