31 classifiers from the Bayesian world 21032017 Bayes
 classifiers from the Bayesian world 21/03/2017")
3(+1) classifiers from the Bayesian world 21/03/2017
 =")
Bayes classifier • Bayes decision theory • Bayes classifier P( j | x) = P(x | j ) · P ( j ) / P(x) • Discriminant function in the case of normal likelihood • Parameter estimation: – Form of the density is known – The density is defined by a few parameters – Estimate the parameters from data

Example age debit income leave? <21 none < 50 K yes 21 -50 yes 50 K-200 K yes 50< yes 50 K-200 K no 21 -50 yes 200 K< no 50< none 200 K< ?

Naϊve Bayes

Naϊve Bayes The Naive Bayes classifier is a Bayes classifier where we assume the conditional independence of the features:
![Naϊve Bayes Two-category case x = [x 1, x 2, …, xd ]t where](http://slidetodoc.com/presentation_image_h2/e1b870d6efeb0a58501bb2d16a5c9802/image-6.jpg "Naϊve Bayes Two-category case x = [x 1, x 2, …, xd ]t where")
Naϊve Bayes Two-category case x = [x 1, x 2, …, xd ]t where each xi is binary and pi = P(xi = 1 | 1) qi = P(xi = 1 | 2)


Training Naive Bayes - MLE • Goal: estimate pi = P(xi = 1 | 1 ) and qi = P(xi = 1 | 2 ) based on N training samples • assume that pi and qi are binomial • Maximum Likelihood estimation is:
![Training Naive Bayes – Bayes estimation Beta distribution X ~ Beta(a, b) E [X]=1/(1+b/a)](http://slidetodoc.com/presentation_image_h2/e1b870d6efeb0a58501bb2d16a5c9802/image-9.jpg "Training Naive Bayes – Bayes estimation Beta distribution X ~ Beta(a, b) E [X]=1/(1+b/a)")
Training Naive Bayes – Bayes estimation Beta distribution X ~ Beta(a, b) E [X]=1/(1+b/a)

Training Naive Bayes – Bayes estimation • assume that pi and qi are binomial • we use Beta distribution to represent uncertainty of the estimation … 2 steps of Bayes estimation …
 • in practice: – – avoding 0")
Training Naive Bayes – Bayes estimation (m-estimate) • in practice: – – avoding 0 likelihood/posteriori m and p are constants (metaparameters) p is the prior guess for each pi m is the „equivalent sample size”

Naϊve Bayes in practice • • not so naive fast, easily distributable low memory good choice if there are – many features – and potentially each feature can contribute to the solution
 age debit income leave? <21 none < 50 K yes 21")
Example P( ) age debit income leave? <21 none < 50 K yes 21 -50 yes 50 K-200 K yes 50< yes 50 K-200 K no 21 -50 yes 200 K< no 50< none 200 K< ? P(age>50| =yes) = (0+mp) / 2+m P(none debit| =yes) P(200 K<income| =yes)

Generative vs. Discriminative Classifiers • Generative: • Modeling the data belonging to each class, i. e. how they are generated • Bayes: likelihood P(x | j ) and apriori P( j ) are estimated • Discriminative: • Goal is the discrimination of classes • Bayes: direct estimation of the posteriori P( j | x) x 1 x 2 x 3
 Two-category case: Training (MLE):")
Logistic Regression (Maximum Entropy Classifier) Two-category case: Training (MLE):

Non-parametric Bayes classifiers

Non-parametric estimation of densities Non-parametric estimation techniques do not assume the form the density Bayes classifier: non-parametric estimation of likelihood P(x | j ), i. e. generative or directly the posteriori P( j | x), i. e. discriminative 17
 – Probability that a vector x will fall")
Non-parametric estimation 18 – estimate p(x) – Probability that a vector x will fall in region R is: – P is a smoothed (or averaged) version of the density function p(x) if we have a sample of size n; therefore, the expected value that k points fall in R is then: k = n. P Pattern Classification, Chapter 2 (Part 1)
 is continuous and that the region R")
Non-parametric estimation applying MLE for P: p(x) is continuous and that the region R is so small that p does not vary significantly within it: where is a point within R and V the volume enclosed by R. 19

20 Convergence of non-parametric estimations • The volume V needs to approach 0 anyway if we want to use this estimation • Practically, V cannot be allowed to become small since the number of samples is always limited
 to")
Convergence of non-parametric estimations Three necessary conditions should apply if we want pn(x) to converge to p(x): 21

