4 Anwendung der logistic Regression auf die Berechung

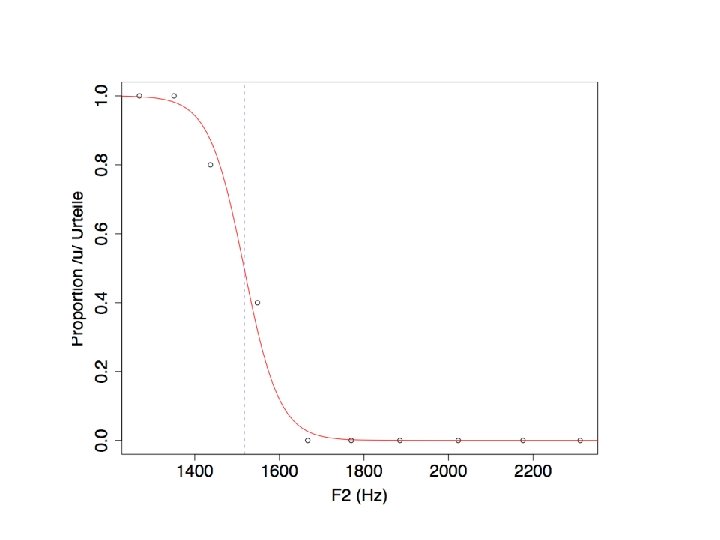
4. Anwendung der logistic Regression auf die Berechung einer perzeptiven Grenzen zwischen Kategorien Experiment. Anhand der Sprachsynthese wurde ein F 2 Kontinuum in 11 Schritten synthetisiert. 5 Vpn. (L 1 Englisch) mussten zu jedem Stimulus mit "I" oder "U" antworten. Bei welchem F 2 -Wert liegt die Grenze zwischen den Vokalen? Die Anzahle der Bewertungen ist hier: ui 2311 2176 2023 1885 1770 1667 1548 1437 1351 1269 u 0 0 0 2 4 5 5 i 5 5 5 3 1 0 0 Bei F 2 = 1437 Hz gab es 4 Urteil für "U", ein Urteil für "I"
![Ein Vektor von Proportionen p = ui[, 1]/apply(ui, 1, sum) p Bei 1437 Hz](http://slidetodoc.com/presentation_image_h2/e35b7b3eafb205b0fef892238a554039/image-2.jpg "Ein Vektor von Proportionen p = ui[, 1]/apply(ui, 1, sum) p Bei 1437 Hz")
Ein Vektor von Proportionen p = ui[, 1]/apply(ui, 1, sum) p Bei 1437 Hz waren 80% der Urteile "U" (und daher 20% "I") 2311 2176 2023 1885 1770 1667 1548 1437 1351 1269 0. 0 0. 4 0. 8 1. 0 Eine Abbildung von F 2 als Funktion dieser Proportionen f 2 werte = as. numeric(rownames(ui)) plot(f 2 werte, p, ylab="Proportion /u/ Urteile", xlab="F 2 (Hz)")

Eine logistische Regression an diese Werte anpassen Die Urteile aus den F 2 -Werten vorhersagen logui = glm(ui ~ f 2 werte, family=binomial) Mit der Methode auf S. 13 -14 die logistische Regressionskurve überlagern Die Koeffiziente m = coef(logui)[2] k = coef(logui)[1] Die logistische Regressionskurve curve(exp(m*x + k)/(1+ exp(m*x+k)), xlim=c(1200, 2400), add=T, col=2)
 = zu welchem F 2 -Wert, ist ein Urteil für")
Die 50% Grenze (Umkipppunkt) = zu welchem F 2 -Wert, ist ein Urteil für "I" genauso wahrscheinlich wie ein Urteil für "U"? Es kann bewiesen werden, dass dies mit -k/m in dieser Formel gegeben wird (in diesem Beispiel ist y die Proportion, p, und x ist F 2 werte) -k/m 1516. 723 abline(v=-k/m, lty=2, col="blue")

6. Zwei unabhängige Variablen. Hier sind genau dieselben Daten aber zusätzlich nach männlich-weiblich aufgeteilt. female n y lost n n y y 1950 16 14 0 5 1960 9 9 6 15 1971 8 7 10 16 1980 8 5 7 13 1993 4 0 10 22 2005 1 1 15 19 In 1971 waren 26 Tokens [lost] und 15 [lo: st] lost von diesen 26 waren 10 von Männern und 16 von Frauen erzeugt. (a) Gibt es einen Trend? Also weniger [lo: st] in späteren Jahren? 8 M, 7 F 1950 1960 1971 1980 1993 2005 high low 30 5 18 21 15 26 13 20 4 32 2 34 (b) Ist die Proportion [lost]/[lo: st] in M und F unterschiedlich verteilt?

