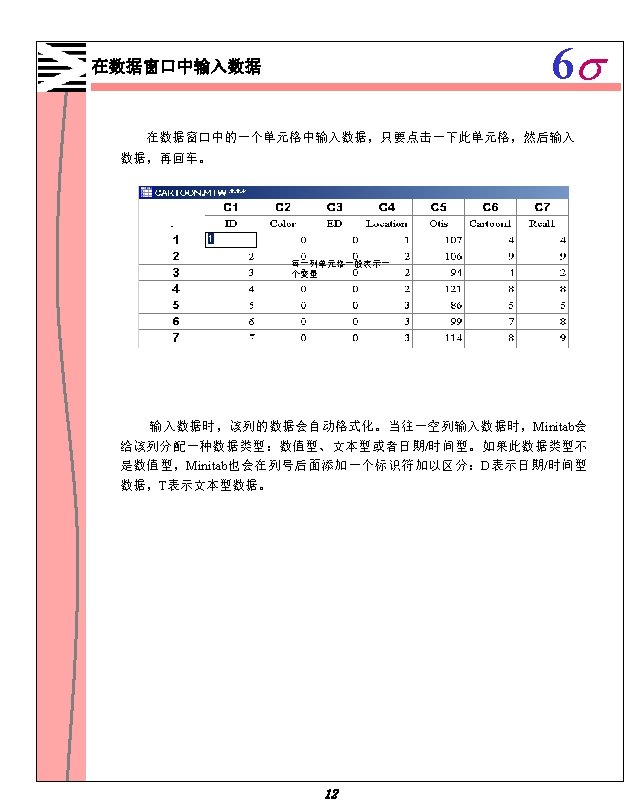
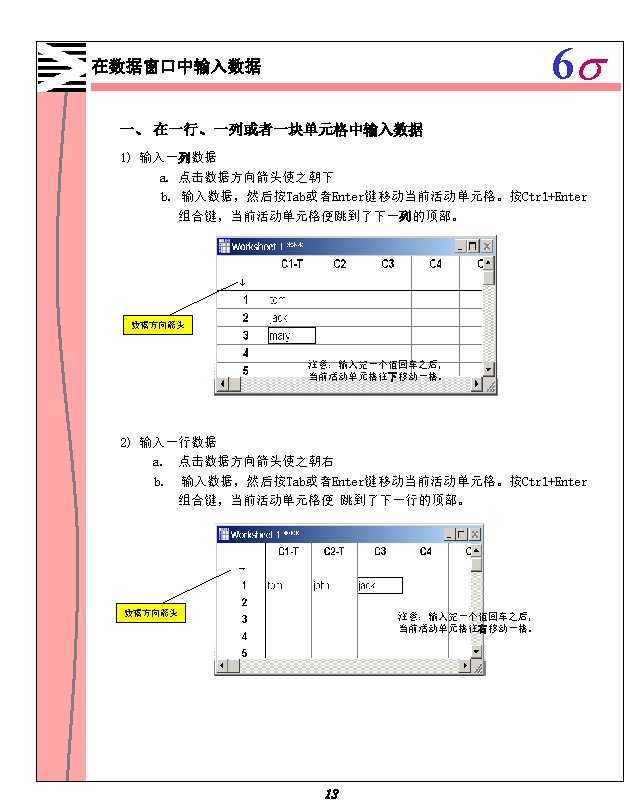
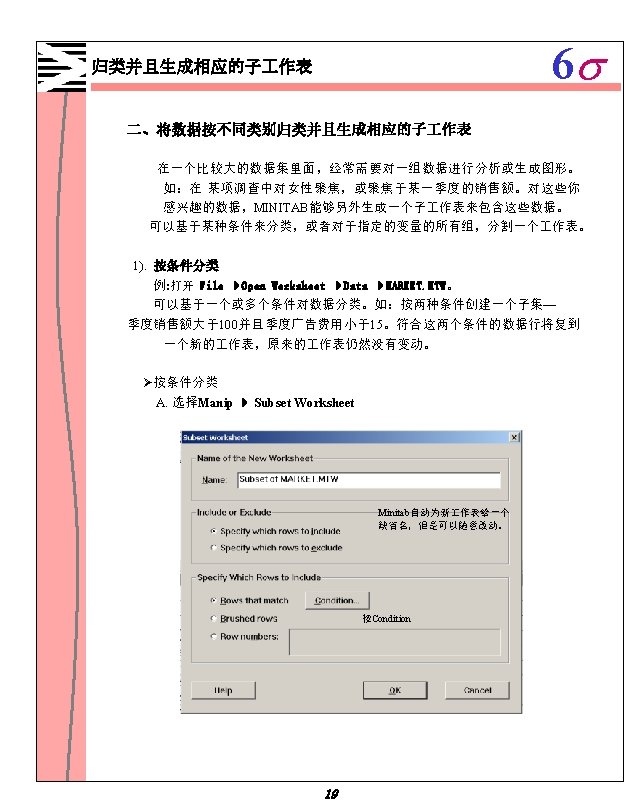
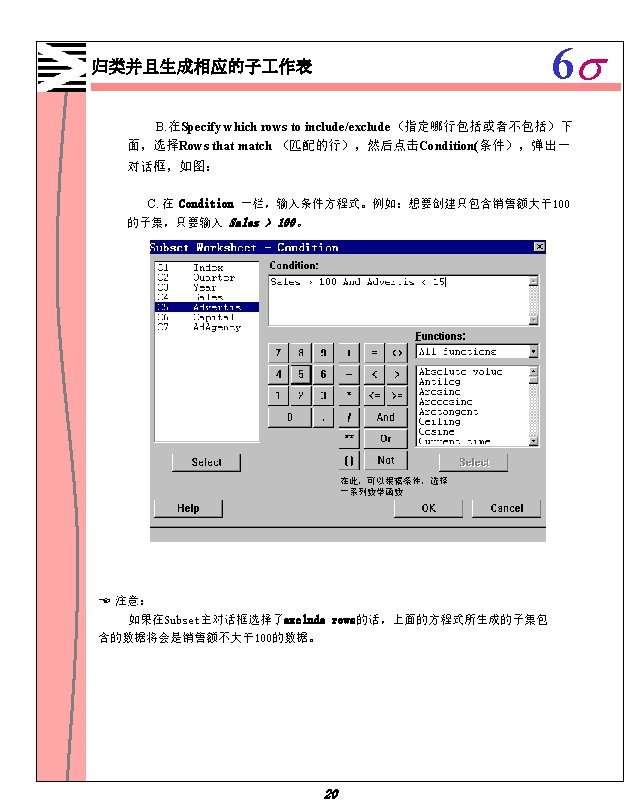
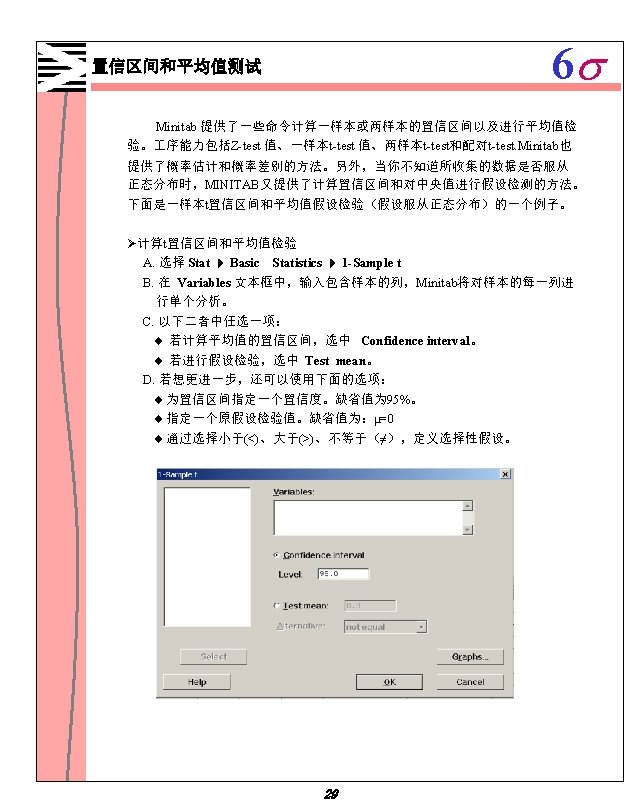
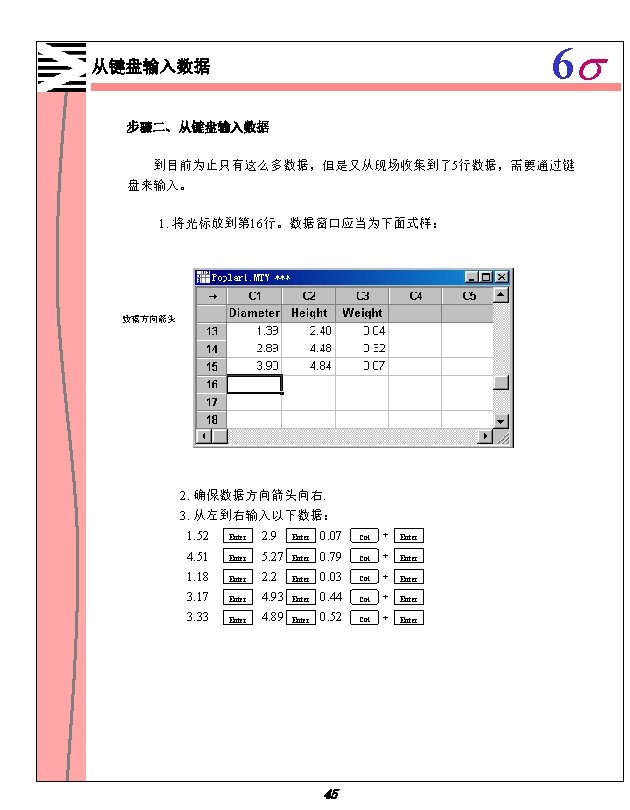
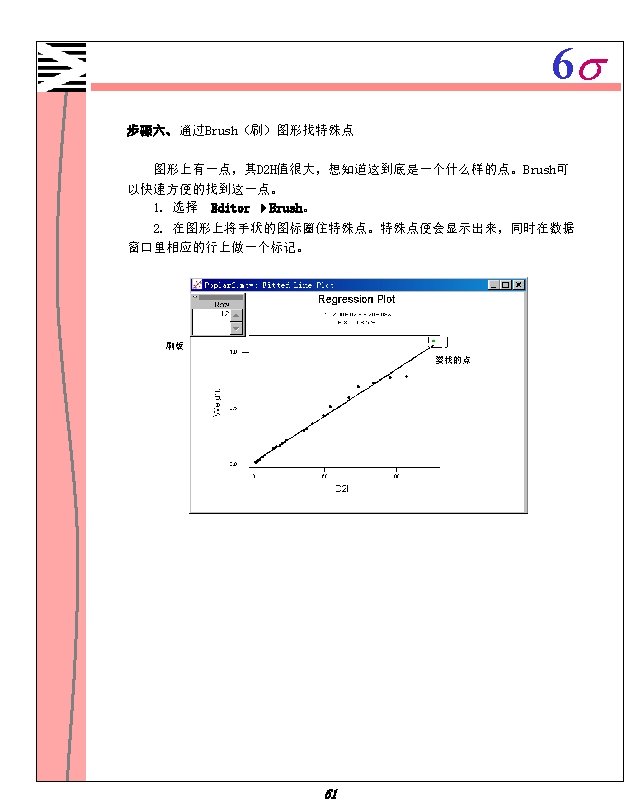
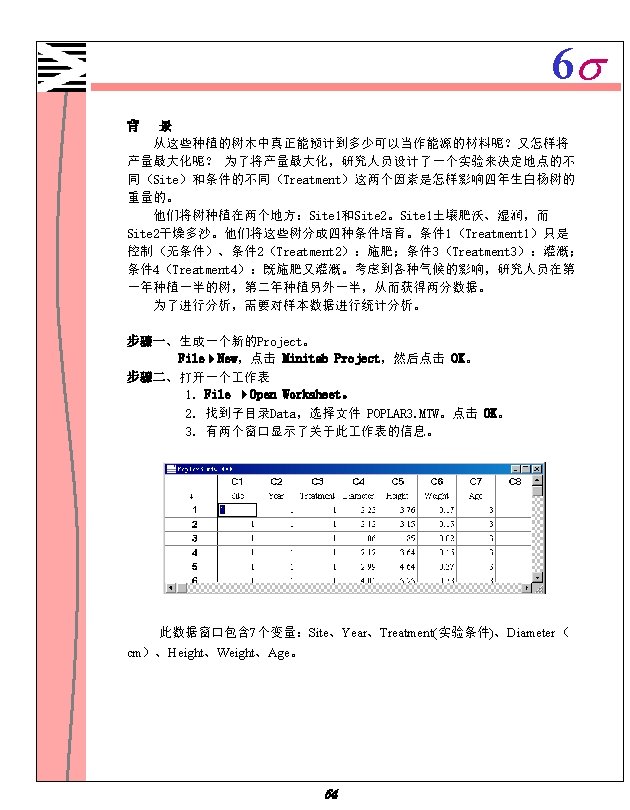
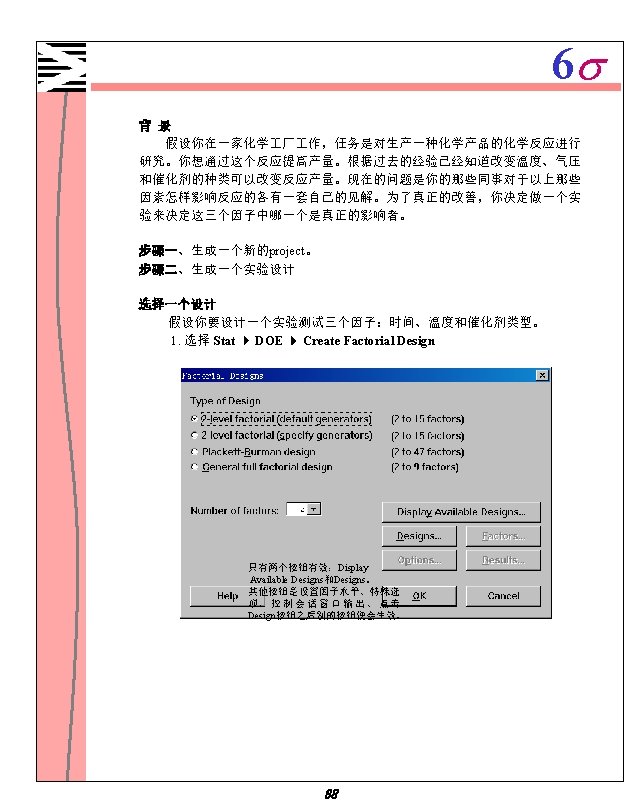
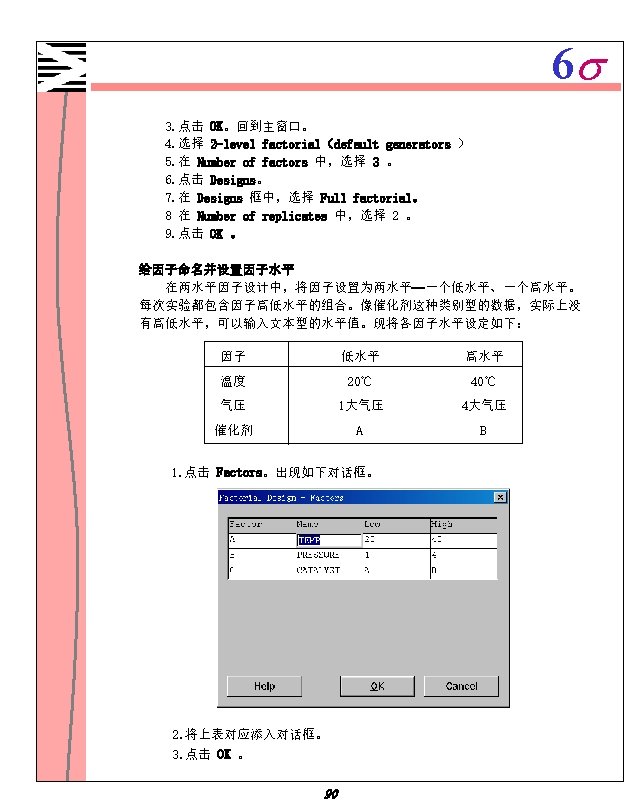
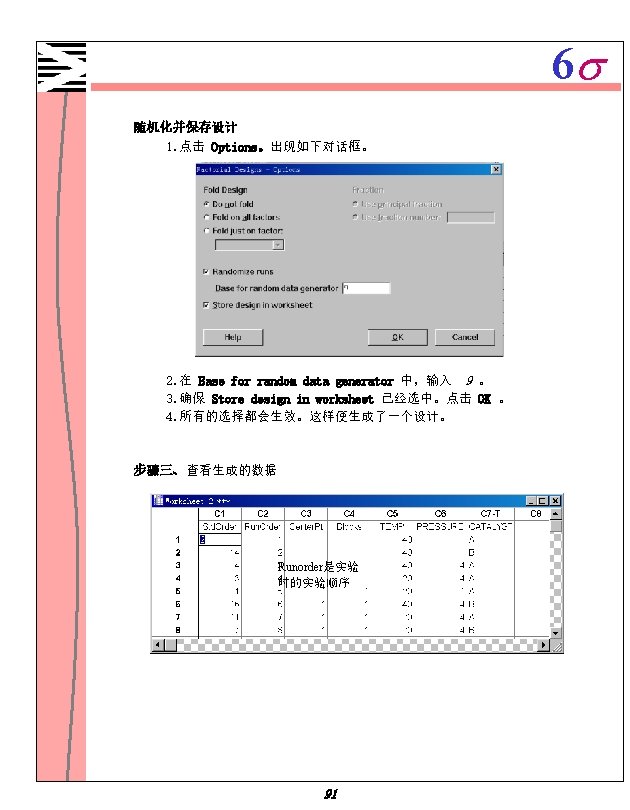
6 s Minitab 1 1 Minitab 1 2



