1 Analytic Function Analytic Function Analytic Function Analytic



































, UPDATE_DATE, SAL NUMBER(7,")





, '01', COUNT(*))), 0) JANUARY,")
,")





















- Slides: 66
1. Analytic Function • Analytic Function의 소개 Analytic Function의 수행원리 ◎ Analytic Function의 3요소 • Result Set Partitions : query processing with analytic function의 1단계 수행결과를 column이나 expression을 기준으로 grouping한 것, 1단계 수행결과 전체가 하나의 partition에 속할 수도 있고, 적은 rows를 가진 여러 개의 작은 partition으로 쪼개질 수도 있다. 그러나, 한 row는 반드시 하나의 partition에 속한다. • (Sliding) Window : current row에 대한 analytic calculation 수행의 대상이 되는 row의 범위(range), window는 current row를 기준으로 하나의 partition 내에서 sliding하며, 반드시 starting row와 ending row를 가진다. window size는 partition 전체가 될 수도 있고 partition의 부분범위가 될 수도 있으나 하나의 partition을 넘을 수는 없다. partition의 부분범위로서 window size를 정할 때는 physical number of rows로 정할 수도 있고 logical interval로 정할 수도 있다. • Current Row : 모든 Analytic Function의 적용은 항상 Partition내의 Current Row를 기준으로 수행된다. Current Row는 항상 Window의 Start와 End를 결정하는 기준(Reference Point)으로서 역할을 하므로 Current Row가 없는 Window는 존재하지 않는다. 4
1. Analytic Function • Analytic Function의 소개 Analytic Function의 수행원리 ◎ Analytic Function의 3요소 • Result Set Partitions • (Sliding) Window • Current Row 5
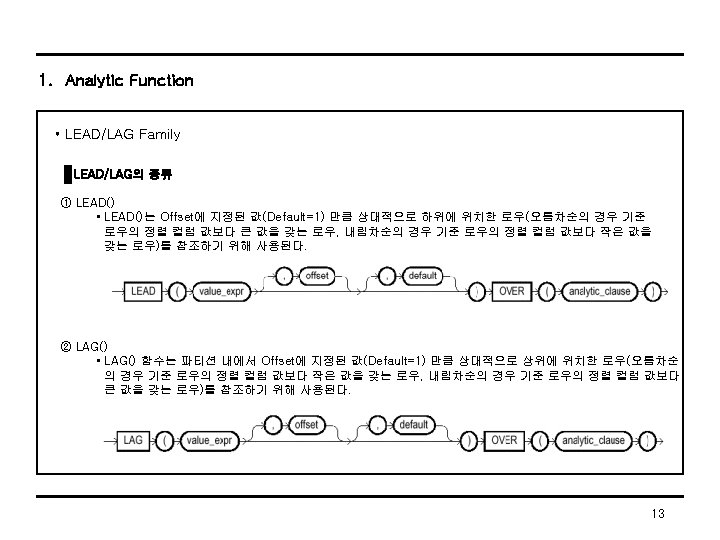
1. Analytic Function • Analytic Function의 소개 Analytic Function의 수행원리 ◎ Analytic Function의 종류 • Ranking Family : 대상 집합에 대하여 특정 컬럼(들) 기준으로 순위나 등급을 매기는 Analytic Function 류로서 다음과 같은 종류가 있다. - RANK(), DENSE_RANK(), CUME_DIST(), PERCENT_RANK(), NTILE(), ROW_NUMBER() • Window Aggregate Family : 현재 Row(Current Row)를 기준으로 지정된 윈도우(Window) 내의 로우들을 대상으로 집단화(aggregate)를 수행하여 여러 가지 유용한 집계정보(Running Summary, Moving Average 등)를 구하는 Analytic Function 류이며 다음과 같은 종류가 있다. - SUM, AVG, MIN, MAX, STDDEV, VARIANCE, COUNT, FIRST_VALUE, LAST_VALUE • Reporting Aggregate Family : 서로 다른 두 가지의 Aggregation Level을 비교하고자 하는 목적으로 사용하는 Analytic Function으로 다음과 같은 종류가 있다. - SUM, AVG, MIN, MAX, COUNT, STDDEV, VARINCE • LEAD/LAG Family : 서로 다른 두 Row 값을 비교하기 위한 Analytic Function으로 LEAD와 LAG가 있다. 6
1. Analytic Function • Analytic Function의 소개 Analytic Function의 수행원리 ◎ Analytic Function의 문법 {Analytic Function} ([ALL | DISTINCT] { | *}) OVER ([PARTITION BY [, . . . ] ] [ORDER BY [, . . . ] ] [Windowing_Clause]) • Analytic Function : 하나 이상의 컬럼 또는 적합한 표현식이 사용될 수 있다. Analytic Function의 아규먼트는 0에서 3개까지 가능하고 Asterisk(*)는 COUNT()에서만 허용되며 DISTINCT는 해당 집계 함수가 허용할 때만 지원된다. • Over analytic_clause : 해당 함수가 쿼리 결과 집합에 대해 적용되라는 지시어로 FROM, WHERE, GROUP BY와 HAVING구 이후에 계산되어 진다. SELECT구 또는 ORDER BY구에 Analytic Function을 사용할 수 있다. 7
