3 CALL MPICOMMRANKcomm rank ierr IF rank EQ







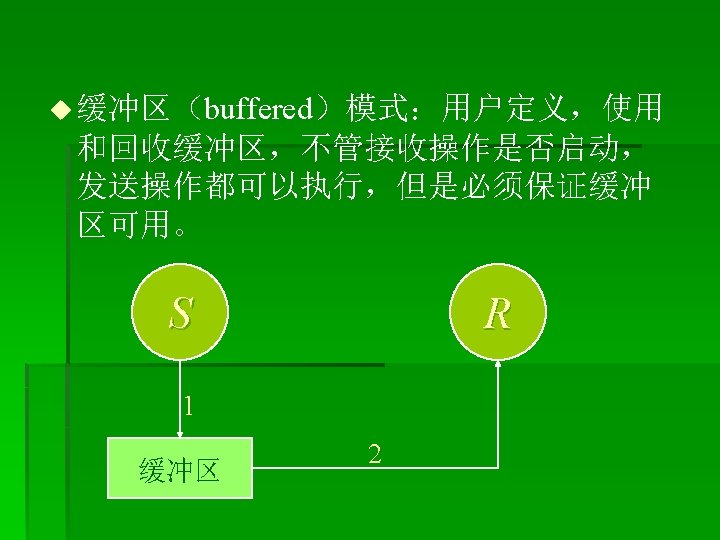
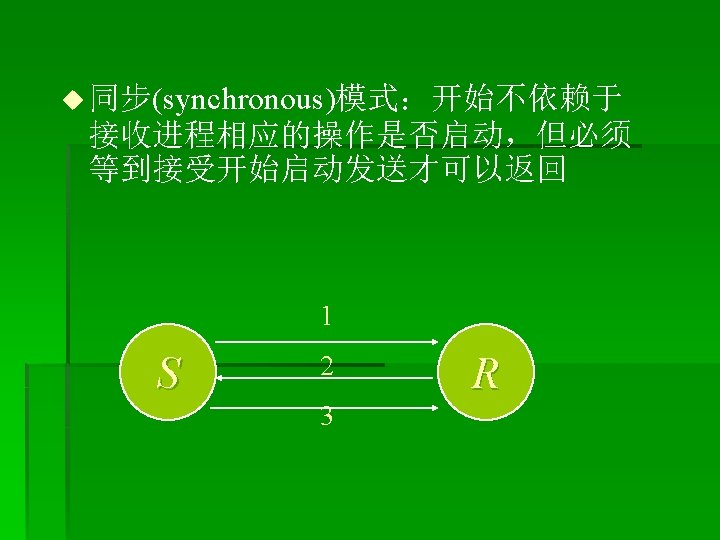

 IF (rank. EQ. 0) THEN CALL MPI_RECV(recvbuf, count, MPI_REAL,")
 IF (rank. EQ. 0) THEN CALL MPI_SEND(sendbuf, count, MPI_REAL,")
 IF (rank. EQ. 0) THEN CALL MPI_SEND(sendbuf, count,")
%groupsize; § anticlock=(myrank+groupsize-1)%groupsize; § MPI_Send(buf 1, LENGTH, MPI_CHAR, clock, tag, MPI_COM")
; § MPI_Recv(buf 2,")





![/*Make data table */ table =(int *)calloc(size, sizeof(int)); table[rank]=rank+1; /*准备要广播的数据*/ MPI_Barrier (MPI_COMM_WORLD); /*将数据广播出去*/ for](https://slidetodoc.com/presentation_image_h2/d738bfeaa49d9a1e00ea4c7152457168/image-24.jpg "/*Make data table */ table =(int *)calloc(size, sizeof(int)); table[rank]=rank+1; /*准备要广播的数据*/ MPI_Barrier (MPI_COMM_WORLD); /*将数据广播出去*/ for")


 int argc;")
 /*进程0读入需要广播的数据*/ scanf(“%d”, &value); /*将该数据广播出去*/ MPI_Bcast(&value, 1, MPI_INT, 0, MPI_COMM_WORLD); /*各进程打印收到的数据*/ printf(“Process")
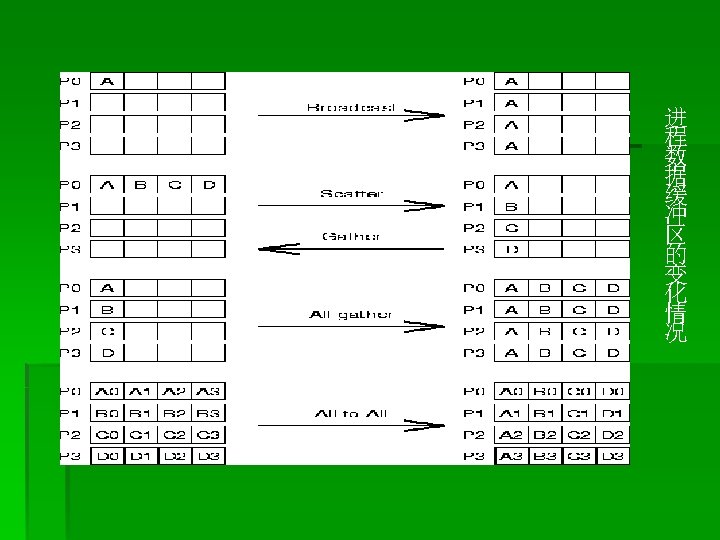
 § 把根进程中的数据分散发送给组中的所有进程( 包括自己): § MPI_Scatter (*sendbuf, sendcnt, sendtype, *recvbuf, recvcnt, recvtype, root, comm)")

 § 在组中指定一个进程收集组中所有进程发送来的 消息,这个函数操作与MPI_Scatter函数操作相 反: § MPI_Gather (*sendbuf, sendcnt, sendtype, *recvbuf, ecvcount, recvtype, root,")


;")
; MPI_Comm_size(MPI_COMM_WORLD, &numprocs); MPI_Comm_rank(MPI_COMM_WORLD, &myid); MPI_Get_processor_name(processor_name, &namelen); fprint(stdout, ”Process %d of %d on")