female n y lost n n y y 1950 16 14 0 5 1960 9 9 6 15 1971 8 7 10 16 1980 8 5 7 13 1993 4 0 10 22 2005 1 1 15 19 Dies ist ein Problem der mehrfachen Logistic Regression: (also in diesem Fall eine Linie im 3 D-Raum) logodds (lo: st) = b 0 + b 1 year + b 2 Geschlecht logodds(lo: st) (b 0 ist das Intercept, b 1 und b 2 die Neigungen) Und eine gerade Linie in einem 3 D -Raum Geschlecht Year

Daten-Vorbereitung pfad = "das Verzeichnis wo ich lost 2. txt gespeichert habe" lost 2 = as. matrix(read. table(paste(pfad, "lost 2. txt", sep="/"))) high = Spalte 1 = /lo: st/ low = Spalte 2 = /l. Ost/ J = c(jahr, jahr) J [1] 0. 0 10. 0 21. 0 30. 0 43. 0 55. 0 0. 1 10. 1 21. 1 30. 1 43. 1 55. 1 0 10 21 30 43 55 high 16 9 8 8 4 1 14 9 7 5 0 1 low 0 6 10 7 10 15 5 15 16 13 22 19 1950 1960 1971 1980 1993 2005 0 10 21 30 43 55 G = c(rep(0, 6), rep(1, 6)) [1] 0 0 0 1 1 1 G } } M W

Zuerst eine Abbildung… 0. 0 mean of p 0. 4 0. 8 p = lost 2[, 1]/apply(lost 2, 1, sum) interaction. plot(J, G, p) Nimmt die Proportion von /lo: st/ in späteren Jahren ab? G (Die Unterschiede zwischen m m und f ignorieren). f Ja 0 10 21 30 43 55 Nein Vielleicht J Unterscheiden sich m und f in der Proportion von /lo: st/? (Die Unterschiede in den Jahrgängen ignorieren). Ja Nein Vielleicht
 Wenn wir übrigens")
Modell berechnen… mehrg = glm(lost 2 ~ J + G, binomial) Wenn wir übrigens G weglassen, dann müssten wir trotz der anderen Aufteilung der Daten das gleiche Ergebnis wir vorhin bekommen: g 2 = glm(lost 2 ~ J, binomial) anova(g 2, test="Chisq") Analysis of Deviance Table Df Deviance Resid. Df Resid. Dev P(>|Chi|) NULL 11 89. 557 year 1 61. 121 10 28. 436 5. 367 e-15
 mehrg Coefficients: (Intercept) J Gm")
mehrg = glm(lost 2 ~ J + G, binomial) mehrg Coefficients: (Intercept) J Gm 1. 87754 -0. 07524 1. 20282 Degrees of Freedom: 11 Total (i. e. Null); 9 Residual Null Deviance: 89. 56 Residual Deviance: 15. 61 AIC: 51. 51 logodds(lo: st) = 1. 87754 - 0. 07524 J+ 1. 20282 G anova(mehrg, test="Chisq") NULL J G Df Deviance Resid. Df Resid. Dev P(>|Chi|) 11 89. 557 1 61. 121 10 28. 436 5. 367 e-15 1 12. 822 9 15. 613 3. 425 e-04 Die Proportion von 'lo: st' nimmt in späteren Jahren ab, c 2(1) = 61. 12, p < 0. 001. M und F unterscheiden sich in der Proportion von lo: st/l. Ost, c 2(1) = 12. 82, p < 0. 001

7. Die Interaktion zwischen 2 Variablen Mit 2 oder mehr Variablen soll auch geprüft werden, ob sie miteinander interagieren. Eine Interaktion zwischen den unabhängigen Variablen – in diesem Fall Geschlecht und Jahrgang – liegt vor, wenn sie eine unterschiedliche Wirkung auf die abhängige Variable ausüben wie in 1 und 2, aber nicht in 3 und 4 prop(lo: st) f prop(lo: st) m 2000 1950 2000 1 1950 2000 2 1950 2000 3 1950 4

Die Interaktion zwischen 2 Variablen Wenn eine Interaktion vorliegt, dann können signifikante Ergebnisse in einer der unabhängigen Variablen nicht uneingeschränkt akzeptiert werden. z. B wenn eine Interaktion vorkommt, gibt es vielleicht eine Wirkung von Jahrgang auf die Proportion von /lo: st/ nur in Männern aber nicht in Frauen usw. dies scheint aber hier nicht der Fall zu sein.