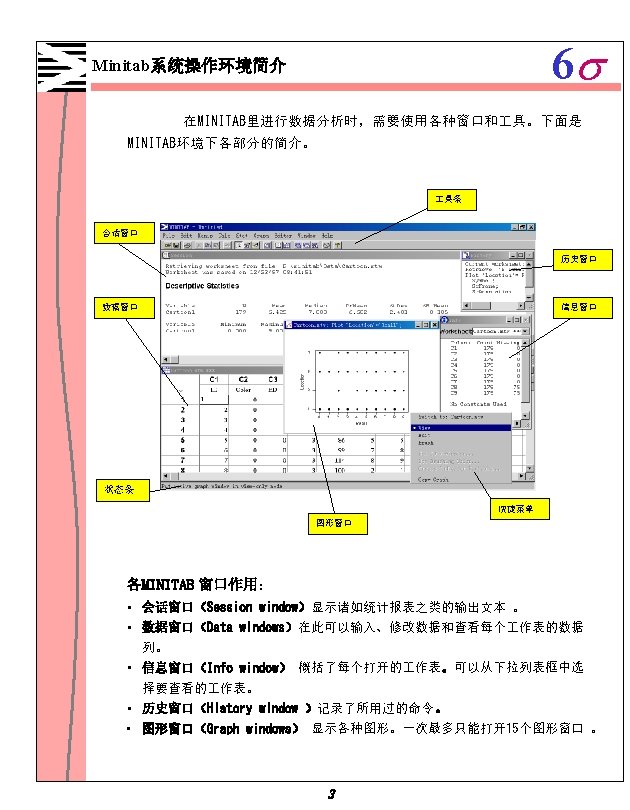
6 s 第一章 Minitab 概 要 1 -1 Minitab系统操作环境简介 1 -2 Minitab的 作步骤 1 -3 关于Minitab的 Project文件类型 2