1. Analytic Function • Aggregate Family Window Aggregate의 개념 ◎ 문법 {SUM | AVG | MAX | MIN | COUNT | STDDEV | VARIANCE | FIRST VALUE | LAST VALUE} ({<Value Expression 1> | *}) OVER ([PARTITION BY <Value Expression 2>] ORDER BY <Value Expression 3> [Collate Clause] [ASC | DESC] [NULLS FIRST | NULLS LAST] ROWS | RANGE {{UNBOUNDED PRECEDING | <Value Expression 4> PRECEDING} | BETWEEN {UNBOUNDED PRECEDING | <Value Expression 5> PRECEDING} | AND {CURRENT ROW | VALUE Ecpression 6> FOLLOWING}} • OVER : FROM, WHERE, GROUP BY, HAVING 절이 처리된 후에 적용되며, 함수를 적용하기 위한 행의 정렬 기준 또는 대상 행 집합에 대한 윈도우 정의 • ROWS | RANGE : 윈도우 크기를 결정하기 위한 행 집합을 정의 ① ROWS는 물리적인 단위에 의해 윈도우 크기 지정 ② RANGE는 논리적인 상대 번지에 의해 윈도우 크기 지정 • BETWEEN AND : 윈도우의 시작 위치와 마지막 위치 지정 • UNBOUNDED PRECEDING : 윈도우의 시작 위치는 각 분할의 첫 번째 행 • UNBOUNDED FOLLOWING : 윈도우의 마지막 위치는 각 분할의 마지막 행 15
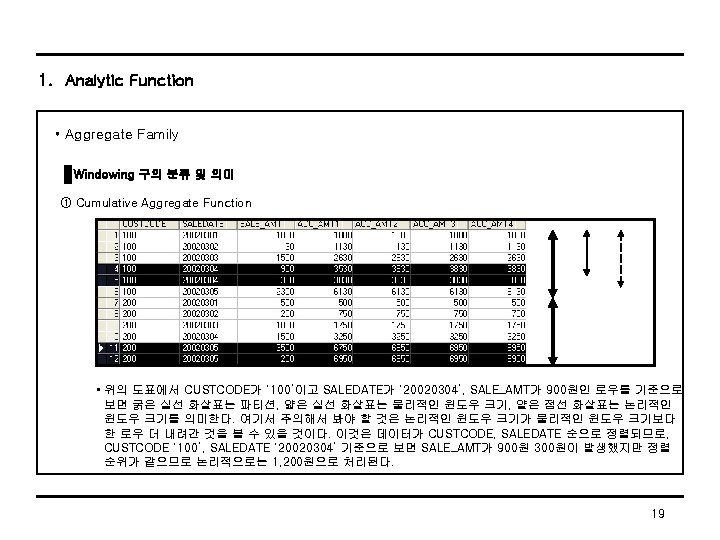
1. Analytic Function • Aggregate Family Windowing 구의 분류 및 의미 ① Cumulative Aggregate Function SELECT CUSTCODE, SALEDATE, SALE_AMT, SUM(SALE_AMT) OVER(PARTITION BY CUSTCODE ORDER BY SALEDATE ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) ACC_AMT 1, SUM(SALE_AMT) OVER(PARTITION BY CUSTCODE ORDER BY SALEDATE RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) ACC_AMT 2, SUM(SALE_AMT) OVER(PARTITION BY CUSTCODE ORDER BY TO_DATE(SALEDATE, 'YYYYMMDD') RANGE BETWEEN UNBOUNDED PRECEDING AND INTERVAL '0' DAY FOLLOWING) ACC_AMT 3, SUM(SALE_AMT) OVER(PARTITION BY CUSTCODE ORDER BY SALEDATE) ACC_AMT 4 FROM SALE_TBL; • 위의 쿼리문에서 굵은 글자가 Windowing_Cluase를 의미하고 ACC_AMT 1은 Physical Window에 의해, ACC_AMT 2는 Logical Window 중에서 Value Range에 의해, ACC_AMT 3은 Logical Window 중에서 Time Interval, ACC_AMT 4는 Window_Clause를 생략했지만 ACC_AMT 2와 같은 의미를 가진다. 18
1. Analytic Function • Aggregate Family Windowing 구의 분류 및 의미 ② Moving Aggregate Function SELECT CUSTCODE, SALEDATE, SALE_AMT, SUM(SALE_AMT) OVER(PARTITION BY CUSTCODE ORDER BY SALEDATE ROWS BETWEEN 1 PRECEDING AND CURRENT ROW) ACC_AMT 1, SUM(SALE_AMT) OVER(PARTITION BY CUSTCODE ORDER BY TO_DATE(SALEDATE, 'YYYYMMDD') RANGE BETWEEN 1 PRECEDING AND CURRENT ROW) ACC_AMT 2, SUM(SALE_AMT) OVER(PARTITION BY CUSTCODE ORDER BY TO_DATE(SALEDATE, 'YYYYMMDD') RANGE BETWEEN INTERVAL '1' DAY PRECEDING AND CURRENT ROW) ACC_AMT 3 FROM SALE_TBL; • 위의 쿼리문에서 굵은 글자가 Windowing_Clause를 의미하고 ACC_AMT 1은 Physical Window에 의해, ACC_AMT 2는 Logical Window 중 Value Range에 의해, ACC_AMT 3은 Logical Window 중 Time Interval에 대한 의미를 가진다. 21