; if(myid==0) { printf(“pi is approximately %.")
 § 用来对分布在进程组上的数据执行前缀归约: § MPI_Scan (*sendbuf, *recvbuf, count, datatype, op, comm)")




, B(N+1, N+1) …… DO K=1, STEP DO")

")
 call MPI_COMM_RANK(MPI_COMM_WORLD, myid, ierr) call MPI_COMM_SIZE(MPI_COMM_WORLD, numprocs, ierr) print *, ”Process”, myid,")
 then do i=1, totalsize a(i, mysize+1)=8. 0 end do end")
 do n=1, steps (从右侧的邻居得到数据) if (myid. lt. 3)then call MPI_RECV(a(1, mysize+2), totalsize, MPI_REAL,")
 then call MPI_SEND(a(1, mysize+1), totalsize, MPI_REAL, myid+1, 10, MPI_COMM_WORLD,")
 then begin_col=3 end if if (myid. eq. 3) then end_col=mysize")
=b(i, j) end do do i=2, totalsize-1")


 call MPI_COMM_RANK(MPI_COMM_WORLD, myid, ierr) call MPI_COMM_SIZE(MPI_COMM_WORLD, numprocs, ierr) master=0 rows=100 cols=100 If")
 call MPI_BCAST(b, cols, MPI_DOUBLE_PRECISION, master, MPI_COMM_WORLD, ierr) (依次将矩阵A的各行发送给其他的numprocs-1个从进程) do")
 do i=1, row call MPI_RECV(ans, 1, MPI_DOUBLE_PRECISION, MPI_ANY_SOURCE, MPI_ANY_TAG, MPI_COMM_WORLD, status,")
 call MPI_SEND(1. 0, 0, MPI_DOUBLE_PRECISION, sender, 0, MPI_COMM_WORLD, ierr)")
 if (status(MPI_TAG). ne. 0) then row=status(MPI_TAG) ans=0. 0 do I=1, cols ans=ans+buffer(i)*b(j)")
- Slides: 63
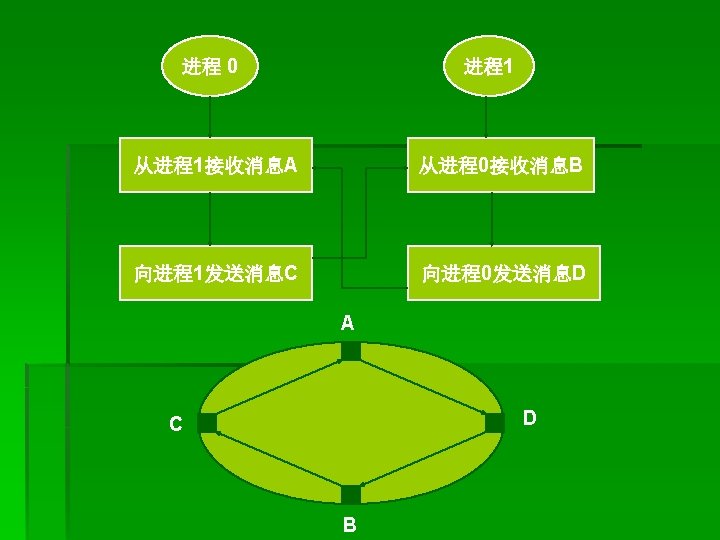
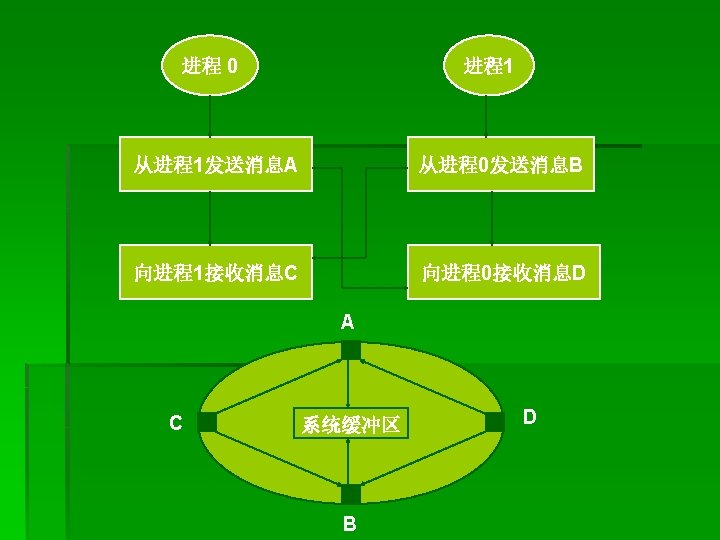
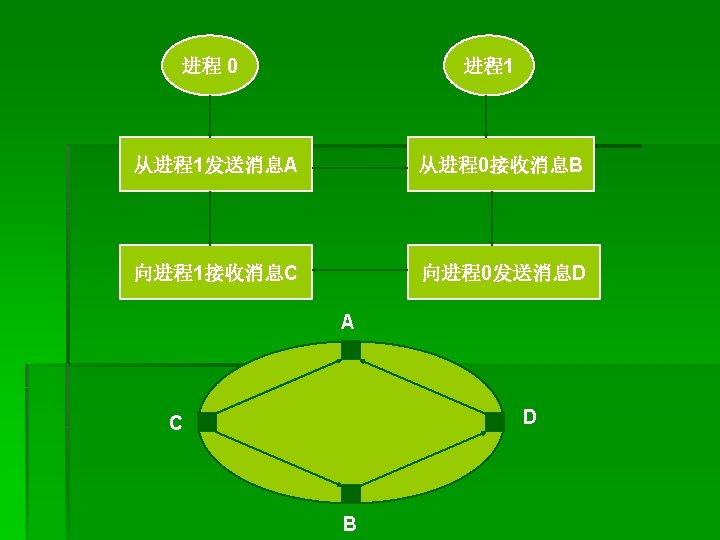