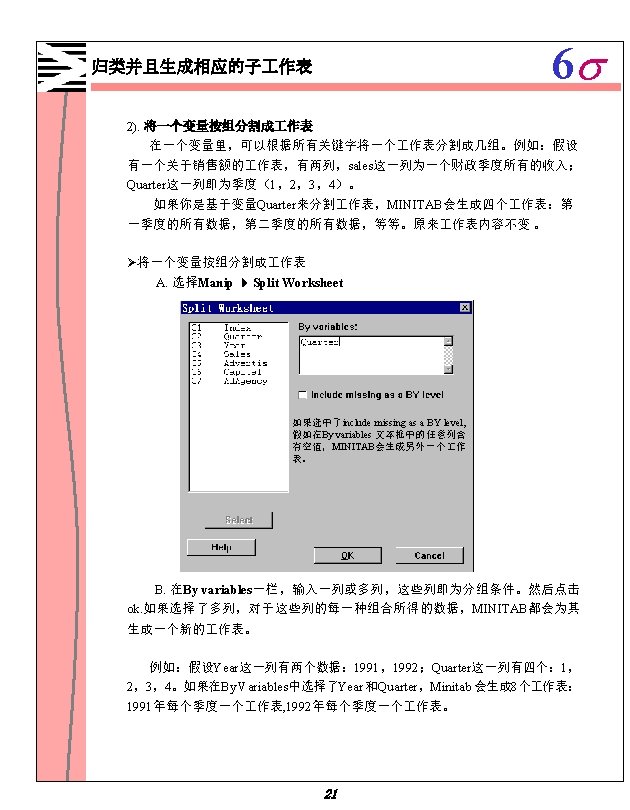
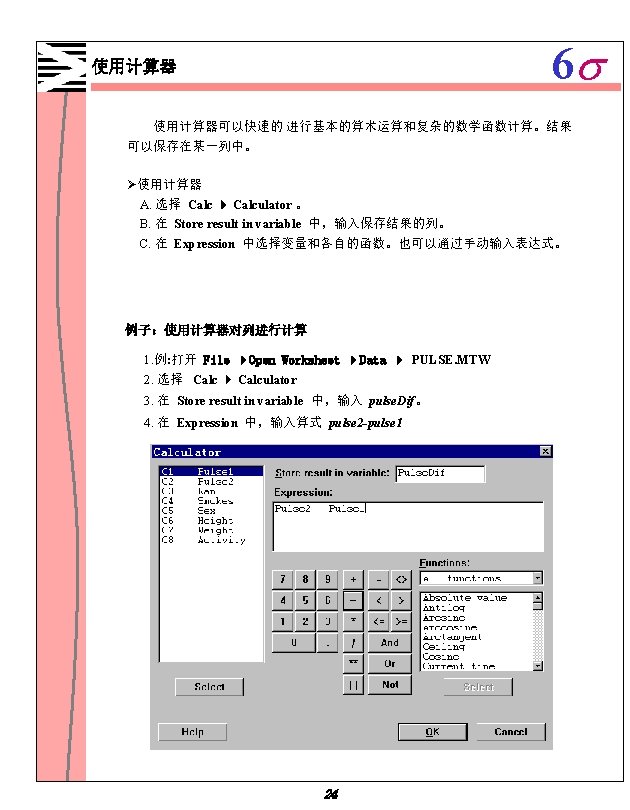

6 s 使用计算器 5. 点击 OK 后结果如所示: C 1 C 2 ↓ Pulse 1 1 64 88 24 2 58 70 12 3 62 76 14 4 66 78 12 5 64 80 16 6 74 84 10 7 84 84 0 … … … 25 Pulse C 9 2 pulse Dif





 相关性的一个例子 假设要分析学生身高与体重的关系。 1. 打开文件 PULSE. MTW。 2. 选择 Stat Basic Statistics")
6 s 相关(correlation) 相关性的一个例子 假设要分析学生身高与体重的关系。 1. 打开文件 PULSE. MTW。 2. 选择 Stat Basic Statistics Correlation 3. 在 Variables 文本框中,输入 Height 和 Weight. 点击 OK。 Session window 输出: Correlations: Height, Weight Pearson correlation of Height and Weight = 0. 785 P-Value = 0. 000 结果解释 根据输出结果,相关值(r=0. 785,P-Value=0. 000)表明身高与体重正相关。 32

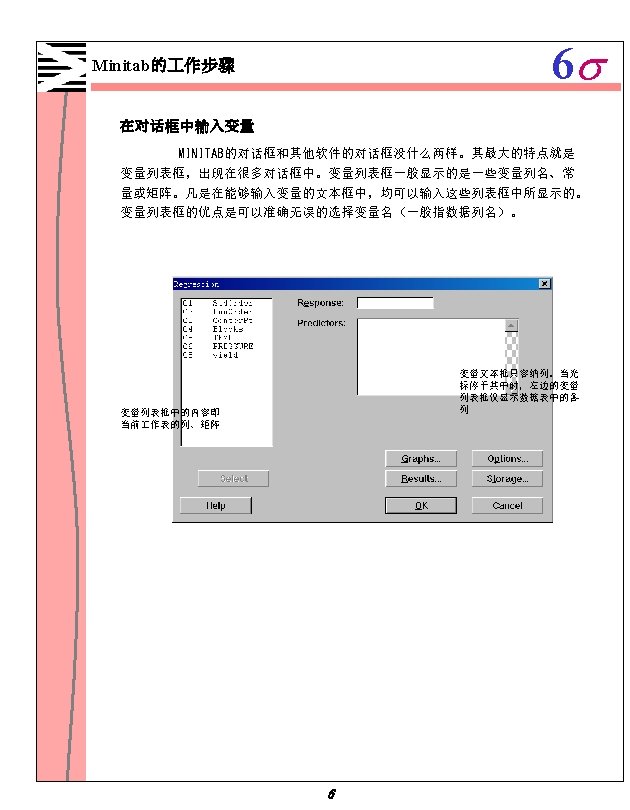
 运行一个简单线性回归的例子 假设想要找出体重与身高的关系 1. 打开文件 PULSE. MTW 2. 选择 Stat Regression 3.")
6 s 回归(regression) 运行一个简单线性回归的例子 假设想要找出体重与身高的关系 1. 打开文件 PULSE. MTW 2. 选择 Stat Regression 3. 在 Response 文本框中,输入 WEIGHT。在 Predictors 中,输入 Height 。 然后点击 OK 。 Regression Analysis: Weight versus Height The regression equation is Weight = - 205 + 5. 09 Height Predictor Coef SE Coef T P Constant -204. 74 29. 16 -7. 02 0. 000 Height 5. 0918 0. 4237 12. 02 0. 000 S = 14. 79 R-Sq = 61. 6% R-Sq(adj) = 61. 2% Analysis of Variance Source DF SS MS F P Regression 1 31592 144. 38 0. 000 Residual Error 90 19692 219 Total 91 51284 Unusual Observations Obs Height Weight Fit SE Fit Residual St. Resid 9 72. 0 195. 00 161. 87 2. 08 33. 13 2. 26 R 25 61. 0 140. 00 105. 86 3. 62 34. 14 2. 38 R 40 72. 0 215. 00 161. 87 2. 08 53. 13 3. 63 R 84 68. 0 110. 00 141. 50 1. 57 -31. 50 -2. 14 R R denotes an observation with a large standardized residual 结果解释 P值等于0,表明体重是身高的一个显著性因子,R 2 等于61. 6%表明此模型在 反应值中所占的比率。 34