1. Analytic Function • Aggregate Family Windowing 구의 분류 및 의미 ③ Centered Aggregate Function SELECT CUSTCODE, SALEDATE, SALE_AMT, SUM(SALE_AMT) OVER(PARTITION BY CUSTCODE ORDER BY SALEDATE ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING) ACC_AMT 1, SUM(SALE_AMT) OVER(PARTITION BY CUSTCODE ORDER BY TO_DATE(SALEDATE, 'YYYYMMDD') RANGE BETWEEN 1 PRECEDING AND 1 FOLLOWING) ACC_AMT 2, SUM(SALE_AMT) OVER(PARTITION BY CUSTCODE ORDER BY TO_DATE(SALEDATE, 'YYYYMMDD') RANGE BETWEEN INTERVAL '1' DAY PRECEDING AND INTERVAL '1' DAY FOLLOWING) ACC_AMT 3 FROM SALE_TBL; • 위의 쿼리문에서 굵은 글자가 Windowing_Clause를 의미하고 ACC_AMT 1은 Physical Window에 의해, ACC_AMT 2는 Logical Window 중 Value Range에 의해, ACC_AMT 3은 Logical Window 중 Time Interval에 대한 의미를 가진다. 24
1. Analytic Function • Aggregate Family Windowing 구의 분류 및 의미 ④ Window Size가 Logical Offset으로 결정될 경우 Ordering이 Unique할 때와 Non Unique할 때의 차이점 SELECT CUSTCODE, SALEDATE, SALE_AMT, SUM(SALE_AMT) OVER(PARTITION BY CUSTCODE ORDER BY SALEDATE RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) ACC_AMT 1, SUM(SALE_AMT) OVER(PARTITION BY CUSTCODE ORDER BY SALEDATE, SALE_AMT RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) ACC_AMT 2 FROM SALE_TBL; • 위의 쿼리문에서 이텔릭 글자가 데이터 정렬에 기준이 되는 PARTITION BY와 ORDER BY구이고 굵은 글자가 Windowing_Clause를 의미하고 ACC_AMT 1과 ACC_AMT 2는 둘 다 Value Range에 의한 논리적 윈도우의 결과를 반영하지만, ORDER BY의 표현식을 다르게 하였다. ACC_AMT 1의 정렬은 CUSTCODE, SALEDATE 기준으로 수행되고 데이터와 비교해보면 정렬의 순서가 같은 데이터들이 있다. 그러나 ACC_AMT 2는 데이터 정렬이 CUSTCODE, SALEDATE, SALE_AMT 기준으로 수행되고 데이터와 비교해보면 정렬순서가 Unique하게 됨을 알 수 있다. 26
1. Analytic Function • Aggregate Family FIRST VALUE, LAST VALUE ① FIRST VALUE 윈도우의 정렬된 값 중에서 첫 번째 값을 반환 ② LAST VALUE 윈도우의 정렬된 값 중에서 마지막 값을 반환 ◎ 문법 FIRST VALUE | LAST VALUE(Value Expression 1) OVER ( [PARTITION BY <Value Expression 2> ORDER BY <Value Expression 3> [Collate Clause] [ASC | DESC] [NULLS FIRST | NULLS LAST] ) 29
