3 1 16 BEST PRACTICES IN SOCIALPERSONALIT Y

3 -1 -16 BEST PRACTICES IN SOCIAL/PERSONALIT Y PSYCHOLOGY

HOW DO WE KNOW WHAT WE KNOW?
")
Outline for Today � Best Practices �Examples of fraud/data manipulation �Questionable Research Practices (QRPs) �Doing research ethically and responsibly � Reproducibility and Replication Efforts �Motivation �History of Attempts � The Future: Being a good consumer of psychological science

Incentives Structure Published work is important getting a job, getting tenure, being awarded grants, and being viewed favorably in our field. � As a result, a “rat race” culture develops and people try to publish as much as they can. � Balancing the desire to stay truthful to psychological science with the necessity to publish. � This results in researchers taking shortcuts and sometimes worse… �
 �")
Recent Cases of Research Misconduct � Karen Ruggiero (late 90 s, early 00’s) � Marc Hauser (2007 -2011) � Diederick Stapel (2011) � Dirk Smeesters (2011 -2012) � Larry Sanna (2012) � Jens Förster (2014 -2015) � Michael La. Cour (2015)

. . . I think it is important to emphasize that I never informed my colleagues of my inappropriate behavior. I offer my colleagues, my Ph. D students, and the complete academic community my sincere apologies. I am aware of the suffering and sorrow that I caused to them. I did not withstand the pressure to score, to publish, the pressure to get better in time. I wanted too much, too fast. In a system where there are few checks and balances, where people work alone, I took the wrong turn. I want to emphasize that the mistakes that I made were not born out of selfish ends. -Brabants Dagblad. 31 October 2011. -Translated from Dutch


However, other practices don’t constitute fraud � Questionable Research Practices � Decisions in design, analysis, and reporting that increase the likelihood of achieving a positive result �And a positive response from editors and reviewers

False Positive Psychology � How do decisions in analyses affect the final results? � Having small samples, collecting additional dependent variables, peeking at data, dropping an experimental condition � If enough possibilities are entertained, the likelihood of achieving a significant result could be over 80%! Simmons et al. , 2011

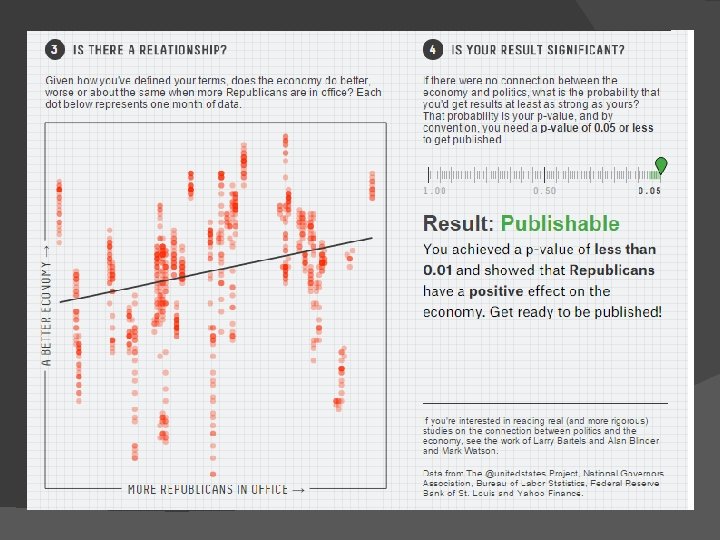
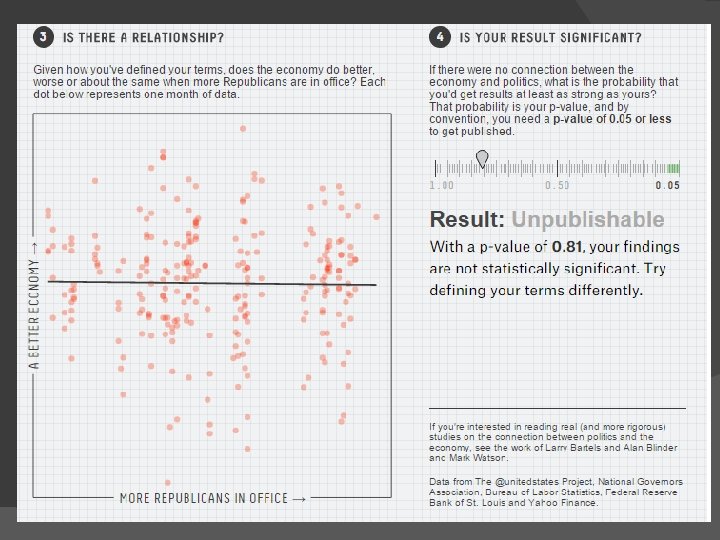
IS THE U. S. ECONOMY AFFECTED BY WHETHER DEMOCRATS OR REPUBLICANS ARE IN OFFICE?