 One-way Analysis of Variance for Weight Source DF Sex SS MS")
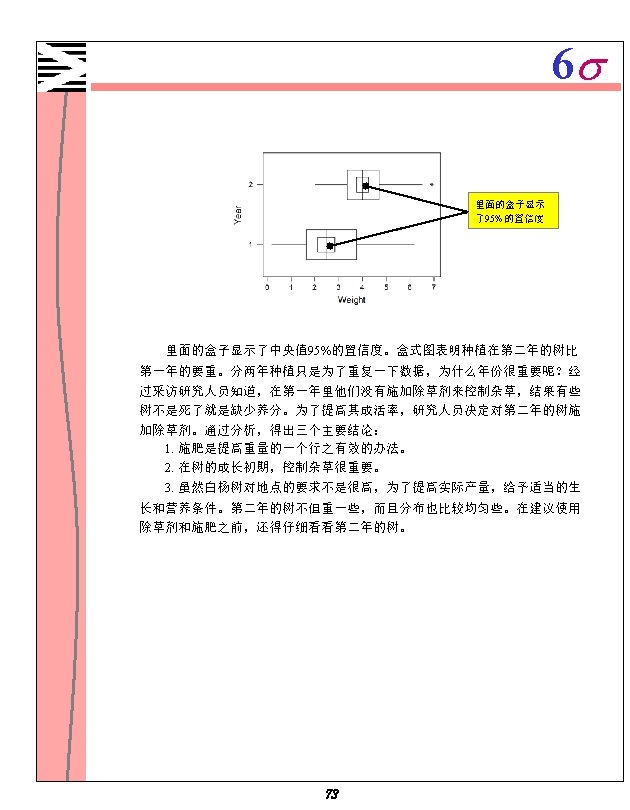
6 s 分散分析(ANOVA) One-way Analysis of Variance for Weight Source DF Sex SS MS F 1 25755 Error 90 25529 284 Total 91 51284 P 90. 80 0. 000 Individual 95% CIs For Mean Based on Pooled St. Dev Level N Mean St. Dev 1 57 158. 26 18. 64 2 35 123. 80 13. 37 --+---------+-----+---(--*-) (---*--) --+---------+-----+---- Pooled St. Dev = 16. 84 Boxplots of data 和 120 135 150 165 Normal plot of residuals 如下: 结果解释 分散分析输出结果和盒式图(boxplot)清楚地表明,女性和男性的体重是不 一样的。F统计值比较大而p值比较小,表明男女存在统计上显著性差异。女性 体重平均值的95%置信区间介限于 118和130之间但是对于男性而言, 95%置信区 间介于155和162之间. 36

 一个显示各列百分比的 二次表的例子 假设你要对不同程度吸烟者的数量及各所占比率进行统计。 1. 打开文件 PULSE. MTW。 2. 选择 Stat Tables")
6 s 表(table) 一个显示各列百分比的 二次表的例子 假设你要对不同程度吸烟者的数量及各所占比率进行统计。 1. 打开文件 PULSE. MTW。 2. 选择 Stat Tables Cross Tabulation。 3. 在 Classification variables 中,输入 4. 选中 Column percents 然后点击 OK 。 Tabulated Statistics: Smokes, Activity Rows: Smokes Columns: Activity 0 1 2 3 1 100. 00 33. 33 31. 15 23. 81 2 -66. 67 68. 85 76. 19 All 100. 00 Cell Contents -% of Col Smokers 和 Activity。 All 30. 43 69. 57 100. 00 结果解释 行表示Smokers 变量: 1表示经常吸烟者而2表示不常抽者。列表示水平程度: 1=轻 微,2=中等,3=许多(这里的0水平是因为测量者误输入),轻微抽烟者占 1/3,抽烟 量最大者占 1/4。 38

,力求固件的 重量变动最小。这些固件 5个一包。随机选择 20包画出X-R图,估计他们的制造 序管理 情况。 1.")
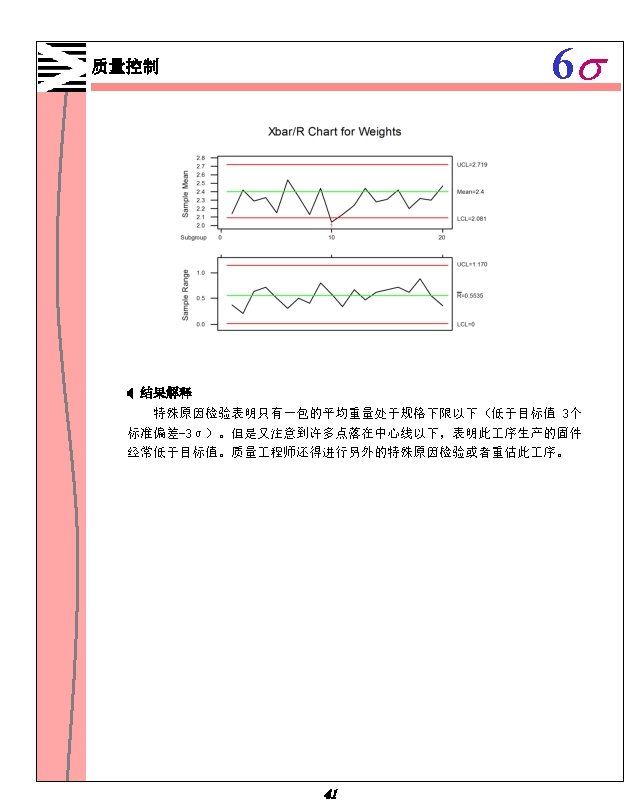
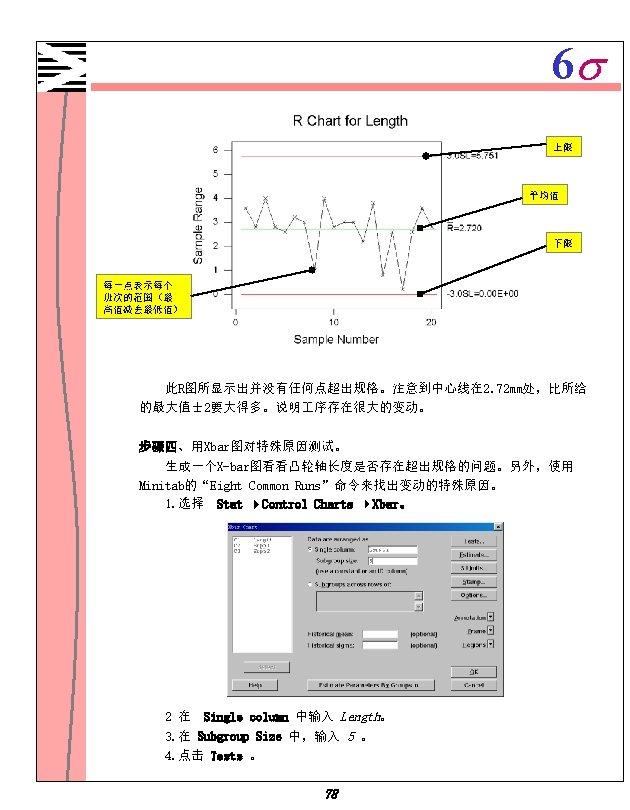
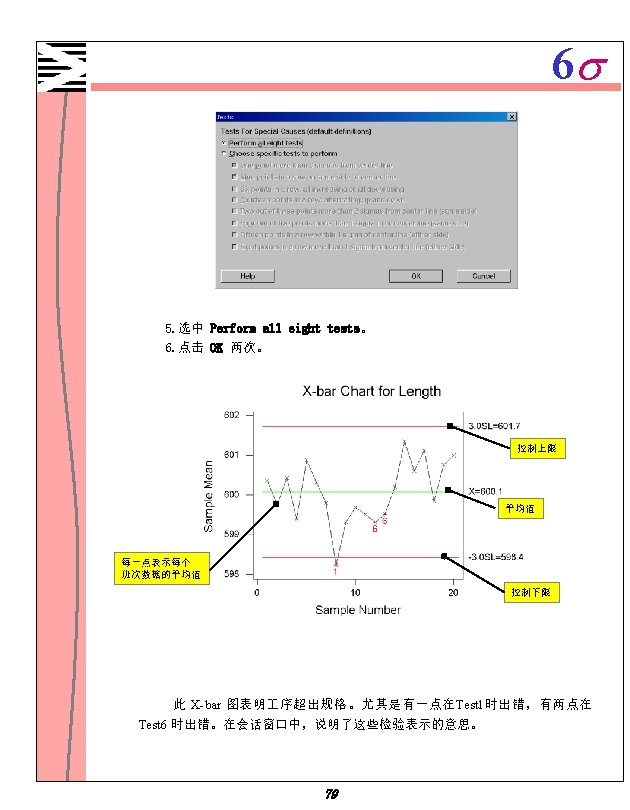
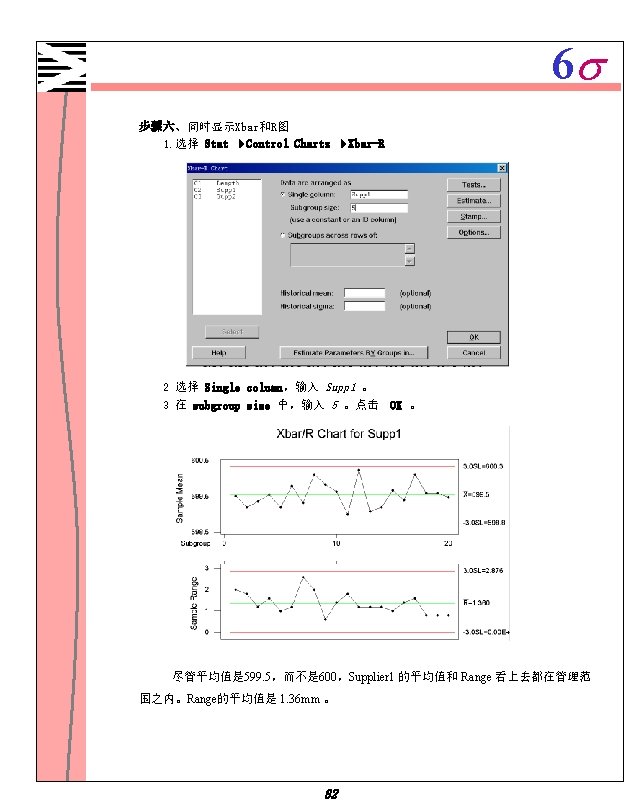
6 s 质量控制 X-R图的一个例子 一制造车间制造金属固定件,需要估计其 序能力(目标值: 2. 4克),力求固件的 重量变动最小。这些固件 5个一包。随机选择 20包画出X-R图,估计他们的制造 序管理 情况。 1. 打开文件 2. 选择 FASTENER. MTW。 Stat ControlCharts Xbar-R。 3. 在 Single column 中,输入 Weights。在 Subgroup size 中,输入 5。 4. 在 Historical mean 中输入 2. 4,点击 OK 。 Test Results for Xbar Chart TEST 1. One point more than 3. 00 sigmas from center line. Test Failed at points: 10 40