1. Analytic Function • Aggregate Family FIRST VALUE, LAST VALUE ◎ 예제 SELECT CUSTCODE, SALEDATE, SALE_AMT, FIRST_VALUE(SALE_AMT) OVER(PARTITION BY CUSTCODE ORDER BY SALEDATE) FIRST_SALE_AMT, LAST_VALUE(SALE_AMT) OVER(PARTITION BY CUSTCODE ORDER BY SALEDATE RANGE BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) LAST_SALE_AMT FROM SALE_TBL; 30
1. Analytic Function • Aggregate Family Reporting Aggregate Function의 활용 다음은 EMP 테이블을 이용하여 Reporting Aggregate Function의 활용 사례에 대해 설명을 할 것이다. 31
1. Analytic Function • Aggregate Family Reporting Aggregate Function의 활용 ① Reporting Aggregate Family – SUM() - EMP 테이블에서 각각의 부서별로, 총 판매액이 가장 많은 직무를 아래 표와 같이 구한다. • Analytic Function을 사용하지 않은 경우 SELECT V 2. DEPTNO, V 2. JOB, V 2. SUM_SAL, V 1. MAX_SUM_SAL FROM (SELECT DEPTNO, MAX(SUM_SAL) MAX_SUM_SAL FROM (SELECT DEPTNO, JOB, SUM(SAL) SUM_SAL FROM EMP GROUP BY DEPTNO, JOB) GROUP BY DEPTNO) V 1, (SELECT DEPTNO, JOB, SUM(SAL) SUM_SAL FROM EMP GROUP BY DEPTNO, JOB) V 2 WHERE V 2. DEPTNO = V 1. DEPTNO AND V 2. SUM_SAL = V 1. MAX_SUM_SAL; 32
1. Analytic Function • Aggregate Family Reporting Aggregate Function의 활용 ① Reporting Aggregate Family – SUM() - EMP 테이블에서 각각의 부서별로, 총 판매액이 가장 많은 직무를 아래 표와 같이 구한다. • Analytic Function을 사용한 경우 SELECT DEPTNO, JOB, SUM_SAL, MAX_SAL FROM (SELECT DEPTNO, JOB, SUM(SAL) SUM_SAL, MAX(SUM(SAL)) OVER(PARTITION BY DEPTNO) MAX_SAL FROM EMP E GROUP BY DEPTNO, JOB) A WHERE SUM_SAL = MAX_SAL; 33
1. Analytic Function • Aggregate Family Reporting Aggregate Function의 활용 ① Reporting Aggregate Family – RATIO_TO_REPORT() • Analytic Function을 사용하지 않은 경우 SELECT V 2. DEPTNO, V 2. JOB, V 2. SUM_SAL, V 1. SUM_TOTAL, V 2. SUM_SAL / V 1. SUM_TOTAL RATIO_TO_SUM FROM (SELECT DEPTNO, SUM(SAL) SUM_TOTAL FROM EMP GROUP BY DEPTNO) V 1, (SELECT DEPTNO, JOB, SUM(SAL) AS SUM_SAL FROM EMP GROUP BY DEPTNO, JOB) V 2 WHERE V 2. DEPTNO = V 1. DEPTNO; 35
1. Analytic Function • Aggregate Family Reporting Aggregate Function의 활용 ① Reporting Aggregate Family – RATIO_TO_REPORT() • Analytic Function을 사용한 경우 SELECT DEPTNO, JOB, SUM(SAL) SUM_SAL, SUM(SAL)) OVER(PARTITION BY DEPTNO) TOTAL_SAL, RATIO_TO_REPORT(SUM(SAL)) OVER(PARTITION BY DEPTNO) RATIO_TO_SUM FROM EMP GROUP BY DEPTNO, JOB; 36
