1 Prolog Modeling game players by using Prolog

1 Prologによるゲームプレイヤーのモデリング Modeling game players by using Prolog 犬童健良*1 Kenryo Indo *1 関東学園大学経済学部 Faculty of Economics, Kanto Gakuen University The 17 th Annual Conference of the Japanese Society for Artificial Intelligence, 25 -27, June 2003

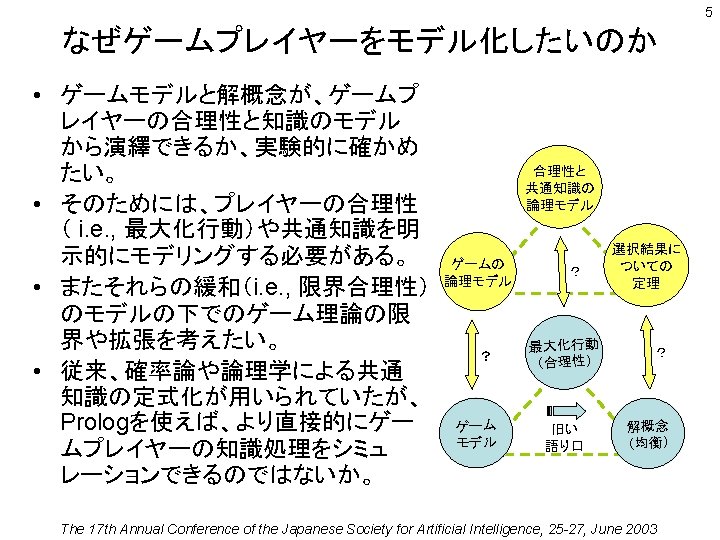
2 1.ゲームプレイヤーのインテリジェンス The 17 th Annual Conference of the Japanese Society for Artificial Intelligence, 25 -27, June 2003






9 2. 行動水準でのゲームモデリング The 17 th Annual Conference of the Japanese Society for Artificial Intelligence, 25 -27, June 2003

![2. 1 標準形ゲームのPrologモデル • Prologで上の例題とその純粋ナッシュ戦略均衡をモデリン グしよう. • 標準形ゲームs1のPrologモデル game(s 1, acts([x, z]), payoffs([1, 1]) ).](http://slidetodoc.com/presentation_image_h/365ba110961a6cdd473f75a662e6d091/image-11.jpg "2. 1 標準形ゲームのPrologモデル • Prologで上の例題とその純粋ナッシュ戦略均衡をモデリン グしよう. • 標準形ゲームs1のPrologモデル game(s 1, acts([x, z]), payoffs([1, 1]) ).")
2. 1 標準形ゲームのPrologモデル • Prologで上の例題とその純粋ナッシュ戦略均衡をモデリン グしよう. • 標準形ゲームs1のPrologモデル game(s 1, acts([x, z]), payoffs([1, 1]) ). game(s 1, acts([x, w]), payoffs([-2, 0]) ). game(s 1, acts([y, z]), payoffs([1, 0]) ). game(s 1, acts([y, w]), payoffs([-1, -1]) ). • また図 1の利得表の非対角部分を変更したゲームs2では,[ -1, -1]が唯一の均衡となる.(囚人ジレンマゲーム) • 標準形ゲームs2のPrologモデル game(s 2, acts([x, z]), payoffs([1, 1]) ). game(s 2, acts([x, w]), payoffs([-2, 2]) ). game(s 2, acts([y, z]), payoffs([2, -2]) ). game(s 2, acts([y, w]), payoffs([-1, -1]) ). The 17 th Annual Conference of the Japanese Society for Artificial Intelligence, 25 -27, June 2003 11
![12 標準形ゲーム の ナッシュ均衡のPrologモデル • ナッシュ均衡を求めるプログラム nash(G, [S 1, S 2], [P 1, P](http://slidetodoc.com/presentation_image_h/365ba110961a6cdd473f75a662e6d091/image-12.jpg "12 標準形ゲーム の ナッシュ均衡のPrologモデル • ナッシュ均衡を求めるプログラム nash(G, [S 1, S 2], [P 1, P")
12 標準形ゲーム の ナッシュ均衡のPrologモデル • ナッシュ均衡を求めるプログラム nash(G, [S 1, S 2], [P 1, P 2]): game(G, acts([S 1, S 2]), payoffs([P 1, P 2]) ), + (game(G, acts([_, S 2]), payoffs([Px, _])), Px>P 1 ), + (game(G, acts([S 1, _]), payoffs([_, Py])), Py>P 2 ). • 実行例 ? - nash(G, Acts, Payoffs). G = s 1 Acts = [x, z] Payoffs = [1, 1] ; G = s 1 Acts = [y, z] Payoffs = [1, 0] ; G = s 2 Acts = [y, w] Payoffs = [-1, -1] ; No The 17 th Annual Conference of the Japanese Society for Artificial Intelligence, 25 -27, June 2003