例3、死锁的发送接收序列 CALL MPI_COMM_RANK(comm, rank, ierr) IF (rank. EQ. 0) THEN CALL MPI_RECV(recvbuf, count, MPI_REAL, 1, tag, comm, status, ierr) CALL MPI_SEND(sendbuf, count, MPI_REAL, 1, tag, comm, ierr) ELSE IF (rank. EQ. 1) CALL MPI_RECV(recvbuf, count, MPI_REAL, 0, tag, comm, status, ierr) CALL MPI_SEND(sendbuf, count, MPI_REAL, 0, tag, comm, ierr) ENDIF
例4、不安全的发送接收序列 CALL MPI_COMM_RANK(comm, rank, ierr) IF (rank. EQ. 0) THEN CALL MPI_SEND(sendbuf, count, MPI_REAL, 1, tag, comm, ierr) CALL MPI_RECV(recvbuf, count, MPI_REAL, 1, tag, comm, status, ierr) ELSE IF (rank. EQ. 1) CALL MPI_SEND(sendbuf, count, MPI_REAL, 0, tag, comm, ierr) CALL MPI_RECV(recvbuf, count, MPI_REAL, 0, tag, comm, status, ierr) ENDIF
程序 5、安全的发送接收序列 CALL MPI_COMM_RANK(comm, rank, ierr) IF (rank. EQ. 0) THEN CALL MPI_SEND(sendbuf, count, MPI_REAL, 1, tag, comm, ierr) CALL MPI_RECV(recvbuf, count, MPI_REAL, 1, tag, comm, status, ierr) ELSE IF (rank. EQ. 1) CALL MPI_RECV(recvbuf, count, MPI_REAL, 0, tag, comm, status, ierr) CALL MPI_SEND(sendbuf, count, MPI_REAL, 0, tag, comm, ierr) ENDIF
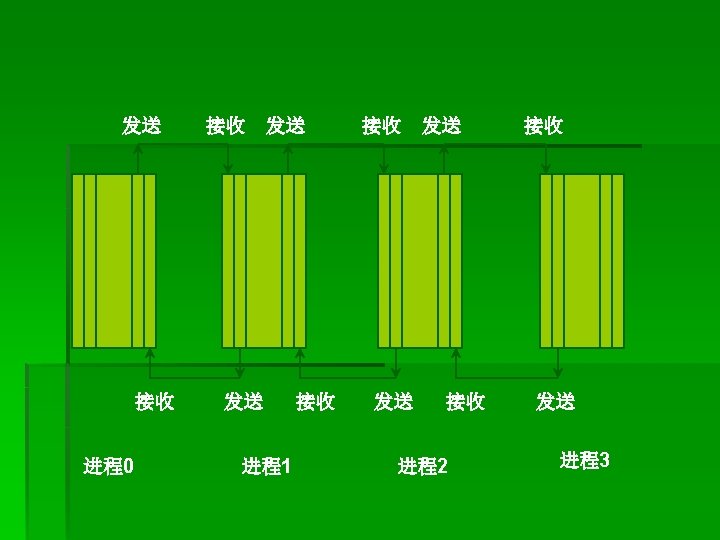
例子 6 § clock=(myrank+1)%groupsize; § anticlock=(myrank+groupsize-1)%groupsize; § MPI_Send(buf 1, LENGTH, MPI_CHAR, clock, tag, MPI_COM M_WORLD); § MPI_Recv(buf 2, LENGTH, MPI_CHAR, anticlock, tag, MPI_C OMM_WORLD, &status); 0 1 2