22

Parzen windows • the volume and the form of R is fixed • V is constant (n is constant) • p(x) is estimated by the count down of points of the training sample in R around x =k
/hn) is equal to unity")
24 Parzen windows- hypercube R is a d-dimensional hypercube ((x-xi)/hn) is equal to unity if xi falls within the hypercube of volume Vn centered at x and equal to zero otherwise. ( is called a kernel)

25 Parzen windows- hypercube number of samples in this hypercube:
 estimates p(x) like the average of a distance between x")
Generalized Parzen Windows pn(x) estimates p(x) like the average of a distance between x and (xi) (i = 1, … , n) samples can be any function between x and xi
 ~ N(0, 1) (u) = (1/ (2 )")
27 Parzen windows - example p(x) ~ N(0, 1) (u) = (1/ (2 ) exp(-u 2/2) and hn = h 1/ n (n>1)

28

29

30

31
 ?")
32 p(x) ?
 = 1 U(a, b) + 2 T(c, d) (mixture of")
33 real generator: p(x) = 1 U(a, b) + 2 T(c, d) (mixture of an uniform and a triangular density)

Parzen windows as classifiers • Parzen Windows are used for modelling/estimation of the multidimensional likelihood • Generative classifier • The decision surface/regions are highly depend on the kernel and kernel length 34

35
 age debit income leave? <21 none < 50 K yes 21")
Example P( ) age debit income leave? <21 none < 50 K yes 21 -50 yes 50 K-200 K yes 50< yes 50 K-200 K no 21 -50 yes 200 K< no 50< none 200 K< ? P(age>50, none debit, 200 K<income | =yes) = ? j can be the number of feature where tha values of j x and xi are different

k nearest neighbor estimation a solution for the problem of the unknown “best” window function: • Let the cell volume be a function of the training data • Center a cell about x and let it grows until it captures kn samples (kn = f(n)) • kn are called the kn nearest-neighbors of x 37
")
38 © Ethem Alpaydin: Introduction to Machine Learning. 2 nd edition (2010)
 P( i | x) direct estimation form n training")
k nearest neighbor classifier (knn) P( i | x) direct estimation form n training samples – take the smallest R around x which includes k samples out of n – if ki out of k is labeled by i : pn(x, i) = ki /(n. V) 39
 – ki /k is the fraction of the samples")
k nearest neighbor classifier (knn) – ki /k is the fraction of the samples within the cell that are labeled i – For minimum error rate, the most frequently represented category within the cell is selected – If k is large and the cell sufficiently small, the performance will approach the best possible 40

41

Példa age debit income leave? <21 none < 50 K yes 21 -50 yes 50 K-200 K yes 50< yes 50 K-200 K no 21 -50 yes 200 K< no 50< none 200 K< ? k=3 Distance metric = how many features are different

Non-parametric classifiers • They HAVE got parameters! • Non-parametric classifiers are Bayes classifiers which use non-parametric denstiy estimation approaches • Parzen-windows classifier – kernel and h length – genarative • k nearest neighbor classifier – distance metric and k – discriminative

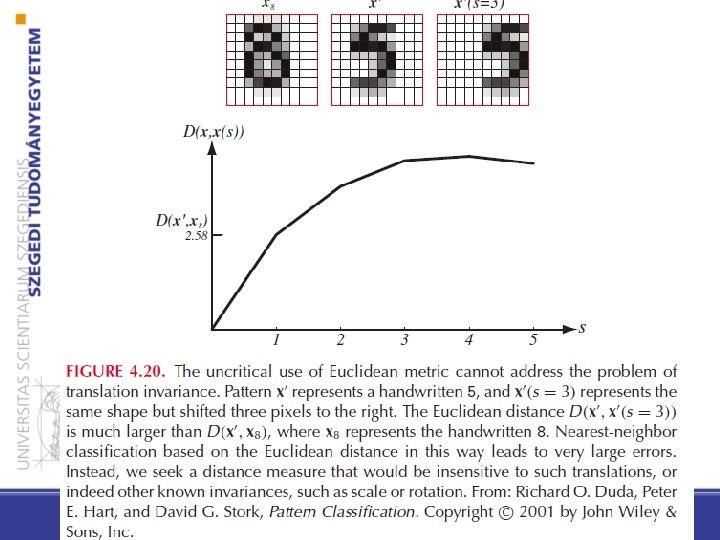
about distance metrics
 Naive Bayes")
Summary Bayes classifiers in practice Parametric Non-parametric Generative (estimation of the likelihood) Naive Bayes Parzen windows classifier Discriminative (direct estimation of the Posteriori) Logistic Regression k nearest neighbor classifier
- Slides: 46