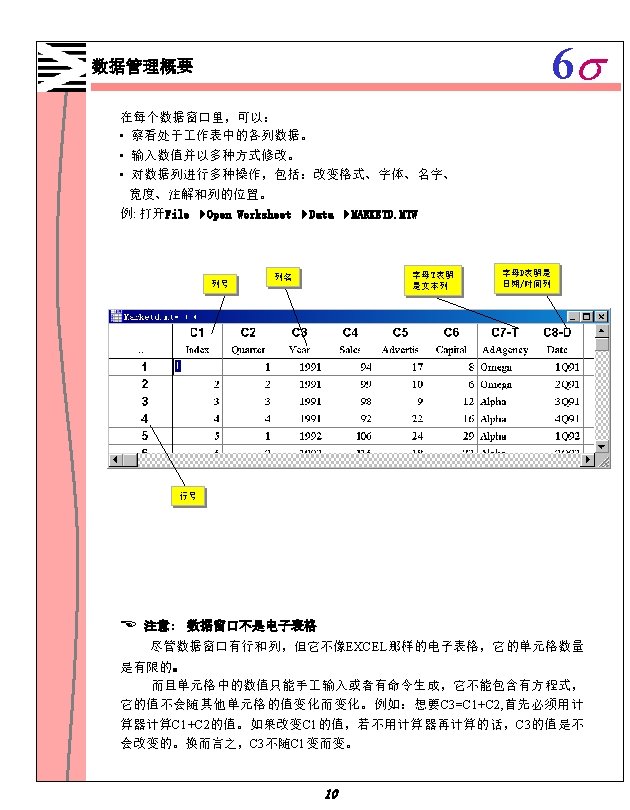
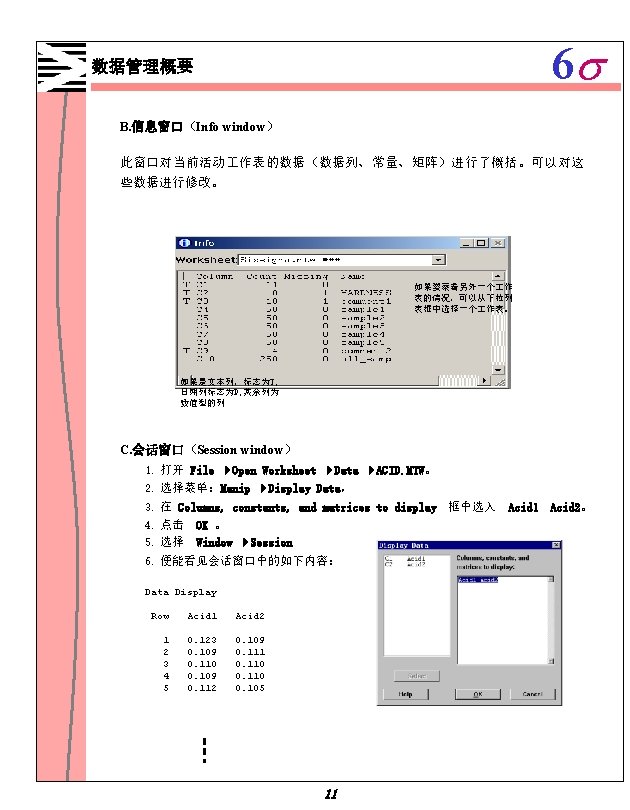
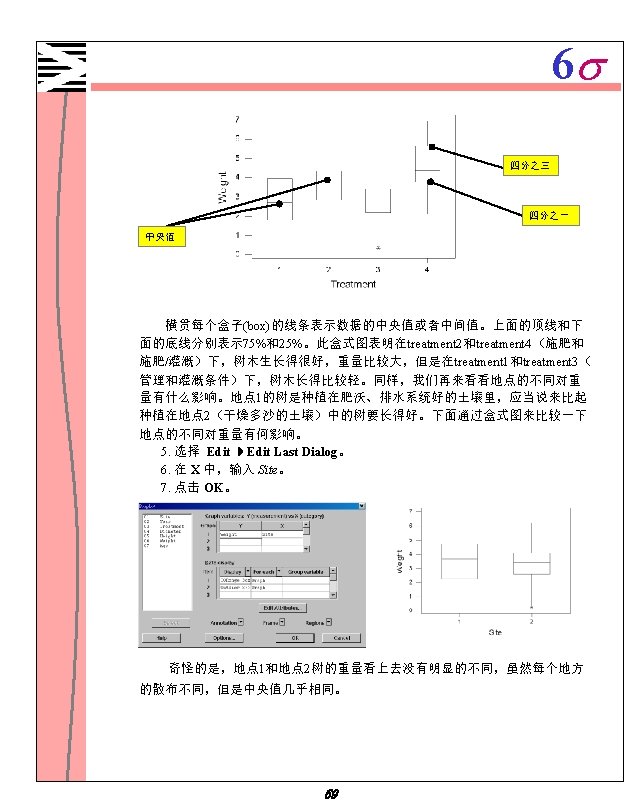
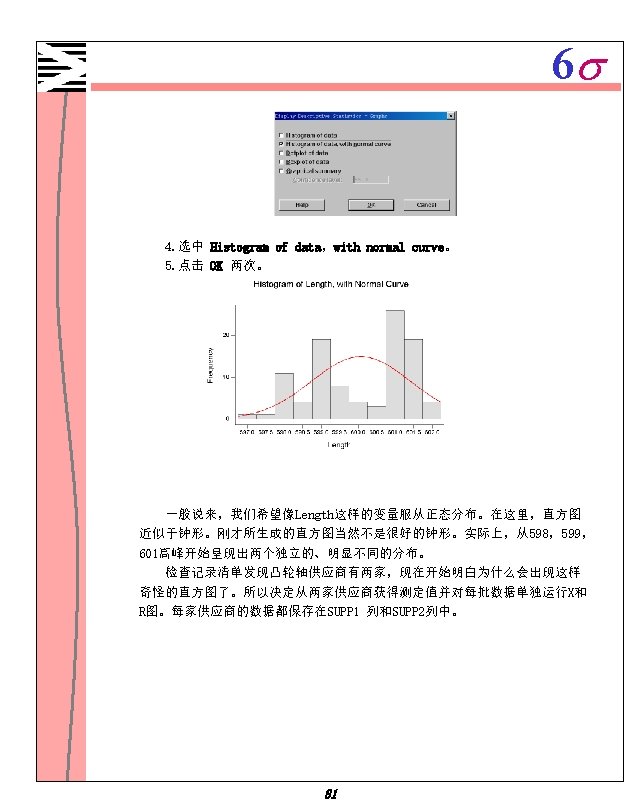
6 s 描述性统计计算 Descriptive Statistics: Diameter, Height, Weight by site Variable Diameter Height Weight site 1 2 1 2 N 10 10 10 Mean Median 2. 598 2. 320 3. 028 3. 250 4. 098 4. 120 4. 255 4. 865 0. 3090 0. 2050 0. 399 0. 380 site 1 2 1 2 SE Mean 0. 290 0. 406 0. 349 0. 396 0. 0800 0. 116 Minimum 1. 060 1. 180 1. 850 2. 200 0. 030 Tr. Mean 2. 604 3. 041 4. 175 4. 351 0. 2863 0. 356 Maximum 4. 090 4. 770 5. 730 5. 540 0. 7800 1. 110 St. Dev 0. 916 1. 284 1. 103 1. 254 0. 2528 0. 366 Q 1 2. 120 1. 488 3. 518 2. 775 0. 1575 0. 063 Boxplots of Diameter by site Q 3 3. 245 4. 053 4. 853 5. 143 0. 4600 0. 648 Boxplots of Weight by site 5 W eight D ia m e te r 1. 0 4 3 0. 5 2 2 0. 0 site 1 1 site 1 2 Boxplots of Height by site 6 H e ig h t 5 4 3 2 1 2 site 从盒式图(boxplot)可以判断出,地方 2的树比地方 1的树大。会话窗口的文本 输出包含以下信息: 在地方 2三个变量都显示出比较大的平均值和中央值。而且,变量Weight相 对其尺寸来说有一个比较大的标准偏差。在地方 2,最小重量只有0. 03 kg而最大 值是 1. 11 kg,这表明一部分白杨树生长得很好,可是其他的仅仅只是活着而已。 48
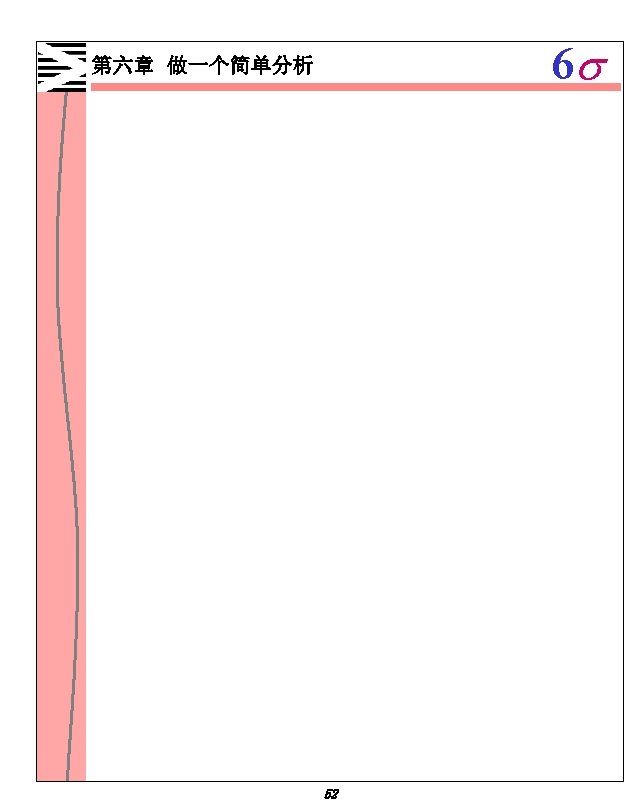