改进: § MPI_Isend(buf 1, LENGTH, MPI_CHAR, clock, tag, MPI_COMM_WORLD, &req uest); § MPI_Recv(buf 2, LENGTH, MPI_CHAR, anticlock, tag, MPI_COMM_WORLD, & status); § MPI_Wait(&request, &status); § ----------------- § MPI_Irecv(buf 2, LENGTH, MPI_CHAR, anticlock, tag, MPI_COMM_WORLD, &r equest); § MPI_Send(buf 2, LENGTH, MPI_CHAR, clock, tag, MPI_COMM_WORLD); § MPI_Wait(&request, &status);
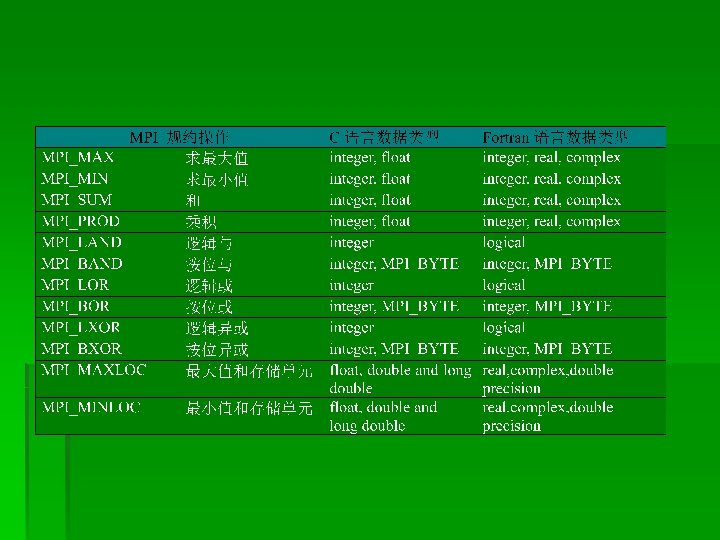
集合通信函数 § § § MPI_Barrier MPI_Bcast MPI_Scatter MPI_Gather MPI_Scan MPI_Reduce
程序 7、同步示例 #include “mpi. h” #include “test. h” #include <stdlib. h> #include <stdio. h> int main(int argc, char * * argv) { int rank, size, I; int *table; int errors=0; MPI_Aint address; MPI_Datatype, newtype; int lens; MPI_Init( &argc, &argv); MPI_Comm_rank (MPI_COMM_WORLD, &rank); MPI_Comm_size (MPI_COMM_WORLD, &size);
/*Make data table */ table =(int *)calloc(size, sizeof(int)); table[rank]=rank+1; /*准备要广播的数据*/ MPI_Barrier (MPI_COMM_WORLD); /*将数据广播出去*/ for (i=0; i<size, i++) MPI_Bcast( &table[i], 1, MPI_INT, i, MPI_COMM_WORLD); /*检查接收到的数据的正确性*/ for (i=0; i<size, i++) if (table[i]!=i+1) errors++; MPI_Barrier(MPI_COMM_WORLD); /*检查完毕后执行一次同步*/ …… /*其他的计算*/ MPI_Finalize(); }
程序 8、广播程序示例 #include <stdio. h> #include “mpi. h” int main (argc, argv) int argc; Char * * argv; { int rank, value; MPI_Init(&argc, &argv); MPI_Comm_rank(MPI_COMM_WORLD, &rank);
do{ if (rank==0) /*进程0读入需要广播的数据*/ scanf(“%d”, &value); /*将该数据广播出去*/ MPI_Bcast(&value, 1, MPI_INT, 0, MPI_COMM_WORLD); /*各进程打印收到的数据*/ printf(“Process %d got %d n”, rank, value); }while(value>=0); MPI_Finalize(); return 0; }