は, – 全体合理性:v({1, 2, 3})=x 1+x 2+x 3,および – 個人合理性: x 1,")
配分のPrologモデル • 配分(imputation)は, – 全体合理性:v({1, 2, 3})=x 1+x 2+x 3,および – 個人合理性: x 1, x 2, x 3≧v({i})=0 の 2条件を満たす共同利益分配案(x 1, x 2, x 3)の集合である. • 配分 imputation(game(G), payoff(A)): game(G, form(coalitional), players(N)), game(G, coalition(N), value(V)), length(N, LN), allocation(LN, V, A), + ( nth 1(K, N, J), nth 1(K, A, AJ), game(G, coalition([J]), value(RJ)), RJ > AJ ). The 17 th Annual Conference of the Japanese Society for Artificial Intelligence, 25 -27, June 2003 14
は,どんな提携Sの下でも互いに支配され ない配分の集合であり,したがって誰も明らかな不満 (excess)を持たない. • コア core(game(G), payoff(A)): game(G, form(coalitional), players(N)),")
提携形ゲーム の コアのPrologモデル • コア(core)は,どんな提携Sの下でも互いに支配され ない配分の集合であり,したがって誰も明らかな不満 (excess)を持たない. • コア core(game(G), payoff(A)): game(G, form(coalitional), players(N)), imputation(game(G), payoff(A)), + ( game(G, coalition(S), value(RY)), S = N, selected_sum(S/N, _B/A, AY), RY > AY ). The 17 th Annual Conference of the Japanese Society for Artificial Intelligence, 25 -27, June 2003 15



![遂行理論の 正直遂行のシミュレーション例 test_impl(g. MR 2, ai, [1, 2], truthful(0), _G 445) start -----------[date(2003/5/4), time(16:](http://slidetodoc.com/presentation_image_h/365ba110961a6cdd473f75a662e6d091/image-19.jpg "遂行理論の 正直遂行のシミュレーション例 test_impl(g. MR 2, ai, [1, 2], truthful(0), _G 445) start -----------[date(2003/5/4), time(16:")
遂行理論の 正直遂行のシミュレーション例 test_impl(g. MR 2, ai, [1, 2], truthful(0), _G 445) start -----------[date(2003/5/4), time(16: 51: 22)] Testing Nash implementability via prolog simulation **** the model specification ****** game form: g. MR 2 members of society: [1, 2] Scc: ai(s 1) = [a] ai(s 2) = [b] is Maskin-monotone. is Essentially-monotone. does not have Moore-Repullo property (defined by Danilov). is not individually-rational. preferene domain: [agent, state, preference, difference] [1, s 1, [a, b, c], [w, w, end]] [2, s 1, [b, a, c], [w, w, end]] [1, s 2, [b, a, c], [w, w, end]] [2, s 2, [a, b, c], [w, w, end]] other tests for this model [mm, em, -, -, rvp, unan, po, -, dict, neli, mlib, -, mju 1, mju 2, mju 3, mju 4] checking the on-SCC patterns: [s 1, a][s 2, b] For state s 1, outcome=a [in, ai], rule=1 message profile is [[a, b, c], [b, a, c]], a, a, 0, 0 This action profile is a Nash equilibrium. For state s 2, outcome=b [in, ai], rule=1 message profile is [[b, a, c], [a, b, c]], b, a, 0, 0 agent=1, Pzs=[1, 2, 3], Czs=[a, b, c], Lcc=[a, b, c] <is_best_response> agent=2, Pzs=[1, 2, 4], Czs=[b, c], Lcc=[b, c] <is_best_response> Br_Members=[1, 2] This action profile is a Nash equilibrium. checking the off-SCC patterns: [s 1, b][s 1, c][s 2, a][s 2, c] end <------------[date(2003/5/4), time(16: 51: 46)] Summary Result [s 1, a, nash_yes, scc_in] [s 1, b, nash_no, scc_out] [s 1, c, nash_no, scc_out] [s 2, a, nash_no, scc_out] [s 2, b, nash_yes, scc_in] [s 2, c, nash_no, scc_out] Statistics cputime= [21. 8214, increased from, 1. 01145] inferences= [21724757, increased from, 768134] atoms= [0, increased from, 3276] functors= [0, increased from, 1931] predicates= [0, increased from, 1844] modules= [0, increased from, 26] codes= [628, increased from, 68159] agent=1, Pzs=[1, 2, 3], Czs=[a, b, c], Lcc=[a, b, c] <is_best_response> agent=2, Pzs=[1, 2, 4], Czs=[a, c], Lcc=[a, c] <is_best_response> Br_Members=[1, 2] The 17 th Annual Conference of the Japanese Society for Artificial Intelligence, 25 -27, June 2003 19