2. ETC Function MERGE ◎ 문법 MERGE INTO TABLE_NAME ALIAS USING (TABLE | VIEW | SUBQUERY) ALIAS ON (JOIN CONDITION) WHEN MATCHED THEN UPDATE SET COL 1 = VAL 1, COL 2 = VAL 2… WHEN NOT MATCHED THEN INSERT (COL 1, COL 2, . . ) VALUES (VAL 1, VAL 2, . . ); • • MERGE는 UPDATE와 INSERT를 결합한 문장으로 각 쓰임새는 다음과 같다. INTO 절 : 데이터가 UPDATE되거나 INSERT될 대상 테이블 USING 절 : 대상 테이블의 데이터와 비교한 후 UPDATE 또는 INSERT할 때 사용할 Data Source ON 절 : UPDATE나 INSERT를 하게 될 Condition으로 해당 조건을 만족하는 Row가 있으면 WHEN MATCHED THEN 이하를 실행하게 되고 없으면 WHEN NOT MATCHED THEN 이하를 실행하게 된다. • WHEN MATCHED THEN 절 : ON 절의 조건이 TRUE인 ROW에 수행할 내용 • WHEN NOT MATCHED THEN 절 : ON 절의 조건에 맞는 ROW가 없을 때 수행할 내용 • MERGE는 ORACLE 9 i부터 지원 됨. 37
2. ETC Function MERGE ◎ 예제 CREATE TABLE EMP_HISTORY( EMP NUMBER(4), UPDATE_DATE, SAL NUMBER(7, 2), SALARY NUMBER(7, 2) ); MERGE INTO EMP_HISTORY EH USING EMP E ON (E. EMPNO = EH. EMP) WHEN MATCHED THEN UPDATE SET EH. SALARY = E. SAL WHEN NOT MATCHED THEN INSERT VALUES (E. EMPNO, SYSDATE, E. SAL * 1. 5); 38
2. ETC Function START WITH, CONNETC BY ◎ 예제 • Top – Down 방식 SELECT LEVEL, EMPNO, ENAME, MGR, JOB FROM EMP START WITH JOB = 'PRESIDENT' CONNECT BY PRIOR EMPNO = MGR; • Bottom – Up 방식 SELECT LEVEL, EMPNO, ENAME, MGR, JOB FROM EMP START WITH JOB = 'CLERK' CONNECT BY PRIOR MGR = EMPNO; 40
2. ETC Function ROLLUP, CUBE ◎ ROLLUP 주로 GROUP BY와 함께 사용되며 GROUPING 조건에 따라 각 그룹의 그룹핑 항목이 있으면 우측부터 하나씩 제외 하면서 그 결과를 반환한다. SELECT DECODE(GROUPING(DEPTNO), 1, 'ALL TOT', DEPTNO) DEPTNO, DECODE(GROUPING(JOB), 1, 'JOB TOT', JOB) JOB, COUNT(SAL) CNT, SUM(SAL) SUM_SAL FROM EMP GROUP BY ROLLUP(DEPTNO, JOB); 42
2. ETC Function ROLLUP, CUBE ◎ CUBE ROLLUP 연산자가 수행한 결과에 부가적으로 그룹핑 조건이 가능한 모든 조합에 대한 결과를 출력한다. SELECT DECODE(GROUPING(DEPTNO), 1, 'ALL TOT', DEPTNO) DEPTNO, DECODE(GROUPING(JOB), 1, 'JOB TOT', JOB) JOB, COUNT(SAL) CNT, SUM(SAL) SUM_SAL FROM EMP GROUP BY CUBE(DEPTNO, JOB); 43
2. ETC Function Row를 Column으로 풀기 SELECT NVL(SUM(DECODE(TO_CHAR(E. HIREDATE, 'mm'), '01', COUNT(*))), 0) JANUARY, NVL(SUM(DECODE(TO_CHAR(E. HIREDATE, 'mm'), '02', COUNT(*))), 0) FEBRUARY, NVL(SUM(DECODE(TO_CHAR(E. HIREDATE, 'mm'), '03', COUNT(*))), 0) MARCH, NVL(SUM(DECODE(TO_CHAR(E. HIREDATE, 'mm'), '04', COUNT(*))), 0) APRIL, NVL(SUM(DECODE(TO_CHAR(E. HIREDATE, 'mm'), '05', COUNT(*))), 0) MAY, NVL(SUM(DECODE(TO_CHAR(E. HIREDATE, 'mm'), '06', COUNT(*))), 0) JUNE, NVL(SUM(DECODE(TO_CHAR(E. HIREDATE, 'mm'), '07', COUNT(*))), 0) JULY, NVL(SUM(DECODE(TO_CHAR(E. HIREDATE, 'mm'), '08', COUNT(*))), 0) AUGUST, NVL(SUM(DECODE(TO_CHAR(E. HIREDATE, 'mm'), '09', COUNT(*))), 0) SEPTEMBER, NVL(SUM(DECODE(TO_CHAR(E. HIREDATE, 'mm'), '10', COUNT(*))), 0) OCTOBER, NVL(SUM(DECODE(TO_CHAR(E. HIREDATE, 'mm'), '11', COUNT(*))), 0) NOVEMBER, NVL(SUM(DECODE(TO_CHAR(E. HIREDATE, 'mm'), '12', COUNT(*))), 0) DECEMBER FROM EMP E GROUP BY TO_CHAR(E. HIREDATE, 'mm'); 44