MPI_Scatter() § 把根进程中的数据分散发送给组中的所有进程( 包括自己): § MPI_Scatter (*sendbuf, sendcnt, sendtype, *recvbuf, recvcnt, recvtype, root, comm) root用 MPI_Send(sendbuf, sendcount·n, sendtype, …)发送一个消息。这个消息分成n个 相等的段,第i个段发送到进程组的第i个进程, sendcnt必须要和recvcnt相同。
MPI_Gather() § 在组中指定一个进程收集组中所有进程发送来的 消息,这个函数操作与MPI_Scatter函数操作相 反: § MPI_Gather (*sendbuf, sendcnt, sendtype, *recvbuf, ecvcount, recvtype, root, comm)
程序 9、规约示例 #include “mpi. h” #include <stdio. h> #include <math. h> double f(double x); /*定义函数f(x) */ { return(4. 0/(1. 0+x*x)); } int main (int argc, char * argv[]) { int done =0, n, myid, numprocs, i; double PI 25 DT=3. 141592653589793238462643; double mypi, h, sum, x; double startwtime=0. 0, endwtime; int namelen; char processor_name[MPI_MAXPROCESSOR_NAME];
MPI_Init(&argc, &argv); MPI_Comm_size(MPI_COMM_WORLD, &numprocs); MPI_Comm_rank(MPI_COMM_WORLD, &myid); MPI_Get_processor_name(processor_name, &namelen); fprint(stdout, ”Process %d of %d on % sn”, myid, numprocs, processor_name); n=0; if (myid==0) { printf(“Please give N=”); scanf(&n); startwtime=MPI_Wtime(); } /*将n值广播出去*/ MPI_Bcast(&n, 1, MPI_INT, 0, MPI_COMM_WORLD);
/*将部分和累加得到所有矩形的面积,该面积和即为近似PI值*/ MPI_Reduce(&mypi, &pi, 1, MPI_DOUBLE, MPI_SUM, 0, MPI_COMM_WORLD); if(myid==0) { printf(“pi is approximately %. 16 f, Error is %. 16 fn”, pi, fabs(pi-PI 25 DT)); endwtime=MPI_Wtime(); printf(“wall clock time=% fn”, endwtime-startwtime); fflush(stdout); } MPI_Finalize(); }