20 3.ゲーム木における情報モデリング The 17 th Annual Conference of the Japanese Society for Artificial Intelligence, 25 -27, June 2003




![展開形ゲーム(完全情報)の 部分ゲーム完全性のPrologモデル • 最初の 2つの均衡の部分ゲーム完全性を検証する ? - subgame_perfect(g 50(weak), Players, A, P), Players=[1, 2].](http://slidetodoc.com/presentation_image_h/365ba110961a6cdd473f75a662e6d091/image-26.jpg "展開形ゲーム(完全情報)の 部分ゲーム完全性のPrologモデル • 最初の 2つの均衡の部分ゲーム完全性を検証する ? - subgame_perfect(g 50(weak), Players, A, P), Players=[1, 2].")
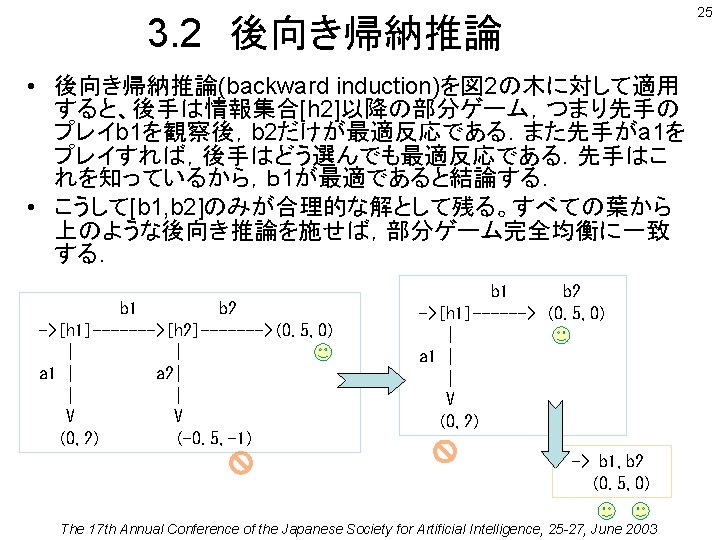
展開形ゲーム(完全情報)の 部分ゲーム完全性のPrologモデル • 最初の 2つの均衡の部分ゲーム完全性を検証する ? - subgame_perfect(g 50(weak), Players, A, P), Players=[1, 2]. trial([0, 2], [a 1, a 2], [a 1, [ (a 1 ->a 2), (b 1 ->a 2)]]) subgame(player: 1/[1, 0], [a 1, [ (a 1 ->a 2), (b 1 ->a 2)]], [0, 2])ne subgame(player: 2/[0, 2], [b 1, [ (a 1 ->a 2), (b 1 ->a 2)]], [0. 5 -1, -1]) defeated_by([[b 1, [ (a 1 ->a 2), (b 1 ->b 2)]], [0. 5, 0]]) trial([0. 5, 0], [b 1, b 2], [b 1, [ (a 1 ->a 2), (b 1 ->b 2)]]) subgame(player: 1/[1, 0], [b 1, [ (a 1 ->a 2), (b 1 ->b 2)]], [0. 5, 0])ne subgame(player: 2/[0, 2], [a 1, [ (a 1 ->a 2), (b 1 ->b 2)]], [0, 2])ne subgame(player: 2/[0, 2], [b 1, [ (a 1 ->a 2), (b 1 ->b 2)]], [0. 5, 0])ne A = acts([b 1, [ (a 1 ->a 2), (b 1 ->b 2)]]) P = payoffs([0. 5, 0]) Yes The 17 th Annual Conference of the Japanese Society for Artificial Intelligence, 25 -27, June 2003 26