2. ETC Function Column을 Row로 풀기 SELECT SUBDEPTNO, SUBDEPT. DNAME, DECODE(DUMY. X, 0, TO_CHAR(SUBDEPTNO), SUBDEPT. DNAME) TEMP FROM (SELECT DEPTNO, DNAME FROM DEPT) SUBDEPT, (SELECT 0 X FROM DUAL UNION ALL SELECT 1 X FROM DUAL) DUMY ORDER BY SUBDEPTNO; 45
3. Appendix • PFILE & SPFILE ◎ Oracle 9 i 인스턴스 구동을 위한 SPFILE 및 PFILE • init. ora 파일의 지정 인스턴스 구동 시에 init. ora 파일을 명시적으로 지정하는 방법은 이전 버전과 동일하다. 유의해야 할 점은 SPFILE은 PFILE과 같이 인스턴스 구동 시 동적으로 지정할 수 없다는 것이다. 만약 SPFILE을 지정할 경우 에러가 발생한다. SQL> startup pfile=C: oracleadminLHKDBpfileinit. ora ORACLE 인스턴스가 시작되었습니다. Total System Global Area 118255568 bytes Fixed Size 282576 bytes Variable Size 83886080 bytes Database Buffers 33554432 bytes Redo Buffers 532480 bytes 데이터베이스가 마운트되었습니다. SQL> startup spfile=C: oracleadminLHKDBpfileinit. ora SP 2 -0714: 부적합한 STARTUP 옵션 조합입니다 53
3. Appendix • PFILE & SPFILE ◎ 사용하고자 하는 SPFILE의 지정 사용하고자 하는 SPFILE을 지정하고자 할 경우에는 init. ora 파일을 사용하여야 하며, init. ora 파일에는 SPFILE의 절대 경로만 지정되어 있어야 한다. 이 경우에는 SQL*PLUS에서 인스턴스 구동 시 사용된 SPFILE을 다음과 같이 확인해 볼 수 있다. SQL> startup pfile=C: oracleadminLHKDBpfileinit. ora ORACLE 인스턴스가 시작되었습니다. Total System Global Area 118255568 bytes Fixed Size 282576 bytes Variable Size 83886080 bytes Database Buffers 33554432 bytes Redo Buffers 532480 bytes 데이터베이스가 마운트되었습니다. 데이터베이스가 열렸습니다. SQL> show parameter pfile NAME TYPE VALUE ----------------------------spfile string C: oracleora 90databaseSPFILELHKDB. ORA 54
3. Appendix • No Archivelog Mode & Archivelog Mode 설정 ◎ Archivelog Mode 상태 확인 SQL> archive log list 데이터베이스 로그 모드 아카이브 모드가 아님 자동 아카이브 사용 아카이브 대상 c: oracleoradataLHKDB 가장 오래된 온라인 로그 순서 19 현재 로그 순서 21 SQL> select log_mode from v$database; LOG_MODE ------------NOARCHIVELOG 55
3. Appendix • No Archivelog Mode & Archivelog Mode 설정 ◎ Archivelog Mode 설정 방법 • 데이터베이스 종료 SQL> shutdown abort ORACLE 인스턴스가 종료되었습니다. • 데이터베이스를 MOUNT SQL> startup mount ORACLE 인스턴스가 시작되었습니다. Total System Global Area 118255568 bytes Fixed Size 282576 bytes Variable Size 83886080 bytes Database Buffers 33554432 bytes Redo Buffers 532480 bytes 데이터베이스가 마운트되었습니다. 57