MPI_Scan() § 用来对分布在进程组上的数据执行前缀归约: § MPI_Scan (*sendbuf, *recvbuf, count, datatype, op, comm)
程序 10 串行表示的Jacobi迭代 …… REAL A(N+1, N+1), B(N+1, N+1) …… DO K=1, STEP DO J=1, N DO I=1, N B(I, J)=0. 25*(A(I-1, J)+A(I+1, J)+A(I, J+1)+A(I, J-1)) END DO DO J=1, N DO I=1, N A(I, J)=B(I, J) END DO
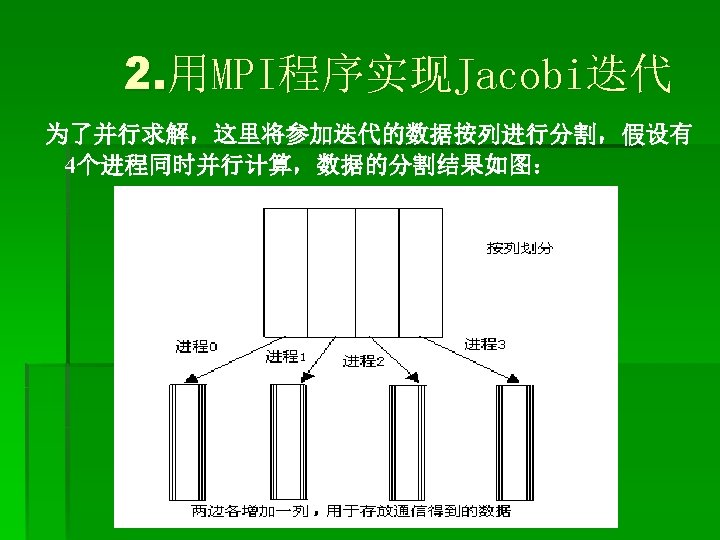
程序 11、 并行的Jacobi迭代 program main include ‘mpif. h’ integer totalsize, mysize, steps Parameter (totalsize=16) (定义全局数组的规模) parameter (mysize=totalsize/4, steps=10) integer n, myid, numprocs, i, j, rc Real a(totalsize, mysize+2), b(totalsize, mysize+2) Integer begin_col, end_col, ierr Integer status(MPI_STATUS_SIZE)
call MPI_INIT(ierr) call MPI_COMM_RANK(MPI_COMM_WORLD, myid, ierr) call MPI_COMM_SIZE(MPI_COMM_WORLD, numprocs, ierr) print *, ”Process”, myid, ” of”, numprocs, ” is alive” (数组初始化) do j=1, mysize+2 do i=1, totalsize a(i, j)=0. 0 end do If (myid. eq. 0) then do i=1, totalsize a(i, 2)=8. 0 end do end if
If (myid. eq. 3) then do i=1, totalsize a(i, mysize+1)=8. 0 end do end if do i=1, mysize+2 a(1, i)=8. 0 a(totalsize, i)=8. 0 end do
(Jacobi迭代部分) do n=1, steps (从右侧的邻居得到数据) if (myid. lt. 3)then call MPI_RECV(a(1, mysize+2), totalsize, MPI_REAL, myid+1, 10, MPI_COMM_WORLD, status, ierr) end if (向左侧的邻居发送数据) if (myid. gt. 0)then call MPI_SEND(a(1, 2), totalsize, MPI_REAL, myid-1, 10, MPI_COMM_WORLD, ierr) end if