27 4. 知識水準でのゲームモデリング The 17 th Annual Conference of the Japanese Society for Artificial Intelligence, 25 -27, June 2003





 --- naive expectation % ------------------------- % trader(naive,")
33 モデル1:素朴な取引者 % model of trader (1) --- naive expectation % ------------------------- % trader(naive, J, S, Q, D): partition(J, S, H), win_prob_on_event(J, H, Q), decision(Q, D). decision(Q, ok): - Q > 0. 5. decision(Q, reject): - Q < 0. 5. decision(Q, indifferent): - Q = 0. 5. The 17 th Annual Conference of the Japanese Society for Artificial Intelligence, 25 -27, June 2003
 --- 2 nd order expectation % with")
34 モデル2:浅読みの取引者 % model of trader (2) --- 2 nd order expectation % with a sort of certainty reasoning % ------------------------- % trader(sophist, J, S, Q, reject): trader(naive, J, S, Q, reject); trader(naive, J, S, Q, indifferent). trader(sophist, J, S, Q, ok): trader(naive, J, S, Q, ok), partition(J, S, H), + ( member(S 1, H), agent(J 1), J 1 = J, trader(naive, J 1, S 1, _Q 1, reject)). The 17 th Annual Conference of the Japanese Society for Artificial Intelligence, 25 -27, June 2003
 --% expectation under common knowledge of rationality")
35 モデル3:合理的期待 % model of trader (3) --% expectation under common knowledge of rationality % ------------------------- % trader(rational, J, (T, S), Q, D): state(S), time(T/N), T > 0, agent(J), move(J, T/N, yes), delay(T, 1, T 1), %T 1 is T - 1, partition(J, T 1/N, S, H), win_prob_on_event(J, H, Q), decision(Q, D). The 17 th Annual Conference of the Japanese Society for Artificial Intelligence, 25 -27, June 2003