6 s 5. 在 Residuals for Plots下,点击 Standardized。 6. 在 Residuals Plots ,点击 Histogram of residuals 和 Normal plot of residuals。 7. 在 Residuals versus the variables下,输入 D 2 H。 8. 点击 OK 两次。 Minitab便显示会话窗口中的文本、三个图形。 54

6 s Regression Analysis The regression equation is Weight = 0. 0196 + 0. 00758 D 2 H Predictor Coef St. Dev Constant 0. 01961 0. 04566 D 2 H 0. 0075838 0. 0007994 S = 0. 1298 R-Sq = 83. 3% T 0. 43 9. 49 P 0. 673 0. 000 R-Sq(adj) = 82. 4% Analysis of Variance Source Regression Residual Error Total DF 1 18 19 Unusual Observations Obs D 2 H Weight 12 126 1. 1100 15 74 0. 0700 SS 1. 5155 0. 3031 1. 8187 Fit 0. 9756 0. 5779 MS 1. 5155 0. 0168 St. Dev Fit 0. 0717 0. 0374 F 89. 99 P 0. 000 Residual St Resid 0. 1344 1. 24 X -0. 5079 -4. 09 R R denotes an observation with a large standardized residual X denotes an observation whose X value gives it large influence. 55
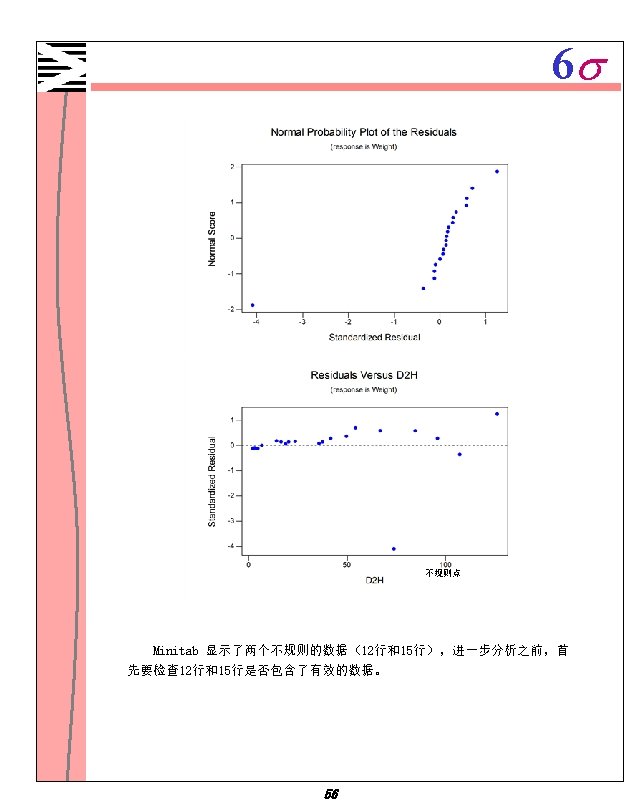


6 s 简单的重复一下前面的菜单选择。 1. 首先关闭所有图形窗口。 2. 选择 Stat Regression 。 Regression Analysis The regression equation is Weight = 0. 0200 + 0. 00829 D 2 H Predictor Coef St. Dev T P Constant 0. 01999 0. 01365 1. 46 0. 160 D 2 H 0. 0082897 0. 0002390 34. 68 0. 000 S = 0. 03880 R-Sq = 98. 5% R-Sq(adj) = 98. 4% Analysis of Variance Source DF Regression 1 Residual Error 18 Total 19 SS 1. 8108 0. 0271 1. 8379 MS 1. 8108 0. 0015 F 1202. 89 P 0. 000 Unusual Observations Obs D 2 H Weight Fit St. Dev Fit Residual St Resid 12 126 1. 11000 1. 06492 0. 02142 0. 04508 1. 39 X 17 107 0. 79000 0. 90858 0. 01740 -0. 11858 -3. 42 R R denotes an observation with a large standardized residual X denotes an observation whose X value gives it large influence. 如果有一个比较好的模型并且对所有的统计假设都感到满意的话, 那么可以 直接抽取一部分作白杨树为样本, 测量直径和高度, 然后预测其重量, 而不用把 树砍下来再去称量。 由此回归输出结果可以看出, 在系数表中, D 2 H有一个比较高的T值和很小的P 值, 有足够的理由说明D 2 H和Weight之间存在很强的关系。 在变量分析表中比较大的F统计值和值比较小的P值将这种关系量化. R的平 方(R-Sq)以及R的调和平方(R-Sq(adj))的值都大于98%, 进一步证明D 2 H与Weight 之间存在很强的线性关系。 在下最后结论之前,再看一下图表。 58