//向右侧的邻居发送数据 if (myid. lt. 3) then call MPI_SEND(a(1, mysize+1), totalsize, MPI_REAL, myid+1, 10, MPI_COMM_WORLD, ierr) end if //从左侧的邻居接收数据 if (myid. gt. 0) then call MPI_RECV(a(1, 1), totalsize, MPI_REAL, myid-1, 10, MPI_COMM_WORLD, status, ierr) end if begin_col=2 end_col=mysize+1
if (myid. eq. 0) then begin_col=3 end if if (myid. eq. 3) then end_col=mysize end if do j=begin_col, end_col do i=2, totalsize-1 b(i, j)=0. 25*(a(i, j+1)+a(i, j-1)+a(i+1, j)+a(i-1, j)) end do
do j=begin_col, end_col do i=2, totalsize-1 a(i, j)=b(i, j) end do do i=2, totalsize-1 print *, myid, (a(i, j), j=begin_col, end_col) end do call MPI_FINALIZE(rc) end
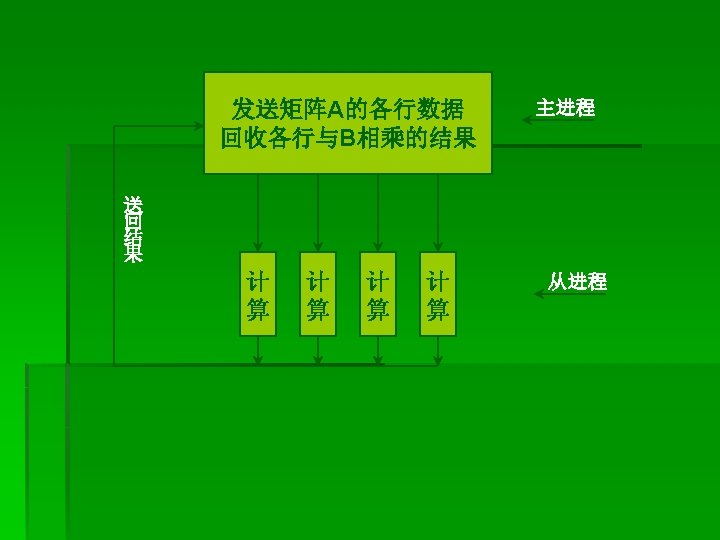
程序 12、 矩阵向量乘 program main include “mpif. h” integer MAX_ROWS, MAX_COLS, rows, cols parameter (MAX_ROWS=1000, MAX_COLS=1000) double precision a(MAX_ROWS, MAX_COLS), b(MAX_COLS), c(MAX_COLS) double presicion buffer(MAX_COLS), ans integer myid, master, numprocs, ierr, status(MPI_STATUS_SIZE) integer i, j, numsent, numrcvd, sender integer anstype, row
call MPI_INIT(ierr) call MPI_COMM_RANK(MPI_COMM_WORLD, myid, ierr) call MPI_COMM_SIZE(MPI_COMM_WORLD, numprocs, ierr) master=0 rows=100 cols=100 If (myid. eq. master) then (主进程对矩阵A和B赋初值) do i=1, cols b(i)=1 do j=1, rows a(I, j)=1 end do