: time(T/N), partition(J,")
取引交渉のモデリング:情報と知識の更新 /* dynamic knowledge updated by messages */ %-----------------------partition(J, T/N, S, H): time(T/N), partition(J, S, H 1), remove_impossible_states(J, T/N, S, H 1, H). % know(J, T/N, S, E): time(T/N), agent(J), state(S), partition(J, T/N, S, H), % remove_impossible_states(J, T/N, S, E, H), (length(H, 1)->E=H; true), event(E), subset(H, E). % remove_impossible_states(J, T/N, S, E, H): time(T/N), agent(J), state(S), event(E), findall(X, think(J, T/N, S, is_impossible(X)), D), subtract(E, D, F), sort(F, H). think(J, T/N, S, is_impossible(O)): agent(J), time(T/N), state(S), state(O), + think(J, T/N, S, is_possible(O)). % think(J, 0/N, S, is_possible(O)): time(0/N), think(J, S, is_possible(O)). think(J, T/N, S, is_possible(O)): time(T/N), T = 0, %T 1 is T - 1, delay(T, 1, T 1), think(J, T 1/N, S, is_possible(O)), is_consistent_with_information(T, S, O). /* the supporting evidence of state */ %-----------------------is_consistent_with_information(T, S, O): time(T/_N), state(S), state(O), agent(J), trader(rational, J, (T, S), _Q, D), % real. trader(rational, J, (T, O), _Q 1, D). % expected. The 17 th Annual Conference of the Japanese Society for Artificial Intelligence, 25 -27, June 2003 37
 • ホームページに掲載したPrologプログラムtrade. plは, Milgromと Stokeyの例題における相互知識推論と意思決定をシミュレートする.これ は基本的に帽子パズルと同じアルゴリズムによって再現される.以下にそ の実行画面の一部を示す. ? - trader(naive, J, s 3,")
Prologによる取引シミュレーション(1) • ホームページに掲載したPrologプログラムtrade. plは, Milgromと Stokeyの例題における相互知識推論と意思決定をシミュレートする.これ は基本的に帽子パズルと同じアルゴリズムによって再現される.以下にそ の実行画面の一部を示す. ? - trader(naive, J, s 3, Q, D). J=1 Q = 0. 666667 D = ok ; J=2 Q = 0. 666667 D = ok ; ? - trader(rational, J, (T, s 3), Q, D). J=1 T=1 Q = 0. 666667 D = ok ; J=2 T=2 Q = 0. 666667 D = ok ; J=1 T=3 Q = 0. 5 D = indifferent ; No ? - trader(sophist, J, s 3, Q, D). J=2 T=4 Q = 0. 5 D = indifferent ; J=1 Q = 0. 666667 D = ok ; J=1 T=5 Q = 0. 5 D = indifferent ; J=2 Q = 0. 666667 D = ok ; J=2 T=6 Q = 0. 5 D = indifferent No Yes The 17 th Annual Conference of the Japanese Society for Artificial Intelligence, 25 -27, June 2003 38
 • 状態s4では元のパーティションの場合, シミュレーション結果を見ると,確かに最初 は1も仮の合意をしているが,2の返答を聞 いた後,やはり翻意して拒絶する. ? - trader(rational, J, (T, s 4), Q,")
Prologによる取引シミュレーション(2) • 状態s4では元のパーティションの場合, シミュレーション結果を見ると,確かに最初 は1も仮の合意をしているが,2の返答を聞 いた後,やはり翻意して拒絶する. ? - trader(rational, J, (T, s 4), Q, D). J=1 T=1 Q = 0. 555556 D = ok ; J=2 T=2 Q = 0. 666667 D = ok ; J=1 T=3 Q = 0. 25 D = reject ; ≫Milgrom & Stokey のNo Trade Resultの検証 (Continued) J=2 T=4 Q = 0. 75 D = ok ; J=1 T=5 Q = 0. 25 D = reject ; J=2 T=6 Q = 0. 75 D = ok Yes The 17 th Annual Conference of the Japanese Society for Artificial Intelligence, 25 -27, June 2003 39
 • プログラムtrade. plで,エージェント のパーティションの部分を次のよう に変更した後,s4で trader/5 を実 行すると,取引への合意が達成さ れる. • また他のいずれの状態においても, 合意が成立する. •")
取引シミュレーション(非パーティション) • プログラムtrade. plで,エージェント のパーティションの部分を次のよう に変更した後,s4で trader/5 を実 行すると,取引への合意が達成さ れる. • また他のいずれの状態においても, 合意が成立する. • 非パーティション情報構造のモデル partition(1, s 1, [s 1, s 2, s 3, s 5]). partition(1, S, [s 2, s 3]): member(S, [s 2, s 3]). partition(1, s 4, [s 4, s 5]). partition(1, s 5, [s 5]). partition(2, s 1, [s 1]). partition(2, s 2, [s 1, s 2]). partition(2, S, [s 3, s 4]): member(S, [s 3, s 4]). partition(2, s 5, [s 1, s 3, s 4, s 5]). ? - trader(rational, J, (T, s 4), Q, D). J=1 T=1 Q = 0. 555556 D = ok ; J=2 T=2 Q = 0. 666667 D = ok ; J=1 T=3 Q = 0. 555556 D = ok ; J=2 T=4 Q = 0. 666667 D = ok ; J=1 T=5 Q = 0. 555556 D = ok ; The 17 th Annual Conference of the Japanese Society for Artificial Intelligence, 25 -27, June 2003 40

![42 参考文献 • [Aumann 76] Aumann, R. J. : Agreeing to disagree, Annals of](http://slidetodoc.com/presentation_image_h/365ba110961a6cdd473f75a662e6d091/image-42.jpg "42 参考文献 • [Aumann 76] Aumann, R. J. : Agreeing to disagree, Annals of")
42 参考文献 • [Aumann 76] Aumann, R. J. : Agreeing to disagree, Annals of Statistics 4: 1236 -1239 (1976). • [Fudenberg 91] Fudenberg, D. and J. Tirole: Game Theory, MIT press (1991). • [Imai 01] 今井晴雄・岡田章: ゲーム理論の新展開,勁草書房 (2001). • [Indo 02] Indo, K. : Implementing Nash implementation theory with Prolog: A logic programming approach, 第 6回実 験経済学コンファレンス予稿(2002) • [Indo 03] Indo, K. : Common knowledge,mimeo (2003), http: //www. us. kanto-gakuen. ac. jp/indo/kw/ck 03 b. html. • [Milgrom 82] Milgrom, P. and N. Stokey: Information, trade and common knowledge, Journal of Economic Theory 26: 17 -27 (1982). • [Muto 01] 武藤滋夫: ゲーム理論入門,日経文庫 (2001). The 17 th Annual Conference of the Japanese Society for Artificial Intelligence, 25 -27, June 2003
- Slides: 42