Not so simple… � Do you look at the number of Republicans or Democrats? � Which politicians do you look at? � How do you measure the U. S. economy? � Should you look at it in general or excluding economic recessions?


 surveyed 2, 155 academic psychologists")
Questionable Research Practices � John, Loewenstein, & Prelec (2012) surveyed 2, 155 academic psychologists about the frequency of 10 different QRPs…. . � Not reporting all measures, rounding off p-values, only including data that “worked out” � Up to 63. 4% admission and high levels of each being “defensible”

What should researchers do? � Increase disclosure in methods, results, and hypothesis presentation � Pre-register hypotheses and studies �Data collection rules, analytic strategies � Share data � Be a responsible scientist regardless of outcome

Center for Open Science � Open Science Framework � Founded to increase to openness, integrity, and reproducibility of scientific research �Brian Nosek and Jeff Spies � Open source software platform for preregistering hypotheses, archiving study materials, depositing data and syntax � Initiated the Reproducibility Project

Video CENTER FOR OPEN SCIENCE

Producing Reliable Findings � Reproducibility: A study can be duplicated in method and/or analysis � Replicability: A study about a phenomenon produces similar results from a previous study of the same phenomenon. �Close/Exact Replications �Conceptual Replications

ARE PSYCHOLOGY FINDINGS REPRODUCIBLE AND REPLICABLE?

Many Labs 1. 0 � Started running studies that could be done relatively easily. � Effects varied from those that have been known to replicate (classic studies) and those that were unknown.

Many Labs 1. 0

Many Labs 2. 0/3. 0 and other changes � Many Labs 2. 0: Replication across sample and setting � Many Labs 3. 0: Subject pool quality across the academic semester � Editorial policies of some journals changed � Special issues on replication

Some criticisms � Researchers cherry pick studies b/c they have some personal /intellectual ax to grind � People who do replications are somehow not qualified to do science � Science is naturally self-correcting � Unknown differences between studies �Sample-specific reasons for non-replication

Unknown differences Approval at Time 1: 65% Approval at Time 2: 32%
 � Large-scale replication � 100 studies from 3 different journals �Close/exact")
Reproducibility Project (2015) � Large-scale replication � 100 studies from 3 different journals �Close/exact replications �Contacted original study authors �Open materials and data ○ Reduces likelihood of “unknown differences” effect � How many do you think replicated?

Why didn’t more findings replicate? � Perhaps some difference between studies �Boundary effects � Or perhaps the effect didn’t exist in the first place? �Some uncertainty in findings �File drawer problem

File Drawer Problem

WHAT DOES GOOD RESEARCH LOOK LIKE?

Good Research � Good research is open research �Materials and data are shared publicly � Good research features experimental methods that are strong and isolate a question of interest � Good research is adequately “powered” research

What is power? � The ability to detect an effect that actually exists. � Often tied to sample size �“I need X number of people to detect an effect” � Depends on how big your “effect” or phenomenon of interest is. �If large, you need fewer participants �If small, you need more participants

Power � Most psychological effects are small, so you need a lot of participants �Some say 200; others say it depends on what you’re studying!


Houses � Measuring one city house and one suburban house � Measuring five city houses and five suburban houses � How many houses do you need to collect to tell if there’s a difference? �Depends on the “true” difference, which we don’t always know

Power � Generally set at 80% �There’s an 80% chance of finding an effect that exists. �However, usually is much lower than this ○ Underestimate how much data is needed ○ Differences are smaller than they think ○ It’s hard and expensive

Gender and Height � Average height of men? � 5 ft, 9 in � Average height of women? � 5 ft, 4 in � Required sample size? � 12 (total)
")
Gender and Weight � Required sample size? � 92 (total)

Power � Generally set at 80% � There’s an 80% chance of finding an effect that exists. � However, usually is much lower than this � Depends on the size of an effect � Men weigh more than women ○ N=92 � People who like spicy food like Indian food ○ N=52 � People who like eggs report eating egg salad more ○ N=96 � Smokers think smoking is less likely to kill someone ○ N=288

Consuming Science � Be an informed consumer of science � Don’t believe everything you read! �If an effect seems unbelievable, it just might be. � Pay attention to sample size �How big is the sample? �Effects are unreliable if sample size is too low, a 2, 000 person study more reliable than a 50 person study.

Consuming Science � Is the study you are reading the only demonstration of this effect? �Have people from other labs replicated this? � Did the authors make their data available? � Advocate for good research so we can understand more about humans and why they do the things they do
- Slides: 42