3. Appendix • No Archivelog Mode & Archivelog Mode 설정 ◎ Archivelog Mode 설정 방법 • 데이터베이스 모드 변경 RECOVER를 해도 똑같은 에러가 나오는 것이 바로 shutdown abort 때문이다. 또는 로그 스위치를 강제로 시켜주면 된다. ※ 오라클 메시지 참고 00265, 00000, "instance recovery required, cannot set ARCHIVELOG mode" // *Cause: The database either crashed or was shutdown with the ABORT // option. Media recovery cannot be enabled because the online // logs may not be sufficient to recover the current datafiles. // *Action: Open the database and then enter the SHUTDOWN command with the // NORMAL or IMMEDIATE option. 다시 STARTUP 한 후 shutdown normal 또는 immediate하면 모두 정상적으로 실행 될 것이다. 59
3. Appendix • No Archivelog Mode & Archivelog Mode 설정 ◎ Archivelog Mode 설정 방법 • 데이터베이스 모드 변경 데이터베이스를 오픈하여 정상적으로 다시 shutdown 처리해야 한다. SQL> alter database open; 데이타베이스가 변경되었습니다. SQL> shutdown immediate; 데이터베이스가 닫혔습니다. 데이터베이스가 마운트 해제되었습니다. ORACLE 인스턴스가 종료되었습니다. SQL> startup mount ORACLE 인스턴스가 시작되었습니다. Total System Global Area 118255568 bytes Fixed Size 282576 bytes Variable Size 83886080 bytes Database Buffers 33554432 bytes Redo Buffers 532480 bytes 데이터베이스가 마운트되었습니다. 60
3. Appendix • No Archivelog Mode & Archivelog Mode 설정 ◎ Archivelog Mode 설정 방법 • 데이터베이스 모드 변경 SQL> alter database open; 데이타베이스가 변경되었습니다. SQL> alter system switch logfile; 시스템이 변경되었습니다. SQL> alter system archive log stop; 시스템이 변경되었습니다. SQL> alter system archive log start; 시스템이 변경되었습니다. 62
3. Appendix • No Archivelog Mode & Archivelog Mode No Archivelog Mode 설정 ◎ No Archivelog Mode 설정 방법 No Archivelog Mode로 설정하는 방법은 간단하다. • 데이터베이스 종료 SQL> shutdown 데이터베이스가 닫혔습니다. 데이터베이스가 마운트 해제되었습니다. ORACLE 인스턴스가 종료되었습니다. • 데이터베이스 마운스 SQL> startup mount ORACLE 인스턴스가 시작되었습니다. Total System Global Area 118255568 bytes Fixed Size 282576 bytes Variable Size 83886080 bytes Database Buffers 33554432 bytes Redo Buffers 532480 bytes 데이터베이스가 마운트되었습니다. 63
3. Appendix • No Archivelog Mode & Archivelog Mode No Archivelog Mode 설정 ◎ No Archivelog Mode 설정 방법 • 데이터베이스 모드 변경 SQL> alter database noarchivelog; 데이타베이스가 변경되었습니다. SQL> archive log list; 데이터베이스 로그 모드 자동 아카이브 대상 가장 오래된 온라인 로그 순서 현재 로그 순서 아카이브 모드가 아님 사용 c: oracleoradataLHKDB 23 25 간단히 No Archivelog Mode로 변경되었다. 64
3. Appendix • No Archivelog Mode & Archivelog Mode No Archivelog Mode 설정 ◎ No Archivelog Mode 설정 방법 • 데이터베이스 모드 변경 SQL> alter database open; 데이타베이스가 변경되었습니다. SQL> select log_mode from v$database; LOG_MODE ------------NOARCHIVELOG 65
3. 참고한 Site ◎ http: //blog. naver. com/oriwolf/ ◎ http: //cafe. naver. com/flyoracle. cafe ◎ http: //blog. naver. com/jeany 4 u 66