Die Interaktion zwischen 2 Variablen Die Interaktion zwischen 2 unabhängigen Variablen, A und B, kann in R mit A: B geprüft werden. Daher in diesem Fall g = glm(lost 2 ~ J + G + J: G, binomial) Eine Abkürzung dafür (und mit genau demselben Ergebnis) g = glm(lost 2 ~ J * G, binomial) anova(g, test="Chisq") NULL J G J: G 1 1 1 Df Deviance Resid. Df Resid. Dev P(>|Chi|) 11 89. 557 61. 121 10 28. 436 5. 367 e-15 12. 822 9 15. 613 3. 425 e-04 0. 017 8 15. 596 0. 896 d. h. die Interaktion ist nicht signifikant und J: G kann aus dem Regressionsmodell weggelassen werden.
 bestätigt: library(MASS) step. AIC(g) Start: AIC= 53. 49")
Dies wird auch durch step. AIC() bestätigt: library(MASS) step. AIC(g) Start: AIC= 53. 49 lost 2 ~ J * G Df Deviance AIC - J: G 1 15. 613 51. 506 <none> 15. 596 53. 489 AIC wird kleiner wenn wir J: G weglassen Df Deviance AIC <none> 15. 613 51. 506 - G 1 28. 436 62. 328 - J 1 80. 018 113. 910 Wir bleiben also bei Call: glm(formula = lost 2 ~ J + G, family = binomial) Residual Deviance: 15. 61 AIC: 51. 51

Weitere Folien zum Durchlesen. . .

8. Logistic Regression und zwei Ebenen Aus dem vorigen Beispiel wird auch klar, dass ähnlich wie c 2 Logistic Regression angewandt werden kann, auch wenn die Gruppe nur aus 2 Ebenen besteht. Gibt es einen signifikanten Unterschied zwischen M und F? gmf = glm(lost 2 ~ G, "binomial") anova(gmf, test="Chisq") Df Deviance Resid. Df Resid. Dev P(>|Chi|) NULL 11 89. 557 G 1 9. 539 10 80. 018 0. 002 M und F unterscheiden sich in der Proportion von lo: st/l. Ost (c 2(1) = 9. 5, p < 0. 002).

Wir bekommen dasselbe Ergebnis wenn Logistic Regression auf die entsprechende Tabelle angewandt wird: m = apply(lost 2[1: 6, ], 2, sum) f = apply(lost 2[7: 12, ], 2, sum) mf = rbind(m, f) rownames(mf) = c(0, 1) colnames(mf) = c("high", "low") mf lost 2 0. 0 10. 0 21. 0 30. 0 43. 0 55. 0 0. 1 10. 1 21. 1 30. 1 43. 1 55. 1 high low 16 0 9 6 8 10 8 7 4 10 1 15 14 5 9 15 7 16 5 13 0 22 1 19 = high low 0 46 48 1 36 90 (kodiert nur nach M und F) l. mf = c(0, 1) gmf 2 = glm(mf ~ l. mf, "binomial") anova(gmf 2, test="Chisq")

und man bekommt dann fast das gleiche Ergebnis mit einem c 2 -Test, der direkt auf die Tabelle angewandt wird: chisq. test(mf) Pearson's Chi-squared test with Yates' continuity correction data: mf X-squared = 8. 6985, df = 1, p-value = 0. 003185 Ein c 2 -Test kann jedoch nicht verwendet werden, bei einer Gruppenanzahl von > 2 …

3 Gruppen jeweils 2 Ebenen lost 3 alt. 0 alt. 1 jung. 0 jung. 1 high 43 30 3 6 low 35 15 13 75 Hier sind dieselben Daten aufgeteilt in 2 Altersgruppen sowie M/F Gruppe 1 = Vokal = high/low Gruppe 2 = Geschl = M/F (=0/1) Gruppe 3 = Alter = alt/jung Haben (a) Alter und (b) Geschlecht einen Einfluss auf die Proportion von /lo: st/?

Zuerst eine Abbildung high low alt. 0 43 35 alt. 1 30 15 jung. 0 3 13 jung. 1 6 75 # Alter kodieren A = c(0, 0, 1, 1) # Geschlecht kodieren G = c(0, 1, 0, 1) prop = lost 3[, 1]/apply(lost 3, 1, sum) interaction. plot(A, G, prop)

0. 3 0. 4 0. 5 0 1 0. 2 mean of prop 0. 6 G 1 0 A Signifikanter Einfluss auf lo: st/l. Ost? im Alter? ja nein vielleicht im Geschlecht? ja nein vielleicht Interaktion zwischen A und G?
 anova(g, test=\"Chisq\") Df Deviance Resid.")
g = glm(lost 3 ~ A * G, binomial) anova(g, test="Chisq") Df Deviance Resid. NULL A 1 64. 452 G 1 0. 398 A: G 1 2. 908 Df Resid. Dev P(>|Chi|) 3 67. 758 2 3. 306 9. 893 e-16 1 2. 908 0. 528 0 -4. 441 e-16 0. 088 Es gab einen signifikanten Einfluss vom Alter (c 2(1)=64. 2, p < 0. 001) aber nicht vom Geschlecht auf die Proportion von /lo: st/. Die Interaktion zwichen Alter und Geschlecht war nicht signifikant (p > 0. 05).
- Slides: 23