6 s 第七章 高级Minitab 62





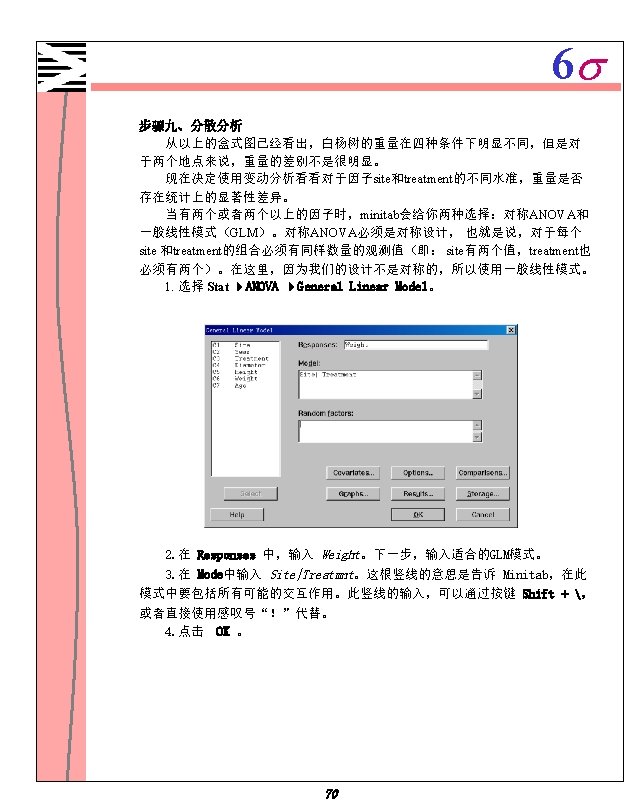

6 s General Linear Model Factor Type Levels Values Site fixed 2 1 2 Treatmen fixed 4 1 2 3 4 Analysis of Variance for Weight, using Adjusted SS for Tests Source DF Seq SS Adj MS F P Site 1 3. 112 2. 424 1. 52 0. 219 Treatmen 3 78. 005 78. 275 26. 092 16. 39 0. 000 Site*Treatmen 3 10. 509 3. 503 2. 20 0. 091 Error 140 222. 873 1. 592 Total 147 314. 498 Unusual Observations for Weight Obs Weight Fit St. Dev Fit Residual St Resid 22 0. 35000 2. 91200 0. 28213 -2. 56200 -2. 08 R 42 0. 64000 3. 34167 0. 29739 -2. 70167 -2. 20 R 43 0. 16000 3. 34167 0. 29739 -3. 18167 -2. 59 R 52 0. 66000 3. 52250 0. 28213 -2. 86250 -2. 33 R 64 2. 36000 4. 90889 0. 29739 -2. 54889 -2. 08 R 69 2. 12000 4. 90889 0. 29739 -2. 78889 -2. 27 R 72 5. 82000 3. 34167 0. 29739 2. 47833 2. 02 R R denotes an observation with a large standardized residual. 在这个模式中,GLM列出了每个因子以及每因子的水平数,然后列出了变 动分析表,最后是不规则数据表。 假设要对此模式中的每个影响进行 F-test。例如:要验证原假设(条件的影 响对于两个地点是相同的—Site*Treatment的交互作用),用Minitab的P值与最常 用的0. 05水平值进行比较。因为p-value为 0. 091,它大于0. 05,所以你不能拒绝原 假设。也就是说,不能得出“条件对地点的影响不同”的结论。 现在看看Site和Treatment的主效果。Site的p值是 0. 219,同样大于0. 05,所 以也不能得出“树的重量在两个地点之间存在显著性差异”的结论。而Treatment 的p值很小,只有0. 000,因此可以说对于不同的条件,树的平均重量存在显著性 差异。 这与以前画的盒式图是相吻合——树的重量在不同条件下不同,而对于两 个地点来说只存在轻微的差别。在作出“条件是影响重量的唯一重要因子”结论之 前,再看看年份对于重量的影响——别忘了,研究人员分两年种植了这批树。 71
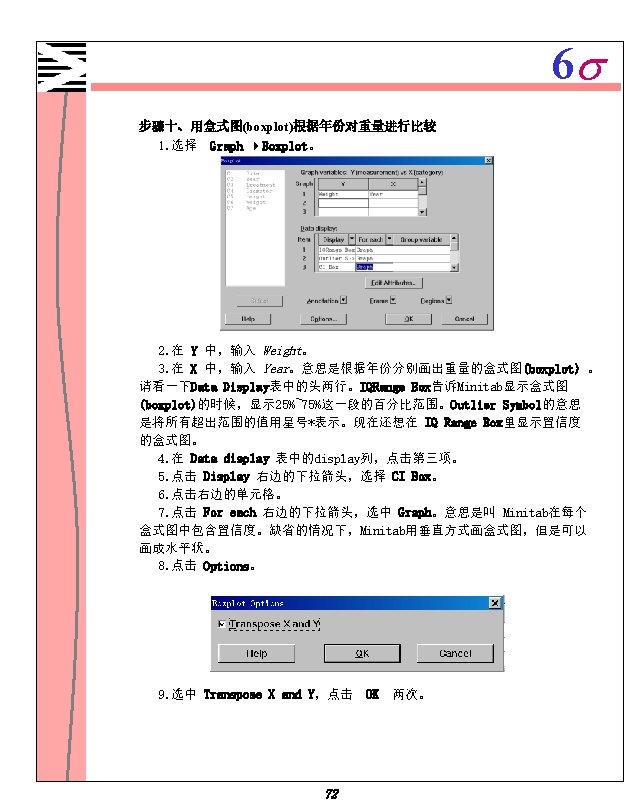



 2. 选中")
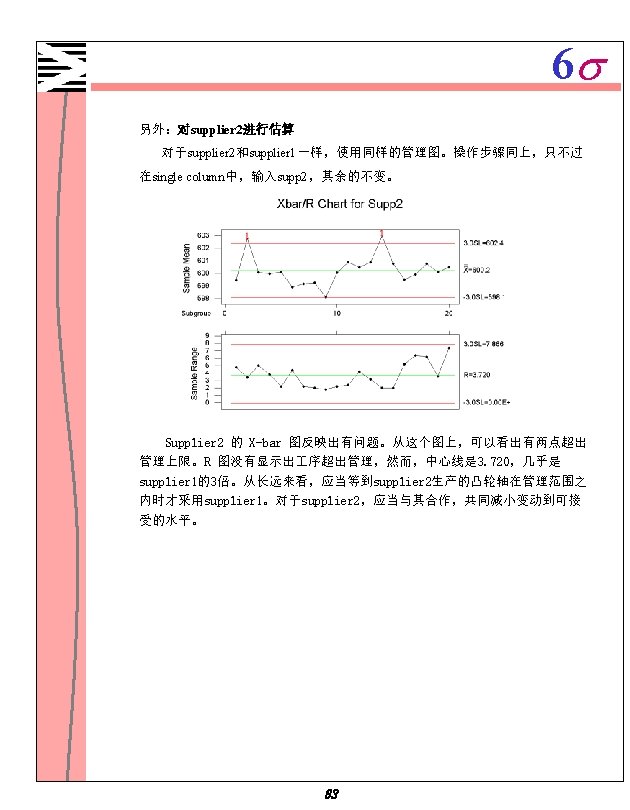
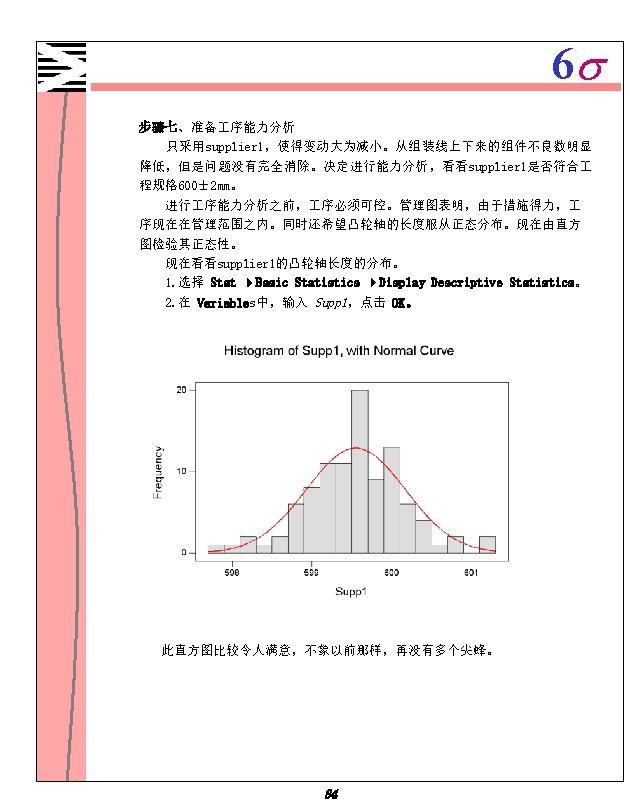
6 s 步骤八、 进行 序能力分析。 1. 选择 Stat Qulity Tools Capability Analysis(Normal) 2. 选中 Single column 输入 Supp 1 。 3. 在 Subgroup size 中,输入 5 。 4. 在 Lower spec 中,输入 598 。 5. 在 Upper spec,输入 602 。 6. 点击 Options 。 7. 在 Target(adds Cpm to table),输入 600 。 8. 点击 OK 。 85
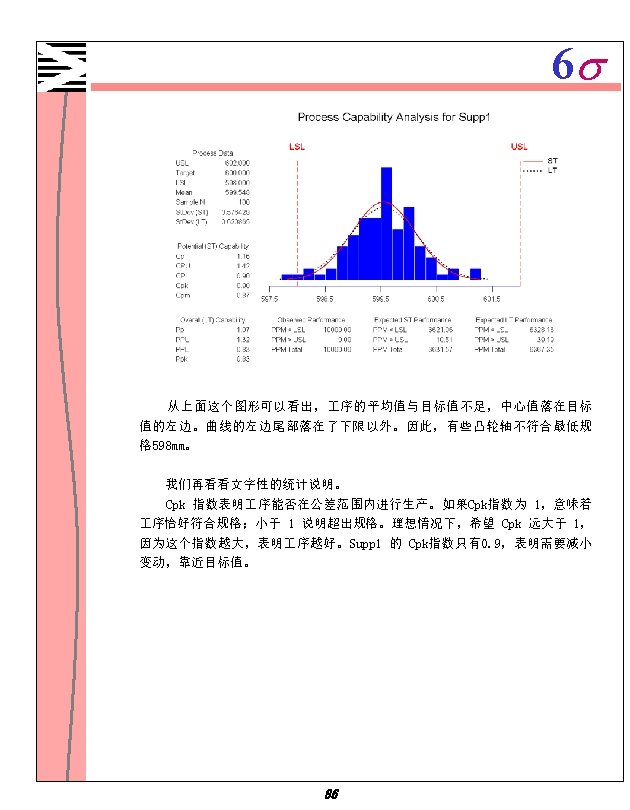