* * numsent=0 numrcvd=0 (将矩阵B发送给所有其他的从进程,通过下面的广播语句实现) call MPI_BCAST(b, cols, MPI_DOUBLE_PRECISION, master, MPI_COMM_WORLD, ierr) (依次将矩阵A的各行发送给其他的numprocs-1个从进程) do i=1, min(numprocs-1, rows) do j=1, cols (将一行的数据取出来依次放到缓冲区中) buffer(j)=a(i, j) end do (将准备好的一行数据发送出去) call MPI_SEND(buffer, cols, MPI_DOUBLE_PRECISION, i, i, MPI_COMM_WORLD, ierr) numsent=numsent+1 end do
* * (对所有的行,依次接收从进程对一行数据的计算结果) do i=1, row call MPI_RECV(ans, 1, MPI_DOUBLE_PRECISION, MPI_ANY_SOURCE, MPI_ANY_TAG, MPI_COMM_WORLD, status, ierr) sender=status(MPI_SOURCE) anstype=status(MPI_TAG) (将该行数据赋给结果数组C的相应单元) c(anstype)=ans (如果还有其他的行没有被计算,则继续发送) if (numsent. lt. rows) then do j=1, cols (准备好新一行的数据) buffer(j)=a(numsent+1, j) end do (将该行数据发送出去) call MPI_SEND(buffer, cols, MPI_DOUBLE_PRECISION, sender, numsent+1, MPI_COMM_WORLD, ierr) numsent=numsent+1
* else (若所有行都已发送出去,则每接收一个消息则向相应的从进程发 送一个标志为 0的空消息,终止该从进程的执行) call MPI_SEND(1. 0, 0, MPI_DOUBLE_PRECISION, sender, 0, MPI_COMM_WORLD, ierr) end if end do else * * (下面为从进程的执行步骤,首先是接收数组B) call MPI_BCAST(b, cols, MPI_DOUBLE_PRECISION, master, MPI_COMM_WORLD, ierr) (接收主进程发送过来的矩阵A一行的数据) call MPI_RECV(buffer, cols, MPI_DOUBLE_PRECISION, master, MPI_ANY_TAG, MPI_COMM_WORLD, status, ierr)
(若接收到标志为 0的消息,则退出执行) if (status(MPI_TAG). ne. 0) then row=status(MPI_TAG) ans=0. 0 do I=1, cols ans=ans+buffer(i)*b(j) end do (计算一行的结果,并将结果发送给主进程) call MPI_SEND(ans, 1, MPI_DOUBLE_PRECISION, master, row, MPI_COMM_WORLD, ierr) goto 90 end if call MPI_FINALIZE(ierr) end