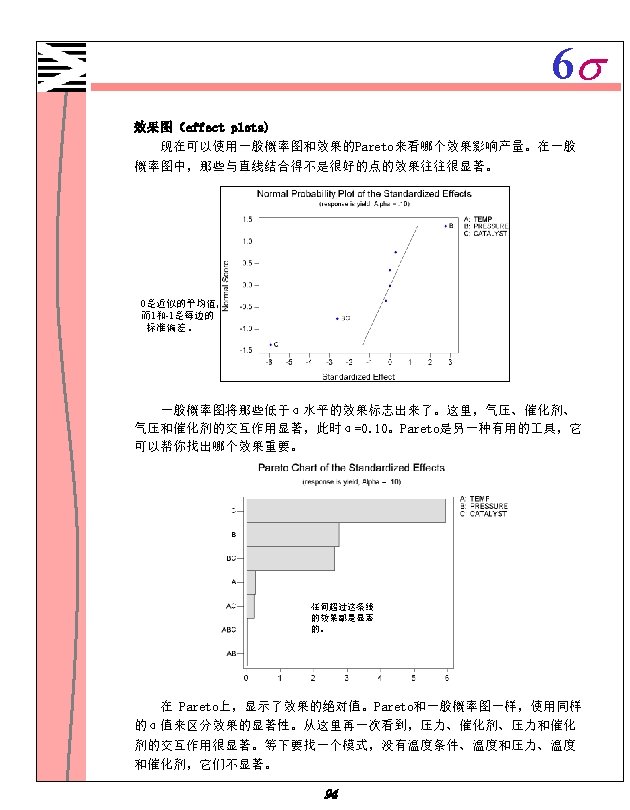
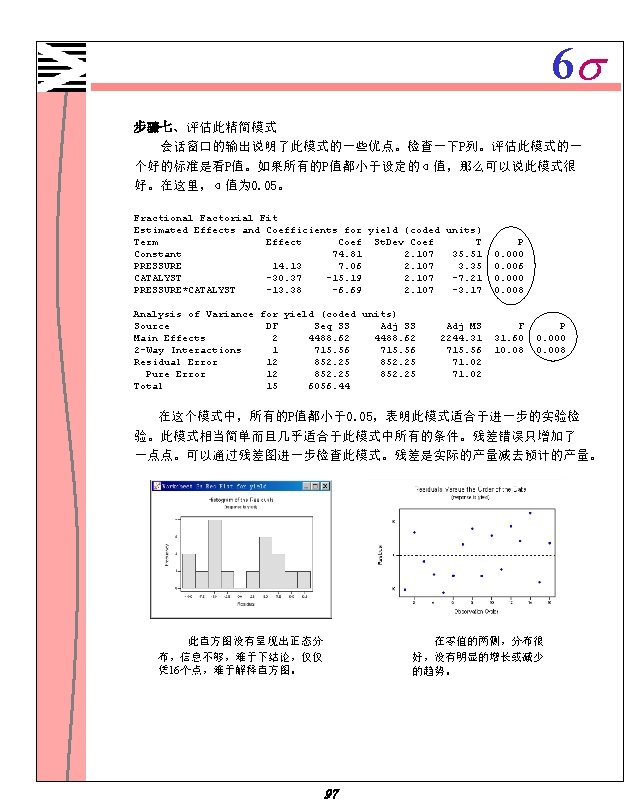
6 s 4. 为了生成两个效果图以便知道哪个效果显著些,选中 Normal 和Pareto, 使用缺省值α。 5. 两次点击 OK。 Fractional Factorial Fit Estimated Effects and Coefficients for yield (coded units) Term Effect Coef St. Dev Coef T P Constant 74. 81 2. 561 29. 21 0. 000 TEMP 1. 38 0. 69 2. 561 0. 27 0. 795 PRESSURE 14. 12 7. 06 2. 561 2. 76 0. 025 CATALYST -30. 37 -15. 19 2. 561 -5. 93 0. 000 TEMP*PRESSURE -0. 13 -0. 06 2. 561 -0. 02 0. 981 TEMP*CATALYST -1. 13 -0. 56 2. 561 -0. 22 0. 832 PRESSURE*CATALYST -13. 37 -6. 69 2. 561 -2. 61 0. 031 TEMP*PRESSURE*CATALYST -0. 13 -0. 06 2. 561 -0. 02 0. 981 Analysis of Variance for yield (coded units) Source DF Seq SS Adj MS F P Main Effects 3 4496. 19 1498. 73 14. 28 0. 001 2 -Way Interactions 3 720. 69 240. 23 2. 29 0. 155 3 -Way Interactions 1 0. 06 0. 00 0. 981 Residual Error 8 839. 50 104. 94 Pure Error 8 839. 50 104. 94 Total 15 6056. 44 完成了一个完全模式,它包含三个主效果、三个二次交互作用、一个三次交 互作用。在 Estimated Effects and coefficients 表中,根据P列的值决定哪 个效果显著。因为使用的α值是 0. 05,气压、催化剂、气压和催化剂的交互作 用显著,也就是说,他们的P值小于0. 05。 93
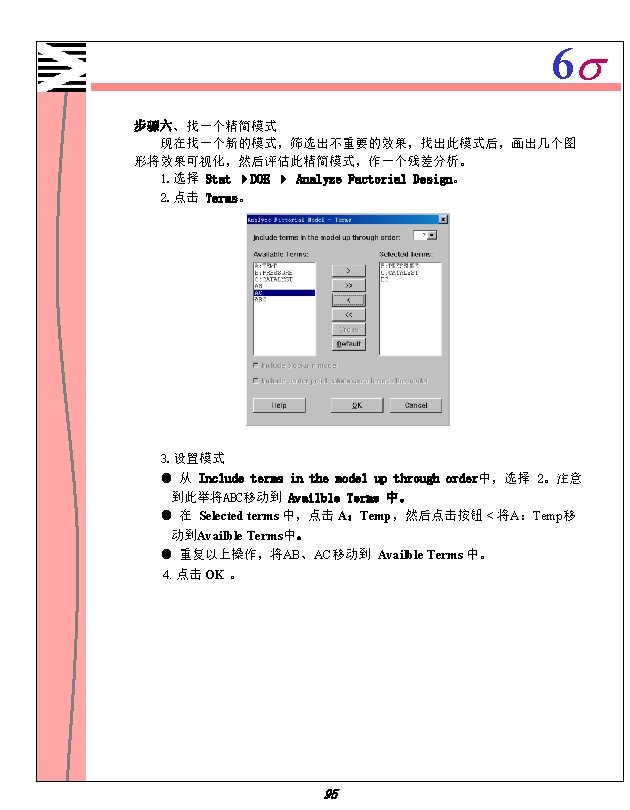

6 s 5. 点击Graphs,将Normal、Pareto不选中。 6. 选中 Histogram, Normal plot,Residuals versus fits和Residuals versus order. 点击 OK 。 7. 在主对话框中点击 OK 。 96


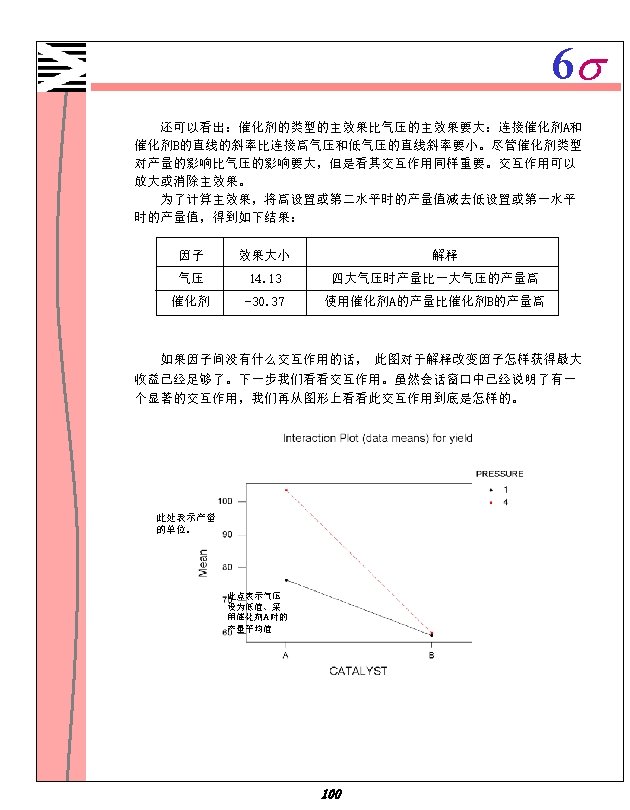

- Slides: 102